Data structure alignment (数据结构对齐 / 内存对齐)
开篇的话
-
在比较老的编译器里,如果没有对变量取地址的操作,那么有些局部变量是通过寄存器保存的,不占栈上内存,根本不存在内存中如何排列的问题,比如TurboC 2.0这种。
-
在一些较新的编译器里,局部变量排列顺序并不是从上到下一次排列,有些是根据使用频率来排列的,这样可以降低cache的miss率,所以怎么排列完全根据使用频率。
-
大部分主流编译器的局部变量地址确实是从下到上,但也有反过来的。从下到上排列的好处之一是编译器处理一个函数的时候,可以动态增长栈的长度,不需要先判断局部变量有多少个。
-
还有一些非主流编译器会调整变量的排列次序,使得其在各个变量基本对齐的情况下占用的栈空间最小,对于一些嵌入式设备来说,非常有用。
前言
数据结构对齐是指在计算机内存中排列和访问数据的方式。它包含三个独立但相关的问题:数据对齐(data alignment),数据结构填充( data structure padding)和打包(packing.)。
当数据自然对齐时,现代计算机硬件中的CPU最有效地执行对内存的读写操作,这通常意味着数据的内存地址是数据大小的倍数。
-
读/写总是从word_size的倍数的地址开始的。
-
读/写的长度总是word_size的倍数。
例如,在32位体系结构中,如果数据存储在四个连续字节中并且第一个字节位于4字节边界上,则可以对齐数据。
数据对齐是指根据元素的自然对齐来对齐元素。为了确保自然对齐,可能有必要在结构元素之间或结构的最后一个元素之后插入一些填充。
例如,在32位计算机上,包含16位值和32位值的数据结构可以在16位值和32位值之间具有16位填充以对齐32位在32位边界上的值。,或者,可以打包结构,省略填充 可能会导致访问速度变慢,但其优点是使用的内存只有原来的一半。
在一台64位的计算机上,读取一块1k的内存,CPU需要进行的读取操作次数是:
- 1 k = 1024 b y t e = 1024 ∗ 8 b i t s 1k = 1024 byte = 1024 * 8 bits 1k=1024byte=1024∗8bits
- 1024 ∗ 8 b i t s 64 b i t s / t i m e = 128 t i m e \frac {1024 \ast 8 bits}{ 64 bits/time } = 128 time 64bits/time1024∗8bits=128time
原因
CPU一次通过单个存储字访问存储器。只要存储字大小至少与计算机支持的最大原始数据类型一样大,对齐的访问将始终访问单个存储字。对于未对齐的数据访问,情况可能并非如此。
如果数据中的最高字节和最低字节不在同一存储字中,则计算机必须将数据访问分为多个存储访问。这需要很多复杂的电路来生成内存访问并进行协调。为了处理存储字位于不同存储页面中的情况,处理器必须在执行指令之前验证两个页面均存在,或者必须能够在指令执行过程中处理任何存储器访问中的TLB丢失或页面错误。
一些处理器设计故意避免引入这种复杂性,而是在内存访问未对齐的情况下产生替代行为。例如,ARMv6 ISA之前的ARM体系结构的实现要求对所有多字节加载和存储指令进行强制性对齐内存访问。根据发出的特定指令,尝试进行未对齐访问的结果可能是舍入有问题地址的最低有效位,从而将其转换为对齐访问(有时会有其他警告),或者引发MMU异常( (如果存在MMU硬件),或静默产生其他潜在的不可预测的结果。从ARMv6架构开始,添加了支持以处理许多(但不一定是所有)情况下的未对齐访问。
当访问单个存储字时,该操作是原子的,即一次读取或写入整个存储字,并且其他设备必须等待读取或写入操作完成才能访问它。对于未对齐访问多个存储字可能不是正确的,例如,第一个字可能被一个设备读取,两个字都被另一个设备读取,然后第二个字被第一个设备读取,因此读取的值都不是原始值也不更新值。尽管此类故障很少见,但很难识别。
举例
内存地址不对齐,会引起什么样的问题呢?用一个例子来说明:
-
假定在一台32位机器上,有一个整型变量i的地址是34 ,那i存储在内存的34、35、36、37地址;
-
为了把这个变量从内存读进CPU,由于计算机从内存读取数据的天性(第一点,读/写总是从word_size的倍数的地址开始的),需要两次读取(第一次从32开始读32 33 34 35,第二次从36开始读36 37 38 39),然后把第一次读取的后两个字节(34 35)抽取出来,把第二次读取的前面两个字节(36 37)抽取出来拼到一起组成变量i:
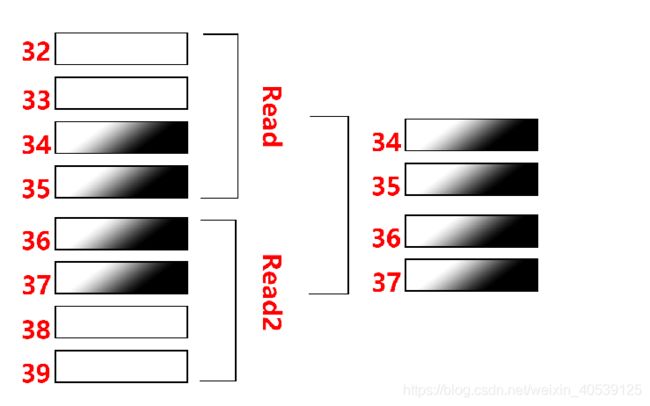
一个int变量为4bytes,即32位,从CPU一次可以读取的内存块长度来看,本可以一次读完;但是因为这个变量的内存块地址没有对齐,将导致本来一个read指令就能完成的读取操作,需要两次read外加其它复杂的抽取拼接计算,从而大大地降低了性能。
看一个实例:
环境:64位系统,Xcode的clang编译器
-
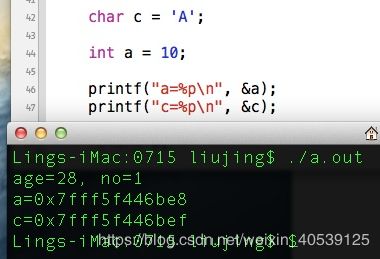
为什么
a与c地址不是间隔4呢?
答: clang编译器按照定义的顺序分配地址,地址是从上往下分配的(由高到低)。所以首先设置好c的地址。接着,a的地址必须是4的整数倍,从c的地址0xef往下,第一个4的整数倍是0xec,但是它们之间只有3个空位,所以没法用。于是a必须再往下找下一个4的整数倍,即0xe8。
注:X86是小端,栈地址的生长方式 (从高地址到低地址) – 即先分配的变量存在高地址,后分配的存在低地址,栈结构中高地址的方向叫做栈底,栈的访问方式是先进后出 -
第一个4的整数倍是0xec,那么为什么整数不是从0xec往小地址内存存呢,如0xeb,0xea, 0xe9, 0xe8呢,而是从0xec, 0xed, 0xef存呢?
答:小端模式,一个局部变量(栈空间)的地址,就是它的占据的几个位置里面值最小的那个(指针指向最低地址的字节)
结构的典型对齐方式
- 数组 :按照基本数据类型对齐,第一个对齐了后面的自然也就对齐了。
- 联合 :按其包含的长度最大的数据类型对齐。
- 结构体: 结构体中每个数据类型都要对齐。
结构字节对齐的原则主要有:
-
数据类型自身的对齐值:char型数据自身对齐值为1字节,short型数据为2字节,int/float型为4字节,double型为8字节 …(操作系统不同可能由偏差)
-
结构体或类的自身对齐值:其成员中自身对齐值最大的那个值。(结构体的每一个成员相对结构体首地址的偏移量应该是对其参数的整数倍,如果不满足则补足前面的字节使其满足)
-
指定对齐值:#pragma pack (value)时的指定对齐值value。
-
数据成员、结构体和类的有效对齐值:自身对齐值和指定对齐值中较小者,即有效对齐值=min{自身对齐值,当前指定的pack值}。
我们直接看例子吧:
typedef struct node1 {
} S1;
typedef struct node2 {
int a;
char b;
short c;
} S2;
typedef struct node3 {
char a;
int b;
short c;
} S3;
typedef struct node4 {
int a;
short b;
static int c; //静态变量单独存放在静态数据区
} S4;
typedef struct node5 {
bool a;
S1 b;
short c;
} S5;
typedef struct node6 {
bool a;
S2 b;
int c;
} S6;
typedef struct node7 {
bool a;
S2 b;
double d;
int c;
} S7;
typedef struct node8 {
bool a;
S2 b;
char* c;
} S8;
- node1为一个空结构体,在C中空结构体的大小为0字节,在C++中空结构体的大小为1字节。
- node2的内存结构:
(4 — 1 — 1(补) — 2),总大小为8字节(结构体的每一个成员相对结构体首地址的偏移量应该是对其参数的整数倍)。 - node3的内存结构:
(1 — 3(补) — 4 — 4),总大小为12字节(结构体的每一个成员相对结构体首地址的偏移量应该是对其参数的整数倍)。 - node4的内存结构:
(4 — 2 — 2(补)),总大小为8字节,注意静态变量被分配到静态数据区,不在sizeof计算的范围内。 - node5的内存结构:
(1 — 1 — 2),总大小为4字节。 - node6的内存结构:
(1 — 3(补) — 8 — 4),总大小为16字节,注意结构体变量的对齐参数的计算。 - node7的内存结构:
(1 — 3(补)— 8 — 4(补) — 8 — 4 — 4(补)),总大小为32字节。 - node8的内存结构:
(1 — 3(补) — 8 — 4),总大小为16字节。
详细分析一下node7,其余的也类似:
#pragma pack(n)为8对于a变量,其对齐参数为1,此时offset=0,可以被1整除,因此为其分配1字节空间;
对于b变量,其对齐参数为4(s2结构体的成员变量最大对齐参数为int => 4),此时offset=1,不能被4整除,因此填充3字节后为其分配8字节空间;
对于d变量,其对齐参数为8,此时offset=12,不能被8整除,因此填充4字节后为其分配8字节空间。
对于c变量,其对齐参数为4,此时offset=24,可以被4整除,因此为其分配4字节空间。此时所有变量都分配完,但此时offset=28,不能被最大对齐参数8整除,因此填充4字节使其可以被8整除。所以最后node7的大小为32字节。
强制指定对齐大小
在缺省情况下,C编译器为每一个变量或是数据单元按其自然对界条件分配空间。一般地,可以通过下面的方法来改变缺省的对界条件:
- 使用伪指令#pragma pack (n),C编译器将按照n个字节对齐。
- 使用伪指令#pragma pack (),取消自定义字节对齐方式。
gcc里还可以使用__attribute__关键字来声明数据类型的对齐方式,优先级高于#pragma预编译指令。
- __attribute((aligned (n))),让所作用的结构成员对齐在n字节自然边界上。如果结构中有成员的长度大于n,则按照最大成员的长度来对齐。
- attribute ((packed)),取消结构在编译过程中的优化对齐,按照实际占用字节数进行对齐。
1. __attribute__方式
struct stu{
char sex;
int length;
char name[10];
}__attribute__ ((aligned (1)));
struct stu my_stu;
此时,sizeof(my_stu)可以得到大小为15。上面的定义等同于:
struct stu{
char sex;
int length;
char name[10];
}__attribute__ ((packed));
struct stu my_stu;
- 当aligned作用于变量时,其作用是告诉编译器为变量分配内存的时候,要分配在指定对其的内存上,作用于变量之上不会改变变量的大小。
例如:int a attribute((aligned(16)));该变量a的内存起始地址为16的倍数。 - 当aligned作用于类型时,其作用是告诉编译器该类型声明的所有变量都要分配在指定对齐的内存上。当该属性作用于结构体声明时可能会改变结构体的大小。
2. pragma方式
声明#pragma可以设置对齐参数的数值,缺省是8字节:
#pragma pack (n) //作用:C编译器将按照n个字节对齐。
#pragma pack () //作用:取消自定义字节对齐方式。
#pragma pack (push,1) //作用:是指把原来对齐方式设置压栈,并设新的对齐方式设置为一个字节对齐
#pragma pack(pop) //作用:恢复对齐状态
#pragma pack(push) //保存对齐状态
#pragma pack(4) //设定为4字节对齐 相当于 #pragma pack (push,4)
3. aligned和pack的主要区别
- pack作用于结构体或类的定义,而aligned既可以作用于结构体或类的定义,也可以作用于变量的声明。
- pack的作用是改变结构体或类中成员变量的布局规则,而aligned只是建议编译器对指定变量或指定类型的变量分配内存时的规则。
- pack可以压缩变量所占内存的空间
- align可以指定变量在内存的对其规则,而pack不可以。
- 若某一个结构体的默认pack为n,pack指定的对齐规则m大于n,则该pack忽略。若aligned指定的对齐规则s大于n,则此时结构体的大小一定为s的整数倍。
- aligned和pack指定规则时都必须为2的n次幂。
参考资料
- Wiki - Data structure alignment
- 知乎 - C语言中连续定义两个变量,为什么地址是这样的?
- 刘煌旭 - 深入理解内存对齐
- linuxsong - C/C++字节对齐详解
- sczyh30 - C/C++ 结构体字节对齐
- 魏传柳 - C语言pack与aligned的区别