1 一些资源
http://openmp.org/wp/ openmp 开放标准的并行程序指导性注释,没用过
http://software.intel.com/zh-cn/articles/parallelization-using-intel-threading-building-blocks-intel-tbb intel tbb ,Intel的C++多线程库,没有用过,有人说性能很不好
https://code.google.com/p/nbds/ 无锁数据结构库,关键是针对缓存做了优化,需要注意的是里边的哈希表是没有删除的,说多了都是泪
http://mcg.cs.tau.ac.il/projects/hopscotch-hashing-1 并发的hopscotch哈希表实现
da-data.blogspot.nl/2013/03/optimistic-cukoo-hashing-for.html 并发的cukoo实现,查找非常快,但增加和删除目前是大锁,作者说以后会推出无锁的增加和删除,不知道什么时候出来
http://ww2.cs.mu.oz.au/~astivala/paralleldp/ 实现了无锁的基于数组的哈希表,无锁的基于链表的哈希表,对比了多种实现的性能,无锁实现仍然是没有删除,另外,无锁实现没有针对缓存做优化
http://dpdk.org/ rte_ring.c 实现了无锁的生产者消费者队列
另外,据说apache protable runtime 里边有很多lock-free算法,Windows里的Interlocked系列函数内部实现也用到了很多lock-free算法,没有验证过。
上述代码里,详细调试过的有nbds的无锁hashtable, 用它构造了一个哈希表作为流表,与基于DPDK example的一种哈希表+dpdk rwlock 的实现做L3转发性能对比,发现不删流的情况下性能差不多,当然测试是在冲突率不是很高的情况下测试的。
2. 一次测试
2.1 测试平台
测试在一台intel E5-2658 上进行,这款CPU有两个物理CPU,每个物理CPU有8个核,每个核有两个核线程。测试只使用到一颗物理CPU,只用到core1~core8,发包和统计工具是testcenter发包仪器,使用两块万兆网卡对发udp包。
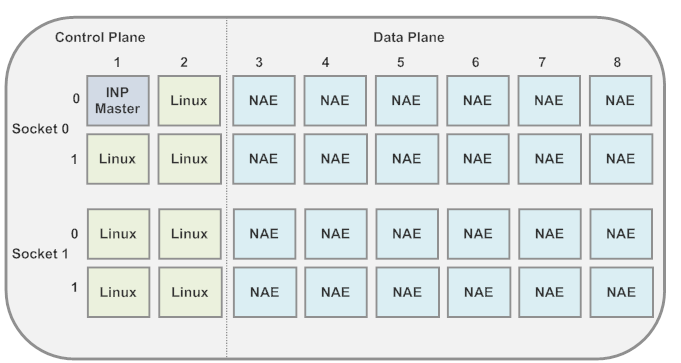
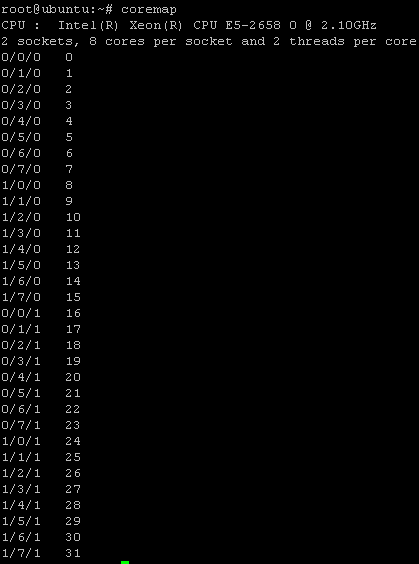
2.2 测试过程
1) DPDK 示例程序examples 里有 l2fwd 示例程序,测试程序在l2fwd的基础上改写。
如图,l2fwd 只有收包和发包两个步骤,测试程序增加了解码和查表(增加节点、拷贝mac)的操作。
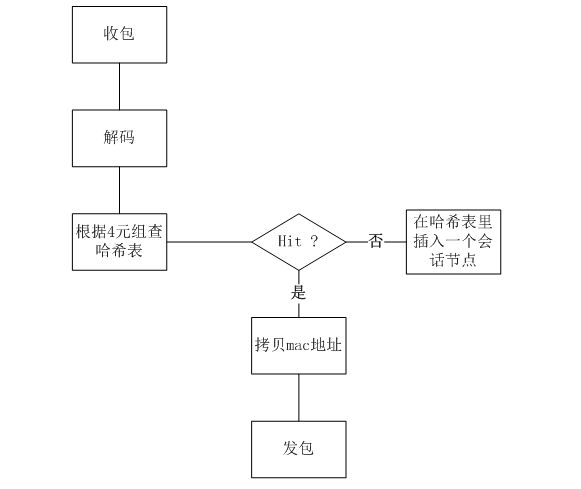
1) 测试时,固定2个core线程负责两个网卡的收包和发包,中间的解码+会话表处理灵活配置核心,测试对比了 2个,4个,6个核线程的情况
2) 哈希表部分API 使用函数指针做了一个抽象层(lookup,insert,delete),具体实现替换为不同的哈希表实现
2.3 哈希算法
1) 第一种哈希使用DPDK librte_hash/rte_fbk_hash.c 增加rte_rwlock 实现,在原有哈希算法基础上,每个bucket增加一个rwlock, lookup 的时候需要获取读锁,返回前释放。Insert 需要先获取写锁,然后lookup一遍没有相同值再插入,返回前释放写锁,delete 也需要获取写锁。
2) 第二种哈希使用nbds 的 hashtable.c 实现,在原有哈希算法基础上,将key,value 的真实值替换为 DPDK 的mempool 实现,将所有内存的申请替换为 DPDK 的rte_malloc实现。
2.4 测试结果
3) 简单测试发现,随着中间工作核线程数目增加,性能有明显提升
4) 多次反复测试发现,两种哈希实现性能相差不大。
5) Nbds 没有实现真正的delete算法,研究中发现,大部分开源的无锁结构都没有实现删除算法,删除算法会导致“状态爆炸”即中间可能的状态太多导致正确性很难证明。
结论:
a, 对于哈希表这种操作相对复杂的结构,加上要考虑多核平台的内存模型,无锁的高效稳定实现非常难,不要自己实现这样的结构。
b. 基于自旋锁/读写锁实现的哈希表性能可以接受