mysql 索引的使用之中文全文索引
这里讨论的是 mysql 5.7 InnoDB 全文索引,在mysql 5.6 之前的版本中,myisam 支持全文索引而InnoDB 是不支持的,而且 mysql 全文索引对中文的支持也不太友好,所以一般采用其它方案去替代。一般的替代方案是 sphinx 或者 elasticSearch 。
在mysql 索引使用篇(https://blog.csdn.net/zhang_referee/article/details/83215770) 中说过,类似于 columnName like '%keywords%' 的模糊匹配是很慢的,而且又无法使用到索引。在项目中一般采用其它方案去替代(我之前使用的是elasticSeaarch) 。
先看一下,这里的案例表,索引情况:
mysql> show index from dye_production_schedules;
+--------------------------+------------+--------------------------+--------------+---------------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+--------------------------+------------+--------------------------+--------------+---------------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| dye_production_schedules | 0 | PRIMARY | 1 | id | A | 1708677 | NULL | NULL | | BTREE | | |
| dye_production_schedules | 1 | order_id_order_detail_id | 1 | order_id | A | 9115 | NULL | NULL | | BTREE | | |
| dye_production_schedules | 1 | order_id_order_detail_id | 2 | order_detail_id | A | 1831978 | NULL | NULL | | BTREE | | |
| dye_production_schedules | 1 | dye_factory_id | 1 | dye_factory_id | A | 14141 | NULL | NULL | | BTREE | | |
| dye_production_schedules | 1 | dye_code | 1 | dye_code | A | 1831978 | NULL | NULL | | BTREE | | |
| dye_production_schedules | 1 | order_detail_id | 1 | order_detail_id | A | 95830 | NULL | NULL | | BTREE | | |
| dye_production_schedules | 1 | order_id_batch_num | 1 | order_id | A | 10781 | NULL | NULL | | BTREE | | |
| dye_production_schedules | 1 | order_id_batch_num | 2 | batch_num | A | 1831978 | NULL | NULL | | BTREE | | |
| dye_production_schedules | 1 | customer_color_name | 1 | customer_color_name | NULL | 1831978 | NULL | NULL | | FULLTEXT | | |
+--------------------------+------------+--------------------------+--------------+---------------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
9 rows in set (0.02 sec)可以看到在 custormer_color_name 列上建立了全文索引。不过这里有个坑,后面会说到。
如果看过我之前的 mysql 索引基础篇的文章(https://blog.csdn.net/zhang_referee/article/details/83045903) 就会发现,我在建全文索引的时候埋了个大坑——天真的以为建立了全文索引就能支持中文。结果在写这篇文章的时候,发现explain 分析说使用到了全文索引,但在具体查询某个中文关键词的时候,查询结果出人意外——检索不到想要的数据。后来查资料才知,原来要使用中文全文索引,需要手动指定ngram全文分析器。可以在创建或修改时使用指定 WITH PARSER ngram。
我这里修改执行一下,以下语句即可:
mysql> alter table dye_production_schedules add fulltext(`customer_color_name`) with parser ngram;
Query OK, 0 rows affected (12 min 39.63 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> show create table dye_production_schedules;

ok ,下面就来体验一把强大的 ngram 。在示例表数据中`customer_color_name`列上搜索 '缠绵悱恻' :
mysql> select id,dye_code,customer_color_name from dye_production_schedules where match(`customer_color_name`) against('缠绵悱恻') limit 10;
+------+----------------+-----------------------------------------------------------------------------------------------------------+
| id | dye_code | customer_color_name |
+------+----------------+-----------------------------------------------------------------------------------------------------------+
| 873 | 069d837c01a1ad | pjvwylu5K4到福州一次,有一篇《将离》抒写那回的别恨,是缠绵悱恻的文字。m2BbW |
| 962 | 6fbc2b2e505359 | Mv4mJp27tP朋友拉到福州一次,有一篇《将离》抒写那回的别恨,是缠绵悱恻的0UnbO |
| 1856 | 0b28e88b7d8aed | c7Enqd3xNZ》抒写那回的别恨,是缠绵悱恻的文字。这些日子,我在浙江乱跑,pI8fH |
| 3851 | 72b085dd124bf6 | WEXKPAUkb6恨,是缠绵悱恻的文字。这些日子,我在浙江乱跑,有时到上海小住2DwSv |
| 4004 | 71cd2b3a7aa06c | Wt79irOzTC友拉到福州一次,有一篇《将离》抒写那回的别恨,是缠绵悱恻的文HGAjU |
| 5556 | 8fdef9d7df4774 | MXI3te2VPp《将离》抒写那回的别恨,是缠绵悱恻的文字。这些日子,我在浙江DvlKS |
| 5945 | 09c7ec5af6b589 | rSgWeb5qa8次,有一篇《将离》抒写那回的别恨,是缠绵悱恻的文字。这些日子NO9yX |
| 6258 | ee292e96585a49 | tE8GlNjvDe写那回的别恨,是缠绵悱恻的文字。这些日子,我在浙江乱跑,有时Xsk96 |
| 6548 | 18c869d0bcd38c | XbetqKvrQL回的别恨,是缠绵悱恻的文字。这些日子,我在浙江乱跑,有时到上a9HoY |
| 6741 | 7dade53c7f5001 | 49uHlA3mdh《将离》抒写那回的别恨,是缠绵悱恻的文字。这些日子,我在浙江UVkwS |
+------+----------------+-----------------------------------------------------------------------------------------------------------+
10 rows in set (0.02 sec)
mysql> explain select id,dye_code,customer_color_name from dye_production_schedules where match(`customer_color_name`) against('缠绵悱恻') limit 10 \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: dye_production_schedules
partitions: NULL
type: fulltext
possible_keys: customer_color_name
key: customer_color_name
key_len: 0
ref: const
rows: 1
filtered: 100.00
Extra: Using where; Ft_hints: sorted, limit = 10
1 row in set, 1 warning (0.02 sec)
MySQL内置的全文解析器使用单词之间的空格作为分隔符来确定单词的开始和结束位置,但不适用于中文等语言。为了解决这个问题,MySQL提供了一个支持中文,日文和韩文(CJK)的 ngram 全文解析器。ngram全文解析器支持InnoDB和 MyISAM。
MySQL 5.7.6中引入的ngram全文解析器是一个内置的服务器插件。与其他内置服务器插件一样,它在服务器启动时自动加载。
全文索引相关的配置选项中,除了最小和最大字长选项(innodb_ft_min_token_size, innodb_ft_max_token_size, ft_min_word_len, ft_max_word_len),其它同样适用于ngram。
mysql> select @@innodb_ft_min_token_size;
+----------------------------+
| @@innodb_ft_min_token_size |
+----------------------------+
| 3 |
+----------------------------+
1 row in set (0.00 sec)
mysql> select @@innodb_ft_max_token_size;
+----------------------------+
| @@innodb_ft_max_token_size |
+----------------------------+
| 84 |
+----------------------------+
1 row in set (0.00 sec)
mysql> select @@ft_min_word_len;
+-------------------+
| @@ft_min_word_len |
+-------------------+
| 4 |
+-------------------+
1 row in set (0.00 sec)
mysql> select @@ft_max_word_len;
+-------------------+
| @@ft_max_word_len |
+-------------------+
| 84 |
+-------------------+
1 row in set (0.00 sec)
mysql> select @@ngram_token_size;
+--------------------+
| @@ngram_token_size |
+--------------------+
| 2 |
+--------------------+
1 row in set (0.00 sec)
可见系统默认分词大小为3,而ngram 默认分词大小为2。
还可以使用show_variables like '%ngram%' 来查看其它ngram 相关的系统变量。
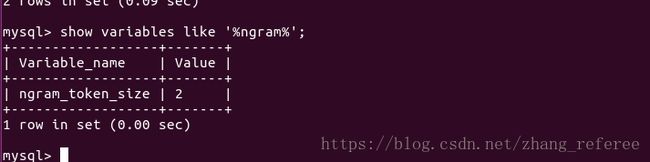
ngram解析器的默认ngram标记大小为2。例如,分词大小为2时,ngram解析器将字符串"缠绵悱恻"解析为: 缠绵,绵悱,悱恻。可以使用ngram_token_size 来配置分词大小,最小值为1,最大值为10。通常,ngram_token_size设置为要搜索的最大分词的大小,如果你想查询到单个字,那么我们需要设置为1。 ngram_token_size的值设置的越小,全文索引占用的空间也越小。一般来说,查询正好等于ngram_token_size的词,速度会更快,但是查询比它更长的词或短语,则会变慢。
ngram分析器停用词处理
内置的MySQL全文解析器将单词与禁用词列表中的条目进行比较。如果单词等于禁用词列表中的条目,则该单词将从索引中排除。对于ngram解析器,以不同方式执行停用词处理。ngram解析器排除包含停用词的符号,而不是排除与禁用词列表中的条目相等的符号。例如,假设 ngram_token_size=2包含“ a,b ”的文档被解析为“ a ” 和“ ,b ”。如果逗号(“ , ”)被定义为停用词,则两者都是“ a ”和“ ,b ”从索引中排除,因为它们包含逗号。默认情况下,ngram解析器使用默认的停用词列表,其中包含英语停用词列表。对于适用于中文,日文或韩文的禁用词列表,必须由我们自己创建(这里大部分来自于mysql英文官方手册翻译)。
看到这里后,我就在想,中文也有很多无意义的词,比如说"的",然后就实验了一把。
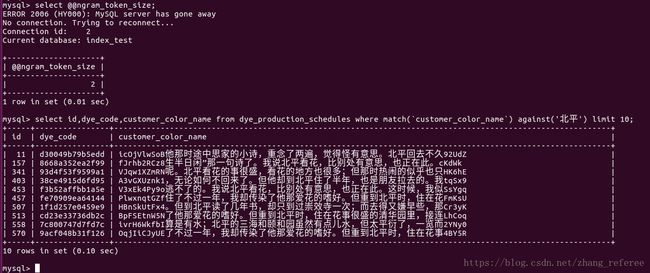
mysql> select sql_no_cache id,dye_code,customer_color_name from dye_production_schedules where `customer_color_name` like '%北平%' limit 10;
+-----+----------------+-----------------------------------------------------------------------------------------------------------+
| id | dye_code | customer_color_name |
+-----+----------------+-----------------------------------------------------------------------------------------------------------+
| 11 | d30049b79b5edd | icOjVlwSoB他那时途中思家的小诗,重念了两遍,觉得怪有意思。北平回去不久92UdZ |
| 157 | 8668a352ea2f99 | fJrhb2RCz8生半日闲”那一句诗了。我说北平看花,比别处有意思,也正在此。cKdWk |
| 341 | 93d4f53f9599a1 | VJqw1XZmRN呢。北平看花的事很盛,看花的地方也很多;但那时热闹的似乎也只HK6hE |
| 403 | 38ce4915d6fd95 | A3vGXUznk1,无论如何不回来了。但他却到北平住了半年,也是朋友拉去的。我tqSx9 |
| 453 | f3b52affbb1a5e | V3xEk4Py9o逃不了的。我说北平看花,比别处有意思,也正在此。这时候,我似SsYgq |
| 457 | fe70909ea64144 | PlwxnqtGZf住了不过一年,我却传染了他那爱花的嗜好。但重到北平时,住在花FmKsU |
| 507 | 1f1d257e0459e9 | HBnSkUtFx4。但到北平读了几年书,却只到过崇效寺一次;而去得又嫌早些,那Cr3yK |
| 513 | cd23e33736db2c | BpFSEtnW5N了他那爱花的嗜好。但重到北平时,住在花事很盛的清华园里,接连LhCoq |
| 558 | 7c800747d7fd7c | ivrH6WkfbI算是有水;北平的三海和颐和园虽然有点儿水,但太平衍了,一览而2YNy0 |
| 570 | 9acf048b31f126 | OqjIiCJyUE了不过一年,我却传染了他那爱花的嗜好。但重到北平时,住在花事4BY5R |
+-----+----------------+-----------------------------------------------------------------------------------------------------------+
10 rows in set, 1 warning (0.02 sec)
mysql> explain select sql_no_cache id,dye_code,customer_color_name from dye_production_schedules where `customer_color_name` like '%北平%' limit 10;
+----+-------------+--------------------------+------------+------+---------------+------+---------+------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------------------------+------------+------+---------------+------+---------+------+---------+----------+-------------+
| 1 | SIMPLE | dye_production_schedules | NULL | ALL | NULL | NULL | NULL | NULL | 1831978 | 11.11 | Using where |
+----+-------------+--------------------------+------------+------+---------------+------+---------+------+---------+----------+-------------+
1 row in set, 2 warnings (0.00 sec)
mysql> explain select id,dye_code,customer_color_name from dye_production_schedules where match(`customer_color_name`) against('的');
+----+-------------+--------------------------+------------+----------+---------------------+---------------------+---------+-------+------+----------+-------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------------------------+------------+----------+---------------------+---------------------+---------+-------+------+----------+-------------------------------+
| 1 | SIMPLE | dye_production_schedules | NULL | fulltext | customer_color_name | customer_color_name | 0 | const | 1 | 100.00 | Using where; Ft_hints: sorted |
+----+-------------+--------------------------+------------+----------+---------------------+---------------------+---------+-------+------+----------+-------------------------------+
1 row in set, 1 warning (0.00 sec)
mysql> select id,dye_code,customer_color_name from dye_production_schedules where match(`customer_color_name`) against('的');
Empty set (0.05 sec)
在上面的栗子中,可以看到,会自动的把"的"这种无用词给过滤掉,所以我们单搜"的"是没有匹配结果的。
这里提下,ngram_token_size 是只读变量,
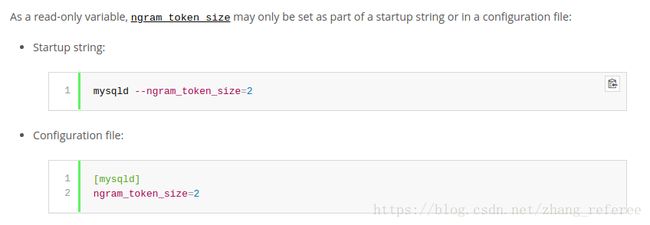
以上截图自mysql 官方手册。
这里说下第二种修改方法,mysql配置文件默认(my.cnf)是没有ngram_token_size这个配置项的,需要自己添加,记得重启mysql.
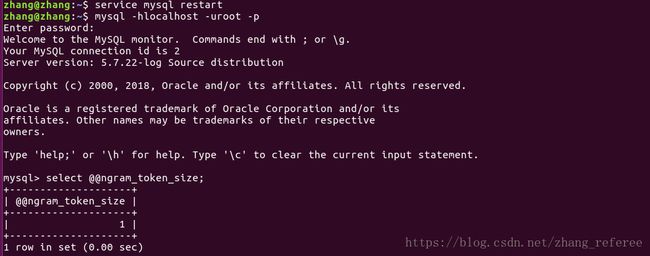
通过将ngram_token_size 这个选项设置为1后发现,上面的查询结果为空。

目测是改ngram_token_size 值是在索引建立后所致。可以建一个表测验一番:
mysql> create table ngram_token_test(
->
-> id int auto_increment,
-> `content` varchar(128) not null default '',
-> primary key(id),
-> fulltext index `content` (`content`) with parser ngram
->
-> )engine = innodb default charset = utf8;
Query OK, 0 rows affected (2.62 sec)
mysql> insert into ngram_token_test(`content`) values
-> ('染色'),
-> ('上海'),
-> ('海山生明月'),
-> ('今夕何夕兮搴洲中流'),
-> ('今日何日兮得与王子同舟'),
-> ('蒙羞被好兮不訾诟耻'),
-> ('心几烦而不绝兮得知王子'),
-> ('山有木兮木有枝'),
-> ('心悦君兮君不知'),
-> ('小木兮子');
Query OK, 10 rows affected (0.16 sec)
Records: 10 Duplicates: 0 Warnings: 0
mysql> select @@ngram_token_size;
+--------------------+
| @@ngram_token_size |
+--------------------+
| 1 |
+--------------------+
1 row in set (0.00 sec)
mysql> select * from ngram_token_test where match(`content`) against('海');
+----+-----------------+
| id | content |
+----+-----------------+
| 2 | 上海 |
| 3 | 海山生明月 |
+----+-----------------+
2 rows in set (0.00 sec)
mysql> select * from ngram_token_test where match(`content`) against('小');
+----+--------------+
| id | content |
+----+--------------+
| 10 | 小木兮子 |
+----+--------------+
1 row in set (0.01 sec)
ok ,果然如猜想那样,如果使用ngram 分词器,修改了 ngram_token_size 这个值后,修改前建立的相关索引需要重建(忽然明白了,为什么是只读变量了)。
OK,然后改回原来的值。
ngram 解析器查询处理
先创建一个示例表:
mysql> create table articles(
->
-> id int auto_increment,
-> `content` varchar(256) not null default '',
-> primary key(id),
-> fulltext index `content` (`content`) WITH PARSER NGRAM
->
-> )engine = innoDB default charset = utf8;
Query OK, 0 rows affected (3.12 sec)
mysql> insert into articles(`content`) values
-> ('计算机信息系统'),
-> ('数据库管理系统'),
-> ('信息的系统'),
-> ('息系'),
-> ('管理系统开发与维护'),
-> ('信息系统'),
-> ('操作系统'),
-> ('作系'),
-> ('系统'),
-> ('mysql 管理从入门到放弃'),
-> ('mysql 管理和维护'),
-> ('笔记本维修'),
-> ('linux 系统维护'),
-> ('管理员的日常'),
-> ('信息挖掘与分析');
Query OK, 15 rows affected (0.12 sec)
Records: 15 Duplicates: 0 Warnings: 0
ngram Parser Term Search
对于自然语言模式搜索,搜索项将转换为ngram项的并集。例如,字符串“ abc ”(假设 ngram_token_size=2)被转换为“ ab bc ”。给定两个文档,一个包含“ ab ”而另一个包含 “ abc ”,搜索词“ ab bc ”匹配两个文档。
对于布尔模式搜索,搜索项将转换为ngram短语搜索。例如,字符串'abc'(假设 ngram_token_size=2)将转换为' “ ab bc ” '。给定两个文档,一个包含'ab'而另一个包含'abc',搜索短语' “ ab bc ” '仅匹配包含'abc'的文档。
自然语言模式:
mysql> select * from articles where match(`content`) against('信息系统' IN NATURAL LANGUAGE MODE);
+----+-----------------------------+
| id | content |
+----+-----------------------------+
| 1 | 计算机信息系统 |
| 6 | 信息系统 |
| 4 | 息系 |
| 3 | 信息的系统 |
| 15 | 信息挖掘与分析 |
| 2 | 数据库管理系统 |
| 5 | 管理系统开发与维护 |
| 7 | 操作系统 |
| 9 | 系统 |
| 13 | linux 系统维护 |
+----+-----------------------------+
10 rows in set (0.00 sec)
布尔模式:
mysql> select * from articles where match(`content`) against('信息系统' IN BOOLEAN MODE);
+----+-----------------------+
| id | content |
+----+-----------------------+
| 1 | 计算机信息系统 |
| 6 | 信息系统 |
+----+-----------------------+
2 rows in set (0.00 sec)
ngram Parser通配符搜索
如果通配符搜索的前缀符号小于ngram分词大小,则查询将返回包含以该符号开头的ngram的所有索引行。例如,假设 ngram_token_size=2搜索“ a * ”将返回以“ a ”开头的所有行 。
如果通配符搜索的前缀符号大于等于ngram分词大小,则该查询将转换为ngram短语,并忽略通配符运算符。例如,假定 ngram_token_size=2,一个 “ ABC * ”通配符搜索被转换为 “ AB BC ”。
mysql> select * from articles where match(`content`) against('信*' IN BOOLEAN MODE);
+----+-----------------------+
| id | content |
+----+-----------------------+
| 1 | 计算机信息系统 |
| 3 | 信息的系统 |
| 6 | 信息系统 |
| 15 | 信息挖掘与分析 |
+----+-----------------------+
4 rows in set (0.00 sec)
mysql> select * from articles where match(`content`) against('信息系*' IN BOOLEAN MODE);
+----+-----------------------+
| id | content |
+----+-----------------------+
| 1 | 计算机信息系统 |
| 6 | 信息系统 |
+----+-----------------------+
2 rows in set (0.01 sec)
ngram Parser短语搜索
短语搜索转换为ngram短语搜索。例如,搜索短语“ abc ”被转换为 “ ab bc ”,其返回包含“ abc ”和“ ab bc ”的文档 。
搜索短语“ abc def ”被转换为 “ ab bc de ef ”,其返回包含“ abc def ”和“ ab bc de ef ”的文档 。不返回包含“ abcdef ”的文档。
mysql> insert into articles(`content`) values
-> ('管理--新增'),
-> ('理维'),
-> ('维护'),
-> ('管理维护');
Query OK, 4 rows affected (0.10 sec)
Records: 4 Duplicates: 0 Warnings: 0
mysql> select * from articles where match(`content`) against('管理维护' IN BOOLEAN MODE);
+----+--------------+
| id | content |
+----+--------------+
| 19 | 管理维护 |
+----+--------------+
1 row in set (0.00 sec)
mysql> select * from articles where match(`content`) against('管理的维护' IN BOOLEAN MODE);
Empty set (0.00 sec)
mysql> select * from articles where match(`content`) against('管理 维护 ' IN BOOLEAN MODE);
+----+--------------------------------+
| id | content |
+----+--------------------------------+
| 5 | 管理系统开发与维护 |
| 11 | mysql 管理和维护 |
| 19 | 管理维护 |
| 13 | linux 系统维护 |
| 18 | 维护 |
| 2 | 数据库管理系统 |
| 10 | mysql 管理从入门到放弃 |
| 14 | 管理员的日常 |
| 16 | 管理--新增 |
+----+--------------------------------+
9 rows in set (0.00 sec)
由于官方文档全为英文,加之本人英文水平有限,有些感觉不好翻译的地方直接上了英文,与其瞎翻译误导人,不如保持原汁原味。
本文参考自:
mysql 官方手册 : https://dev.mysql.com/doc/refman/5.7/en/fulltext-search-ngram.html
这里推荐这篇文章:http://www.cnblogs.com/zhoujinyi/p/5643408.html ,在写到后半部分的时候,有参考到,感觉写的很不错。