Flink Table & SQL 自定义TableSource、TableSink
Flink Table & SQL中提供了非常丰富的接口来让我们自定义TableSource、TableSink。
自定义TableSource或TableSink,需要将以下两点结合起来:
-
了解不同
TableSource接口、TableSink接口、TableFactory接口提供的功能以及适用的场景。 -
看
JDBCTableSource、JDBCUpsertTableSink源码,源码中对失败重试、本地缓存、批量读写等都提供了很好的示例。最好是从JDBCTableSourceSinkFactory开始看起,并改改源码,多Debug,慢慢就明白了。
注意: 这里提到了TableFactory,TableFactory让我们能够通过一组字符串属性来创建TableSource或TableSink实例,且让我们定义的TableSource或TableSink更加通用。
本文总结3大类接口: TableSource、TableSink、TableFactory。也梳理下自己这块的知识体系。
TableSource
TableSource接口是定义Source的基础接口,用于支持从外部系统中获取数据并转换成Table。
public interface TableSource<T> {
default DataType getProducedDataType() {
final TypeInformation<T> legacyType = getReturnType();
if (legacyType == null) {
throw new TableException("Table source does not implement a produced data type.");
}
return fromLegacyInfoToDataType(legacyType);
}
@Deprecated
default TypeInformation<T> getReturnType() {
return null;
}
@Deprecated
TableSchema getTableSchema();
default String explainSource() {
return TableConnectorUtils.generateRuntimeName(getClass(), getTableSchema().getFieldNames());
}
}
TableSource接口有四个方法: getProducedDataType、getReturnType、getTableSchema、explainSource。
-
getProducedDataType(): 定义TableSource返回的数据类型。 -
getReturnType(): 定义TableSource返回的数据类型。过时的方法。有很多地方在用,如JDBCTableSource、KafkaTableSourceBase、PythonInputFormatTableSource。我们在定义新的TableSource时,用getProducedDataType()即可。 -
getTableSchema(): 定义TableSource返回的Schema,即表的字段名、字段类型。过时的方法。 -
explainSource(): 返回TableSource的描述信息。
接着,来看下TableSource接口的UML,如下:
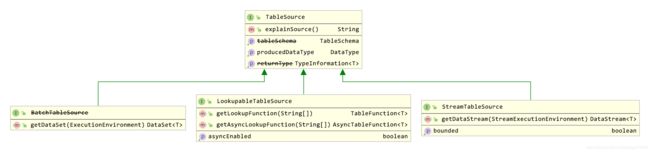
TableSource主要有三个子类: StreamTableSource、BatchTableSource、LookupableTableSource。
StreamTableSource
StreamTableSource扩展了TableSource,支持从外部系统中获取无界流DataStream并最终转化为Table。
public interface StreamTableSource<T> extends TableSource<T> {
default boolean isBounded() {
return false;
}
DataStream<T> getDataStream(StreamExecutionEnvironment execEnv);
}
StreamTableSource接口有两个方法: isBounded、getDataStream。
-
isBounded(): 返回布尔值。是有界还是无界,默认无界流。 -
getDataStream(StreamExecutionEnvironment execEnv): 借助StreamExecutionEnvironment返回一个DataStream。通常可通过StreamExecutionEnvironment#createInput(InputFormat方法、typeInfo) StreamExecutionEnvironment#addSource(SourceFunction方法实现。function)
BatchTableSource
BatchTableSource扩展了TableSource,支持从外部系统中获取有界流DataSet。已过时的接口,不做过多介绍。了解下。
public interface BatchTableSource<T> extends TableSource<T> {
DataSet<T> getDataSet(ExecutionEnvironment execEnv);
}
LookupableTableSource
LookupableTableSource扩展了TableSource,支持通过一组Key从外部系统(如Mysql、HBase、Kudu等)中查找数据。在流维Join的场景下,该接口非常实用。
例如,MySQL TableSource实现此接口后,可处理如Kafka流 Join Mysql维的场景。
public interface LookupableTableSource<T> extends TableSource<T> {
TableFunction<T> getLookupFunction(String[] lookupKeys);
AsyncTableFunction<T> getAsyncLookupFunction(String[] lookupKeys);
boolean isAsyncEnabled();
}
LookupableTableSource接口有三个方法: getLookupFunction、getAsyncLookupFunction、isAsyncEnabled。
-
getLookupFunction(String[] lookupKeys): 返回一个TableFunction。根据指定的key同步查找匹配的行。也就是说,同步Lookup,本质上是通过TableFunction实现的。 -
getAsyncLookupFunction(String[] lookupKeys): 返回一个AsyncTableFunction。根据指定的key异步查找匹配的行。也就是说,异步Lookup,本质上是通过AsyncTableFunction实现的。 -
isAsyncEnabled(): 如果启用了异步Lookup,则此方法应返回true。当返回true时,必须实现getAsyncLookupFunction(String[] lookupKeys)方法。
Flink Table & SQL LookableTableSource
给TableSource带上时间属性
处理时间
public interface DefinedProctimeAttribute {
@Nullable
String getProctimeAttribute();
}
DefinedProctimeAttribute接口只有一个方法: getProctimeAttribute。
getProctimeAttribute(): 返回处理时间的字段名。字段名必须出现在TableSchema中,且是TIMESTAMP类型。
事件时间
public interface DefinedRowtimeAttributes {
List<RowtimeAttributeDescriptor> getRowtimeAttributeDescriptors();
}
DefinedRowtimeAttributes接口只有一个方法: getRowtimeAttributeDescriptors。
getRowtimeAttributeDescriptors(): 返回RowtimeAttributeDescriptor的列表。RowtimeAttributeDescriptor用来描述这个rowtime字段。RowtimeAttributeDescriptor有3个属性:-
attributeName: rowtime的字段名。字段名必须出现在TableSchema中,且是TIMESTAMP类型。 -
timestampExtractor: 时间戳提取器,从记录中提取时间戳。如从记录中某个Long类型的字段中转换出时间戳。 -
watermarkStrategy: 水印生成器。
-
注意:
-
getRowtimeAttributeDescriptors()虽然返回一个列表,但目前单个TableSource中仅支持一个rowtime字段。 -
内置时间戳提取器:
ExistingField、StreamRecordTimestamp。-
ExistingField(String field): 从已经存在的Long、Timestamp、时间戳格式的String字段(如"2018-05-28 12:34:56.000")类型的字段中获取rowtime。 -
StreamRecordTimestamp(): 从DataStream StreamRecord的时间戳中提取rowtime属性的值。此TimestampExtractor不适用于批处理TableSource。
-
-
内置水印生成器:
PeriodicWatermarkAssigner、PreserveWatermarks、PunctuatedWatermarkAssigner。-
AscendingTimestamps: 升序时间的水印生成器。 -
BoundedOutOfOrderTimestamps: 固定延迟的水印生成器。 -
PreserveWatermarks: 水印由底层的DataStream提供。
-
让TableSource支持Projection Pushdown
像Parquet这类的列存文件,支持只读取指定的列, 此时,将指定列的查询下推,只需要扫描指定的列,可大大提升读取效率。
JDBCTableSource、CsvTableSource都支持了Projection Push-Down。
通过ProjectableTableSource接口,可以给TableSource增加Projection下推功能。
public interface ProjectableTableSource<T> {
TableSource<T> projectFields(int[] fields);
}
ProjectableTableSource接口只有一个方法: projectFields。
projectFields(int[] fields): 指定那些列要下推。
让TableSource支持Filter Pushdown
Parquet本身支持RowGroup级别的过滤,此时可将Filter下推,可减少传入Flink的数据量,提高性能。
通过FilterableTableSource接口,可以给TableSource增加过滤下推功能。
public interface FilterableTableSource<T> {
TableSource<T> applyPredicate(List<Expression> predicates);
boolean isFilterPushedDown();
}
FilterableTableSource接口有两个方法: applyPredicate、isFilterPushedDown。
-
applyPredicate(List: 指定Predicate列表。predicates) -
isFilterPushedDown(): 返回该标志以指示是否已尝试Filter Pushdown。
TableSink
TableSink接口是定义Sink的基础接口,用于支持将Table输出到外部存储。对于流表,一般是Table => DataStream =>外部存储。
public interface TableSink<T> {
default DataType getConsumedDataType() {
final TypeInformation<T> legacyType = getOutputType();
if (legacyType == null) {
throw new TableException("Table sink does not implement a consumed data type.");
}
return fromLegacyInfoToDataType(legacyType);
}
@Deprecated
default TypeInformation<T> getOutputType() {
return null;
}
default TableSchema getTableSchema() {
final String[] fieldNames = getFieldNames();
final TypeInformation[] legacyFieldTypes = getFieldTypes();
if (fieldNames == null || legacyFieldTypes == null) {
throw new TableException("Table sink does not implement a table schema.");
}
return new TableSchema(fieldNames, legacyFieldTypes);
}
@Deprecated
default String[] getFieldNames() {
return null;
}
@Deprecated
default TypeInformation<?>[] getFieldTypes() {
return null;
}
@Deprecated
TableSink<T> configure(String[] fieldNames, TypeInformation<?>[] fieldTypes);
}
TableSink有六个方法: getConsumedDataType、getOutputType、getTableSchema、getFieldNames、getFieldTypes、configure。
-
getConsumedDataType(): 消费的表的数据类型。 -
getOutputType(): 此方法将在以后的版本中移除,因为它使用的是旧的类型系统。建议使用getConsumedDataType()。 -
getTableSchema(): 消费的表的Schema。 -
getFieldNames(): 过时的方法,用getTableSchema()代替。 -
getFieldTypes(): 过时的方法,用getTableSchema()代替。 -
configure(String[] fieldNames, TypeInformation[] fieldTypes): 配置此TableSink的字段名、字段类型。
接着,来看下TableSink接口的UML,如下:
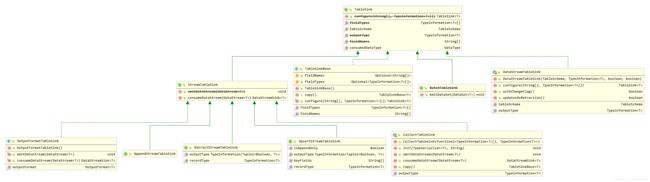
为支持不同的场景,TableSink有多种实现,这里只总结的三种: AppendStreamTableSink、UpsertStreamTableSink、RetractStreamTableSink。
对于这三种Sink,之前有总结过一篇: Flink Table & SQL AppendStreamTableSink、RetractStreamTableSink、UpsertStreamTableSink。
AppendStreamTableSink
AppendStreamTableSink扩展了TableSink,支持将只有Insert的流表保存到外部存储。
public interface AppendStreamTableSink<T> extends StreamTableSink<T> {
}
AppendStreamTableSink接口没有自己的方法,在实现时根据需要重写父类consumeDataStream(DataStream方法。
KafkaTableSinkBase、CsvTableSink、JDBCAppendTableSink均实现了此接口。
RetractStreamTableSink
RetractStreamTableSink扩展了TableSink,支持将有Insert、Delete、Update的流表保存到外部存储。
在处理时,流表将被转换为Add和Retract消息流,这些消息流被编码为Java Tuple2。第一个字段Boolean值指示消息类型(true表示插入,false表示删除)。第二个字段是具体的数据。
public interface RetractStreamTableSink<T> extends StreamTableSink<Tuple2<Boolean, T>> {
TypeInformation<T> getRecordType();
@Override
default TypeInformation<Tuple2<Boolean, T>> getOutputType() {
return new TupleTypeInfo<>(Types.BOOLEAN, getRecordType());
}
}
RetractStreamTableSink接口有两个方法: getRecordType、getOutputType。
-
getRecordType(): 处理的数据类型。 -
getOutputType(): 默认方法,消息编码输出的类型。
UpsertStreamTableSink
UpsertStreamTableSink扩展了TableSink,支持将有Insert、Delete、Update的流表保存到外部存储。
在处理时,流表将被转换为Upsert和Delete消息流,然后被编码为Java Tuple2。第一个字段Boolean值指示消息类型(true表示upsert,false表示delete )。第二个字段是具体的数据。
public interface UpsertStreamTableSink<T> extends StreamTableSink<Tuple2<Boolean, T>> {
void setKeyFields(String[] keys);
void setIsAppendOnly(Boolean isAppendOnly);
TypeInformation<T> getRecordType();
@Override
default TypeInformation<Tuple2<Boolean, T>> getOutputType() {
return new TupleTypeInfo<>(Types.BOOLEAN, getRecordType());
}
}
UpsertStreamTableSink接口有4个方法: setKeyFields、setIsAppendOnly、getRecordType、getOutputType。
-
setKeyFields(String[] keys): 设置Unique Key。 -
setIsAppendOnly(Boolean isAppendOnly): 是否只有Insert。 -
getRecordType(): 处理的数据类型。 -
getOutputType(): 默认方法,Upsert和Delete被编码为Java Tuple2
TableFactory
Flink中有很多TableSource、TableSink的实现。在流环境中,根据一组字符串属性,如下:
create table sink_mysql
(
field1 STRING,
field2 STRING,
field3 STRING
) with (
'connector.type' = 'jdbc',
'connector.driver' = 'com.mysql.jdbc.Driver',
'connector.url' = 'jdbc:mysql://localhost:3306/bigdata?characterEncoding=utf8&useSSL=false',
'connector.username' = '****',
'connector.password' = '****',
'connector.table' = 't_result',
'connector.write.flush.max-rows' = '50',
'connector.write.flush.interval' = '2s',
'connector.write.max-retries' = '3'
);
应该去匹配哪个TableSink?此时,就需要TableFactory。TableFactory让你能够基于一组字符串属性(如上with语句块)匹配并创建TableSource、TableSink实例。
每个TableSource、TableSink的实现都应有对应的TableFactory。
TableFactory接口是定义一个Table工厂的基类。先来看下TableFactory接口的UML,如下:

如果是流表,在用的时候一般会用其子类: StreamTableSourceFactory、StreamTableSinkFactory。
StreamTableSourceFactory
StreamTableSourceFactory扩展了TableFactory,用来定义StreamTableSource的工厂。
public interface StreamTableSourceFactory<T> extends TableSourceFactory<T> {
StreamTableSource<T> createStreamTableSource(Map<String, String> properties);
@Override
default TableSource<T> createTableSource(Map<String, String> properties) {
return createStreamTableSource(properties);
}
}
StreamTableSourceFactory有两个方法: createStreamTableSource、createTableSource。
-
createStreamTableSource(Map: 基于给定的字符串属性,创建StreamTableSource。 -
createTableSource(Map: 默认方法,通过调用createStreamTableSource来创建TableSource。
在定义一个StreamTableSourceFactory时,至少需要实现如下3个方法:
-
requiredContext(): 父类中的方法,定义此Factory的上下文。只有满足这些属性时,才与此Factory匹配。空上下文意味着此Factory对所有的类型都匹配。 -
supportedProperties(): 父类中的方法,定义此Factory支持的属性列表。 -
createStreamTableSource(Map: 定义基于字符串属性,如何创建TableSource。
StreamTableSinkFactory
StreamTableSinkFactory扩展了TableFactory,用来定义StreamTableSink的工厂。
public interface StreamTableSinkFactory<T> extends TableSinkFactory<T> {
StreamTableSink<T> createStreamTableSink(Map<String, String> properties);
@Override
default TableSink<T> createTableSink(Map<String, String> properties) {
return createStreamTableSink(properties);
}
}
StreamTableSinkFactory有两个方法: createStreamTableSink、createTableSink。
-
createStreamTableSink(Map: 基于给定的字符串属性,创建StreamTableSink。 -
createTableSink(Map: 默认方法,通过调用createStreamTableSink来创建TableSink。
注意:
-
TableFactory利用Java SPI进行发现。这就意味着,如果是个Maven项目,在
resources/META-INF/services目录中需要包含一个文件org.apache.flink.table.factories.TableFactory,该文件里声明了他提供的TableFactory的全类名。同理,打包的Jar包中也应该有META-INF/services/org.apache.flink.table.factories.TableFactory文件。 -
定义了TableFactory后,就可以在SQL Client(YAML文件形式)、Table API(API的方式)、SQL(Create DDL的方式)使用。
-
TableFactory匹配过程:
(1). 基于SPI发现所有可用的Factory。
(2). 通过Factory Class (如StreamTableSourceFactory)过滤Factory。
(3). 通过Context过滤Factory。
(4). 通过支持的属性过滤Factory。
(5). 验证最匹配的那个Factory。或者是抛出AmbiguousTableFactoryException 或 NoMatchingTableFactoryException异常。