urllib库的使用
urllib库包含了四个模块分别是:
request:基本的http请求模块,用来模拟发送请求。
error:异常处理模块,捕获请求中的异常,然后进行重试或其他的操作以保证程序不会意外终止。
parse:一个根据模块,提供了如拆分、解析、合并等的许多URL处理方法。
robotparser:主要用来识别网站的robots.txt文件,然后判断哪些网站可以爬,哪些不能。
request模块:
下面利用这个模块将淘宝的首页抓取下来:
import urllib.request
respons = urllib.request.urlopen('https://www.taobao.com')#http请求对象
print(respons.read().decode('utf-8'))#调用http请求对象的read()方法读取对象的内容并以utf-8的格式显示出来respons对象主要包含read()、readinto()、getheader(name)、getheaders()、fileno()等方法,以及msg、version、status、reason、debuglevel、closed等属性。下面看一个例子:
import urllib.request
respons = urllib.request.urlopen('https://www.baidu.com')
print(respons.status)
print(respons.getheaders())
print(respons.getheader('Server'))运行结果:
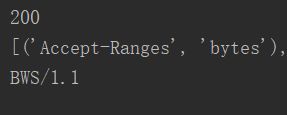
分别得到了访问百度时的响应状态码和响应的头信息,然后响应头中的Server值是BWS/1.1,表明服务器是用此搭建的。
下面再详细说明各参数的用法:
data:这是一个可选参数,并且如果它是字节流编码格式的内容,即bytes类型,则需要通过bytes()方法转化,它的请求方式是POST方式。下面来看一个例子:
import urllib.parse
import urllib.request
data = bytes(urllib.parse.urlencode({'word':'hello'}),encoding='utf8')
respons = urllib.request.urlopen('http://httpbin.org/post',data=data)
print(respons.read())
运行结果如下:
{
"args": {},
"data": "",
"files": {},
"form": {
"word": "hello"
},
"headers": {
"Accept-Encoding": "identity",
"Connection": "close",
"Content-Length": "10",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "Python-urllib/3.6"
},
"json": null,
"origin": "223.87.203.60",
"url": "http://httpbin.org/post"
}bytes()方法的第一个参数是str类型,需要用urllib.parse模块的urlencode()方法来将参数字典转化为字符串,第二个参数指定编码格式为utf8,我们传递的参数在form字段中,表明是模拟了表单提交的方式。
timeout:用于设置超时时间,例如:
import socket
import urllib.request
import urllib.error
try:
response = urllib.request.urlopen('http://httpbin.org/get',timeout=0.1)
except urllib.error.URLError as e:
if isinstance(e.reason,socket.timeout):
print('TIME OUT')我们请求 http://httpbin.org/get 测试连接,设置超时时间是0.1秒,然后捕获了URLError异常,接着判断异常是socket.timeout类型(超时异常),从而得出它确实是因为超时而报错,输出TIME OUT。
由于urlopen()只是实现最基本请求的发起,并不足以构建一个完整的请求,比如在请求中加入Headers等信息,因此更多的是用Request,下面来看一个Request用法的实例:
import urllib.request
request = urllib.request.Request('https://www.baidu.com')
response = urllib.request.urlopen(request)
print(response.read().decode('utf8'))在这个例子中,我们用Request对象来代替URL,这样一来既可以将请求独立成一个对象,又可以更加丰富和灵活地配置参数。Request的构造方法如下: class urllib.request.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)
其中url是用于请求的URL,是必传的。
参数data如果要传就必须是bytes类型,如果它是字典,可以先用urllib.parse模块里的urlencode()编码。
headers是一个字典,也就是请求头,可以在构造请求时通过headers参数直接构造,也可以通过调用请求示例的add_header()方法添加。添加请求头最常用的用法就是通过修改User-Agent来伪装浏览器。
origin_req_host指的是请求方的host名称或者ip地址。
unverifiable表示这个请求是否是无法验证的,默认是False,就是说用户没有足够的权限来选则接收这个请求的结果。比如我们要抓取一篇HTML文档中的图片,但是没有权限,这时它的值就为True。
method是一个字符串,用来指示请求使用的方法,比如GET、POST、PUT。
下面来看一个例子:
from urllib import request,parse
url = 'http://httpbin.org/post'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36',
'Host':'httpbin.org'
}
dict = {
'name':'Germey'
}
data = bytes(parse.urlencode(dict),encoding='utf8')
req = request.Request(url=url,data=data,headers=headers,method='POST')
response = request.urlopen(req)
print(response.read().decode('utf-8'))运行结果如下:
{
"args": {},
"data": "",
"files": {},
"form": {
"name": "Germey"
},
"headers": {
"Accept-Encoding": "identity",
"Connection": "close",
"Content-Length": "11",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36"
},
"json": null,
"origin": "223.87.203.60",
"url": "http://httpbin.org/post"
}另外,headers也可以用add_header()方法来添加:
req = request.Request(url=url,data=data,method='POST')
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36')
使用urlretrieve()方法将抓取到的网页保存下来:(参数分别是要抓取的网页和保存的文件名)
from urllib import request
request.urlretrieve('https://baijiahao.baidu.com/s?id=1603000490958603018&wfr=spider&for=pc','index.html')高级用法
上面这些方法虽然可以用来构造请求,但是对于一些更高级的操作比如Cookies和代理等就难以处理了。这时候就需要更强大的工具Handler,我们可以把它简单的理解为处理器,又专门处理登录验证的,处理Cookies的和代理设置的,利用它们可以做到HTTP请求中所有的事情。
首先看到urllib.request模块里的BaseHandler类,它是所有其它Handler的父类,它提供了最基本的方法,例如default_open()、protocol_request()等。接下来就列举一些子类:
HTTPDefaultErrorHandler:用于处理HTTP响应错误,错误都会抛出HTTPError类型的异常。
HTTPRedirectHandler:用于处理重定向。
HTTPCookieProcessor:用于处理Cookies。
ProxyHandler:用于设置代理,默认代理为空。
HTTPPasswordMgr:用于管理密码,它维护了用户名和密码的表。
HTTPBasicAuthHandler:用于管理认证,如果一个连接打开时需要认证,就可以用它来解决认证问题。
下面来看看几个例子:
对于有些网站,在打开的时候就要求输入用户名和密码验证成功以后才能查看页面,对于这样的页面就需要用HTTPBasicAuthHandler来完成:
from urllib.request import build_opener,HTTPPasswordMgrWithDefaultRealm,HTTPBasicAuthHandler
from urllib.error import URLError
username ='username'
password = 'password'
url = 'http://localhost:5000'
p = HTTPPasswordMgrWithDefaultRealm()#创建一个HTTPPasswordMgrWithDefaultRealm对象
p.add_password(None,url,username,password)#将用户名和密码添加进去
#实例化HTTPBasicAuthHandler对象建立一个处理验证的Handler
auth_handler = HTTPBasicAuthHandler(p)
# 使用build_opener方法构建一个Opener,发送请求的时候就相当于验证成功了
opener = build_opener(auth_handler)
try:
result = opener.open(url)
html = result.read().decode('utf-8')
print(html)
except URLError as e:
print(e.reason)在爬虫中如果需要添加代理,那么可以这样:
from urllib.error import URLError
from urllib.request import ProxyHandler,build_opener
#在本地搭建一个代理,它运行在9743端口
proxy_handler = ProxyHandler({
'http':'http://127.0.0.1:9743',
'https':'https://127.0.0.1:9743'
})#参数是字典,键名是协议类型,键值是代理连接,可添加多个代理
#利用这个Handler及build_opener()方法构造一个Opener发送请求即可
opener = build_opener(proxy_handler)
try:
response = opener.open('https://www.baidu.com')
print(response.read().decode('utf-8'))
except URLError as e:
print(e.reason)Cookies:
Cookies的处理就需要相关的Handler了,首先需要将网站的Cookies获取下来:
import http.cookiejar,urllib.request
cookie = http.cookiejar.CookieJar()#声明一个CookieJar对象
handler = urllib.request.HTTPCookieProcessor(cookie)#用HTTPCookieProcessor来构建一个Handler
opener = urllib.request.build_opener(handler)#构建一个Opener
response = opener.open('http://www.baidu.com')
for item in cookie:
print(item.name+'='+item.value)运行结果是:
BAIDUID=B22318A394394F6EA032B060C4F59382:FG=1
BIDUPSID=B22318A394394F6EA032B060C4F59382
H_PS_PSSID=1459_21108_28132_28267
PSTM=1547544199
delPer=0
BDSVRTM=0
BD_HOME=0
这里输出了每条Cookie的名称和值。下面来看看将Cookie保存到文件中:
import http.cookiejar,urllib.request
filename = 'cookies.txt'
cookie = http.cookiejar.MozillaCookieJar(filename)#声明一个MozillaCookieJar对象
#MozillaCookieJar类是Cookiejar的子类,用来处理Cookies和文件相关的事件,比如读取和保存Cookies
handler = urllib.request.HTTPCookieProcessor(cookie)#用HTTPCookieProcessor来构建一个Handler
opener = urllib.request.build_opener(handler)#构建一个Opener
response = opener.open('https://www.csdn.net/')
cookie.save(ignore_discard=True,ignore_expires=True)那生产了Cookies文件以后怎样从文件中读取并利用呢?下面举个例子来看看:
import http.cookiejar,urllib.request
filename = 'cookies.txt'
cookie = http.cookiejar.MozillaCookieJar()
cookie.load('cookies.txt',ignore_discard=True,ignore_expires=True)#调用load方法读取本地的Cookies文件,获取到其内容
handler = urllib.request.HTTPCookieProcessor(cookie)#创建handler
opener = urllib.request.build_opener(handler)#创建opener
response = opener.open('https://blog.csdn.net/weixin_38241876')
print(response.read().decode('utf-8'))异常处理
在网络不好的情况下程序可能会因报错而终止运行,这时异常处理就很重要了。
URLError是error异常模块的基类,由request模块生成的异常都可以通过捕获这个类来处理。
HTTPError是URLError的子类,专门用来处理HTTTP请求错误,比如认证请求失败等,它有三个属性,code:返回HTTP状态码。reason:返回错误的原因。headers:返回请求头。下面举个例子:
from urllib import request,error
try:
response = request.urlopen('http://abcdefg.com/index.html')
except error.HTTPError as e:
print(e.reason,e.code,e.headers,sep='\n')运行结果:
Not Found
404
Date: Tue, 15 Jan 2019 10:25:32 GMT
X-ServedBy: web034
Strict-Transport-Security: max-age=0
Expires: Thu, 01 Jan 1970 00:00:00 GMT
Content-Type: text/html; charset=UTF-8
X-PC-AppVer: 16681
X-PC-Date: Thu, 03 Jan 2019 12:54:09 GMT
X-PC-Host: 10.194.4.23
Last-Modified: Tue, 15 Jan 2019 02:18:17 GMT
ETag: W/"d7b919c5e5f0bea9a4e92940825b69a4"
X-PC-Key: 37O9qPjo18q_vykLB-yBYK1WHLQ-brass-bat-2mfd
X-PC-Hit: true
Vary: Accept-Encoding
Age: 0
X-Varnish: varnish-web005
Set-Cookie: crumb=BXxMs02ghpuKNTkxMWNmYTI0MDQ3Njg0YzdjN2YwMTEwN2VhYTkw;Path=/
Transfer-Encoding: chunked
Connection: close
x-contextid: O4v3bmIs/j56h9SDu
x-via: 1.1 echo026由于HTTPError是URLError的子类,所以可以先选则捕获子类的错误,然后捕获父类的错误:
from urllib import request,error
try:
response = request.urlopen('http://abcdefg.com/index.html')
except error.HTTPError as e:
print(e.reason,e.code,e.headers,sep='\n')
except error.URLError as e:
print(e.reason)
else:
print('请求成功!')这样一来如果不是HTTPError异常,就会捕获URLError异常,输出错误原因。
有时候reason属性返回的不是一个字符串而是一个对象,先看一个例子:
import socket
import urllib.request
import urllib.error
try:
response = urllib.request.urlopen('https://www.baidu.com',timeout=0.01)
except urllib.error.URLError as e:
print(type(e.reason))
if isinstance(e.reason,socket.timeout):
print('TIME OUT')运行结果为:
TIME OUT
这里的reason属性是socket.timeout类,所以我们这里可以用isinstance()方法来判断它的类型。
解析连接
urllib库提供了parse模块用以处理URL的标准接口,例如实现URL各部分的抽取,合并以及连接转换。
urlparse()方法实现url的识别和分段:
from urllib.parse import urlparse
result = urlparse('https://market.m.taobao.com/apps/abs/10/297/x7m9k?spm=a2166.8043889.305590.6.59e87482PoG2FO&wh_weex=true&psId=1650038')
print(type(result),'\n',result)结果为:
ParseResult(scheme='https', netloc='market.m.taobao.com', path='/apps/abs/10/297/x7m9k', params='', query='spm=a2166.8043889.305590.6.59e87482PoG2FO&wh_weex=true&psId=1650038', fragment='')
返回结果是一个ParseResult对象,由scheme、netloc、path、params、query、fragment这六部分组成,分别代表协议、域名、访问路径、参数、查询条件、锚点。
urlunparse()方法接受的参数是一个可迭代对象,但它的长度必须是6,先来看一个例子:
from urllib.parse import urlunparse
data = ['http','www.taobao.com','index.html','user','a=8','comment']
print(urlunparse(data))运行结果为:;user?a=8#http://www.taobao.com/index.htmlcomment这样就实现了一个url的构造。
urlsplit()与urlparse()的区别就在于它不再单独解析params这部分。比如:
from urllib.request import urlsplit
result = urlsplit('https://blog.csdn.net/weixin_38241876/article/details/86487901')
print(result)SplitResult(scheme='https', netloc='blog.csdn.net', path='/weixin_38241876/article/details/86487901', query='', fragment='')
这是一个元组类型。
urljoin():首先提供一个base_url(基础链接)作为第一个参数,将新的连接作为第二个参数,该方法会分析base_url的scheme、netloc和path三个内容并对新连接缺失的部分进行补充返回最后的结果。例如:
from urllib.parse import urljoin
print(urljoin('http://www.taobao.com/index.html','.htmlcomment'))输出:http://www.taobao.com/.htmlcomment
urlencode()在构造GET()请求参数的时候非常有用,例如:
from urllib.parse import urlencode
params = {
'name':'germey',
'age':22
}#表示参数的字典
base_url = 'http://www.baidu.com?'
url = base_url + urlencode(params)#序列化为GET请求参数
print(url)利用parse_qs()方法可以将一个GET请求转回字典:
from urllib.parse import parse_qs
print(parse_qs('http://www.baidu.com?name=germey&age=22'))如果要将内容转化为URL编码的格式,就需要用quote()方法,有时候URL中带有中文,可能会出现乱码,就需要将中文字符转化为URL编码:
from urllib.parse import quote
keyword = '百度'
url = 'https://www.baidu.com/s?wd=' + quote(keyword)
print(url)结果如下:https://www.baidu.com/s?wd=%E7%99%BE%E5%BA%A6
利用unquote()方法可以实现解码:
from urllib.parse import unquote
print(unquote('https://www.baidu.com/s?wd=%E7%99%BE%E5%BA%A6'))结果为:https://www.baidu.com/s?wd=百度
Robots协议
也叫爬虫协议,用来告诉爬虫和搜索引擎哪些页面可以爬取,哪些不能。当搜索爬虫访问一个站点时,它首先会检查这个站点根目录下是否存在robots.txt文件,如果存在则会根据其中的爬取范围来爬取,如果没有这个文件,爬虫就会访问所以可直接访问的页面。
robotparser模块可用于解析robotts.txt,这个模块提供了一个RobotFileParser可以根据某网站的robots.txt文件来判断一个爬虫是否有权限来爬取这个页面,它有如下一些方法:
set_url():用来设置robots.txt文件的链接,如果在创建RobotFileParser对象时传入了链接就不需要使用这个方法来设置了。
read():读取robots.txt文件并进行分析,这个方法执行一个读取和分析操作,这个方法必须调用。
parse():用来解析robots.txt文件,传入robots.txt某些行的内容,它会按照robots.txt的语法规则来分析这些内容。
can_fetch():传入User-agent和要抓取的URL,返回是否可以抓取这个URL,只有Ture和False。
mtime():返回上次抓取和分析robots.txt的时间。
modified():将当前时间设置为上次抓取和分析robots.txt的时间。
现在看一个例子:
from urllib.robotparser import RobotFileParser
rp = RobotFileParser()
rp.set_url('http://www.jianshu.com/robots.txt')
rp.read()
print(rp.can_fetch('*','http://www.jianshu.com/p/b67554025d7d'))
print(rp.can_fetch('*','http://www.jianshu.com/search?q=python&page=1&type=collections'))结果为False表示不能抓取。