最新 Python3 爬取前程无忧招聘网 mysql和excel 保存数据
Python 爬虫目录
1、最新 Python3 爬取前程无忧招聘网 lxml+xpath
2、Python3 Mysql保存爬取的数据 正则
3、Python3 用requests 库 和 bs4 库 最新爬豆瓣电影Top250
4、Python Scrapy 爬取 前程无忧招聘网
5、持续更新…
本文更新于2020年08月06日
原本的网站未升级维护,升级后的网站,采用了js渲染数据部分,所以本文将采用selenium web框架
本文爬取网站为https://search.51job.com/list/000000,000000,0000,00,9,99,%25E6%2595%25B0%25E6%258D%25AE%25E5%2588%2586%25E6%259E%2590,2,1.html?
本文选用的是lxml模块,xpath语法提取数据
推荐谷歌用户一个可以帮助xpath调试的插件
Xpath Helper

1、进行分析网站
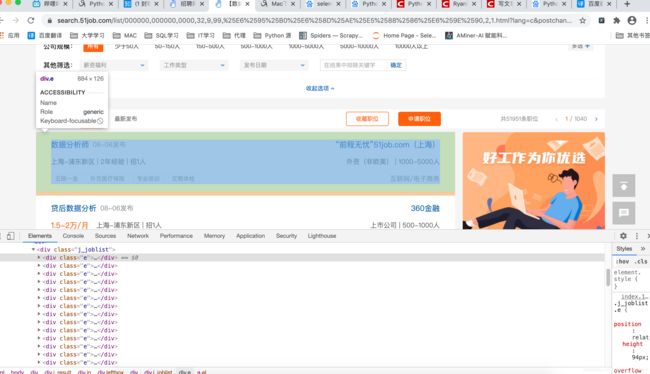
**
要爬取的职位名、公司名、工作地点、薪资的信息都在class="e"里
**

分析完就可以用xpath 语法进行调试了
完整代码如下:
from selenium import webdriver
from lxml import etree
import time
import xlwt
import pymysql
# 启动时不启动浏览器
option = webdriver.ChromeOptions()
option.add_argument('headless')
def get_url(url):
browser = webdriver.Chrome(options=option)
browser.get(url)
html_text = browser.page_source
# browser.quit()
# time.sleep(5)
return html_text
def get_data(url):
html_text = get_url(url)
dom = etree.HTML(html_text)
dom_list = dom.xpath(
'//div[@class="j_result"]/div[@class="in"]/div[@class="leftbox"]//div[@class="j_joblist"]//div[@class="e"]')
Job_list = []
for t in dom_list:
# 1.岗位名称
job_name = t.xpath('.//a[@class="el"]//span[@class="jname at"]/text()')[0]
# print(job_name)
# 2.发布时间
release_time = t.xpath('.//a[@class="el"]//span[@class="time"]/text()')[0]
# 3.工作地点
address = t.xpath('.//a[@class="el"]//span[@class="d at"]/text()')[0]
# 4.工资
salary_mid = t.xpath('.//a[@class="el"]//span[@class="sal"]')
salary = [i.text for i in salary_mid][0] # 列表解析
# 5.公司名称
company_name = t.xpath('.//div[@class="er"]//a[@class="cname at"]/text()')[0]
# 6.公司类型和规模
company_type_size = t.xpath('.//div[@class="er"]//p[@class="dc at"]/text()')[0]
# 7.行业
indusrty = t.xpath('..//div[@class="er"]//p[@class="int at"]/text()')[0]
JobInfo = {
'job_name': job_name,
'address': address,
'salary': salary,
'company_name': company_name,
'company_type_size':company_type_size,
'industry':indusrty,
'release_time':release_time
}
Job_list.append(JobInfo)
# print(Job_list)
# 保存至excel
book = xlwt.Workbook(encoding='utf-8',style_compression=0)
sheet = book.add_sheet("职业信息", cell_overwrite_ok=True) # sheet表名为职业信息
col = ('job_name', 'address', 'salary', 'company_name','company_type_size','industry','release_time') # 列名
# 标题设置样式
style1 = xlwt.XFStyle()
al = xlwt.Alignment()
al.horz= 0x02 #水平居中
style1.alignment = al
# 内容设置样式
style = xlwt.XFStyle()
alignment = xlwt.Alignment()
alignment.horz = 0x01 #左对齐
style.alignment = alignment
for i in range(0,7):
sheet.write(0, i, col[i],style1)
for i ,item in enumerate(Job_list):
sheet.write(i + 1, 0, item['job_name'],style)
sheet.write(i + 1, 1, item['address'],style)
sheet.write(i + 1, 2, item['salary'],style)
sheet.write(i + 1, 3, item['company_name'],style)
sheet.write(i + 1, 4, item['company_type_size'],style)
sheet.write(i + 1, 5, item['industry'],style)
sheet.write(i + 1, 6, item['release_time'],style)
book.save("职业信息.xls")
print('保存成功')
# 保存至mysql
# 创建连接
db = pymysql.Connect(
host='localhost', # mysql服务器地址
port=3306, # mysql服务器端口号
user='root', # 用户名
passwd='123123', # 密码
db='save_data', # 数据库名
charset='utf8' # 连接编码
)
# 创建游标
cursor = db.cursor()
sql = """CREATE TABLE job_info(
ID INT PRIMARY KEY AUTO_INCREMENT ,
job_name VARCHAR(100) ,
address VARCHAR (100),
salary VARCHAR (30),
company_name VARCHAR (100) ,
company_type_size VARCHAR (100),
industry VARCHAR (50),
release_time VARCHAR (30)
);
"""
cursor.execute(sql)
for i in Job_list:
insert = "INSERT INTO job_info(" \
"job_name,address,salary,company_name,company_type_size,industry,release_time" \
")values(%s,%s,'%s',%s,%s,%s,%s)"%(repr(i['job_name']),repr(i['address']),i['salary'],repr(i['company_name']),repr(i['company_type_size']),repr(i['industry']),repr(i['release_time']))
cursor.execute(insert)
db.commit()
db.close
if __name__ == '__main__':
for i in range(1,201):
print('开始存储第'+str(i)+'条数据中')
url_pre = 'https://search.51job.com/list/000000,000000,0000,00,9,99,%25E6%2595%25B0%25E6%258D%25AE%25E5%2588%2586%25E6%259E%2590,2,'
url_end = '.html?'
url = url_pre + str(i) + url_end
get_data(url)
time.sleep(3)
print('存储完成')
完成后效果
mysql 存储
Excel 存储