基于Scrapy框架下的Python网络爬虫的实现
项目简介:
通过使用Python爬虫框架Scrapy,完成互联网信息的提取
- 基于Scrapy项目的目录结构以及相关功能的介绍
- Scrapy的基本命令
- 图片类爬虫项目的实现
基于Scrapy项目的目录结构以及相关功能的介绍
使用Scrapy创建一个爬虫项目之后,会有如图所示的项目结构:
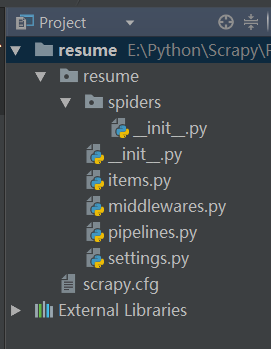
新建项目中的各文件的介绍如下:
1.resume/resume/__init__.py文件是resume项目的初始化文件,主要是该项目的初始化信息
2.resume/resume/items.py文件主要用于定义我们要获取的数据信息。假如我们想要获取网络上特定图片的链接以及图片名等信息,那在该文件中就可以进行如下的相应设置:
import scrapy
class QtpjtItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
picurl = scrapy.Field()
picname = scrapy.Field()
解决方法:File-Settings-Project:<创建的项目名>-Project Interpreter
3.resume/resume/pipelines.py文件是爬虫的管道文件,主要是用来对我们获取的数据(items文件里面定义的)进行进一步的加工处理
4.resume/resume/settings.py文件主要是爬虫项目的设置文件,比如爬虫的代理IP、代理用户、下载延时、禁止Cookie、下载中间件(middlewares.py)等等
5.resume/resume/spiders是爬虫项目的核心文件,在该项目中创建的所有网络爬虫都会放在该目录下
6.resume/resuem/__init__.py是爬虫项目中爬虫的初始化文件
7.resume/resume/middlewares.py文件是下载中间件文件,Python3.6会默认创建,如果想要编写自己的下载中间件文件,可删除该文件,并创建自己的middlewares文件
Scrapy的基本命令
Scrapy有两类命令:全局命令和项目命令
- 全局命令
- fetch:显示爬虫的爬取过程
- runspider:实现不依托Scrapy项目,直接运行一个爬虫文件
- settings:查看scrapy对应的配置信息
- shell:启动Scrapy的交互终端
- startproject:创建爬虫项目
- version:查看Scrapy的版本信息
- view:下载网页并直接用浏览器查看
- 项目命令
- Bench:测试本地硬件性能
- Genspider:查看当前可使用的爬虫模板,或基于某一爬虫模板创建爬虫
- Crawl:启动爬虫
- List:列出当前可用的爬虫文件
图片类爬虫项目的实现
项目目标:提取千图网(http://www.58pic.com/)上的简历模板的网址,下载模板并保存到本地文件中。为了防止IP被禁止,我们使用代理IP(需要编写相关的下载中间件文件),同时设置下载延时,并禁止Cookie。
- items.py文件的编写
我们要获取简历模板的网址(url)和相应id,在items文件中可以进行如下设置:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class QtpjtItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
picurl = scrapy.Field()
picid = scrapy.Field()
- settings.py文件的编写
使用代理IP,设置下载延时,禁止本地Cooike的相关设置都是在settings.py文件中。
首先,我们进行代理IP的设置,直接编辑setting.py文件并添加如下信息:
#IP池设置
IPPOOL = [
{"ipaddr": "175.43.106.232:808"},
{"ipaddr": "117.90.4.38:9000"},
{"ipaddr": "117.90.5.139:9000"},
{"ipaddr": "121.232.148.32:9000"},
{"ipaddr": "120.209.189.218:8998"},
{"ipaddr": "121.232.147.46:9000"},
{"ipaddr": "124.88.67.39:80"},
{"ipaddr": "58.222.254.11:3128"},
{"ipaddr": "61.185.219.126:3128"},
{"ipaddr": "121.232.147.241:9000"},
{"ipaddr": "121.232.144.34:9000"},
{"ipaddr": "113.74.53.204:808"},
{"ipaddr": "116.55.215.93:8998"},
{"ipaddr": "182.34.180.95:8998"},
{"ipaddr": "219.216.102.209:8998"},
{"ipaddr": "106.58.111.252:80"},
{"ipaddr": "114.103.217.194:8998"},
{"ipaddr": "121.232.144.159:9000"}
]设置好IP池之后,我们就可以来编写下载中间件文件。
- middlewares.py文件的编写
#middlewares
#coding:utf-8
from __future__ import unicode_literals
#导入随机数模块,目的是为了随机选择一个IP池里的IP
import random
#从settings文件导入设置好的IPPOOL
from qtpjt.settings import IPPOOL
#from scrapy.contrib.downloadermiddleware.httpproxy import HttpProxyMiddleware
#导入官方文档中HttpProxyMiddleware对应的模块
from scrapy.downloadermiddlewares.httpproxy import HttpProxyMiddleware
class IPPOOLS(HttpProxyMiddleware):
def __init__(self, ip=''):
self.ip = ip
def process_request(self, request, spider):
thisip = random.choice(IPPOOL)#随机选择一个IP
print "当前使用的IP是:"+thisip["ipaddr"]
#将对应的IP实际添加为具体的代理,用该IP进行爬取
request.meta["proxy"] = "http://"+thisip["ipaddr"]
编写好下载中间件文件之后,还需要在settings文件中进行相应设置,以使该下载中间件生效
在settings文件中,与下载中间件相关的配置信息如下:
# Enable or disable downloader middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'myxml.middlewares.MyCustomDownloaderMiddleware': 543,
#}
我们根据官方文档对这一部分的信息进行如下修改:
DOWNLOADER_MIDDLEWARES = {
# 'myxml.middlewares.MyCustomDownloaderMiddleware': 543,
'scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware': 123,
'qtpjt.middlewares.IPPOOLS': 125
}其中,qtpjt是下载中间件所在目录,middlewares是下载中间件文件名,IPPOOLS是下载中间件中需要用到的类
- pipelines.py文件的编写
# -*- coding: utf-8 -*-
from __future__ import unicode_literals
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import urllib
class QtpjtPipeline(object):
def process_item(self, item, spider):
#一个图片列表页中有多张图片,通过for循环依次将图片存储到本地
for i in range(0, len(item["picurl"])):
thispic = item["picurl"][i]
trueurl = thispic + "_1024.jpg"
# localpath = "E:/Python/Scrapy/Part1/qtpjt/resume/" +item["picid"][i]+ ".jpg"
#构造本地存储地址
localpath = "E:/Python/Scrapy/Part1/qtpjt/PPT/" +item["picid"][i]+ ".jpg"
#localpath = "E:/Python/Scrapy/Part1/qtpjt/pic/"+item["picid"][i]+".jpg"
#通过urllib.urlretrieve()将原图片下载到本地
urllib.urlretrieve(trueurl, filename=localpath)
return item
将settings.py文件中关于pipelines文件的配置部分修改如下
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'qtpjt.pipelines.QtpjtPipeline': 300,
}最后,我们来编写爬虫文件
- resume.py文件的编写
# -*- coding: utf-8 -*-
from __future__ import unicode_literals
import scrapy
import re
from qtpjt.items import QtpjtItem
from scrapy.http import Request
class ResumeSpider(scrapy.Spider):
name = "resume"
#允许爬取的域名
allowed_domains = ["58pic.com"]
#开始爬取的网址
start_urls = ['http://www.58pic.com/jieri/249/']
def parse(self, response):
item = QtpjtItem()
#构建提取缩略图网址的正则表达式
paturl = "(http://pic.qiantucdn.com/58pic/.*?).jpg"
item["picurl"] = re.compile(paturl).findall(str(response.body))
#构建提取图片名的正则表达式,以便构建本地的文件名
patlocal = '程序设计完成之后,可以在命令行中运行该爬虫:

此时,爬虫已经开始运行,五分钟之后,爬取效果如图:
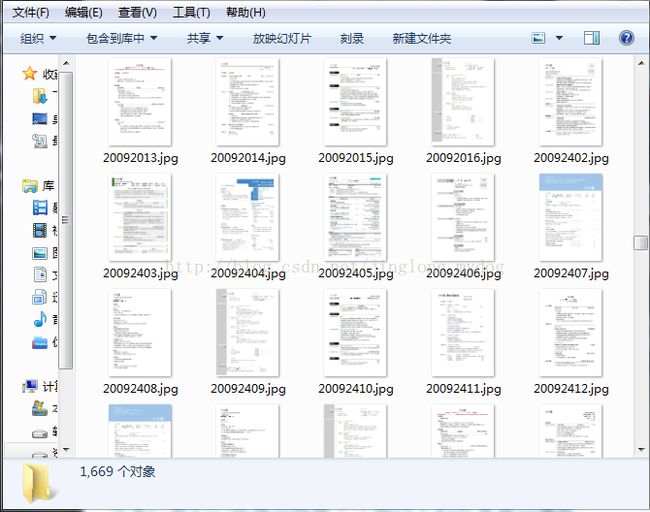
可见,我们已经成功爬取了千图网上的简历模板。
参考书籍:《精通Python网络爬虫》——韦玮