AutoEncoder的简介与使用pytorch建立(Stacked) AutoEncoder推荐系统
AE
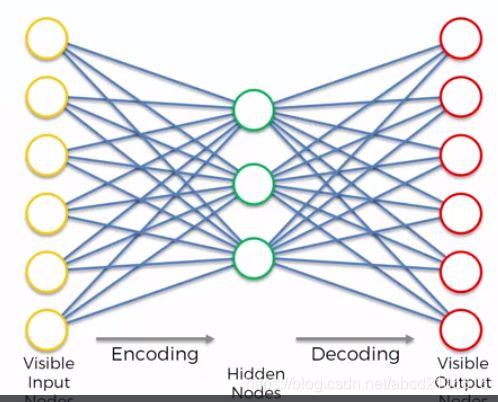
简单来说,之所以AutoEncoder适合做推荐系统,与Boltzmann Machine类似,其内部是一个系统,即若某一点出现变化,系统内所有点都会随之进行变动(更新)。Boltzmann Machine的Visible nodes直观来说是input,但实际上visible nodes与hidden nodes是在同一个系统下不分你我。在Restricted Boltzmann Machine (RBM)下有更直观清晰的对visible nodes与hidden nodes进行分别,AE这里的visible nodes 与hidden nodes与RBM的类似,直观来说,visible input nodes可以勉强当作为ANN的input values,visible output nodes可以勉强当作ANN的output values,hidden nodes可以勉强当作ANN的hidden layers。AE的forward propagation包括encode与decode,以及back propagation更新权重
推荐阅读:
直观理解
[1] Malte Skarupke, 2016, Neural Networks Are Impressively Good At Compression
写AE(他讲的是用Keras,而本文使用pytorch,但问题不大)
[2] Francois Chollet, 2016, Building Autoencoders in Keras
为解决overfitting问题,有多版本的AE方法可以被利用减少或者避免overfitting,如 Sparse Autoencoders,Denoising Autoencoders,Contractive AutoEncoders等
[3] Chris McCormick, 2014, Deep Learning Tutorial - Sparse Autoencoder
[4] Eric Wilkinson, 2014, Deep Learning: Sparse Autoencoders
[5] Alireza Makhzani, 2014, k-Sparse Autoencoders
[6] Pascal Vincent, 2008, Extracting and Composing Robust Features with Denoising Autoencoders
本文将实现的Stacked Autoencoders(很普通的AE版本–添加多层hidden layers到网络)
[7] Pascal Vincent, 2010, Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion
AE与Boltzmann Machine有概念上的联系,也建议尝试理解Boltzmann Machine
[8] Yann LeCun, 2006, A Tutorial on Energy-Based Learning
[10] Geoffrey Hinton, 2006, A fast learning algorithm for deep belief nets
[11] Oliver Woodford, 2012?, Notes on Contrastive Divergence
[12] Yoshua Bengio, 2006, Greedy Layer-Wise Training of Deep Networks
[13] Geoffrey Hinton, 1995, The wake-sleep algorithm for unsupervised neural networks
[14] Ruslan Salakhutdinov, 2009?, Deep Boltzmann Machines
建立的Stacked AutoEncoder (SAE) 的步骤:

以下以电影推荐为例,利用pytorch建立(Stacked) AutoEncoder简单的推荐系统,数据集为:总-一百万电影与用户评价(ml-1m),以及训练与测试集-十万电影与用户评价(ml-100k)。如果下载不到可以自行搜索ml-1m与ml-100k数据集
代码:(多数为英文注释,可复制翻译,自我感觉挺标准的)
# AutoEncoders
# Importing the libraries
import numpy as np
import pandas as pd
import torch
#nn is the module of torch to implement nueral networks
import torch.nn as nn
# this is for parallel computation
import torch.nn.parallel
#this is for optimizers
import torch.optim as optim
import torch.utils.data
#this is for stochastic rate
from torch.autograd import Variable
from operator import itemgetter#用来使用sorted() function
# for 1m data and 100k data, can take the 100k data as a community, or local data, 1m as a global data
# Importing the dataset 1 million data
#separator is ::, set engine='python' to make it efficient, encoding: some movie names are some special charaters that cannot be processed by UTF-8, instead, using 'latin-1'
movies = pd.read_csv('ml-1m/movies.dat', sep = '::', header = None, engine = 'python', encoding = 'latin-1')
users = pd.read_csv('ml-1m/users.dat', sep = '::', header = None, engine = 'python', encoding = 'latin-1')
ratings = pd.read_csv('ml-1m/ratings.dat', sep = '::', header = None, engine = 'python', encoding = 'latin-1')
# Preparing the training set and the test set 100k data, splitting into 80k training set and 20k test set
#since the separator is tab, so it uses delimiter='\t' to separate the data
training_set = pd.read_csv('ml-100k/u1.base', delimiter = '\t')
# we need np.array to process by torch instead of dataframe
training_set = np.array(training_set, dtype = 'int')
test_set = pd.read_csv('ml-100k/u1.test', delimiter = '\t')
test_set = np.array(test_set, dtype = 'int')
# Getting the number of users and movies, create list of list, put '0' to the value that certain user didn't rate the movie
nb_users = int(max(max(training_set[:,0]), max(test_set[:,0])))
nb_movies = int(max(max(training_set[:,1]), max(test_set[:,1])))
# Converting the data into an array with users in lines and movies in columns
def convert(data):
new_data = []
#匹配相对应的 local data里面 user与movie相匹配,若user没有评价过该movie,then mark ‘0’
for id_users in range(1, nb_users + 1):
#create 第一层list,id_movies为某user看过的movie的id
id_movies = data[:,1][data[:,0] == id_users]
#id_ratings为某user评价过某movie的rate
id_ratings = data[:,2][data[:,0] == id_users]
#首先创建全部为0的list,再将user 评价movie的rating分数替换0,那么就能mark user没看过的movie为0
ratings = np.zeros(nb_movies)
#由于movieID由1开始,而python由0开始,因此要rating匹配python则-1
#for i in (0, nb_movies):
# ratings[i].append() id_ratings
ratings[id_movies - 1] = id_ratings
#将以上创建的list合并到一个list,以被torch提取
new_data.append(list(ratings))
return new_data
training_set = convert(training_set)
test_set = convert(test_set)
# Converting the data into Torch tensors
#Tensors are arrays that contain elements of single data type, which is a multi-dimentional matrix, but instead of being a numpy.array, this is a pytorch.array
#numpy.array will be less efficient, so we using tensors, torch.tensors, next is to convert the list of list to torch.tensors
training_set = torch.FloatTensor(training_set)
test_set = torch.FloatTensor(test_set)
# Creating the architecture of the Neural Network, Stacked Auto Encoder that is going to be the child class of an existing parent class in pytorch called Module M which is taken from the nn module that we import there
class SAE(nn.Module):
#since we are doing an inheritance, the arguement need not be added, but need ,
def __init__(self, ):
#use super() function to optimize the SAE
super(SAE, self).__init__()
# Linear class which will make the different full connections between layers
#now define this architecture by choosing the number of layers and the hidden neurons in each of these hidden layers
#fc is full connection, the first part of the neural network, which is between the input vector features that is the ratings of all the movies for one specific user
#and the first hidden layer is shorter vetor than the input vetoc
#the object below will represent the full connection between this first input vector features and the first encoded vector, call this full connection fc1
#the first feature is the input vector, the number of input features, second feature will be the number of nodes or neurons in the first hidden layer. This is the number of elements in the first encoded vector, the following number is not tuned, which is determined as experience
#20 means 20 features or hidden nodes will ne chosen to make the first layer's process, it can be tuned
self.fc1 = nn.Linear(nb_movies, 20)
#the second full connection, the first feature will be 20 that is the hidden nodes of the first hidden layer, 10 is determined as the size of second hidden layer, this will detect more features based on the first hidden layer
self.fc2 = nn.Linear(20, 10)
#start to decode or reconstruct the original input vector, the second feature will equal to the firs feature of fc2
self.fc3 = nn.Linear(10, 20)
#same reason, for the reconstruction of the input vector, the output vetor should have the same dimention as the input vector
self.fc4 = nn.Linear(20, nb_movies)
#determin the activation function, sigmoid or you can use other activation function to compare
self.activation = nn.Sigmoid()
#The main purpose of this forward() function (forward propagation), it will return in the end the vector of predicted rating that we will compare them with real rating that is input vector
#The second arguement x which is our input vector, which you will see that we will transform this input vector x by encoding it twice and decoding it twice to get the final ouptut vetor that is the decoded vector that was reconstructed
def forward(self, x):
#need to modify or update x after each encoding and decoding
x = self.activation(self.fc1(x))
x = self.activation(self.fc2(x))
#start decoding it
x = self.activation(self.fc3(x))
#the final part of the decoding doesn't need to apply the activation function, we directly use full coneection fc4 function
x = self.fc4(x)
#x is our vector of predicted ratings
return x
def predict(self, x): # x: visible nodes
x = self.forward(x)
return x
#load the trained model
#sae = torch.load('AutoEncoder.pkl')
#since we don't have any arguement in the init function, so sae=SAE() need no arguement
sae = SAE()
#criterion that will need for the training, for the loss function MSE
criterion = nn.MSELoss()
#can use RMSprop or adam optimizer, deppends on the condition or tuning
#RMSprop() optimizer needs arguement: 1 all the parameters 2 learning rate, setting based on the condition, 3 weight decay which is used to reduce the learning rate after every few epochs in order toregulate the convergence, setting based on the condition
optimizer = optim.RMSprop(sae.parameters(), lr = 0.01, weight_decay = 0.5)
# Training the SAE
nb_epoch = 20
#in each epochs, we will loop over all our observation that is users, than to loop each epochs, so there're 2 loop
for epoch in range(1, nb_epoch + 1):
#the loss variable = 0 since before start the training, loss = 0, loss will increase as it finds some errors
train_loss = 0
#s: counter. we need to normalize the train loss, so need to divide the train loss by this counter s=0. means the type of counter is float
s = 0.
for id_user in range(nb_users):
#since nb_users and training_set start from 0, so don't need to modify the range to (1, nb_users1)
#training_set[id_user] is a vector, but a network in pytorch or even in keras can not accept a single vector of one dimension, what they rather accept is a batch of input vectors,
#so when we apply different functions of the network for example forward function, the function will not take single vector of 1D as input, so we need to add an additional dimension like a fake dimension which will correpondent to the batch,
#so using Variable().unsqueeze(0), we will put this dimension into the first dimension, so this value will be 0, we now create a batch having a single input vector, but at the same time, a batch can have several input vectors (batch learning)
input = Variable(training_set[id_user]).unsqueeze(0)
#now take care of the target, we have separate variables between input vector and target, so basically the target is the same as the input vector, since we are going to modify the input, which will be a clone of the input vector, using clone()
target = input.clone()
#to optimize the memory
#target.data will take all the values of target which is input vectors, that will be all the rating of this user at the loop
#so this we will make sure the observation contains at least 1 rating, which means take the users who have rated at least 1 movie
if torch.sum(target.data > 0) > 0:
#first get our vector of predicted ratings that is output
output = sae(input)
#second, again, to optimize the memory and the computation
#when we apply stochastic gradient descent, we want to make sure the gradient is computed only with respect to the input and not the target, to do this we will use require_grad = False, whcih will reduce the computation and save up memory, that will make sure will not compute the gradient of the targets
target.require_grad = False
#also the optimization, we onlyu want to include the computations the non-zero values, we don't want to use the movie that users didn't rate, we have already set the non-zero input target, but we haven't set the non-zero output, so set it
#equal to 0 means that it will not add up to the error that will affect the weight updating
output[target == 0] = 0
#compute the loss
loss = criterion(output, target)
#compute the mean corrector, number of movies/the number of movies predicted possitive, + 1e-10 means we want to make sure the 分母是非空的,所以加上1^-10,一个很小的数在分母上
#mean_corrector represent the average of the error by only considering the movies that were rated
mean_corrector = nb_movies/float(torch.sum(target.data > 0) + 1e-10)
#backward method for the loss, which will tell in which direction we need to update the different weights
loss.backward()
#update the train_loss and s
train_loss += np.sqrt(loss.item()*mean_corrector)
s += 1.
#differece between backward and optimizer.step, backward decides the dirction to which the weight will be updated, optimizer.step decides intensity of the updates that is the amount by which the weights will be updated
optimizer.step()
print('epoch: '+str(epoch)+' loss: '+str(train_loss/s))
#if the final loss = 1, means when we predict of a user is going to like a movie, on average we will make an error of one star one star out of five
# Testing the SAE
test_loss = 0
s = 0.
for id_user in range(nb_users):
input = Variable(training_set[id_user]).unsqueeze(0)
target = Variable(test_set[id_user])
if torch.sum(target.data > 0) > 0:
output = sae(input)
target.require_grad = False
output[(target == 0).unsqueeze(0)] = 0
loss = criterion(output, target)
mean_corrector = nb_movies/float(torch.sum(target.data > 0) + 1e-10)
test_loss += np.sqrt(loss.item()*mean_corrector)
s += 1.
print('test loss: '+str(test_loss/s))
#save the training model
#torch.save(sae, 'AutoEncoder.pkl')#you can use one of the function to save the training model
#torch.save(sae.state_dict(), 'AutoEncoder.pkl')
#next time you can using the following code to load the model you've trained, just replace 'sae = SAE()' with following code, and delete every code behind (loss computation)
#sae = torch.load('AutoEncoder.pkl')
#prediction
#定义prediction function
def Prediction(user_id, nb_recommend):
user_input = Variable(test_set[user_id - 1]).unsqueeze(0)
predict_output = sae.predict(user_input)
predict_output = predict_output.data.numpy()
predicted_result = np.vstack([user_input, predict_output])
trian_movie_id = np.array([i for i in range(1, nb_movies+1)])#create a temporary index for movies since we are going to delete some movies that the user had seen, 创建一个类似id的index,排序用
recommend = np.array(predicted_result)
recommend = np.row_stack((recommend, trian_movie_id))#insert that index into the result array, 把index插入结果
recommend = recommend.T#transpose row and col 数组的行列倒置
recommend = recommend.tolist()#tansfer into list for further process转化为list以便处理
movie_not_seen = []#delete the rows comtaining the movies that the user had seen 删除users看过的电影
for i in range(len(recommend)):
if recommend[i][0] == 0.0:
movie_not_seen.append(recommend[i])
movie_not_seen = sorted(movie_not_seen, key=itemgetter(1), reverse=True)#sort the movies by mark 按照预测的分数降序排序
recommend_movie = []#create list for recommended movies with the index we created 推荐的top20
for i in range(0, nb_recommend):
recommend_movie.append(movie_not_seen[i][2])
recommend_index = []#get the real index in the original file of 'movies.dat' by using the temporary index这20部电影在原movies文件里面真正的index
for i in range(len(recommend_movie)):
recommend_index.append(movies[(movies.iloc[:,0]==recommend_movie[i])].index.tolist())
recommend_movie_name = []#get a list of movie names using the real index将对应的index输入并导出movie names
for i in range(len(recommend_index)):
np_movie = movies.iloc[recommend_index[i],1].values#transefer to np.array
list_movie = np_movie.tolist()#transfer to list
recommend_movie_name.append(list_movie)
print('Highly Recommended Moives for You:\n')
for i in range(len(recommend_movie_name)):
print(str(recommend_movie_name[i]))
return recommend_movie_name
#recommendation for target user's id
user_id = 367
#the number of movies recommended for the user
nb_recommend = 20
movie_for_you = Prediction(user_id = user_id, nb_recommend = nb_recommend)
设置epoch=100,完成训练后平均误差:
test loss: 0.9647635596815916
输出推荐的电影:
Highly Recommended Moives for You:
[‘Waiting for Guffman (1996)’]
[‘Free Willy 2: The Adventure Home (1995)’]
[‘Salut cousin! (1996)’]
[‘8 Seconds (1994)’]
[‘Indian Summer (a.k.a. Alive & Kicking) (1996)’]
[‘Two if by Sea (1996)’]
[‘Grosse Pointe Blank (1997)’]
[‘101 Dalmatians (1996)’]
[‘Steal Big, Steal Little (1995)’]
[‘Aladdin and the King of Thieves (1996)’]
[‘Steel (1997)’]
[‘Shawshank Redemption, The (1994)’]
[‘Four Weddings and a Funeral (1994)’]
[‘Thin Blue Line, The (1988)’]
[‘Dracula: Dead and Loving It (1995)’]
[‘Silence of the Palace, The (Saimt el Qusur) (1994)’]
[‘Remains of the Day, The (1993)’]
[‘Good, The Bad and The Ugly, The (1966)’]
[‘Radioland Murders (1994)’]
[‘Usual Suspects, The (1995)’]