上周有同事问,延迟ACK到底对应用层会产生什么后果,我也不知道该如何作答,于是丢了一个链接:
TCP之Delay ACK在Linux和Windows上实现的异同-Linux的自适应ACK:
是的,这是我几年前关于Delay ACK的分析,如今看来有些许不足,有些空洞,有些学院派,所以本文试图就着这个问题来分析一个关于Delay ACK以及带来相似后果的聚集ACK,以及ACK丢失等等的具体的场景,即ACK失速问题,简称TCP失速。
之所以会在假期写这篇文章,还有两个原因,首先感谢fcicq大神的提示,其次…等我的生日过后再细说。
所谓失速,即TCP发送端由于拥塞窗口配额耗尽而无法继续发送的现象。本文我依然用tcptrace来分析。
先看一下tcptrace图的概览:

有点简陋了,详情参见:
在Wireshark的tcptrace图中看清TCP拥塞控制算法的细节(CUBIC/BBR算法为例):https://blog.csdn.net/dog250/article/details/53227203
接下来我们看一下TCP失速在CUBIC算法看来是如何解决的:
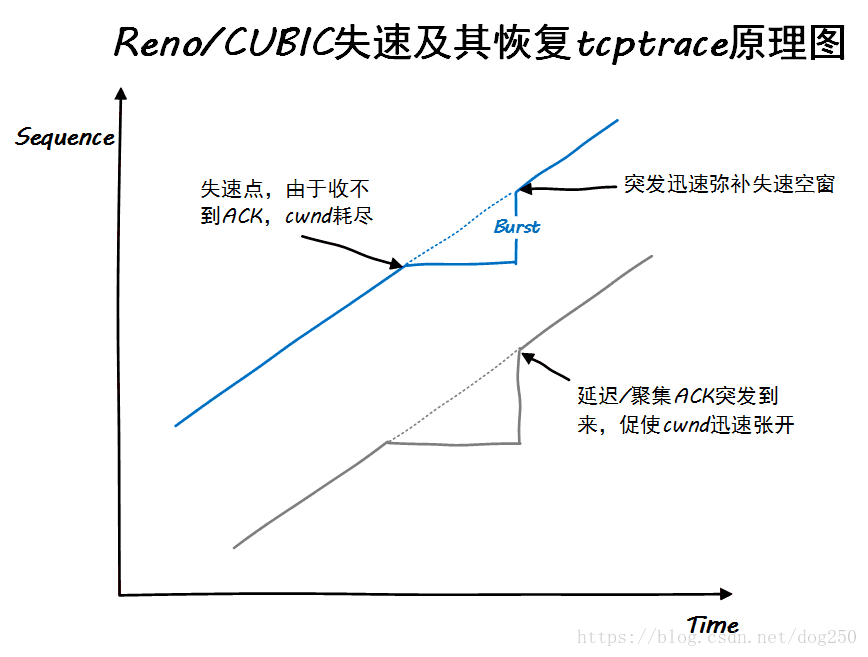
不得不说TCP基于ACK时钟驱动的AIMD模型是一个多么好的负反馈收敛模型,几乎不需要额外的任何事情,在ACK到来后,一个突发会迅速弥补失速带来的发送速率停滞。这完全是因为Reno/CUBIC算法基于cwnd来决定能发送多少数据。
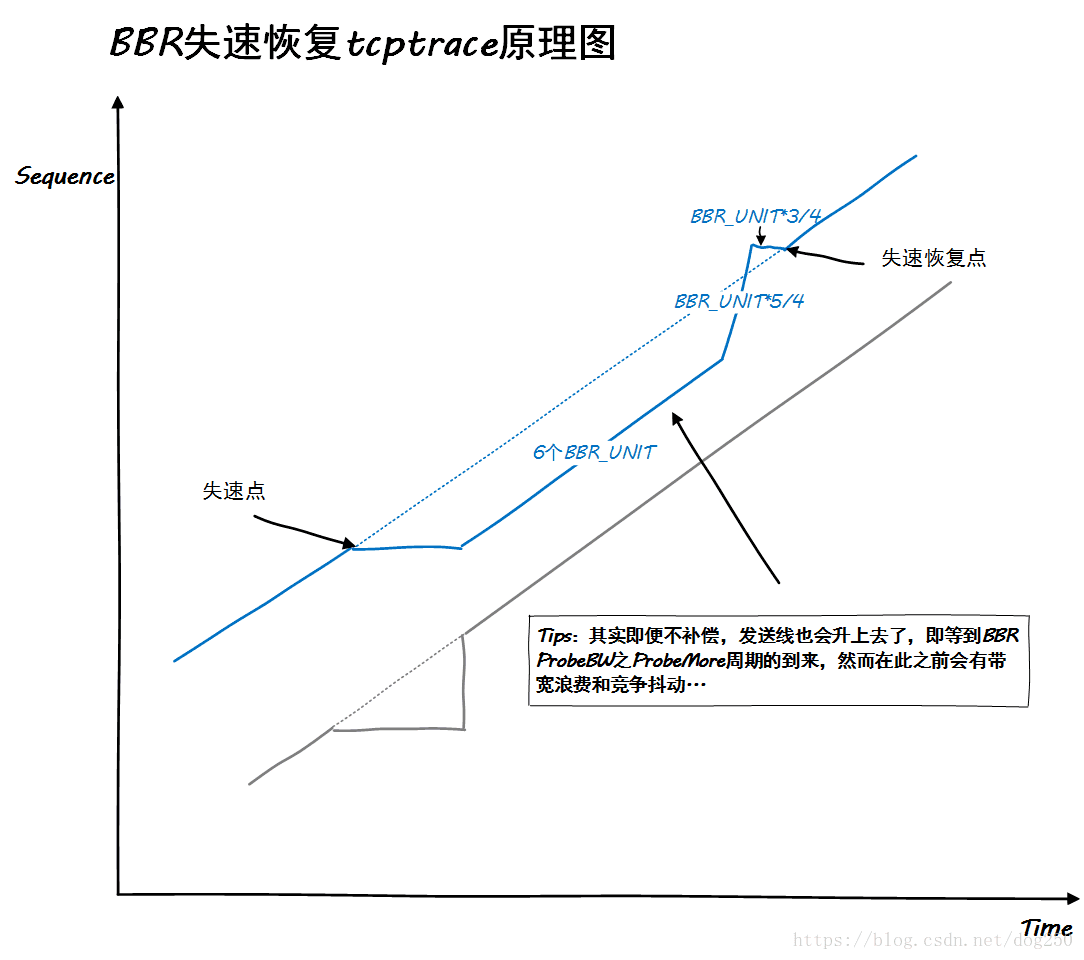
然而,事情在BBR算法中起了变化,我们看一下BBR算法下类似的场景:

有点复杂了,但是仔细琢磨还是可以理解的。我们着重看一下BBR算法失速恢复过程:
问题非常明确,于是,给出我们的愿景:

仔细思考几分钟,有没有什么解决方案呢?其实不光是应对TCP失速,任何关于TCP优化的问题,归根结底都是减小图中那个小三角形面积的问题,不要试图把发送线变陡,因为带宽是大家的,不管你自己,然而一旦出现了图中的阴影三角形,那便是整个网络系统欠你的了,遗憾的是,这种债务需要你自己去理清和了结!
不多说,先给出解决方案:
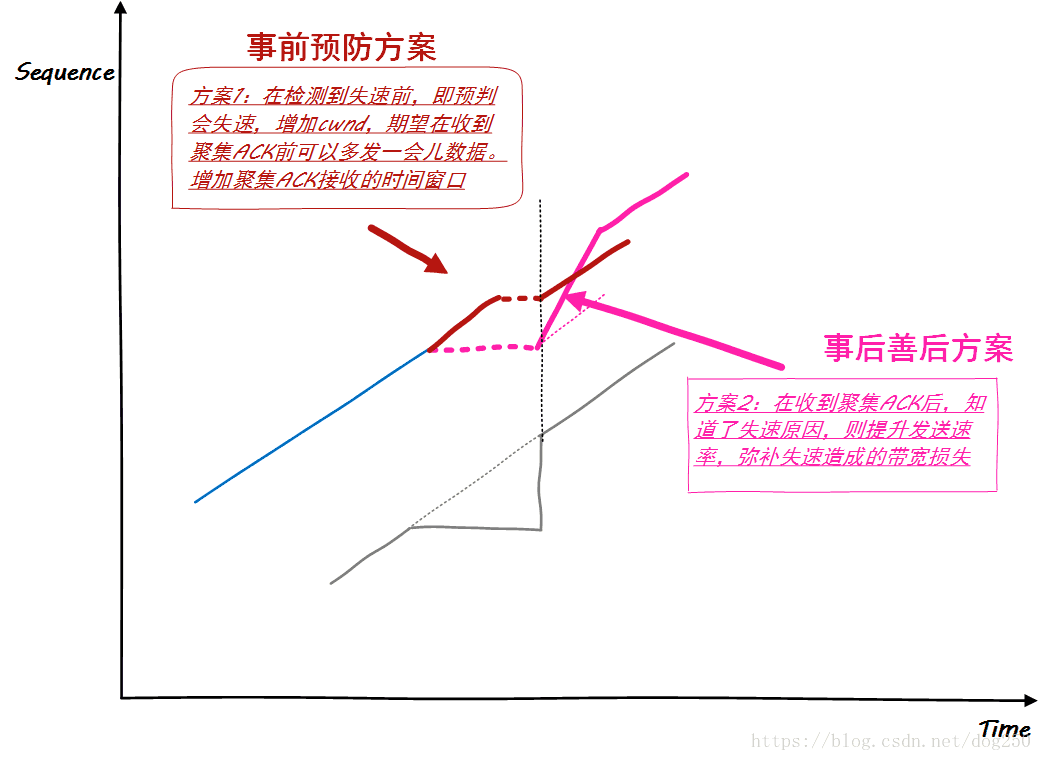
…这里我给出的是省略号,和以往文章直接把答案暴露不同,这里我也没有标准的答案,就算有我也不想再写了。问题回归原点,你怎么预测ACK将会延迟聚集到达?
感谢fcicq大神总是在我闲着无所事事或者忙的焦头烂额的时候给我一些points让我思考从而可以动起来,fcicq大神提供了一个关于BBR最新进展的ppt,非常精彩:
BBR Congestion Control Work at Google IETF
上周有同事问,延迟ACK到底对应用层会产生什么后果,我也不知道该如何作答,于是丢了一个链接:
TCP之Delay ACK在Linux和Windows上实现的异同-Linux的自适应ACK:https://blog.csdn.net/dog250/article/details/52664508
是的,这是我几年前关于Delay ACK的分析,如今看来有些许不足,有些空洞,有些学院派,所以本文试图就着这个问题来分析一个关于Delay ACK以及带来相似后果的聚集ACK,以及ACK丢失等等的具体的场景,即ACK失速问题,简称TCP失速。
之所以会在假期写这篇文章,还有两个原因,首先感谢fcicq大神的提示,其次…等我的生日过后再细说。
所谓失速,即TCP发送端由于拥塞窗口配额耗尽而无法继续发送的现象。本文我依然用tcptrace来分析。
先看一下tcptrace图的概览:
有点简陋了,详情参见:
在Wireshark的tcptrace图中看清TCP拥塞控制算法的细节(CUBIC/BBR算法为例):https://blog.csdn.net/dog250/article/details/53227203
接下来我们看一下TCP失速在CUBIC算法看来是如何解决的:
不得不说TCP基于ACK时钟驱动的AIMD模型是一个多么好的负反馈收敛模型,几乎不需要额外的任何事情,在ACK到来后,一个突发会迅速弥补失速带来的发送速率停滞。这完全是因为Reno/CUBIC算法基于cwnd来决定能发送多少数据。
然而,事情在BBR算法中起了变化,我们看一下BBR算法下类似的场景:
有点复杂了,但是仔细琢磨还是可以理解的。我们着重看一下BBR算法失速恢复过程:
问题非常明确,于是,给出我们的愿景:
仔细思考几分钟,有没有什么解决方案呢?其实不光是应对TCP失速,任何关于TCP优化的问题,归根结底都是减小图中那个小三角形面积的问题,不要试图把发送线变陡,因为带宽是大家的,不管你自己,然而一旦出现了图中的阴影三角形,那便是整个网络系统欠你的了,遗憾的是,这种债务需要你自己去理清和了结!
不多说,先给出解决方案:
…这里我给出的是省略号,和以往文章直接把答案暴露不同,这里我也没有标准的答案,就算有我也不想再写了。问题回归原点,你怎么预测ACK将会延迟聚集到达?
感谢fcicq大神总是在我闲着无所事事或者忙的焦头烂额的时候给我一些points让我思考从而可以动起来,fcicq大神提供了一个关于BBR最新进展的ppt,非常精彩:
BBR Congestion Control Work at Google IETF 101 Update:https://datatracker.ietf.org/meeting/101/materials/slides-101-iccrg-an-update-on-bbr-work-at-google-00
其中有一个非常典型的问题分析,也是和TCP失速相关的,其解决方案偏向于我上述的方案2,是一种检测到ACK行为是聚集或者延迟到达的情况下,对cwnd有所增益,具体增益值就是一个和extra_acked相关的一个数字,具体解释如下图:

图中expected_acked是怎么算出来的呢?记住下面的等式即可:
acked×interval=send_rateacked×interval=send_rate
现在的问题就是求send_ratesend_rate了,在文档:
BBR Congestion Control:IETF 99 Update:https://www.ietf.org/proceedings/99/slides/slides-99-iccrg-iccrg-presentation-2-00.pdf
中的第13/14/15页给出了一个计算方法,同时详细的算法描述请参考:
Delivery Rate Estimation:https://tools.ietf.org/id/draft-cheng-iccrg-delivery-rate-estimation-00.html。
也许还记得我前年写的那篇《来自Google的TCP BBR拥塞控制算法解析》,记得那篇文章里讲send_ratesend_rate计算的时候,给出了一张比较复杂的图:
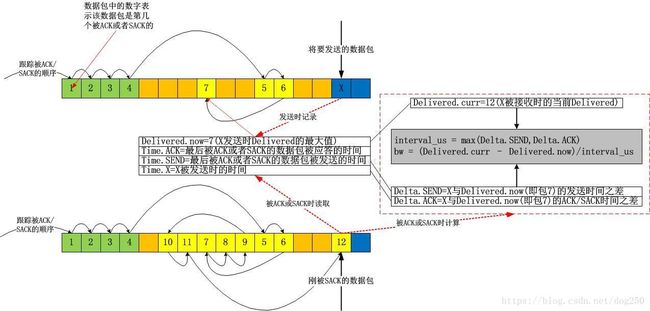
俱往矣,太low,因为大道至简,我那个太复杂了,事情本不该那么复杂,然而初学者总是喜欢把简单事情复杂化。现在看看简单的表示是什么,当然你也可以参见我给出的链接文档(draft-cheng-iccrg-delivery-rate-estimation-00)自己去琢磨:

现在提几个问题。
-
- 为什么ACK会聚集到达?
原因非常多,延迟ACK,ACK丢失,TSO,限速设备…发送归拥塞控制算法自行控制,然而ACK并不是,所以拥塞控制必须监控ACK到达的行为!BBR的cwnd增益为2,某种程度上就是为了应对这种多变的ACK到达情况。 - BBR为什么要”快速恢复”而不是等待ProbeMore去做?
BBR可以这么做,并且它也是这么做的。只是我并不认同这种做法。对于单条TCP流而言,它确确实实是一个负反馈系统,自闭环的,然而如果只有单独的一条流,那么也确实不会有什么反馈,拥塞总是来自他者!总之,我不相信在经历了BBR的6个Probe匀速周期(大约8个RTT)后,由于失速而损失的带宽还能留着还给它!一定有好的解法,只是我还没有想到,而已。
- 为什么ACK会聚集到达?
101 Update:https://
上周有同事问,延迟ACK到底对应用层会产生什么后果,我也不知道该如何作答,于是丢了一个链接:
TCP之Delay ACK在Linux和Windows上实现的异同-Linux的自适应ACK:https://blog.csdn.net/dog250/article/details/52664508
是的,这是我几年前关于Delay ACK的分析,如今看来有些许不足,有些空洞,有些学院派,所以本文试图就着这个问题来分析一个关于Delay ACK以及带来相似后果的聚集ACK,以及ACK丢失等等的具体的场景,即ACK失速问题,简称TCP失速。
之所以会在假期写这篇文章,还有两个原因,首先感谢fcicq大神的提示,其次…等我的生日过后再细说。
所谓失速,即TCP发送端由于拥塞窗口配额耗尽而无法继续发送的现象。本文我依然用tcptrace来分析。
先看一下tcptrace图的概览:
有点简陋了,详情参见:
在Wireshark的tcptrace图中看清TCP拥塞控制算法的细节(CUBIC/BBR算法为例):https://blog.csdn.net/dog250/article/details/53227203
接下来我们看一下TCP失速在CUBIC算法看来是如何解决的:
不得不说TCP基于ACK时钟驱动的AIMD模型是一个多么好的负反馈收敛模型,几乎不需要额外的任何事情,在ACK到来后,一个突发会迅速弥补失速带来的发送速率停滞。这完全是因为Reno/CUBIC算法基于cwnd来决定能发送多少数据。
然而,事情在BBR算法中起了变化,我们看一下BBR算法下类似的场景:
有点复杂了,但是仔细琢磨还是可以理解的。我们着重看一下BBR算法失速恢复过程:
问题非常明确,于是,给出我们的愿景:
仔细思考几分钟,有没有什么解决方案呢?其实不光是应对TCP失速,任何关于TCP优化的问题,归根结底都是减小图中那个小三角形面积的问题,不要试图把发送线变陡,因为带宽是大家的,不管你自己,然而一旦出现了图中的阴影三角形,那便是整个网络系统欠你的了,遗憾的是,这种债务需要你自己去理清和了结!
不多说,先给出解决方案:
…这里我给出的是省略号,和以往文章直接把答案暴露不同,这里我也没有标准的答案,就算有我也不想再写了。问题回归原点,你怎么预测ACK将会延迟聚集到达?
感谢fcicq大神总是在我闲着无所事事或者忙的焦头烂额的时候给我一些points让我思考从而可以动起来,fcicq大神提供了一个关于BBR最新进展的ppt,非常精彩:
BBR Congestion Control Work at Google IETF 101 Update:https://datatracker.ietf.org/meeting/101/materials/slides-101-iccrg-an-update-on-bbr-work-at-google-00
其中有一个非常典型的问题分析,也是和TCP失速相关的,其解决方案偏向于我上述的方案2,是一种检测到ACK行为是聚集或者延迟到达的情况下,对cwnd有所增益,具体增益值就是一个和extra_acked相关的一个数字,具体解释如下图:
图中expected_acked是怎么算出来的呢?记住下面的等式即可:
acked×interval=send_rateacked×interval=send_rate
现在的问题就是求send_ratesend_rate了,在文档:
BBR Congestion Control:IETF 99 Update:https://www.ietf.org/proceedings/99/slides/slides-99-iccrg-iccrg-presentation-2-00.pdf
中的第13/14/15页给出了一个计算方法,同时详细的算法描述请参考:
Delivery Rate Estimation:https://tools.ietf.org/id/draft-cheng-iccrg-delivery-rate-estimation-00.html。
也许还记得我前年写的那篇《来自Google的TCP BBR拥塞控制算法解析》,记得那篇文章里讲send_ratesend_rate计算的时候,给出了一张比较复杂的图:
俱往矣,太low,因为大道至简,我那个太复杂了,事情本不该那么复杂,然而初学者总是喜欢把简单事情复杂化。现在看看简单的表示是什么,当然你也可以参见我给出的链接文档(draft-cheng-iccrg-delivery-rate-estimation-00)自己去琢磨:
现在提几个问题。
-
- 为什么ACK会聚集到达?
原因非常多,延迟ACK,ACK丢失,TSO,限速设备…发送归拥塞控制算法自行控制,然而ACK并不是,所以拥塞控制必须监控ACK到达的行为!BBR的cwnd增益为2,某种程度上就是为了应对这种多变的ACK到达情况。 - BBR为什么要”快速恢复”而不是等待ProbeMore去做?
BBR可以这么做,并且它也是这么做的。只是我并不认同这种做法。对于单条TCP流而言,它确确实实是一个负反馈系统,自闭环的,然而如果只有单独的一条流,那么也确实不会有什么反馈,拥塞总是来自他者!总之,我不相信在经历了BBR的6个Probe匀速周期(大约8个RTT)后,由于失速而损失的带宽还能留着还给它!一定有好的解法,只是我还没有想到,而已。
- 为什么ACK会聚集到达?
r.ietf.org/meeting/101/ www.120xh.cn /slides-101-iccrg-an www.yongshiyule.cn -update-on-bbr-work-at-google-00
其中有一个非常典型的问题分析,也是和TCP失速相关的,其解决方案偏向于我上述的方案2,是一种检测到ACK行为是聚集或者延迟到达的情况下,对cwnd有所增益,具体增益值就是一个和extra_acked相关的一个数字,具体解释如下图:
图中expected_acked是怎么算出来的呢?记住下面的等式即可:
acked×interval=send_rateacked×interval=send_rate
现在的问题就是求send_ratesend_rate了,在文档:
BBR Congestion Control:IETF 99 Update:https://www.ietf.org/proceedings/99/slides/ www.mhylpt.com slides-99-iccrg-iccrg-presentation-2-00.pdf
中的第13/14/15页给出了一个计算方法,同时详细的算法描述请参考:
Delivery Rate Estimation:https://tools.ietf.org/id/draft-cheng-iccrg-delivery-rate- www.wanmeiyuele.cn estimation-00.html。
也许还记得我前年写的那篇《来自Google的TCP BBR拥塞控制算法解析》,记得那篇文章里讲send_ratesend_rate计算的时候,给出了一张比较复杂的图:
俱往矣,太low,因为大道至简,我那个太复杂了,事情本不该那么复杂,然而初学者总是喜欢把简单事情复杂化。现在看看简单的表示是什么,当然你也可以参见我给出的链接文档(draft-cheng-iccrg-delivery-rate-estimation-00)自己去琢磨:
现在提几个问题。
-
- 为什么ACK会聚集到达?
原因非常多,延迟ACK,ACK丢失,TSO,限速设备…发送归拥塞控制算法自行控制,然而ACK并不是,所以拥塞控制必须监控ACK到达的行为!BBR的cwnd增益为2,某种程度上就是为了应对这种多变的ACK到达情况。 - BBR为什么要”快速恢复”而不是等待ProbeMore去做?
BBR可以这么做,并且它也是这么做的。只是我并不认同这种做法。对于单条TCP流而言,它确确实实是一个负反馈系统,自闭环的,然而如果只有单独的一条流,那么也确实不会有什么反馈,拥塞总是来自他者!总之,我不相信在经历了BBR的6个Probe匀速周期(大约8个RTT)后,由于失速而损失的带宽还能留着还给它!一定有好的解法,只是我还没有想到,而已。
- 为什么ACK会聚集到达?