检测工作想借用MTCNN里的48-net,源码来自CongWeilin Git 下下来就能跑,真是良心
进入pepare_data准备好数据以后进入48-net,目录下有一个pythonLayer.py,由于loss函数是自定义的python层,所以train.sh里,第一行要把这个目录export到pythonpath
然后在train.sh第二行里配上自己的caffe编译路径,运行,报错找不到python层,查到是因为给的caffe路径不支持python层导致的,这是在caffe编译的时候没有选择 WITH_PYTHON_LAYER := 1
caffe路径选为py-faster-rcnn/caffe-fast-rcnn/build/tools/caffe 就可以了。
然后报错:
I0705 14:14:54.502411 18187 layer_factory.hpp:77] Creating layer PythonLayer48
F0705 14:14:54.995573 18187 solver_factory.hpp:67] Check failed: registry.count(type) == 0 (1 vs. 0) Solver type SGD already registered.
一个上午也没搞定。
最后下载blvc的caffe,选择WITH_PYTHON_LAYER=1重新编译就没问题。
然后会卡在regression_Layer那里,半个下午没搞定,最后把loss层直接改为caffe自带的欧式距离loss:
layer {
name: "RegressionLoss"
type: "EuclideanLoss"
bottom: "fc6-2"
bottom: "roi"
top: "RegressionLoss"
propagate_down: 1
propagate_down: 0
loss_weight: 1
}
终于可以训练了。
-------------20180709--------------
用caffe自带欧式距离loss还是不行,分类没问题,回归框基本没法看,返回自带python层里的regression_Layer,还是卡在这个regression_Layer的setup上,很诡异,data层和cls_brige层都能注册,就这个不行:
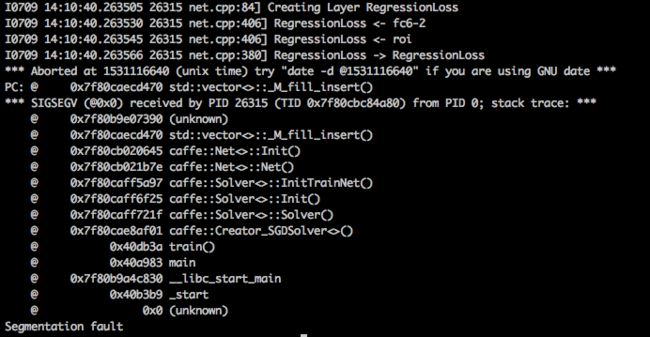
试过各种,改数据输入、改python层名字...都不行。看net.cpp Init()代码,看c++ vector _M_fill_insert()未果。
最后解决掉是在runcaffe.sh里添加blvc版caffe的python路径,看到这个,死马当活马医,试了试竟然就通过了......
export PYTHONPATH=/nfs/xxx/wkspace/caffe/python:$PYTHONPATH #这样是可以的
export PYTHONPATH=$PYTHONPATH:/nfs/xxx/wkspace/caffe/python #这样就不行
然后也遇到了回归loss NAN的问题,学习率多加一个0, lr=0.00001可以了。事实上,作者生成imdb代码有一处问题:

只有part这里是减128,而对positive和negative的处理都是:

全改成一致的,lr=0.0001, type="fixed",可以用。
然后,这是一个正确的输出log:
1 I0709 15:09:24.636786 26765 solver.cpp:239] Iteration 27000 (15.9364 iter/s, 31.3747s/500 iters), loss = 0.00683111 2 I0709 15:09:24.637056 26765 solver.cpp:258] Train net output #0: ClassifyLoss = 0.0068324 (* 1 = 0.0068324 loss) 3 I0709 15:09:24.637082 26765 solver.cpp:258] Train net output #1: RegressionLoss = 0 (* 0.5 = 0 loss) 4 I0709 15:09:24.637099 26765 solver.cpp:258] Train net output #2: cls_Acc = 1 5 I0709 15:09:24.637115 26765 sgd_solver.cpp:112] Iteration 27000, lr = 0.0001 6 I0709 15:09:55.372771 26765 solver.cpp:239] Iteration 27500 (16.2685 iter/s, 30.7343s/500 iters), loss = 0.699202 7 I0709 15:09:55.372918 26765 solver.cpp:258] Train net output #0: ClassifyLoss = 0.693147 (* 1 = 0.693147 loss) 8 I0709 15:09:55.372941 26765 solver.cpp:258] Train net output #1: RegressionLoss = 0.0121121 (* 0.5 = 0.00605605 loss) 9 I0709 15:09:55.372956 26765 solver.cpp:258] Train net output #2: cls_Acc = 0 10 I0709 15:09:55.372972 26765 sgd_solver.cpp:112] Iteration 27500, lr = 0.0001 11 I0709 15:10:26.095998 26765 solver.cpp:239] Iteration 28000 (16.2752 iter/s, 30.7217s/500 iters), loss = 0.00408262 12 I0709 15:10:26.096397 26765 solver.cpp:258] Train net output #0: ClassifyLoss = 0.00408339 (* 1 = 0.00408339 loss) 13 I0709 15:10:26.096426 26765 solver.cpp:258] Train net output #1: RegressionLoss = 0 (* 0.5 = 0 loss) 14 I0709 15:10:26.096446 26765 solver.cpp:258] Train net output #2: cls_Acc = 1 15 I0709 15:10:26.096462 26765 sgd_solver.cpp:112] Iteration 28000, lr = 0.0001 16 I0709 15:10:57.990130 26765 solver.cpp:239] Iteration 28500 (15.6778 iter/s, 31.8923s/500 iters), loss = 0.699614 17 I0709 15:10:57.990347 26765 solver.cpp:258] Train net output #0: ClassifyLoss = 0.693147 (* 1 = 0.693147 loss) 18 I0709 15:10:57.990371 26765 solver.cpp:258] Train net output #1: RegressionLoss = 0.0129341 (* 0.5 = 0.00646706 loss) 19 I0709 15:10:57.990386 26765 solver.cpp:258] Train net output #2: cls_Acc = 0
训练分类网络的时候回归loss=0, 训练回归网络的时候分类loss=0.693(log(2)),表示分类概率=0.5
用自己训练的模型finetune报错:
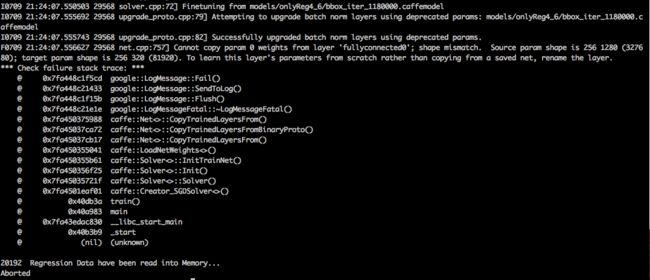
开始的时候以为是因为pythonLayer里的batchsize设的和原来不一样了,改成一致,仍旧报错,然后发现是中间改过输入图片尺度,从48改成了128,又改成了48......
runcaffe.sh改成这样比较方便:
#!/bin/bash set -e set -x EXEC_DIR="48net0" #这里等号前后不能加空格,否则会找不到 export PYTHONPATH=/nfs/xxx/wkspace/caffe/python:$PYTHONPATH export PYTHONPATH=/nfs/xxx/wkspace/caffe/examples/mtcnn/${EXEC_DIR}:$PYTHONPATH TOOLS=./build/tools $TOOLS/caffe train \ --solver=examples/mtcnn/${EXEC_DIR}/solver.prototxt \ --weights=examples/mtcnn/48net-only-cls.caffemodel \ --gpu 0 2>&1 | tee examples/mtcnn/${EXEC_DIR}/`date +'%Y-%m-%d_%H-%M-%S'`.log #根据生成时间打log
-------------2018.07.25------------
用了小半个月以后发现这个版本的数据处理脚本坑还是挺多的,还是因为自己对框架图像算法什么的都不熟,每个坑都搞了很久。
1. 最严重的一个花了整整两天时间,图像输入的问题:
首先是训练出来的网络forward时各种不对,需要和pythonLayer.py里的处理方式同步一下,然后在c++里调用的时候又不对
因为caffe输入是n,c,h,w,opencv读入一张图是通道在后的,需要把通道提前,caffe mtcnn的pythonLayer.py里直接用:
im = np.swapaxes(im, 0, 2)
把通道换到前边了,这样送给caffe去训练的是一张放倒了的图像,那么模型训好,forward的时候也要同样放倒,在python里调的时候因为用了同样的方式没问题,后来在c++里就踩坑了,输出怎么也不对,最后是把像素一个个打印出来找到问题,c++里需要加一句转置:
cv::transpose(img, img);
参考caffe2官方Tuorials,正确的方式应该是训练数据这样准备:

2. 内存问题:
pythonlayer.py里是一次性把所有训练图像都读入内存,训练时随机取一个batch,开了多卡训练以后总是莫名其妙的训练到一段时间就自己停掉了,tmux和nohup命令都一样,最后锁定到时内存爆了,改成训练时读入数据ok,128x128的输入,速度可以接受。
| batchSize | 图像读取方式 | 迭代时间 |
| 128 | 批量读入 | 6.7iters/s |
| 128 | 训练时读入 | 3.2iters/s |
| 512 | 批量读入 | 1.6iters/s |