Python带你了解数据结构【一】
我们学过计算机的童鞋们都知道算法与数据结构一直是大家逃不掉的噩梦,那么今天小编就带大家来看看用python来解读这些数据结构是否会变得简单一点呢?
数据结构,顾名思义就是存放数据的结构,结构的不同会导致我们增删改查数据的效率也大不相同,所以为了能够高效的操作数据,我们需要了解数据结构,并且在适当的情况下使用特定的数据结构。
举个简单的例子,我现在期中考试的成绩出来了,我需要登记大家期中考试的成绩,这个时候我们需要使用什么数据类型?
大家都知道python里面有list和tuple这两种数据类型。现在我们需要一份名单,并且需要在这份名单上做更新和修改处理,那对应的我们需要选择什么数据结构呢?因为需要做修改的操作,所以我们选择list作为我们存储数据的主要方式。当登记完所有的成绩,我们需要把成绩发放到各位同学手中,这个时候为了保证每个人的真实成绩都是不可被修改的,我们又需要改变数据结构,选择tuple类型,来确保每个同学的成绩都是不可被修改的!
上面这个例子就是告诉我们,在不同的时候,我们往往需要选择不同的数据结构来存储对应的数据,以确保我们能够高效的访问或者修改数据,这也就是我们需要学习数据结构的初衷了~
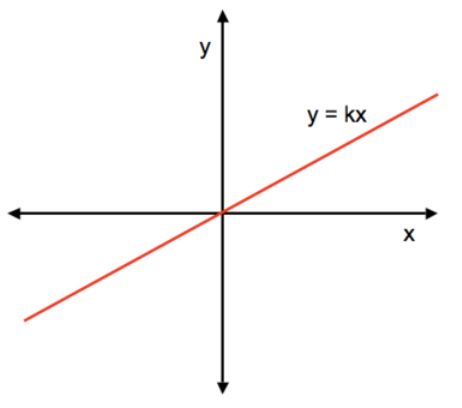
首先,关于数据结构,我们主要分为两类,线性结构和非线性结构,线性结构中的元素都是一一对应的关系,而非线性结构可能存在一对多,多对多的关系。举个例子,一次函数:y=kx(一条直线),x和y的值都是一一对应的,这种关系就是线性结构。
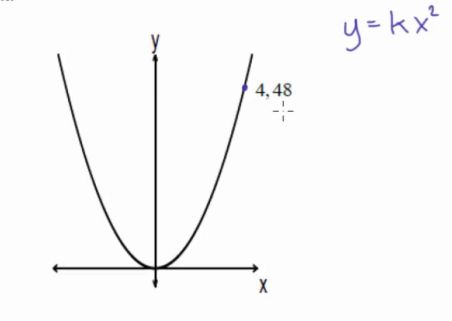
但是像y=kx^2,这种结构就属于非线性结构了,一个y对应两个x的值。
线性结构里面主要有数组(Array),栈(Stack),队列(Queue),链表(Linked List)
非线性结构主要是:树(Tree),图(Graph),堆(Heap),散列表(Hash)
今天我们主要来看看线性结构。
数组(Array)
数组,将具有相同类型的若干变量有序地组织在一起的集合就是数组。在python里面,list就是数组。
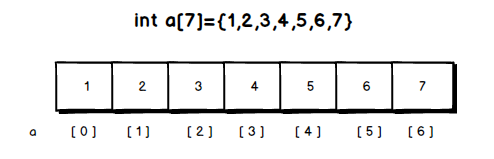
array = [1, 2, 3, 4, 5, 6, 7]
使用中括号包围,将里面的多个元素用逗号隔开,这就是数组了。对于数组我们如何进行它的增删改查操作呢?
数组是一个有序的集合,所以在数组中,每个元素都有一个与之对应的索引,通过这个索引我们就能取到这个值。
print(array[0])
获取索引为0的元素的值
关于数组的修改操作:
修改元素值
array[0] = 5
中间插入新的值
array.insert(0, 5)
尾部插入新的值
array.append(5)
删除值
array.remove(5)链表(Linked List)
说了数组就不得不说和数组相似的链表,链表的定义是不连续(这个不连续是针对于物理存储而言),没有顺序的数据结构。是由多个节点组成的。
从下图中我们可以看出,链表好像就是一个单向传递的过程,总是由上一个传向下一个(这就是单链表),并且每个节点都是由两部分组成,一部分存放数据,一部分指向下一个节点。这就像接力赛跑一样,每个队员都需要将自己的接力棒传向下一个队员。
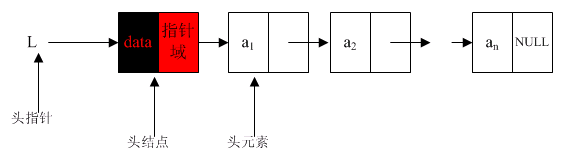

(链表和数组的区别)
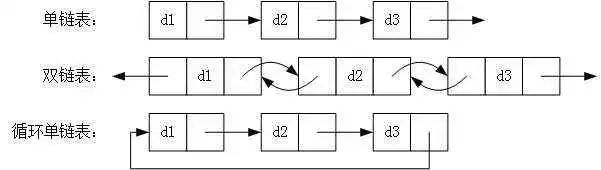
链表分为单链表,双链表和循环链表,我们这边以简单常见的单链表为例。谈谈,简单链表的python实现
链表是由多个不同的节点构成的,所以我们需要定义一个节点,一个节点主要包含两部分,一部分是指针,指向下一组数据,另一部分是存放数据的信息。
class Node(object):
#初始化,需要传入节点的数据
def __init__(self, data):
self.data = data
self.next = None
作为节点类,要具备一些常用的方法,获取节点数据,获取下个节点,更新节点的数据,更新下个节点,这些都可以定义在node类里面。
#返回节点的数据
def get_data(self):
return self.data
#更新节点的数据
def set_data(self, new_data):
self.data = new_data
#返回后继节点
def get_next(self):
return self.next
#变更后继节点
def set_next(self, new_next):
self.next = new_next
定义完节点后,我们就可以来实现简单的链表了。
首先来说一下链表的添加:添加操作,如果是插入操作,需要删除原有的指针,将被删除的指针重新指向新的节点,新的节点指向原来节点指向的那个节点。如果是添加在头部,只需要将新的节点指向头节点即可。
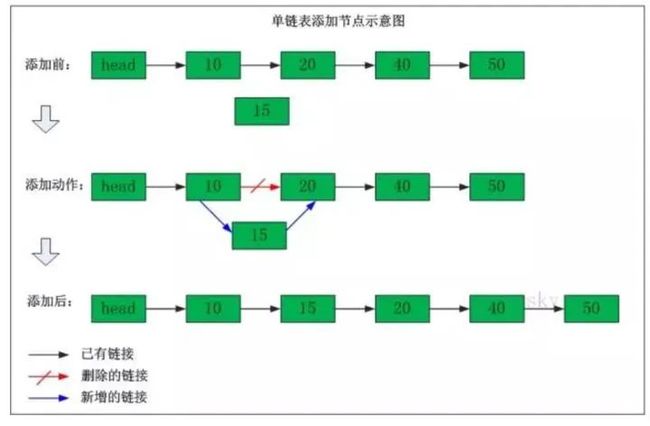
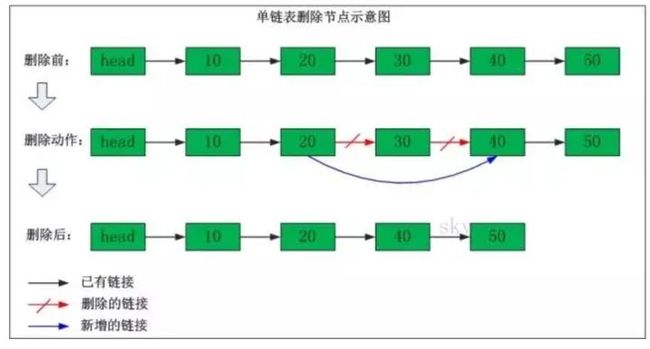
删除操作,需要将被删节点的前一个节点直接指向被删节点的后一个节点即可。
# Reference codes:https://www.jianshu.com/p/e4000619232bclass Linked_list:
# 初始化,头结点为空
def __init__(self):
self.head = None
# 添加节点,添加的新节点作为新的头结点
def add(self, data):
new_node = Node(data)
new_node.set_next() = self.head
self.head = new_node
# 包含查询,传入值,返回该值在链表中是否存在
def search(self, data):
checking = self.head # 从头结点开始查询
while checking != None:
if checking.get_data() == data: # 查找到,返回True
return True
checking = checking.get_next() # 查询下一个节点
return False # 遍历到最后也未能找到,返回False
# 删除节点,将第一个具有传入值的节点从链表中删除
def remove(self, data):
checking = self.head # 从头结点开始查询
previous = None # 记录前一个节点,头结点的前一个节点为None
while checking != None:
if checking.get_data() == data: # 查找到,跳出查找循环
break
previous = checking # 更新前一个节点
checking = checking.get_next() # 查询下一个节点
if previous == None: # 如果头结点便是查找的节点
self.head = checking.get_next()
else: # 查找的节点不在头节点,即,存在前驱节点
previous.set_next(checking.get_next())
# 判断链表是否为空
def isEmpty(self):
return self.head == None
# 返回链表长度
def size(self):
count = 0
counting = self.head # 从头结点开始计数
while counting != None:
count += 1
counting = counting.get_next()
return count以上我们便实现了一个简单的链表。而关于双链表和循环链表呢,与单链表不同的是,双链表多了一个头指针,每个节点既可以指向上个节点也可以指向下个节点。循环链表的特点就是最后一个节点的指针指向头节点。
栈(Stack)
栈,也是一种线性的数据结构,他有个最经典的特征就是FILO(先进后出原则)。
先进后出是什么意思呢?打个比方,你现在有个羽毛球球桶,当你需要打球的时候,通常会在球桶顶端拿球,打完了放回去的时候,却不能放在顶端,只能从底部塞入,再次去拿球的时候,只能从顶部去拿新的球,这就是这就是栈。(下图有误,应该是从哪放就从哪拿)

如何用python实现栈呢?我们使用python中的list来实现十分简单。因为栈的特性,它的删除操作只能从栈顶开始删,所以移除的元素都是栈顶元素,添加元素也只能从栈底添加。
class Stack:
# 初始化栈为空列表
def __init__(self):
self.items = []
# 判断栈是否为空
def is_empty(self):
return self.items == []
# 返回栈顶
def peek(self):
return self.items[len(self.items) - 1]
# 返回栈的大小
def size(self):
return len(self.items)
# 入栈
def push(self, item):
self.items.append(item)
# 出栈
def pop(self, item):
return self.items.pop()队列(Queue)
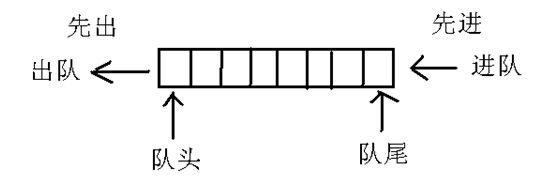
队列,也是一种线性的数据结构,它和栈正好相反,它的特征是FIFO(先进先出原则)。
先进先出的意思是:打个比方,一个n节的火车进入了隧道,最先出隧道的那节车厢肯定就是最先入隧道的那节车厢了,这就是队列。
和上面一样,我们也可以使用list来实现一个队列:
class Queue:
def __init__(self):
self.items = []
def enqueue(self, item):
self.items.append(item)
def dequeue(self):
return self.items.pop(0)
def empty(self):
return self.size() == 0
def size(self):
return len(self.items)
python里面也有自带queue(队列)这样一个模块,可以直接使用。(这里我们就不提python里面其他的队列了,例如LifoQueue,PriorityQueue)
import queue
q = queue.Queue(3) # 调用构造函数,初始化一个大小为3的队列
print(q.empty()) # 判断队列是否为空,也就是队列中是否有数据
# 入队,在队列尾增加数据, block参数,可以是True和False 意思是如果队列已经满了则阻塞在这里,
# timeout 参数 是指超时时间,如果被阻塞了那最多阻塞的时间,如果时间超过了则报错。
q.put(13, block=True, timeout=5)
print(q.full()) # 判断队列是否满了,这里我们队列初始化的大小为3
print(q.qsize()) # 获取队列当前数据的个数
# block参数的功能是 如果这个队列为空则阻塞,
# timeout和上面一样,如果阻塞超过了这个时间就报错,如果想一只等待这就传递None
print(q.get(block=True, timeout=None))
# queue模块还提供了两个二次封装了的函数,
q.put_nowait(23) # 相当于q.put(23, block=False)
q.get_nowait() # 相当于q.get(block=False)以上,便是线性数据结构的python版本的介绍,下期我们将聊聊:非线性的数据结构,欢迎「转发」或者点击「在看」支持!
“扫一扫,关注我吧”
