基于LendingClub数据的信贷分析和建模报告
一:课题分析
二:数据获取
三:数据探索
3.1主要特征含义理解
3.2特征分布
3.2.1目标特征分布
3.2.2分类变量的分布
3.2.3连续数值特征分布
3.2.4时序特征分布
3.2.5文字特征分布
3.2.6两两特征的协方差
四:数据预处理
4.1数据集划分
4.2特征缺失值识别与处理
4.2.1严重缺失值的处理
4.2.2缺失值填充
4.3同值性特征识别与处理
4.4特征格式变换
4.5文本特征处理
4.5.1工作机构分类
4.5.2借款人州地址分类
4.5.2.1 k-means聚类分析
4.5.2.2 等频分箱
4.6时序特征处理
4.7特征编码
4.8归一化处理
4.9警惕数据泄露
4.9.1警惕不恰当特征
4.9.2错误的交叉验证策略
五:特征工程
5.1特征衍生
5.2筛选变量
特征筛选的目的
5.2.1依据共线性筛选变量
5.2.2依据IV筛选变量
5.3特征分箱
5.3.1对无缺省值的连续型数值变量分箱
5.3.2对含有缺省值的连续型数值变量分箱
六:建模
6.1建立评分卡
6.2建立随机森林模型
七:总结
一:课题分析
课题:
研究小微企业主贷款的风险特征,提出可应用性强的风险评估模型构建方案。
课题分析:
小微企业贷款信用评估与小微企业主个人信用情况关系密切,本文将以lendingclub信贷平台上的公开数据作为小微企业主信贷数据模拟样本,构造一个简单明了的传统信贷申请评分卡(A卡),和一个解释性较差的黑箱预测模型,用于辅助决策。
二:数据获取
根据巴塞尔协议提供的经验,正常还款12期以上的贷款人,其还款状态会趋于稳定,因此,我选择LendingClub平台(以下简称LC)2017年Q1的数据,那么我们的样本到目前为止还款全部超过12个月,其数据更新度高,样本可以被有效利用。

由上图,样本共有42538条数据,共有145个特征变量,样本量够大,对它们的分析具有统计意义。
此样本是经过LC平台依据一些条件(比如FICO值)筛选过的美国借款人的样本,因此应用具有一定局限性。
三:数据探索
在着手处理数据之前,先了解基本的数据情况,为进一步的数据探索、数据预处理、特征工程和建模做准备。
3.1主要特征含义理解
主要特征摘录:

3.2特征分布
3.2.1目标特征分布

fully paid:完全结清 charged off:坏账注销
由上表可知,此样本集是一个不平衡数据集。在后续过程中需要考虑到这一点。
3.2.2分类变量的分布
探索典型分类变量依据好坏样本两类的分布并进行可视化展示:



由上左图:
借款人多选择36期贷款,选择60期贷款的违约率要高一些。
由上右图:
我们需要首先理解一下grade这个特征。grade是LC自评等级,不同的网贷平台投资人有不一样的风险收益偏好,LC平台依据这种多样化的需求,将借贷人分成A-G七个等级。
LC使用复杂的算法对每笔贷款予以评级,这个评级和借款人的利率息息相关(这也说明,grade与某些特征是存在关系的)。比如说,那些信用历史好,还款能力好的借款人利率偏低,约7%,其贷款等级通常为A级。从A到G,贷款的风险越来越高,利率也越来越高。
从图中,我们也可以看出这个趋势。
另外,无论是投资人还是借贷者,大多数都是选择较低风险较低收益的类型。

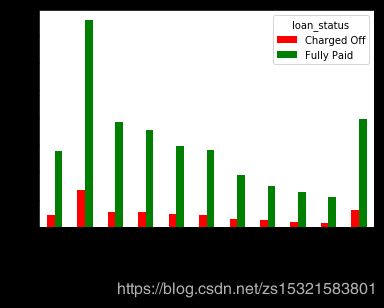
由上左图:
settlement_status(借款人结算计划的状态),只有违约注销了才会有这一项,属于严重缺失值。而且这是贷后指标,对贷前预测模型没有意义。
由上右图:
工作时长低于1年(包括1年)与10年以上的借款人最多,两者的违约比例相差不大,这张图打破了人们惯常以为的工作年限长就靠谱的想法。除此两类,在2-9年内,随着工作年限越长,贷款需求越少,可能是因为收入越来越稳定吧。

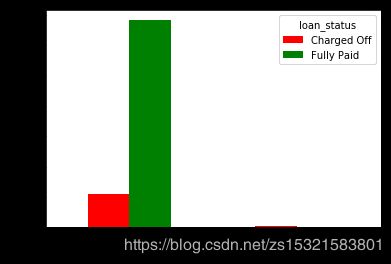
由上左图:
债务整合(举债还债)这类最多。另外3项是:住房改善、汽车、大宗采购,也就是基本生活需求。相对来说,借钱做生意的,违约率较高。
由上右图:
debt_settlement_flag表示已注销的借款人是否与债务结算公司合作。属于贷后信息。


由上左图:
借款人住房按揭、租房最多,违约率不相上下;
由上右图:
表征收入或收入来源是否经过核实。大部分借款是经过核实的,经过简单计算可知,核实的借款违约率约为0.15,未经核实的违约率约为0.14.可以说明网上提交的申请数据还是比较诚实的。另外,也可以初步推断,这个变量的预测能力应该不是特别强。
3.2.3连续数值特征分布
探索连续变量的分布并可视化展示:

数据集中有几十个连续特征,下面是示例图:



其余图示省略。
从这些图中可以初步得出如下信息:
-
贷款额度、分期付款金额成有些长尾的正态分布,说明贷款额度集中在中小额度,但是也有分散的大额度
-
年收入集中在0-10万刀以内,但是也有极高收入(最高达到600万)的借款人
-
负债率较符合正态分布,但是高负债率相较低负债率违约风险更大
-
分析过去2年内的违约次数分布,即便1次违约记录都没有,这次也可能会出现违约,
-
过去6个月内查询次数越多,违约的概率越大
-
迄今为止收到的付款总额或本金越少,违约率越高,这也显示了贷中监控的重要性,有问题及时预警。
-
。。。
3.2.4时序特征分布
全部时序特征:issue_d:(款发放月份),earliest_cr_line(首开信用卡时间),last_pymnt_d(最近一次收到还款的时间),last_credit_pull_d(LC撤回信贷最近的月份),其中第1,3,4项都是贷后数据。

首开信用卡时间分布图:

由上图可知:近期开信用卡的借款人居多,在时间维度上,借款人的分布类似正态分布。
3.2.5文字特征分布
样本中的文本特征有:借款人所在地,借款描述,职位头衔
词云的优势是从大量文字样本中一眼看出文本的主要内容。
通过词云了解各个文本特征分布:

按还款状态分类统计借款人所在州的分布:
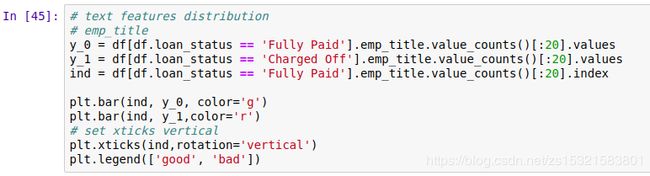
输出:




由上图可知:
借款人的区域来源,主要集中在加州、德州、纽约等等这些大州,后续数据处理可以考虑将这些主要区域提取出来。
借款描述:支付信用卡欠款
职务头衔:借款人的职务背景按照数量分布依次是公司、军队、医院。。。
3.2.6两两特征的协方差
对样本特征的相关性有一个直观的理解:
![]()
输出基于协方差的热力图:

上图中浅颜色的部分是表示特征相关度高,除了对角线的区域,其它区域也分布着高相关性特征对,这说明样本集中某些特征之间存在强线性相关性,这个问题在选用某些机器学习模型(比如基于线性回归的模型族)时会显著影响模型性能,需要引起注意。
四:数据预处理
根据初步数据探索分析的结果,我们知道:
-
数据集存在严重的数据缺失问题
-
某些连续型特征用字符型特征表示,如百分比类的
-
部分特征存在明显的共线性关系
4.1数据集划分
为了避免验证集/测试集数据被污染,最好在数据预处理之前进行训练集,验证集,测试集的划分。
训练集用于训练模型,验证集用于初步评估/优化模型,测试集进行最终的测试。

4.2特征缺失值识别与处理
4.2.1严重缺失值的处理
找到缺失超过60%的特征,并进一步了解缺失情况:

截取输出结果的一部分:

从上表中可以看到,其中绝大部分特征都是完全缺失,对于这种,毫无疑问要删除。但是其中的mths_since_last_delinq(距离上次违约的月份数)、mths_since_last_record(距离上一次公共黑记录月份数)从经验判断应该对评估借款人的信用有帮助,所以,即便这2个属于严重缺失数据,也必须留下来。此外,严重缺失特征中还包括settlement(结算)信息,这属于贷后信息,不应包含在申请评分卡模型中,一并删除。
故:

4.2.2缺失值填充
了解现有缺失值的情况,根据缺失比例,缺失值的具体信息含义,缺失特征性质,来决定处理策略:


上表中标红数据留后处理。
实施:

注:
-
由于接下来将用到逻辑回归模型,它对特征线性相关性较敏感,所以尽管用其它变量拟合缺失值对缺失值的填充会更符合实际情况,也没有采用这种方法。
-
为什么使用众数填充而不是用中位数或是均值填充?因为众数对于数值型变量和字符型变量都适用,而且也有统计意义。
4.3同值性特征识别与处理
如果一个变量大部分的观测都是相同的特征,那么这个特征或者输入变量就是无法用来区分目标时间,一般来说,临界点在90%。但是最终的结果还是应该基于业务来判断。

按众数占比从小到大给占比高于90%的特征排序,并且依据特征内涵确定处理策略:

实施:

4.4特征格式变换
这一步将格式杂乱的特征进行规整.

4.5文本特征处理
经过上述步骤处理后,现有的文本类数据包括:emp_title(职务信息),desc(借款描述), title(标题),addr_state(借款人地址),其中desc/title与purpose相关性较强,都是表明借款用途的信息。
emp_title字面上看是职务头衔,但是实际内容是借款人所在机构,它类型多,且是文本型特征,但是根据数据探索阶段得到的结论,这个变量含有预测性的信息,用模型分箱相当耗费性能,所以根据经验考虑尝试机构类别将它分类。
addr_state也包含预测性信息,可以尝试用卡方分箱或依据经验进行进行分类。
4.5.1工作机构分类
工作机构分类,依据A政府机构类,B银行类,F医院类,E学校类,C自职业类,D公司和其它类,G退休类分类. 如果数据中的emp_title与某个上述A-G有交集,则将它划为该类,用字母字符表示; 缺省值为’H'。

注:由于下面要应用到随机森林模型,它只接受数值型和类别型变量,不接受
‘object’或区间格式的变量,为了方便,将类别统一用数字表示。其它的格式变换也是如此。
4.5.2借款人州地址分类
4.5.2.1 k-means聚类分析
首先尝试使用k-means方式进行聚类,看看每一类中的州地址有没有什么共性:

从输出结果中并没有看出不同群体有什么共性。
4.5.2.2 等频分箱
用频数进行分类,使每一个分组内的样本数尽量相近

4.6时序特征处理
在4.4格式转换部分,将earliest_cr_line,issue_d的字符串格式数据,转换为标准datetime格式数据,方便后续的特征工程。
4.7特征编码
逻辑回归和随机森林模型不接受字符型变量,因此需要将对此类变量进行编码。
常用的编码方式有类别标签法(不同的类别映射到不同的数值),哑变量编码法(对类别变量取哑变量)等等。考虑到评分卡模型的简洁性,在此选用类别标签法。

4.8归一化处理
逻辑回归模型基于线性回归,求参需要用到梯度下降法,为了加快迭代速度,不同特征的变化范围规模相差不宜过大,如果用数值直接带入逻辑回归模型,必须进行变量缩放。但是本文是用逻辑回归建立评分卡,会将数值变量进行分箱,所以这一步可以省略。
4.9警惕数据泄露
数据泄露分为2种:不恰当特征导致的泄露、不恰当的交叉验证策略导致泄露
4.9.1警惕不恰当特征
所有特征中,一旦在目标属性出现后,会随之更新或出现的属性,属于会泄露信息的属性,在这个数据集中,包括贷中、贷后特征。
删除此类特征(之前预处理步骤中已经删除了一些):

4.9.2错误的交叉验证策略:
尽量保证验证集数据的纯粹,不要让它参与到训练集的处理和模型构建当中,这意味着,要在预处理之前分割训练集和测试集。
五:特征工程
5.1特征衍生
将时序变量衍生为月份值,将(贷款发放时间-首次使用信用卡时间)作为一个新的变量,表示信用历史(cre_hist),单位是月份。

5.2筛选变量
5.2.1依据共线性筛选变量
逻辑回归是基于线性回归模型,其前提假设是用于建模的特征之间不存在线性相关性,因此,它对共线性问题比较敏感。共线性的存在对模型稳定性有很大影响,并且也无法区分每个特征对目标变量的解释性。
依据VIF(方差膨胀系数)筛选变量
每个特征的VIF计算是用其它特征对它进行回归拟合,如果这种拟合的解释性很强,说明它们之间存在多重共线性。
用VIF计算连续型变量的共线性:

得到从大到小的VIF值排序:

用协方差计算线性相关性:
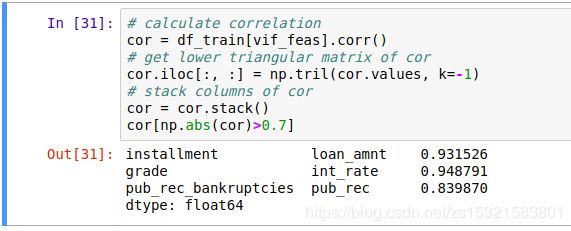
根据经验,vif>10,cor>0.7,变量之间的有显著性的相关性。
从上述关于协方差和VIF的分析结果中我们可以看到:installment&loan_amnt,int_rate&grade,total_acc&open_acc,pub_rec_bankruptcies&pub_rec之间存在线性关系,因为pub_rec_bankruptcies&pub_rec中大多数都是0,所以其有相关可以解释。剩下的几对,我们可以尝试先删除每对中的一个,删除installment & grade,再去检测相关系数。
此外,有几个处于边界地带的特征,暂时留下,特征工程中删除特征时要谨慎,因为删除特征,意味着弃用一些信息。

5.2.2依据特征重要性筛选变量
筛选变量常用的方法有,基于正则化损失函数的线性模型,基于机器学习模型输出的特征重要性,基于IV值。
在此,为了方便进行评分卡建模,采用IV值.
定义woe和iv:

计算每个变量的IV 值并按从大到小的顺序排序:

如果输出IV值是无穷,说明该特征中某些属性中缺失某类样本,这需要重新分箱,将这类样本添加到相邻类(对于连续型数值样本)或样本数量较少的那一类(对于分类样本)中去: deling_2yrs:把7.0,8.0,9.0,11.0划归到7.0那一类,全算作6.0
home_ownership:把2添加到1 这一类
pub_rec:把3.0,4.0,添加到2.0这一类

保留IV大于0.15的特征:

5.3特征分箱
特征分箱就是把连续特征转化为离散特征,或者减小离散特征的离散性。
特征分箱有如下好处:
-
特征分箱后,特征被简化,也简化了模型,比如在逻辑回归评分卡模型中,评分卡被简化,基于决策树的模型中,决策树枝杈减少,降低了过拟合的风险,有效增加了模型的稳定性。
-
特征分箱可以将缺失值划为一类,比如此样本中无法被编码的公共记录缺失类。
-
特征离散化后对异常数据也有更强的容错性。比如假设年龄数据中出现1000岁,模型可以自动将其划分为>80岁一类,否则它会对对异常值敏感的模型如(逻辑回归)造成很大影响。
-
特征离散化之后,方便进一步进行非线性的特征衍生。
分箱的方法:
常用的分箱方法包括卡方分箱、等频或等距分箱、聚类、依据经验分箱等。
对连续型数值变量,在此采用有监督的最优分箱法——卡方分箱。
定义卡方分箱函数:

5.3.1对无缺省值的连续型数值变量分箱
对连续型数值变量实施分箱,得到切割点:
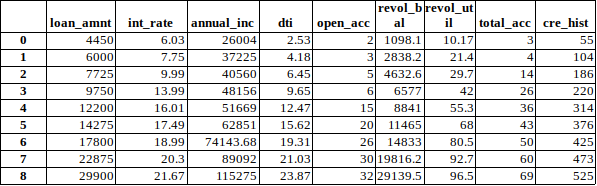
注:上表中的切割点不包括最大点,最小点。

制作切割点字典:
实施分箱:

5.3.2对含有缺省值的连续型数值变量分箱
对两个比较特殊的变量mths_since_last_delinq’和'mths_since_last_record',它们也是属于连续型特征变量,但是却存在缺失值,分箱策略是将缺失值作为一类,其他类进行卡方分箱。
得到2者的切割点:
‘mths_since_last_delinq’:
[19.0, 33.0, 38.0, 63.0]
'mths_since_last_record':
[46.0, 68.0, 79.0, 82.0]
实施分箱:

将所有变量分箱后的效果如下:

六:建模
经过之前的数据处理和特征工程,得到了分箱后的,规整的数据,并且找到了对评分卡来说,高预测性能的特征。
这部分我会建立1个传统的评分卡和1个较复杂解释性较差但预测性较好的随机森林模型。
6.1建立评分卡
在5.2.2节,得到了每个特征中不同属性的woe值,它的含义是该分类对“好结果”的贡献度。
建立评分卡的步骤如下:
-
用woe值替换相应位置的属性值
-
建立逻辑回归模型
-
根据回归结果计分
实施:

评估模型的预测性能:

auc约为0.672,ks值约为0.35,在评分卡建模中,ks值大于0.3,说明这是一个基本可用的模型。
输出评分卡:

所得评分卡见附录——评分表.pdf。
6.2建立随机森林模型
评分卡的优势在于简单明了,但是它无法包含更多的信息。随机森林的是以决策树为弱学习模型通过bagging方法构造出的强学习模型,它能容纳更多的信息,同时通过多模型投票,又能很好的避免过拟合的影响,它正好弥补了这一缺陷。这一模型可以作为评分卡的参考。
用网格搜索的方式优化逻辑回归森林模型:
回归森林模型中,n_estimators表示底层决策树个数,一般来说,树的个数越多,模型的稳定性越强,但是它的增大要受限于计算性能。

参数遍历之后,最优n_estimator取值为100, 此模型比评分卡模型的性能稍好一点。
用学习曲线判断模型的拟合状态:



模型在训练和测试样本上,随着训练样本的增加,贴合很好,并无过拟合现象。
七 总结
在评估小微企业信贷风险时,个人信用评分只是其中一个环节,还应该综合考虑借贷人的经营情况,出借方的风险偏好等其他因素,构建风控策略和风控系统。
参考:
信用评分卡模型 —— 基于Lending Club数据
构建lending club的信用评分模型
一篇文章搞懂机器学习风控建模过程
【有监督分箱】方法一:卡方分箱