SQL习题集_详细注释版答案
目录
一、准备工作
二、MySQL语句执行顺序
三、题目
四、附录
一、准备工作
1 环境
MySQL 5.7.28 + Ubuntu18.04.4
2 登录MySQL
-- Terminal下输入
mysql -uroot -p3 数据库操作
-- 创建数据库 practice
-- character set 用来指定编码格式,方便之后插入中文
create database practice character set utf8;
-- 查看数据库
show databases like 'practice';
-- 选择数据库
use pratice;4 创建数据表
4.1 Student表(sid 学生编号,sname 学生姓名,sage 出生年月,ssex 学生性别)
-- default charset指定编码格式
create table Student(sid varchar(10), sname varchar(10), sbirthday date, ssex varchar(10)) default charset = utf8;
insert into Student values('01' , '赵雷' , '1990-01-01' , '男');
insert into Student values('02' , '钱电' , '1990-12-21' , '男');
insert into Student values('03' , '孙风' , '1990-12-20' , '男');
insert into Student values('04' , '李云' , '1990-12-06' , '男');
insert into Student values('05' , '周梅' , '1991-12-01' , '女');
insert into Student values('06' , '吴兰' , '1992-01-01' , '女');
insert into Student values('07' , '郑竹' , '1989-01-01' , '女');
insert into Student values('09' , '张三' , '2017-12-20' , '女');
insert into Student values('10' , '李四' , '2017-12-25' , '女');
insert into Student values('11' , '李四' , '2012-06-06' , '女');
insert into Student values('12' , '赵六' , '2013-06-13' , '女');
insert into Student values('13' , '孙七' , '2014-06-01' , '女');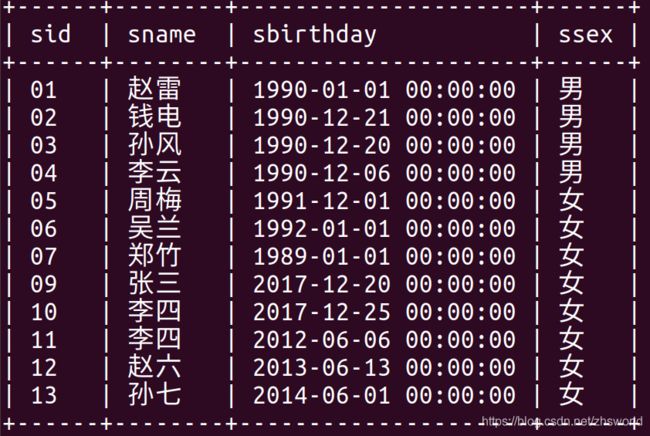
4.2 修改数据库、数据表、字段编码
insert into Student values('01' , '赵雷' , '1990-01-01' , '男');
-- 如果创建数据库或数据表时没有指定编码,则会提示如下错误:
ERROR 1366 (HY000): Incorrect string value: '\xE8\xB5\xB5\xE9\x9B\xB7' for column 'sname' at row 1
-- Incorrect string value 不正确的字符串,定位到是中文编码的问题查看和修改数据库编码
-- 查看数据库编码
show variables like 'character_set_database';
-- 查看数据表编码
-- show create table <表名>;
show create table Student;
-- 修改数据库编码
-- alter database <数据库名> character set utf8;
alter database pratice character set utf8;
-- 修改数据表编码
-- alter table <表名> character set utf8;
alter table Student character set utf8;
-- 修改字段编码
-- alter table <表名> change <字段名> <字段名> <类型> character set utf8;
alter table Student change sname sname varchar(10) character set utf8;
alter table Student change ssex ssex varchar(10) character set utf8;4.3 Course表(cId 课程编号,cname 课程名称,tid 教师编号)
create table Course(cid varchar(10), cname nvarchar(10),tid varchar(10)) default charset = utf8;
insert into Course values('01' , '语文' , '02');
insert into Course values('02' , '数学' , '01');
insert into Course values('03' , '英语' , '03');
4.4 Teacher表(tid 教师编号,tname 教师姓名)
create table Teacher(tid varchar(10), tname varchar(10)) default charset = utf8;
insert into Teacher values('01' , '张三');
insert into Teacher values('02' , '李四');
insert into Teacher values('03' , '王五');

4.5 SC表(sid 学生编号,cid 课程编号,score 分数)
-- decimal(M,D) 数据类型用于要求非常高的精确计算中
-- M 指定小数点左边和右边可以存储的十进制数字的最大个数,最大精度为38
-- D 指定小数点右边可以存储的十进制数字的最大个数。小数位数必须是从0~M之间的值,默认小数位数是0.
-- decimal(5,2) 规定了存储的值将不会超过五位数字 ,而且小数点后面有两位数字。
create table SC(sid varchar(10),cid varchar(10), score decimal(18,1)) default charset = utf8;
insert into SC values('01' , '01' , 80);
insert into SC values('01' , '02' , 90);
insert into SC values('01' , '03' , 99);
insert into SC values('02' , '01' , 70);
insert into SC values('02' , '02' , 60);
insert into SC values('02' , '03' , 80);
insert into SC values('03' , '01' , 80);
insert into SC values('03' , '02' , 80);
insert into SC values('03' , '03' , 80);
insert into SC values('04' , '01' , 50);
insert into SC values('04' , '02' , 30);
insert into SC values('04' , '03' , 20);
insert into SC values('05' , '01' , 76);
insert into SC values('05' , '02' , 87);
insert into SC values('06' , '01' , 31);
insert into SC values('06' , '03' , 34);
insert into SC values('07' , '02' , 89);
insert into SC values('07' , '03' , 98);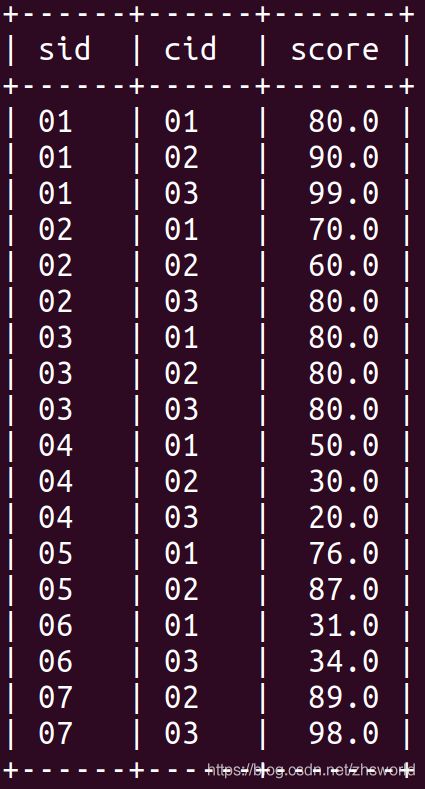
二、MySQL语句执行顺序
(1) FROM
(2) ON
(3) JOIN
(4) WHERE
(5) GROUP BY
(6) HAVING
(7) SELECT
(8) DISTINCT
(9) ORDER BY
(10) LIMIT
三、题目
官方文档:https://dev.mysql.com/doc/refman/5.7/en/func-op-summary-ref.html
在网传50题的基础上,删除了10道冗余的,最终保留了40道
1 查询" 01 "课程比" 02 "课程成绩高的学生的信息及课程成绩
-- 方法一
-- 构建01课程子表和02课程子表筛选出01课程比02课程成绩高的学生,然后再跟Student表进行连接
select Student.*, socre_01, socre_02 from
(select * from
(select sid as sid_01, score as socre_01 from SC where cid = '01') A
left join
(select sid as sid_02, score as socre_02 from SC where cid = '02') B
on A.sid_01 = B.sid_02
where socre_01 > socre_02) C
left join Student
on C.sid_01 = Student.sid;
-- 方法二
-- 构建01课程子表、02课程子表,并与Student表进行连接,然后再进行相应的筛选
select s.*, a.score as score_01, b.score as score_02
from Student s,
(select sid, score from SC where cid=01) a,
(select sid, score from SC where cid=02) b
where a.sid = b.sid and a.score > b.score and s.sid = a.sid;
+------+--------+------------+------+----------+----------+
| sid | sname | sbirthday | ssex | socre_01 | socre_02 |
+------+--------+------------+------+----------+----------+
| 02 | 钱电 | 1990-12-21 | 男 | 70.0 | 60.0 |
| 04 | 李云 | 1990-12-06 | 男 | 50.0 | 30.0 |
+------+--------+------------+------+----------+----------+交叉连接
select * from A, B, C
假设表A有5条记录,表B有6条记录,表C有7条记录,则会生成 5*6*7=210 条记录(笛卡尔积)
2 查询同时存在" 01 "课程成绩和" 02 "课程成绩的学生信息及课程分数
select * from
(select sid, score from SC where cid=01) A,
(select sid, score from SC where cid=02) B
where A.sid = B.sid;
+------+-------+------+-------+
| sid | score | sid | score |
+------+-------+------+-------+
| 01 | 80.0 | 01 | 90.0 |
| 02 | 70.0 | 02 | 60.0 |
| 03 | 80.0 | 03 | 80.0 |
| 04 | 50.0 | 04 | 30.0 |
| 05 | 76.0 | 05 | 87.0 |
+------+-------+------+-------+3 查询存在" 01 "课程成绩但可能不存在" 02 "课程成绩的学生ID(不存在时显示为 null )
select * from
(select sid as sid_01 from SC where cid=01) A
left join
(select sid as sid_02 from SC where cid=02) B
on A.sid_01 = B.sid_02;
+--------+--------+
| sid_01 | sid_02 |
+--------+--------+
| 01 | 01 |
| 02 | 02 |
| 03 | 03 |
| 04 | 04 |
| 05 | 05 |
| 06 | NULL |
+--------+--------+4 查询存在" 01 "课程成绩但不存在" 02 "课程成绩的学生ID
select * from
(select sid as sid_01 from SC where cid=01) A
left join
(select sid as sid_02 from SC where cid=02) B
on A.sid_01 = B.sid_02
where sid_02 is NULL;
+--------+--------+
| sid_01 | sid_02 |
+--------+--------+
| 06 | NULL |
+--------+--------+5 查询平均成绩大于等于 60 分的同学的学生编号和学生姓名和平均成绩
-- 先再SC表中筛选出平均分大于60的sid,然后跟Student表的sname链接
select A.sid, Student.sname, A.score_avg from
(select sid, avg(score) as score_avg from SC
group by sid
having score_avg > 60) A
left join
Student
on A.sid = Student.sid;
+------+--------+-----------+
| sid | sname | score_avg |
+------+--------+-----------+
| 01 | 赵雷 | 89.66667 |
| 02 | 钱电 | 70.00000 |
| 03 | 孙风 | 80.00000 |
| 05 | 周梅 | 81.50000 |
| 07 | 郑竹 | 93.50000 |
+------+--------+-----------+6 查询在 SC 表存在成绩的学生信息
select distinct Student.*
from Student, SC
where Student.sid = SC.sid;
+------+--------+------------+------+
| sid | sname | sbirthday | ssex |
+------+--------+------------+------+
| 01 | 赵雷 | 1990-01-01 | 男 |
| 02 | 钱电 | 1990-12-21 | 男 |
| 03 | 孙风 | 1990-12-20 | 男 |
| 04 | 李云 | 1990-12-06 | 男 |
| 05 | 周梅 | 1991-12-01 | 女 |
| 06 | 吴兰 | 1992-01-01 | 女 |
| 07 | 郑竹 | 1989-01-01 | 女 |
+------+--------+------------+------+7 查询所有同学的学生编号、学生姓名、选课总数、所有课程的总成绩(没成绩的显示为 null )
select Student.sid, Student.sname, A.course_num, A.score_sum from Student
left join
(select sid, count(*) as course_num, sum(score) as score_sum from SC group by sid) A
on Student.sid = A.sid
+------+--------+------------+-----------+
| sid | sname | course_num | score_sum |
+------+--------+------------+-----------+
| 01 | 赵雷 | 3 | 269.0 |
| 02 | 钱电 | 3 | 210.0 |
| 03 | 孙风 | 3 | 240.0 |
| 04 | 李云 | 3 | 100.0 |
| 05 | 周梅 | 2 | 163.0 |
| 06 | 吴兰 | 2 | 65.0 |
| 07 | 郑竹 | 2 | 187.0 |
| 09 | 张三 | NULL | NULL |
| 10 | 李四 | NULL | NULL |
| 11 | 李四 | NULL | NULL |
| 12 | 赵六 | NULL | NULL |
| 13 | 孙七 | NULL | NULL |
+------+--------+------------+-----------+8 查询所有学生的成绩(每科成绩是一列),也就是交叉表
select sid,
max(case when cid='01' then score else "" end) as "cid_01",
max(case when cid='02' then score else "" end) as "cid_02",
max(case when cid='03' then score else "" end) as "cid_03"
from SC
group by sid;
+------+--------+--------+--------+
| sid | cid_01 | cid_02 | cid_03 |
+------+--------+--------+--------+
| 01 | 80.0 | 90.0 | 99.0 |
| 02 | 70.0 | 60.0 | 80.0 |
| 03 | 80.0 | 80.0 | 80.0 |
| 04 | 50.0 | 30.0 | 20.0 |
| 05 | 76.0 | 87.0 | |
| 06 | 31.0 | | 34.0 |
| 07 | | 89.0 | 98.0 |
+------+--------+--------+--------+9 查询「李」姓老师的数量
select count(*) from Teacher
where tname like "李%";
+----------+
| count(*) |
+----------+
| 1 |
+----------+10 查询学过「张三」老师授课的同学的信息
-- 先在Teacher表找到张三老师的tid,之后跟Course表连接获取张三老师tid的所有课程,再然后跟SC表连接
-- 方法一,主要基于left join on
select SC.* from SC
left join
(select Course.* from
(select distinct tid from Teacher
where tname = "张三") A
left join
Course
on A.tid = Course.tid)B
on SC.cid = B.cid
where tid is not null;
-- 方法二,主要基于where in
select SC.* from SC
where cid in
(select cid from Course
where tid = (select distinct tid from Teacher
where tname = "张三"));
+------+------+-------+
| sid | cid | score |
+------+------+-------+
| 01 | 02 | 90.0 |
| 02 | 02 | 60.0 |
| 03 | 02 | 80.0 |
| 04 | 02 | 30.0 |
| 05 | 02 | 87.0 |
| 07 | 02 | 89.0 |
+------+------+-------+IN (value,...)Returns 1 (true) if expr is equal to any of the values in the IN() list, else returns 0 (false).
left_values IN() right_values returns NULL not only if the expression on the left hand side is NULL, but also if no match is found in the list and one of the expressions in the list is NULL.
sql中任意!=null的运算结果都是false当左表比右表数据量大时,in()效率更高,因为in()会遍历右表数据.;当左表比右表数据量小的时候,exists()效率更高,因为exists()会执行左表length次
11 查询没有学全所有课程的同学的信息
-- 方法一
-- 先查看总课程数,计算每个学生上的课程数,再筛选学的课程数<课程总数的同学
select Student.sid, ifnull(A.cid_num,0) as num from Student
left join
(select sid, count(*) as cid_num from SC group by sid) A
on Student.sid = A.sid
where ifnull(A.cid_num,0) <
(select count(distinct cid) as cid_num from Course);
-- 方法二
-- 先计算每个学生的课程数(读1门和没读过的,均是1),然后筛选学的课程数<课程总数的同学
select Student.sid, count(SC.cid) as num from Student
left join SC
on Student.sid = SC.sid
group by Student.sid
having count(SC.cid) < (select count(distinct cid) from Course);
+------+-----+
| sid | num |
+------+-----+
| 05 | 2 |
| 06 | 2 |
| 07 | 2 |
| 09 | 0 |
| 10 | 0 |
| 11 | 0 |
| 12 | 0 |
| 13 | 0 |
+------+-----+ifnull(expression, alt_value)
ifnull() 函数用于判断第一个表达式是否为 NULL,如果为 NULL 则返回第二个参数的值,如果不为 NULL 则返回第一个参数的值
12 查询至少有一门课与学号为" 01 "的同学所学相同的同学的信息
-- 方法一
-- 先用SC表查看01同学学的所有课程,再看学过这些课程的所有sid,最后跟Student进行连接补充信息
select Student.* from
(select distinct(sid) from SC
where cid in
(select cid from SC where sid = '01')) A
left join
Student
on A.sid = Student.sid;
-- 方法二
-- 思路跟上边一致,只不过这里是 where in 一层一层套
select * from Student
where Student.sid in(
select SC.sid from SC where SC.cid in
(select SC.cid from SC where SC.sid = '01'));
+------+--------+------------+------+
| sid | sname | sbirthday | ssex |
+------+--------+------------+------+
| 01 | 赵雷 | 1990-01-01 | 男 |
| 02 | 钱电 | 1990-12-21 | 男 |
| 03 | 孙风 | 1990-12-20 | 男 |
| 04 | 李云 | 1990-12-06 | 男 |
| 05 | 周梅 | 1991-12-01 | 女 |
| 06 | 吴兰 | 1992-01-01 | 女 |
| 07 | 郑竹 | 1989-01-01 | 女 |
+------+--------+------------+------+13 查询和" 01 "号的同学学习的课程 完全相同的其他同学的信息
-- 把每个人的课程数都罗列出来,然后合并字符串,找到跟01同学的课程字符串相同的人(排除01同学)
-- 方法一 case when
select sid,
concat(max(case when cid='01' then cid else "" end),max(case when cid='02' then cid else "" end),max(case when cid='03' then cid else "" end) ) as cids
from SC
group by sid
having cids =
(select
concat(max(case when cid='01' then cid else "" end),max(case when cid='02' then cid else "" end),max(case when cid='03' then cid else "" end) ) as cids
from SC
group by sid
having sid = "01") and sid <> "01";
+------+--------+
| sid | cids |
+------+--------+
| 02 | 010203 |
| 03 | 010203 |
| 04 | 010203 |
+------+--------+
-- 方法二 group_concat
-- 注意order by 的使用,以保证合并字符串的顺序一致
select sid, group_concat(cid order by cid) as cids
from SC
group by sid
having cids =
(select group_concat(cid order by cid) as cids
from SC
group by sid
having sid = "01") and sid <> "01";
+------+----------+
| sid | cids |
+------+----------+
| 02 | 01,02,03 |
| 03 | 01,02,03 |
| 04 | 01,02,03 |
+------+----------+
-- 实际工作中,可以直接手动构造01同学的课程字符串,从而简化SQL语句
-- 如果提前预探索数据的时候,发现01同学学习了全部三门课程,也可以简化SQL语句
https://dev.mysql.com/doc/refman/5.7/en/group-by-functions.html#function_group-concat
GROUP_CONCAT([DISTINCT] expr [,expr ...] [ORDER BY {unsigned_integer | col_name | expr} [ASC | DESC] [,col_name ...]] [SEPARATOR str_val])This function returns a string result with the concatenated non-NULL values from a group.
It returns NULL if there are no non-NULL values.
https://dev.mysql.com/doc/refman/5.7/en/control-flow-functions.html#operator_case
CASE WHEN [condition] THEN result [WHEN [condition] THEN result ...] [ELSE result] END类似于javascript中的 switch,python中的 if...elif...else
14 查询没学过"张三"老师讲授的任一门课程的学生姓名
-- 先在Teacher表找到张三老师对应的tid, 再通过Course表找到其讲授的课程
-- 再通过SC表筛选出学过这些课的学生的sid,最后再通过Student表排除学过些sid,并匹配sname
select distinct(sname) from Student
where sid not in
(select distinct(sid) from SC
where cid in
(select distinct(cid) from Course
where tid in
(select distinct(tid) from Teacher where tname = "张三")));
+--------+
| sname |
+--------+
| 吴兰 |
| 张三 |
| 李四 |
| 赵六 |
| 孙七 |
+--------+15 查询两门及其以上不及格课程的同学的学号,姓名及其平均成绩
-- 方法一
-- 先在SC表中把不及格的成绩都筛选出来,然后统计超过两门课程不及格的同学的学号,通过Student关联同学姓名
-- 最后跟平均成绩Join
select A.sid, A.sname, B.score_avg from
(select * from Student
where sid in
(select sid from SC
where score < 60
group by sid
having count(*) > 1))A
left join
(select sid,avg(score) as score_avg from SC
group by sid) B
on A.sid = B.sid;
-- 方法二
-- 先整一张大表把所有信息放进去,然后再按照条件筛选
select Student.sid, Student.sname, AVG(SC.score) from Student,SC
where Student.sid = SC.sid and SC.score<60
group by SC.sid
having count(*)>1;
+------+--------+---------------+
| sid | sname | AVG(SC.score) |
+------+--------+---------------+
| 04 | 李云 | 33.33333 |
| 06 | 吴兰 | 32.50000 |
+------+--------+---------------+16 检索" 01 "课程分数小于 60,按" 01 "课程分数降序排列的学生信息
select Student.sname,A.* from Student
right join
(select sid,score from SC
where score < 60 and cid = '01'
order by score desc) A
on Student.sid = A.sid;
+--------+------+-------+
| sname | sid | score |
+--------+------+-------+
| 李云 | 04 | 50.0 |
| 吴兰 | 06 | 31.0 |
+--------+------+-------+17 按平均成绩从高到低显示所有学生的所有课程的成绩以及平均成绩
-- 利用case when将一列变成多列
select sid, avg(score) as score_avg,
max(case when cid = '01' then score else "" end) as score_01,
max(case when cid = '02' then score else "" end) as score_02,
max(case when cid = '03' then score else "" end) as score_03
from SC
group by sid
order by avg(score) desc;
+------+-----------+----------+----------+----------+
| sid | score_avg | score_01 | score_02 | score_03 |
+------+-----------+----------+----------+----------+
| 07 | 93.50000 | | 89.0 | 98.0 |
| 01 | 89.66667 | 80.0 | 90.0 | 99.0 |
| 05 | 81.50000 | 76.0 | 87.0 | |
| 03 | 80.00000 | 80.0 | 80.0 | 80.0 |
| 02 | 70.00000 | 70.0 | 60.0 | 80.0 |
| 04 | 33.33333 | 50.0 | 30.0 | 20.0 |
| 06 | 32.50000 | 31.0 | | 34.0 |
+------+-----------+----------+----------+----------+18 查询各科成绩的最高分,最低分,平均分,及格率,中等率,优良率,优秀率,以及科目名称,选修人数
查询结果按人数降序排列,若人数相同,按课程号升序排列
及格为>=60,中等为:70-80,优良为:80-90,优秀为:>=90
select Course.cname, A.* from
(select cid, count(*) as "人数",max(score) as "最高分" , min(score) as "最低分", round (avg(score),1) as "平均分",
concat(round(sum(case when score >= 60 then 1 else 0 end)/count(*)*100,1 ),"%")as "及格率",
sum(case when score >= 70 and score <= 80 then 1 else 0 end)/count(*) as "中等率",
sum(case when score >= 80 and score <= 90 then 1 else 0 end)/count(*) as "优良率",
sum(case when score >= 90 then 1 else 0 end)/count(*) as "优秀率"
from SC
group by cid
order by count(*) desc) A
left join Course on A.cid = Course.cid
order by cid;
+--------+------+--------+-----------+-----------+-----------+-----------+-----------+-----------+-----------+
| cname | cid | 人数 | 最高分 | 最低分 | 平均分 | 及格率 | 中等率 | 优良率 | 优秀率 |
+--------+------+--------+-----------+-----------+-----------+-----------+-----------+-----------+-----------+
| 语文 | 01 | 6 | 80.0 | 31.0 | 64.5 | 66.7% | 0.6667 | 0.3333 | 0.0000 |
| 数学 | 02 | 6 | 90.0 | 30.0 | 72.7 | 83.3% | 0.1667 | 0.6667 | 0.1667 |
| 英语 | 03 | 6 | 99.0 | 20.0 | 68.5 | 66.7% | 0.3333 | 0.3333 | 0.3333 |
+--------+------+--------+-----------+-----------+-----------+-----------+-----------+-----------+-----------+19 把所有的成绩按降序排序,并显示排名
排序种类1:相同的值,排名不一致,也就是说没有重复名次
排序种类2:相同的值,排名一致,且名次没有空位
排序种类3:相同的值,排名一致,且名次有空位
-- 用户变量
-- 赋值
-- 第一种用法,使用set时可以用“=”或“:=”两种赋值符号赋值
set @age=19;
set @age:=20;
-- 第二种用法,使用select时必须用“:=”赋值符号赋值
select @age:=22;
-- 取值
select @age-- 相同的值,排名不一致,也就是说没有重复名次
-- 类似于Hive和MySQL 8.0的row_number()
-- (select @help :=0) A 构建一个一行一列的表,表的别名是A
-- 因为非原始表需要一个显式的别名,所以写了A,也可随意换成其它别名
-- select * from SC, A 构建一个SC和A的交叉表
-- 尝试把()里的select换成set是会报错,因为set只能设置值
-- @help := @help+1 就类似于 x = x + 1 ,也就类似于自增列
-- 看起来有多少行用户变量的赋值就执行多少遍,但原理是啥,暂时未解
-- 看起来 @help := @help+1的赋值操作是在排序后执行的
select SC.score, @help := @help+1 as s_row_number
from SC,(select @help :=0) A
ORDER BY score DESC;
+-------+--------------+
| score | s_row_number |
+-------+--------------+
| 99.0 | 1 |
| 98.0 | 2 |
| 90.0 | 3 |
| 89.0 | 4 |
| 87.0 | 5 |
| 80.0 | 6 |
| 80.0 | 7 |
| 80.0 | 8 |
| 80.0 | 9 |
| 80.0 | 10 |
| 76.0 | 11 |
| 70.0 | 12 |
| 60.0 | 13 |
| 50.0 | 14 |
| 34.0 | 15 |
| 31.0 | 16 |
| 30.0 | 17 |
| 20.0 | 18 |
+-------+--------------+
------------------------------------------------------------------
-- 相同的值,排名一致,且名次没有空位
-- 类似于Hive 和 MySQL 8.0的dense_rank()
-- 没有考虑score是NULL,空""等异常情况
-- 可能是因为,case when中有用户变量,所以是在最后执行的,具体原理待解
-- case语句的执行是
-- (select @help_0 :=0,@help_null :=NULL) A 构一个一行两列的表
-- 第一次执行到hen @help_null = score时,因为help_null是NULL,而NULL跟任何比较都是NULL,所以会跳过这个when分支,进入到下一个when分支
-- when @help_null := score 是一个赋值操作,score是正常数值的时候的时候,肯定是真,所以会执行该语句,
-- 且@help_0 :=@help_0+1 也会执行,即@help_0自增1
-- 第二次执行到when @help_null = score时,其实是在比较第一次获取的score值跟这次的值是否相等,相等的话help_0不变,即排序一样
-- 循环往复
-- NULL任何值比较均是NULL,注意任何值和比较的含义,包括NULL=NULL这种情况
-- order by排序的时候,如果存在NULL值,那么NULL是最小的;空""是仅次于NULL的小
-- score为非正常值的情况可以在外边再加一层表解决
select SC.score,
case when @help_null = score then @help_0
when @help_null := score then @help_0 :=@help_0+1 END as s_dense_rank
from SC,(select @help_0 :=0,@help_null :=NULL) A
ORDER BY score DESC;
+-------+--------------+
| score | s_dense_rank |
+-------+--------------+
| 99.0 | 1 |
| 98.0 | 2 |
| 90.0 | 3 |
| 89.0 | 4 |
| 87.0 | 5 |
| 80.0 | 6 |
| 80.0 | 6 |
| 80.0 | 6 |
| 80.0 | 6 |
| 80.0 | 6 |
| 76.0 | 7 |
| 70.0 | 8 |
| 60.0 | 9 |
| 50.0 | 10 |
| 34.0 | 11 |
| 31.0 | 12 |
| 30.0 | 13 |
| 20.0 | 14 |
+-------+--------------+
------------------------------------------------------------------
-- 相同的值,排名一致,且名次有空位
-- 类似于Hive 和 MySQL 8.0的rank()
-- 因为s_row_number字段依赖于s_rank字段的help_0_2,所以不能更换s_row_number和s_rank的位置,否则会出错
-- 尽量别这么写,因为官方文档里说,不保证一定是先执行@help_0_2 :=@help_0_2 + 1 as s_row_number,再执行@help_0_1 := case when……
-- 详见https://mp.csdn.net/console/editor/html/104541212
-- 第一次执行完@help_0_2 :=@help_0_2 + 1之后,@help_0_2变成了1
-- 第一次执行到hen @help_null = score时,因为help_null是NULL,而NULL跟任何比较都是NULL,所以会跳过这个when分支,进入到下一个when分支
-- when @help_null := score 是一个赋值操作,score是正常数值的时候的时候,肯定是真,所以会执行该语句,
-- then之后也会被执行,@help_0_1 会被赋值@help_0_2的值也就是1
-- 第二次执行到when @help_null = score时,其实是在比较第一次获取的score值跟这次的值是否相等,相等的话,就会取上次的help_0_1值
-- 如果相等就会取help_0_2的值,也就是row_number
select SC.score,
@help_0_2 :=@help_0_2 + 1 as s_row_number,
@help_0_1 := case when @help_null = score then @help_0_1
when @help_null := score then @help_0_2 END as s_rank
from SC,(select @help_0_1 := 0, @help_0_2 := 0, @help_null := NULL) A
ORDER BY score DESC;
+-------+--------------+--------+
| score | s_row_number | s_rank |
+-------+--------------+--------+
| 99.0 | 1 | 1 |
| 98.0 | 2 | 2 |
| 90.0 | 3 | 3 |
| 89.0 | 4 | 4 |
| 87.0 | 5 | 5 |
| 80.0 | 6 | 6 |
| 80.0 | 7 | 6 |
| 80.0 | 8 | 6 |
| 80.0 | 9 | 6 |
| 80.0 | 10 | 6 |
| 76.0 | 11 | 11 |
| 70.0 | 12 | 12 |
| 60.0 | 13 | 13 |
| 50.0 | 14 | 14 |
| 34.0 | 15 | 15 |
| 31.0 | 16 | 16 |
| 30.0 | 17 | 17 |
| 20.0 | 18 | 18 |
+-------+--------------+--------+ps:我也是蛋疼,花时间在上边
-- 实现第三种排序的另一种思路
-- select count(*) from SC as A where A.score > SC.score
-- 如上语句的意思是统计SC表里边,比自身score大的行数有几行
-- 如果有2行,那排序就是+1,也就是3
select SC.*, (
select count(*) from SC as A where A.score > SC.score
) +1 as s_rank
from SC
order by SC.score DESC;20 统计各科成绩各分数段人数:课程编号,课程名称,[100-85],[85-70],[70-60],[60-0]及所占百分比
-- 考虑到重复工作,其它列就不写%了
select Course.cname, A.*
from Course
left join
(select cid,
-- 也可以用count(case when score between 85 and 100 then "100-85" end) as "100-85"
count(case when score>=85 and score<100 then "100-85" end) as "100-85",
count(case when score>=85 and score<100 then "100-85" end)/count(*) as "100-85_占比",
concat(round(count(case when score>=85 and score<100 then "100-85" end)/count(*)*100,1),"%") as "100-85_%",
count(case when score>=70 and score<85 then "100-85" end) as "85-70",
count(case when score>=60 and score<70 then "100-85" end) as "70-60",
count(case when score<60 then "100-85" end) as "60-0"
from SC
group by cid) A
on Course.cid = A.cid;
+--------+------+--------+---------------+----------+-------+-------+------+
| cname | cid | 100-85 | 100-85_占比 | 100-85_% | 85-70 | 70-60 | 60-0 |
+--------+------+--------+---------------+----------+-------+-------+------+
| 语文 | 01 | 0 | 0.0000 | 0.0% | 4 | 0 | 2 |
| 数学 | 02 | 3 | 0.5000 | 50.0% | 1 | 1 | 1 |
| 英语 | 03 | 2 | 0.3333 | 33.3% | 2 | 0 | 2 |
+--------+------+--------+---------------+----------+-------+-------+------+21 查询各科成绩前三名的记录
-- 如下语句的意思,A是SC的计算cid相同时,比自身分数少的行数有几行
-- 这里的SC是外层的SC
-- select count(*) from SC as A where SC.cid = A.cid and SC.score < A.score
-- < 3
-- 选少于3个的,就是取前3名
select * from SC
where
(select count(*) from SC as A
where SC.cid = A.cid and SC.score < A.score
) < 3
order by SC.cid asc, SC.score desc;
+------+------+-------+
| sid | cid | score |
+------+------+-------+
| 01 | 01 | 80.0 |
| 03 | 01 | 80.0 |
| 05 | 01 | 76.0 |
| 01 | 02 | 90.0 |
| 07 | 02 | 89.0 |
| 05 | 02 | 87.0 |
| 01 | 03 | 99.0 |
| 07 | 03 | 98.0 |
| 02 | 03 | 80.0 |
| 03 | 03 | 80.0 |
+------+------+-------+如下是Hive的实现(MySQL8.0应该同样适用)
------------------------------------------------------------
-- 从MySQL中导出相应数据,方便之后hive加载
-- 如下命令,看MySQL允许导出的路径
SHOW VARIABLES LIKE "secure_file_priv"
-- 返回的是/var/lib/mysql-files/
-- 如果想要导出到非如上文件夹,需要调整MySQL的设置,具体可百度
select * from SC
into outfile '/var/lib/mysql-files/sc.txt'
fields terminated by ',';
-- 复制一份到其它没有限制的位置,要不然hive加载时读取不到
-- 这里复制到了''/home/zhs/Downloads/sc.txt'
------------------------------------------------------------
-- 本机启动hadoop
start-dfs.sh
-- 检查是否启动成功
jps
-- 如果显示如下内容代表启动成功
3017 DataNode
3258 SecondaryNameNode
2810 NameNode
3390 Jps
-- 否则,可以尝试手动启动相关进程
hadoop-daemons.sh start namenode
hadoop-daemons.sh start datanode
hadoop-daemons.sh start SecondaryNameNode
-- 本地搭建hive环境可参考
-- https://blog.csdn.net/zhsworld/article/details/104163184
------------------------------------------------------------
-- 启动hive
hive
-- 创建practice数据库
create database if not exists practice;
-- 创建成绩表sc
create table SC(
sid varchar(10) comment '学生编号',
cid varchar(10) comment '课程编号',
score decimal(18,1) comment '成绩'
)
comment '成绩表'
row format delimited fields terminated by ','
stored as textfile;
-- 保留表结构,清楚数据(此次未执行)
truncate table SC;
-- 加载本地数据
load data local inpath '/home/zhs/Downloads/sc.txt'
overwrite into table SC;
-- 又手动插入了3条
insert into SC values('08' , '01' , 36);
insert into SC values('08' , '02' , 90);
insert into SC values('08' , '03' , 99);
------------------------------------------------------------
-- 执行相关语句
select * from
(select cid, score ,
rank() over (partition by cid order by score desc) as rank_num
from SC) as A
where A.rank_num <=3;
01 80.0 1
01 80.0 1
01 76.0 3
02 90.0 1
02 90.0 1
02 89.0 3
03 99.0 1
03 99.0 1
03 98.0 3
22 查询每门课程被选修的学生数
-- 防止有重复数据,所以用了count(distinct sid)
select Course.cname, A.*
from Course
left join
(select cid, count(distinct sid) as nums from SC
group by cid) A
on Course.cid = A.cid;
+--------+------+------+
| cname | cid | nums |
+--------+------+------+
| 语文 | 01 | 6 |
| 数学 | 02 | 6 |
| 英语 | 03 | 6 |
+--------+------+------+23 查询出只选修两门课程的学生编号
select sid,count(*) as nums from SC
group by sid
having count(*) =2;
+------+------+
| sid | nums |
+------+------+
| 06 | 2 |
| 07 | 2 |
| 05 | 2 |
+------+------+24 查询名字中含有「风」字的学生信息
select * from Student
where sname like "%风%";
+------+--------+------------+------+
| sid | sname | sbirthday | ssex |
+------+--------+------------+------+
| 03 | 孙风 | 1990-12-20 | 男 |
+------+--------+------------+------+25 查询同名同姓学生名单,并统计同名人数
select sname, count(*) as nums
from Student
group by sname
having count(*) > 1;
+--------+------+
| sname | nums |
+--------+------+
| 李四 | 2 |
+--------+------+26 查询1990年出生的学生名单
select * from Student
where date_format(sbirthday, "%Y") = 1990;
+------+--------+------------+------+
| sid | sname | sbirthday | ssex |
+------+--------+------------+------+
| 01 | 赵雷 | 1990-01-01 | 男 |
| 02 | 钱电 | 1990-12-21 | 男 |
| 03 | 孙风 | 1990-12-20 | 男 |
| 04 | 李云 | 1990-12-06 | 男 |
+------+--------+------------+------+%Y 年, 数字, 4 位 %y 年, 数字, 2 位 %j 一年中的天数(001……366) %m 月, 数字(01……12) %c 月, 数字(1……12) %b 缩写的月份名字(Jan……Dec) %M 月名字(January……December) %U 一年的星期数(0……52), 这里星期天是星期的第一天 %u 一年的星期数(0……52), 这里星期一是星期的第一天 %W 星期名字(Sunday……Saturday) %a 缩写的星期名字(Sun……Sat) %d 月份中的天数, 数字(00……31) %e 月份中的天数, 数字(0……31) %D 有英语前缀的月份的日期(1st, 2nd, 3rd, 等等。) %w 一个星期中的天数(0=Sunday ……6=Saturday ) %r 时间,12 小时(hh:mm:ss [AP]M) %T 时间,24 小时(hh:mm:ss) %p AM或PM %H 小时(00……23) %k 小时(0……23) %h 小时(01……12) %I 小时(01……12) %l 小时(1……12) %i 分钟, 数字(00……59) %S 秒(00……59) %s 秒(00……59) %% 一个文字“%” -- 示例 select date_format(now(),'%Y-%m-%d %h:%i:%s');
27 查询每门课程的平均成绩,结果按平均成绩降序排列,平均成绩相同时,按课程编号升序排列
select cid, avg(score) as score_avg from SC
group by cid
order by avg(score) desc, cid;
+------+-----------+
| cid | score_avg |
+------+-----------+
| 02 | 72.66667 |
| 03 | 68.50000 |
| 01 | 64.50000 |
+------+-----------+28 查询平均成绩大于等于85的所有学生的学号、姓名和平均成绩
select Student.sname, SC.sid, avg(score) as score_avg
from SC,Student
group by sid
having avg(score) >= 85;
+--------+------+-----------+
| sname | sid | score_avg |
+--------+------+-----------+
| 赵雷 | 01 | 89.66667 |
| 赵雷 | 07 | 93.50000 |
+--------+------+-----------+29 查询课程名称为「数学」,且分数低于60的学生姓名和分数
-- 从Course表找到数学对应的cid
-- 从SC表找到低于60分学生sid和score
-- 从Student表找到sid对应的Sname
-- 第一种方法,left join
select B.*, Student.sname
from
(select A.*, SC.sid, SC.score
from
(select cname,cid from Course
where cname = '数学') A
left join SC
on A.cid = SC.cid
where SC.score < 60) B
left join Student
on B.sid = Student.sid;
+--------+------+------+-------+--------+
| cname | cid | sid | score | sname |
+--------+------+------+-------+--------+
| 数学 | 02 | 04 | 30.0 | 李云 |
+--------+------+------+-------+--------+
-- 第二种方法,交叉表+where
select Student.sname, SC.sid,SC.score
from SC,Student,Course
where Course.cname = '数学' and Course.cid = SC.cid and SC.score < 60 and SC.sid = Student.sid;
+--------+------+-------+
| sname | sid | score |
+--------+------+-------+
| 李云 | 04 | 30.0 |
+--------+------+-------+30 查询所有学生的课程及分数情况(存在学生没成绩,没选课的情况)
-- 先交叉Student和Course,罗列所有的学生+课程的组合
select A.*,SC.score from
(select Student.sid,Student.sname,Course.cid, Course.cname
from Student, Course) A
left join SC
on A.sid = SC.sid and A.cid = SC.cid
order by sid,cid;
+------+--------+------+--------+-------+
| sid | sname | cid | cname | score |
+------+--------+------+--------+-------+
| 01 | 赵雷 | 01 | 语文 | 80.0 |
| 01 | 赵雷 | 02 | 数学 | 90.0 |
| 01 | 赵雷 | 03 | 英语 | 99.0 |
| 02 | 钱电 | 01 | 语文 | 70.0 |
| 02 | 钱电 | 02 | 数学 | 60.0 |
| 02 | 钱电 | 03 | 英语 | 80.0 |
| 03 | 孙风 | 01 | 语文 | 80.0 |
| 03 | 孙风 | 02 | 数学 | 80.0 |
| 03 | 孙风 | 03 | 英语 | 80.0 |
| 04 | 李云 | 01 | 语文 | 50.0 |
| 04 | 李云 | 02 | 数学 | 30.0 |
| 04 | 李云 | 03 | 英语 | 20.0 |
| 05 | 周梅 | 01 | 语文 | 76.0 |
| 05 | 周梅 | 02 | 数学 | 87.0 |
| 05 | 周梅 | 03 | 英语 | NULL |
| 06 | 吴兰 | 01 | 语文 | 31.0 |
| 06 | 吴兰 | 02 | 数学 | NULL |
| 06 | 吴兰 | 03 | 英语 | 34.0 |
| 07 | 郑竹 | 01 | 语文 | NULL |
| 07 | 郑竹 | 02 | 数学 | 89.0 |
| 07 | 郑竹 | 03 | 英语 | 98.0 |
| 09 | 张三 | 01 | 语文 | NULL |
| 09 | 张三 | 02 | 数学 | NULL |
| 09 | 张三 | 03 | 英语 | NULL |
| 10 | 李四 | 01 | 语文 | NULL |
| 10 | 李四 | 02 | 数学 | NULL |
| 10 | 李四 | 03 | 英语 | NULL |
| 11 | 李四 | 01 | 语文 | NULL |
| 11 | 李四 | 02 | 数学 | NULL |
| 11 | 李四 | 03 | 英语 | NULL |
| 12 | 赵六 | 01 | 语文 | NULL |
| 12 | 赵六 | 02 | 数学 | NULL |
| 12 | 赵六 | 03 | 英语 | NULL |
| 13 | 孙七 | 01 | 语文 | NULL |
| 13 | 孙七 | 02 | 数学 | NULL |
| 13 | 孙七 | 03 | 英语 | NULL |
+------+--------+------+--------+-------+
-- 一科一列的
select Student.sid,Student.sname,
max(case when SC.cid = '01' then SC.score else '' end) as '语文',
max(case when SC.cid = '02' then SC.score else '' end) as '数学',
max(case when SC.cid = '03' then SC.score else '' end) as '英语'
from Student
left join SC
on Student.sid = SC.sid
group by sid
order by sid;
+------+--------+--------+--------+--------+
| sid | sname | 语文 | 数学 | 英语 |
+------+--------+--------+--------+--------+
| 01 | 赵雷 | 80.0 | 90.0 | 99.0 |
| 02 | 钱电 | 70.0 | 60.0 | 80.0 |
| 03 | 孙风 | 80.0 | 80.0 | 80.0 |
| 04 | 李云 | 50.0 | 30.0 | 20.0 |
| 05 | 周梅 | 76.0 | 87.0 | |
| 06 | 吴兰 | 31.0 | | 34.0 |
| 07 | 郑竹 | | 89.0 | 98.0 |
| 09 | 张三 | | | |
| 10 | 李四 | | | |
| 11 | 李四 | | | |
| 12 | 赵六 | | | |
| 13 | 孙七 | | | |
+------+--------+--------+--------+--------+31 查询存在不及格的课程
select distinct(cid)
from SC
where score < 60;
+------+
| cid |
+------+
| 01 |
| 02 |
| 03 |
+------+32 查询课程编号为02且课程成绩在80分以上的学生的学号和姓名
-- 先从SC表查询cid为02且score在80分以上的学生的学号
-- 然后再跟Student表关联
select A.*, Student.sname from
(select sid, cid, score
from SC
where cid = '02' and score > 80) A
left join Student
on Student.sid = A.sid;
+------+------+-------+--------+
| sid | cid | score | sname |
+------+------+-------+--------+
| 01 | 02 | 90.0 | 赵雷 |
| 05 | 02 | 87.0 | 周梅 |
| 07 | 02 | 89.0 | 郑竹 |
+------+------+-------+--------+33 假设成绩没有重复,查询选修「张三」老师所授课程的学生中,成绩最高的学生信息及其成绩
-- 交叉表+where in
-- 先再Teacher找到‘张三’对应的tid,然后Course在找到tid对应的cid
-- Student和SC的交叉表,找到Student所有科目的成绩,然后筛选科目cid跟如上cid一致的
select Student.sname, SC.cid, SC.score
from Student,SC
where Student.sid = SC.sid
and SC.cid in
(select cid from Course
where tid in
(select tid from Teacher
where tname = '张三'))
order by score desc
limit 1;
+--------+------+-------+
| sname | cid | score |
+--------+------+-------+
| 赵雷 | 02 | 90.0 |
+--------+------+-------+34 考虑成绩有重复的情况下,查询选修「张三」老师所授课程的学生中,成绩最高的学生信息及其成绩
-- 更改一条数据,制造重复的最高数据
update SC set score = 90 where sid = '07' and cid = '02';
-- 获取每科的最高成绩
-- where后的第一个条件是查找所有科的最高成绩
-- 各科,所以用的是SC.cid = A.cid。如果是每个人,则用SC.sid = A.sid
-- 第二个条件是查找“张三”老师所授课程
select * from SC
where
(select count(*) from SC as A
where SC.cid = A.cid and SC.score< A.score) < 1
and
SC.cid in
(select cid from Course,Teacher
where Course.tid = Teacher.tid and tname = '张三');
+------+------+-------+
| sid | cid | score |
+------+------+-------+
| 01 | 02 | 90.0 |
+------+------+-------+
| 07 | 02 | 90.0 |
+------+------+-------+
-- 完事了,再把数据改回来
update SC set score = 89 where sid = '07' and cid = '02';35 如果一个学生在不同课程中的成绩相同,则返回其学生编号、课程编号、学生成绩
-- 第一种 利用case when
-- 把每科的成绩都单独成列,然后找到三列一致的
-- A.cid_01= A.cid_02 and A.cid_02 =A.cid_03筛选出的结果正确的
-- A.cid_01= A.cid_02 =A.cid_03筛选出的结果是乱的,还不知道为啥
select * from
(select sid,
max(case when cid = '01' then score else '' end) as 'cid_01',
max(case when cid = '02' then score else '' end) as 'cid_02',
max(case when cid = '03' then score else '' end) as 'cid_03'
from SC
group by sid) A
where A.cid_01= A.cid_02 and A.cid_02 =A.cid_03;
+------+--------+--------+--------+
| sid | cid_01 | cid_02 | cid_03 |
+------+--------+--------+--------+
| 03 | 80.0 | 80.0 | 80.0 |
+------+--------+--------+--------+
-- 第二种
-- where子句的意思是学号相同,课程不同,但成绩相同
select distinct A.sid,A.cid,A.score
from SC A, SC B
where A.sid = B.sid and A.cid != B.cid and A.score = B.score;
+------+------+-------+
| sid | cid | score |
+------+------+-------+
| 03 | 02 | 80.0 |
| 03 | 03 | 80.0 |
| 03 | 01 | 80.0 |
+------+------+-------+36 查询选修了全部课程的学生信息
-- select count(distinct(cid)) from Course 查询一共有多少门课
select sid from SC
group by sid
having count(*) = (select count(distinct(cid)) from Course);
+------+
| sid |
+------+
| 01 |
| 02 |
| 03 |
| 04 |
+------+37 查询各学生的年龄,只按年份来算
select sname, (date_format(now(),"%Y") - date_format(sbirthday,"%Y") + 1) as age
from Student;
+--------+------+
| sname | age |
+--------+------+
| 赵雷 | 31 |
| 钱电 | 31 |
| 孙风 | 31 |
| 李云 | 31 |
| 周梅 | 30 |
| 吴兰 | 29 |
| 郑竹 | 32 |
| 张三 | 4 |
| 李四 | 4 |
| 李四 | 9 |
| 赵六 | 8 |
| 孙七 | 7 |
+--------+------+38 按照出生日期来算,当前月日<出生年月的月日则,年龄为-1
-- 方法一
-- 借助to_days
select sname,
case when to_days(now()) > to_days(sbirthday)
then round((to_days(now()) - to_days(sbirthday))/365,1)
else "-1" end as age
from Student;
-- 方法二
-- 借助datediff
select sname, round(datediff(now(),sbirthday)/365,1) as age
from Student;
-- 方法三
-- 借助timestampdiff
select sname, round( timestampdiff(DAY,sbirthday, now()) /365,1) as age
from Student;
+--------+------+
| sname | age |
+--------+------+
| 赵雷 | 30.2 |
| 钱电 | 29.2 |
| 孙风 | 29.2 |
| 李云 | 29.2 |
| 周梅 | 28.3 |
| 吴兰 | 28.2 |
| 郑竹 | 31.2 |
| 张三 | 2.2 |
| 李四 | 2.2 |
| 李四 | 7.7 |
| 赵六 | 6.7 |
| 孙七 | 5.7 |
+--------+------+DATEDIFF(expr1,expr2) returns expr1 − expr2 expressed as a value in days from one date to the other. expr1 and expr2 are date or date-and-time expressions.
TIMESTAMPDIFF(expr1,expr2) returns expr2 − expr1
39 查询本周过生日的学生
-- 第一种
-- date_format 用到底
select * from Student
where date_format(sbirthday,"%u") =(date_format(now(),"%u")+1);
-- 第二种
-- week 函数 (可以再第二个参数指定周几算作本周的开始)
select * from Student
where week(sbirthday,"1") =(week(now(),"2")+1);日期函数大全 https://blog.csdn.net/qq_39706570/article/details/101706322
40 查询下月过生日的学生
-- 第一种
-- date_format 用到底
select * from Student
where date_format(sbirthday,"%m") =(date_format(now(),"%m")+1);
-- 第二种
-- month 函数
select * from Student
where month(sbirthday) =(month(now())+1);
四、附录
1 执行 group by 时会如果提示如下错误:
Expression #1 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'pratice.SC.sid' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
临时性解决措施(退出mysql就会失效):
-- 输入如下命令
-- 去掉了ONLY_FULL_GROUP_BY
set @@sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION';参考链接:https://blog.csdn.net/fansili/article/details/78664267
2 SQL 常用语句主要分为两类。
DDL(Data Definition Languages)语句:数据定义语言,这些语句定义了不同的数据段、数据库、表、列、索引等数据库对象的定义。常用的语句关键字主要包括 create、drop、alter等。
DML(Data Manipulation Language)语句:数据操纵语句,用于添加、删除、更新和查询数据库记录,并检查数据完整性,常用的语句关键字主要包括 insert、delete、udpate 和select 等。(增添改查)
3 网传50道题的链接
https://blog.csdn.net/fashion2014/article/details/78826299
https://www.jianshu.com/p/476b52ee4f1b
https://blog.csdn.net/paul0127/article/details/82529216