JVM - 3. Java对象创建那点事与内存布局
创建与分配方式
创建一个对象的方法有很多但在程序层面最终都指向了new。
通常创建一个对象会通过new指令,看是否能在常量池匹配到一个符号引用,再去检查是否有类加载,如果没有则进行类加载过程。
@@>>>符号引用
@@>>>类
正常来说创建一个都是堆上分配,但是在前面我们也说过因为JVM优化(逃逸分析),会有堆上分配的情况,具体看下面例子。
class A{
//User user堆中静态区
public static User user=new User("曾经沧海难为水",Role.administrator);
public Object ob = new Object();//堆上分配(TLAB分配)
public Integer num = new Integer(1200); //堆上分配(TLAB分配)
public void execute(){
String str=new String("");//未逃逸 >> 栈上分配
...
...
Integer n2=num; //栈上n2 > 指向堆/TLAB上num
int n3 = num;//Integer.intValue();//栈内保存
System.out.println(num);//打印堆上分配的对象
}
}@@>>>逃逸分析
继续上面的说,当类加载完毕后,对象的大小是可以确定的(对象头中保存对象大小或数组长度),当对象确定大小后,我们需要从堆中分配一块内存来存放这个对象。
方式有两种:
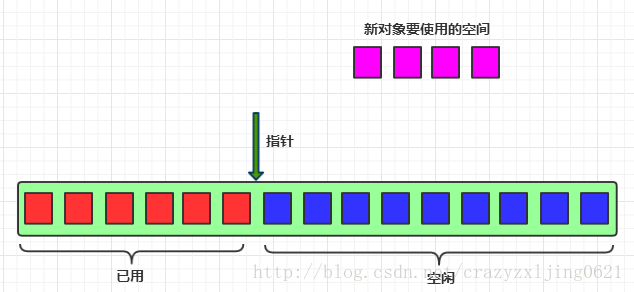
1.指针碰撞
当内存排列是绝对整齐的,已用的在一侧,空闲的在一侧,中间包含放着一个指针作为分界点则,当新的对象进入仅仅是将指针向着空闲一侧挪动对象大小的距离。
准备移动
移动完成
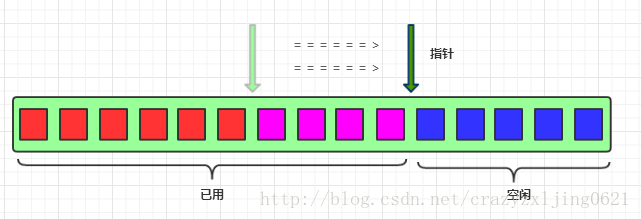
因为堆中空间是共享的,当修改指针移动的时候,可能会发生并发问题。A正准备分配内存,然而B“提前“占用了“A的内存“,怎么办呢?
两个办法可以解决
1.使用CAS来确保分配成功
2.将数据分配到TLAB(下面介绍)
2.空闲列表
上面看到当内存是整齐的情况下可以选择指针碰撞方式去将新对象插入到内存,但是内存如果是非规整的呢?
非整齐的内存空间
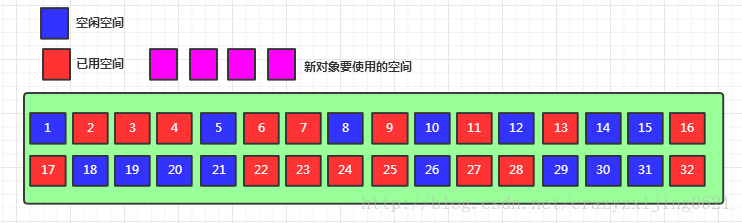
当上面非整齐的内存分布出现时,我们发现无法铜鼓指针碰撞来确定插入位置。那么我们就通过空闲列表(Free list)来维护一个可用地址信息,去空闲列表中寻找连续的可以满足新对象要求的内存空间地址
空闲列表概念图
我并没有去深究空闲列表的数据结构和存放方式。下图只是阐述一个概念

从上面两张图来看,空闲列表记录18~21有可以足够存放目标对象容量的空间,那么对象可以顺利存入,否则将会触发GC来获得足够的空间。
当然当整齐的内存布局下没有空间也会触发GC,但是总体来说比非整齐的GC来的次数更少,因为前者可以最大限度在内存不足的情况下才触发GC,而后者则无法做到这点,因为非整齐的它。没有足够的连续空间插入新对象时,总是要来GC
指针碰撞的方式作用在“标记整理“算法的老年代收集器上,而空闲列表则作用在“标记清除”,当然年轻代使用的都是“复制算法”,老年代+年轻代整体成为分代收集算法,这个以后再说
@@>>>GC
TLAB
上述中说道为了并发问题,我们使用TLAB去解决,TLAB( Thread Local Allocation Buffer 本地线程分配缓冲区)。
1. 当进入新的对象时先到本线程内的TLAB去存储,
2. TLAB的存储格式是规整的内存排列(使用指针碰撞来添加新对象)
3. 当容量不足的时候去年轻代中的Eden区去申请一块大于当前TLAB区的新TLAB
4. 如果新TLAB区依然无法存放对象则将对象再放到正常的堆上分配(CAS确保并发安全)并根据堆上空间选择是否GC
TLAB区中使用指针碰撞来增加新对象不会有安全问题,因为是当前线程
TLAB默认大小为Eden区的1%
-XX: +/-UseTLAB 来开启TLAB支持
-XX:TLABWasteTargetPercent来调整TLAB大小比例
继续创建
1.前面所说获取内存空间
2.将获取到的空间设置为0
3.设置对象头信息
4.执行[init]指令
对象的布局
对象分为三部分,对象头,实例数据,对齐填充
对象头

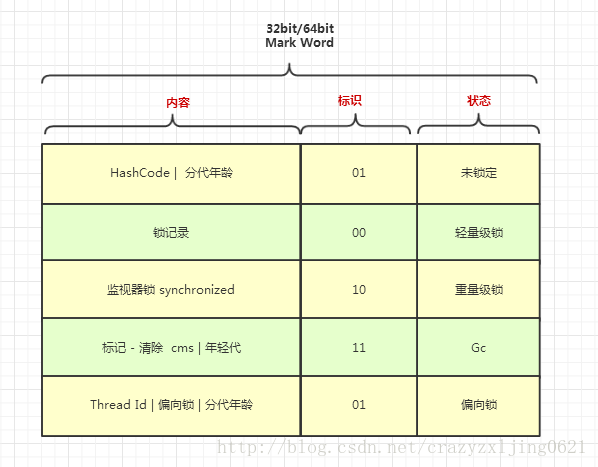
Mark Word
一个可以复用的区域来标记对象运行时数据,它的内容不是固定的在不同的情况下此区域会根据标识来记录不同信息。
摘选自openJdk1.8 > markOop.hpp
//32 bits:
// --------
// hash:25 ------------>| age:4 biased_lock:1 lock:2 (normal object)
// JavaThread*:23 epoch:2 age:4 biased_lock:1 lock:2 (biased object)
// size:32 ------------------------------------------>| (CMS free block)
// PromotedObject*:29 ---------->| promo_bits:3 ----->| (CMS promoted object)
// 64 bits:
// --------
// unused:25 hash:31 -->| unused:1 age:4 biased_lock:1 lock:2 (normal object)
// JavaThread*:54 epoch:2 unused:1 age:4 biased_lock:1 lock:2 (biased object)
// PromotedObject*:61 --------------------->| promo_bits:3 ----->| (CMS promoted object)
// size:64 ----------------------------------------------------->| (CMS free block)Mark Word中有以下四种标识五种状况
// [ptr | 00] locked ptr points to real header on stack
// [header | 0 | 01] unlocked regular object header
// [ptr | 10] monitor inflated lock (header is wapped out)
// [ptr | 11] marked used by markSweep to mark an object
// not valid at any other time
类型指针
对象指向它的类元数据的指针,但并不是所有虚拟机实现需要在对象上保留一个指向元数据类型的指针。
数组对象大小
当对象是数组时,记录数组对象大小
因为对象的元数据中包含了对象大小,然而数组对象元数据中不包含对象大小信息
实例数据与对齐填充
- 程序代码中中所定义的各种类型的字段内容。
- 无论是父类的还是本身的都会在实例数据中记录下来
- 在JVM配置中我们可以使用-XX:FieldsAllocationStyle [0,1,2]来配置不同的内存布局。
内存布局
首先先确定八个基础类型以及引用类型所占用的字节数
- boolean 1byte
- byte 1byte
- char 2byte
- short 2byte
- float4byte
- int 4byte
- long 8byte
- double 8byte
-
对象布局优先级规范如下:
// Rearrange fields for a given allocation style
//oop指针 padded代表对齐填充
//hotspot中对象地址按照8的整数位分块,对齐填充的作用就是确保满足这种规范,当空间足够满足规范,对齐填充就不需要出现了
if( allocation_style == 0 ) {
// Fields order: oops, longs/doubles, ints, shorts/chars, bytes, padded fields
//类指针在前,之后按照8byte -> 1byte 的顺序排列
} else if( allocation_style == 1 ) {
// Fields order: longs/doubles, ints, shorts/chars, bytes, oops, padded fields
//先按照8byte -> 1byte 排序,类指针在后
} else if( allocation_style == 2 ) {
// Fields allocation: oops fields in super and sub classes are together.
//子类的类指针紧挨父类类指针,其余也是8byte -> 1byte顺序
我们用64bit Hotspot JVM来说明,32bit的一会在后面会简单阐述一下
准备工作
public class A {
int isInt_1;//4
byte isByte_2; //1
char isChars_3; //2
Object isOops_4; //8
long isLong_5; //8
short isShort_6; //2
}
public class B extends A {
String isString=new String("Hello A");
int isInt2;
} 分析对象布局的小工具
http://openjdk.java.net/projects/code-tools/jol/
http://central.maven.org/maven2/org/openjdk/jol/jol-cli/0.9/jol-cli-0.9-full.jar
我们先来看下A类的内存布局
System.out.println(ClassLayout.parseClass(A.class).toPrintable());
//org.openjdk.jol.Main.main("internals","A");
-XX:FieldsAllocationStyle=0

可以看到OOp类型排到了前面,然后根据策略选择重拍属性顺序。在尾部因为不满足8bit的规则,增加了外部对齐7字节,总共使用占用48字节,浪费7字节

-XX:FieldsAllocationStyle=1

因为修改了顺序,对齐由外部转到了内部,空间占用与浪费空间同上
-XX:FieldsAllocationStyle=2

其实如果把oop看成所谓的“首位开端“,那么当策略为2的时候,我认为可以说是双端对齐。
那想了想,如果来个class C extends B,那么它们的布局是怎样的呢?
第一张图
增加了class C继承了B ,C中包含int和integer两个成员

第二张图
删除了class A中的oop

第三张图
恢复了class A中的oop,在class B中又增加了一个oop

从上面两张图总结一个-XX:FieldsAllocationStyle=2的理论
“如果基类没有oop,则oop默认永远都放在尾部,反之则把oop放在头部”
32bit jvm 内存布局
这里简单说下当jvm为32bit的时候header为8byte(4+4)
指针压缩
当64bit jvm下开启了指针压缩 -XX:+UseCompressedOops
header头就被压缩至12byte(4+4+4),oop类指针也被压缩到4byte
-XX:+/- CompactFields
该选项确保较窄的成员有可能为了避免补齐padding浪费空间,而跳过队列限制补在空位(有的地方说,子类也会为基类补齐,但是我尝试了一下并没有。)
compactFields是默认开启的
-XX:FieldsAllocationStyle=0 -XX:-CompactFields

-XX:FieldsAllocationStyle=0 -XX:+CompactFields

对象访问定位
句柄

句柄在堆区,句柄保存了对象地址与类型,当reference访问时去句柄请求。
优点:句柄地址堆reference来说稳定,不需要频繁修改。
直接指针
reference直接保存对象地址与类型,无需句柄的存在
优点:直接指针的好处就是效率更快节省了与句柄定位的开销(Hotspot使用的就是直接指针方式)