python常见数据结构全攻略
常见数据结构
一、String(字符串)
1、基本使用
-
创建字符串
# 创建字符串 str1 = str("lucky is a good man") # 基本类型字符串在使用是会自动转变为字符串对象类型 str1 = 'lucky is a nice man' -
运算
# 字符串运算 str3 = "lucky is a cool man" str4 = "lucky is a handsome man" # 字符串加法(字符串拼接) str5 = str3 + str4 print("str5= %s"%(str5)) # 字符串乘法(重复字符串) str6 = str3 * 3 print("str6= %s"%(str6)) -
成员判断
# 成员判断 str7 = "lucky is a good man" print("lucky" in str7) -
内容获取
# 内容获取 str8 = "lucky is a good man" # 根据下标(索引)获取字符串中的内容,下标从0开始 # 字符串[下标] print(str8[2]) # 截取字符串中的一部分 字符串[start:stop] [start, stop) print(str8[1:4]) print(str8[1:]) print(str8[:4]) -
格式化打印
%s %d %f 格式化字符串 格式化整数 格式化浮点数字,可指定小数点后的精度 name = "lucky" age = 18 height = 175.5 print("我叫%s,我今年%d岁,身高%f,具体身高%.1f" % (name, age, height, height)) # 已知print的内容默认是打印在一行的,另一个print会另起一行再打印 # end默认为\n print("lucky is a good", end="*") print(" man")
2、常用转义字符
\n |
\t |
\\ |
\" |
\' |
|---|---|---|---|---|
| 换行符 | 横向制表符 | 反斜杠 | 双引号 | 单引号 |
str12 = "su\\nc\tk is a go\no m\"a'n"
print(str12)
# 如果字符串里有很多字符需要转义,就需要加入很多\,为了简化,python允许使用r""表示,""内部的字符串默认不转义
# \\\t\\
print("\\\t\\")
print("\\\\\\t\\\\")
print(r"\\\t\\")
3、比较大小
原理:按顺序从两个字符串中从左侧开始获取字符,比较两个字符,谁的阿斯科玛值大那么就是哪个字符串大,如果相等,则继续比较下一个
str1 = "abc"
str2 = "ab"
print(str1 > str2)
4、内置功能
注意:字符串本身是不可以改变的
-
eval()
原型:eval(str)
功能:将字符串当成有效的表达式来求值并返回结果
返回值:计算后得到的数字num = eval("123") print(num, type(num)) # print(int("12+3")) #报错 print(eval("12+3")) print(eval("+123")) print(eval("-123")) print(eval("12-3")) print(eval("12*3")) #注意:字符串中有非数字字符会报错(数学运算符除外) # print(eval("12a3")) #报错 # print(eval("a123")) #报错 # print(eval("123a")) #报错 # 表示的是变量是可以的 a = "124" print(eval("a")) # print(eval("a+1")) #报错 -
len(string)
原型:len(str)
功能:计算字符串的长度(按字符个数计算)
参数:一个字符串
返回值:字符串的长度print(len("lucky is a good man")) print(len("lucky is a good man凯")) -
lower()
原型:lower()
功能:将字符串中所有大写英文字母转为小写str1 = "lucky Is a GoOd MAn!" str2 = str1.lower() print(str1) print(str2) -
upper()
原型:upper()
功能:将字符串中所有小写英文字母转为大写str3 = "lucky Is a GoOd MAn!" str4 = str3.upper() print(str3) print(str4) -
swapcase()
原型:swapcase()
功能:将字符串中的大写英文字母转为小写,小写英文字母转为大写str5 = "lucky Is a GoOd MAn!" str6 = str5.swapcase() print(str5) print(str6) -
capitalize()
原型:capitalize()
功能:将字符串中第一个字符转为大写,其余转为小写str7 = "lucky Is a GoOd MAn!" str8 = str7.capitalize() print(str7) print(str8) -
title()
原型:title()
功能:得到“标题化”的字符串,每个单词的首字符大写,其余小写str9 = "lucky Is a GoOd MAn!" str10 = str9.title() print(str10) -
center(width[, fillchar])
功能:返回一个指定width宽度的居中字符串,fillchar为填充字符串,默认为空格
print("lucky".center(20, "#")) -
ljust(width[, fillchar])
功能:返回一个指定width宽度的左对齐字符串,fillchar为填充字符串,默认为空格
print("lucky".ljust(20, "#")) -
rjust(width,[, fillchar])
功能:返回一个指定width宽度的右对齐字符串,fillchar为填充字符串,默认为空格
print("lucky".rjust(20, "#")) -
zfill (width)
功能:返回一个指定width宽度的右对齐字符串,默认填充0
print("lucky".zfill(20)) -
count(str[, beg= 0[,end=len(string)]])
功能:返回str在string中出现的次数,如果beg或者end指定则返回指定范围内的出现次数
str11 = "lucky is a very very good man very" print(str11.count("very")) print(str11.count("very", 13)) print(str11.count("very", 13, 25)) -
find(str[, beg=0[, end=len(string)]])
功能:检测str是否包含在string中,默认从左到右查找,如果存在则返回第一次出现的下标,否则返回-1,如果beg或者end指定则在指定范围内检测
str12 = "lucky is a very very good man" print(str12.find("very")) # print(str12.find("nice")) -
index(str[, beg=0[, end=len(string)]])
功能:检测str是否包含在string中,默认从左到右查找,如果存在则返回第一次出现的下标,否则返回异常(报错),如果beg或者end指定则在指定范围内检测
str13 = "lucky is a very very good man" print(str13.index("very")) # print(str13.index("nice")) -
rfind(str[, beg=0[,end=len(string)]])
功能:检测str是否包含在string中,默认从右到左查找,如果存在则返回第一次出现的下标,否则返回-1,如果beg或者end指定则在指定范围内检测
-
str12 = "lucky is a very very good man" print(str12.rfind("very")) # print(str12.rfind("nice")) -
rindex(str[, beg=0[, end=len(string)]])
功能:检测str是否包含在string中,默认从右到左查找,如果存在则返回第一次出现的下标,否则返回异常(报错),如果beg或者end指定则在指定范围内检测
str13 = "lucky is a very very good man" print(str13.rindex("very")) # print(str13.rindex("nice")) -
lstrip([char])
功能:截掉字符串左侧指定的字符,默认为空格
str14 = " lucky is a good man" str15 = str14.lstrip() print(str14) print(str15) str16 = "######lucky is a good man" str17 = str16.lstrip("#") print(str16) print(str17) -
rstrip([char])
功能:截掉字符右左侧指定的字符,默认为空格
str18 = "lucky is a good man " str19 = str18.rstrip() print(str18,"*") print(str19,"*") -
strip([chars])
功能:在字符串上执行lstrip和rstrip
-
split(str=" "[, num=string.count(str)])
功能:按照str(默人空格)切割字符串,得到一个列表,列表是每个单词的集合
str20 = "lucky is a good man" print(str20.split()) print(str20.split(" ")) str21 = "lucky####is##a#good#man" print(str21.split("#")) -
splitlines([keepends])
功能:按照行(’\r’、’\r\n’、’\n’)切割,如果keepends为False,不包含换行符,否则包含换行符
str22 = """good nice cool handsome """ print(str22.splitlines()) print(str22.splitlines(False)) print(str22.splitlines(True)) -
join(seq)
功能:指定字符拼接列表中的字符串元素
str23 = "lucky is a good man" li = str23.split() str24 = "##".join(li) print(str24) -
max(str)
功能:返回字符串中最大的字符
print(max("abcdef")) -
min(str)
功能:返回字符串中最小的字符
print(min("abcdef")) -
replace(old, new[, max])
功能:将字符串中的old替换为new,如果没有指定max值,则全部替换,如果指定max值,则替换不超过max次
str25 = "lucky is a good good good man" str26 = str25.replace("good", "cool") print(str26) -
maketrans()
功能:创建字符映射的转换表
t = str.maketrans("un", "ab") -
translate(table, deletechars="")
功能:根据给出的转换表转换字符
str27 = "lucky is a good man" str28 = str27.translate(t) print(str28) -
isalpha()
功能:如果字符串至少有一个字符并且所有的字符都是英文字母则返回真,否则返回假
print("abc".isalpha()) print("ab1c".isalpha()) -
isalnum()
功能:如果字符串至少有一个字符并且所有的字符都是英文字母或数字字符则返回真,否则返回假
print("abc1".isalnum()) print("abc".isalnum()) print("1234".isalnum()) -
isupper()
功能:如果字符串至少有一个字符并且所有的字母都是大写字母则返回真,否则返回假
print("12AB".isupper()) print("12ABc".isupper()) -
islower()
功能:如果字符串至少有一个字符并且所有的字母都是小写字母则返回真,否则返回假
-
istitle()
功能:如果字符串是标题化的则返回真,否则返回假
-
isdigit()
功能:如果字符串只包含数字则返回真,否则返回假
print("1234".isdigit()) print("1234a".isdigit()) -
isnumeric()
功能:如果字符串只包含数字则返回真,否则返回假
-
isdecimal()
功能:检测字符串是否只包含十进制数字
-
isspace()
功能:如果字符串只包含空白符则返回真,否则返回假
print("".isspace()) print(" ".isspace()) print("\t".isspace()) print("\n".isspace()) print("\r".isspace()) print("\r\n".isspace()) print(" abc".isspace()) -
startswith(str[, beg=0[,end=len(string)]])
功能:检测字符串是否以str开头,是则返回真,否则返回假,可指定范围
str29 = "lucky is a good man" print(str29.startswith("kaige")) -
endswith(suffix, beg=0, end=len(string))
功能:检测字符串是否以str结尾,是则返回真,否则返回假,可指定范围
-
encode(encoding=‘UTF-8’,errors=‘strict’)
功能:以encoding指定的编码格式进行编码,如果出错报一个ValueError的异常,除非errors指定的值是ignore或replace -
str30 = "lucky是一个好男人" str31 = str30.encode() print(str31, type(str31)) -
bytes.decode(encoding=“utf-8”, errors=“strict”)
功能:以encoding指定的格式进行解码,注意解码时使用的格式要与编码时的一致
str32 = str31.decode("GBK", errors="ignore") print(str32, type(str32)) -
ord()
功能:获取字符的整数表示
print(ord("a")) -
chr()
功能:把数字编码转为对应的字符
print(chr(97)) -
str()
功能:转为字符串
num1 = 10 str33 = str(num1) print(str33, type(str33))
二、list列表
1、什么情况下使用列表?
-
思考
存储5个人的年龄,求他们的平均值
age1 = 18 age2 = 19 age3 = 20 age4 = 21 age5 = 22 -
思考
存储100个人的年龄
-
解决
使用列表
2、基本使用
-
本质
是一个有序集合
-
创建列表
''' 创建列表 格式:列表名 = [元素1, 元素2, ……, 元素n] ''' # 创建空列表 li1 = [] print(li1, type(li1)) # 创建带有元素的列表 # 注意:列表中元素的类型可以不同,但是在今后的开发中一般不存在这种状况 li2 = [1, 2, 3, 4, 5, "good", True] print(li2) -
列表元素的访问
# 列表元素的访问 li3 = [1,2,3,4,5] # 往列表末尾添加元素 li3.append(6) # 获取元素 列表名[下标] print(li3[2]) # print(li3[9]) #下标超出范围,溢出 # print(li3[-1]) # 下标可以是负数,-1表示最后一个元素的下标,-2表示倒数第二个,依次类推 # 修改元素 列表名[下标] = 值 li3[2] = 33 # li3[6] = 10 #下标不存在 print(li3) # 截取列表 print(li3[1:3]) print(li3[1:]) print(li3[:3]) -
列表操作
# 列表相加(列表组合) li4 = [1,2,3] li5 = [4,5,6] li6 = li4 +li5 print(li6)# 列表相乘(列表重复) li7 = [7,8,9] li8 = li7 * 3 print(li7) print(li8)# 成员判断 li9 = [1,2,3] print(1 in li9) print(4 in li9)
3、二维列表
概念:列表中的元素是一位列表的列表
本质:一维列表
li1 = [[1,2,3],
[4,5,6],
[7,8,9]]
print(li1[1][1])
4、内置功能
-
append(obj)
在列表的末尾添加一个新的元素
li1 = [1,2,3,4,5] li1.append(6) li1.append([7,8,9]) print(li1) -
extend(seq)
在列表的末尾一次追加多个元素
li2 = [1,2,3,4,5] li2.extend([6,7,8]) print(li2) -
insert(index, obj)
将元素obj按下标插入列表,不会覆盖原数据,原数据会按顺序后移
li3 = [1,2,3,4,5] li3.insert(2, 100) print(li3) -
pop(index=-1)
移除列表中指定下标出的元素,默认移除最后一个,返回被删掉的数据
li4 = [1,2,3,4,5] data = li4.pop() print(data, li4) -
remove(obj)
移除列表中第一次出现的obj元素
li5 = [1,2,3,4,5,2,4,2,5,6,7] li5.remove(2) print(li5) -
clear()
清空列表
li6 = [1,2,3,4,5] li6.clear() print(li6) -
count(obj)
返回元素obj在列表中出现的次数
li7 = [1,2,3,4,5,2,4,2,5,6,7] print(li7.count(2)) -
len(seq)
返回列表中元素的个数
li8 = [1,2,3,4,5] print(len(li8)) -
index(obj)
在列表中获取元素第一次出现的下标,没有则会抛出ValueError异常
li9 = [1,2,3,4,5,2,4,2,5,6,7] print(li9.index(2)) -
max(seq)
返回列表中最大的元素
print(max([2,3,4,1,4,6,7,3])) -
min(seq)
返回列表中最小的元素
-
reverse()
列表倒序
li10 = [1,2,3,4,5] li10.reverse() print(li10) -
sort()
根据func函数给定的规则进行列表元素的排序,默认升序
li11 = [2,1,3,5,4] li11.sort() print(li11) -
list(seq)
将其他类型的集合转为列表类型
str1 = "lucky" li12 = list(str1) print(li12, type(li12))
5、内存问题
-
赋值
-
==与is
num1 = 1 num2 = 1 print(id(num1), id(num2)) print(num1 == num2) print(num1 is num2) num3 = 401 num4 = 401 print(id(num3), id(num4)) print(num3 == num4) print(num3 is num4) -
赋值
a = [1,2,3,4,5] b = a print(id(a), id(b)) print(a == b) print(a is b)c = [1,2,3,4,5,[7,100,9]] d = c print(c == d) print(c is d) c[5][0] = 60 print(c) print(d)
-
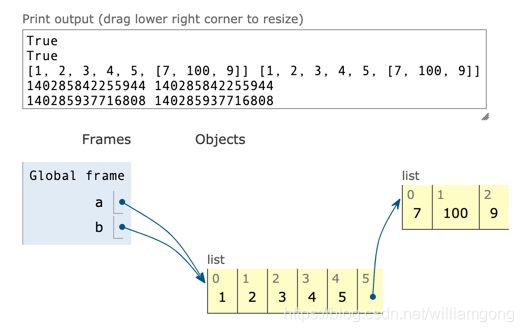
-
浅拷贝
只拷贝表层元素
from copy import copy a = [1,2,3,4,5] b = copy(a) print(id(a), id(b)) print(a == b) print(a is b) c = [1,2,3,[4,5,6]] d = copy(c) print(id(c), id(d)) print(c == d) print(c is d) print(id(c[3]), id(d[3])) print(c[3] == d[3]) print(c[3] is d[3])
-
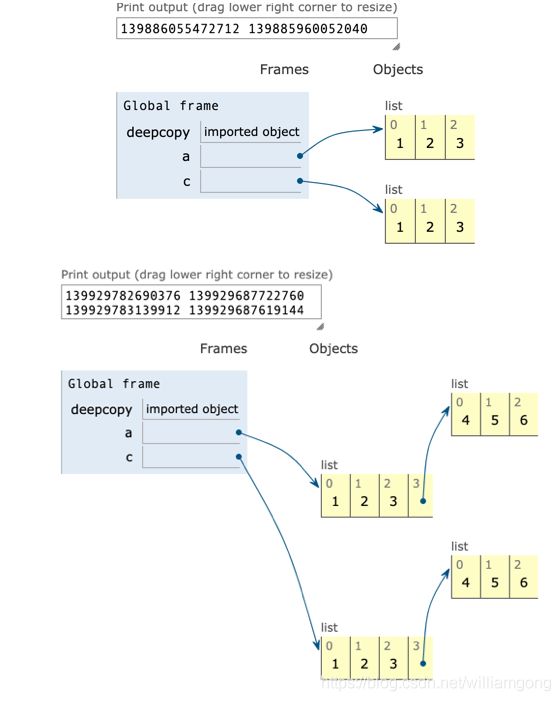
深拷贝
注意:不论深拷贝还是浅拷贝都会在内存中生成一片新的内容空间(把拷贝的内容在内存中重新创建一份)
两者有区别的前提:元素中有另外的列表
说明:深拷贝在内存中重新创建所有子元素
from copy import deepcopy a = [1,2,3,4,5] b = deepcopy(a) print(id(a), id(b)) print(a == b) print(a is b) c = [1,2,3,4,5,[6,7,8]] d = deepcopy(c) print(id(c), id(d)) print(c == d) print(c is d) print(id(c[5]), id(d[5])) print(c[5] == d[5]) print(c[5] is d[5])

三、tuple元组
1、概述
-
本质
有序集合
-
特性
- 与列表非常相似
- 一旦初始化就不能修改
- 使用小括号
2、基本使用
-
创建
''' 创建格式: 元组名 = (元素1, 元素2, ……, 元素n) ''' # 创建空元祖 t1 = () print(t1, type(t1)) # 创建带元素的元组,元组的元素类型可以不同 t2 = (1,2,3,4,5) print(t2) # 创建含有一个元素的元组,需要加一个逗号 t3 = (1,) print(t3, type(t3)) -
元组元素的访问
# 取值 元组名[下标] t4 = (1,2,3,4,5) print(t4[2]) # print(t4[7]) #下标越界 print(t4[-1]) # print(t4[-7]) #下标越界 # 注意:元素是不能修改的,但是如果元组的元素是列表类型,那么列表中元素是可以修改的 t5 = (1,2,3,4,5,[6,7,8]) # t5[3] = 100 # 报错 # t5[5] = [1,2,3] # 报错 t5[5][0] = 60 print(t5) -
元组操作
t6 = (1,2,3) t7 = (4,5,6) t8 = t6 + t7 print(t8, t6, t7) print(t6 * 3) -
元组截取
t9 = (1,2,3,4,5,6,7,8,9,0) print(t9[3:7]) print(t9[3:]) print(t9[:7]) print(t9[3:-2]) -
元组对称赋值
# 用于函数返回多个返回值 num1, num2 = (1, 2) # 如果只有一个占位符,可以省略小括号,但是最好不要省略 print("num1 = %d"%num1) print("num2 = %d"%(num2))
3、操作方法
-
len(seq)
print(len((1,2,3,4))) -
max()
-
min()
-
tuple(seq)
将其他类型的集合转为元组类型
print(tuple("lucky")) print(tuple([1,2,3,4]))
四、dict字典
1、概述
-
概念
使用键值对(key-value)的形式存储数据,具有极快的查找速度
-
特性
-
字典中的key必须唯一
-
键值对是无序的
-
key必须是不可变对象
a:字符串、数字都是不可变的,可以作为key(一般为字符串)
b:列表是可变的,不能作为key
-
-
思考
保存一个学生的信息(姓名、学号、性别、年龄、身高、体重)
str1 = "lucky#1#男#18#173.5#80" li1 = ["lucky", 1, "男", 18, 173.5, 80] t1 = ("lucky", 1, "男", 18, 173.5, 80) -
问题解决
使用字典
定义格式:字典名 = {key1:value1, key2:value2,……,keyn:valuen}
2、基本使用
-
创建
# 创建一个字典保存一个学生信息 stu1 = {"name": "lucky", "age": 18, "sex": "男", "height": 173.5, "weight":80, "id": 1} stu2 = {"name": "liudh", "age": 57, "sex": "男", "height": 180, "weight":75, "id": 2} stus = [stu1, stu2] -
访问字典的值
stu3 = {"name": "lucky", "age": 18, "sex": "男", "height": 173.5, "weight":80, "id": 1} # 获取 字典名[key] print(stu3["name"]) # print(stu3["money"]) #获取不存在的属性值会报错 # 获取 字典名.get(key) print(stu3.get("age")) print(stu3.get("money")) # 获取不存在的属性会得到None money = stu3.get("money") if money: print("money = %d"%money) else: print("没有money属性") -
添加键值对
# 添加键值对,没有的键会添加,有的会修改 stu3["nikeName"] = "kaige" stu3["age"] = 16 -
删除
stu3.pop("nikeName") print(stu3)
3、比较list与dict
-
list
优点:占用的内存空间小,浪费的内存很少
缺点:查找和插入的效率会随着元素的增多而降低
-
dict
优点:查找和插入的速度极快,不会随着key-value的增多而降低效率
缺点:需要占用大量的内存,内存浪费过多
五、set集合
1、概述
特性:与dict类似,是一组key的集合(不存储value)
本质:无序和无重复的集合
2、基本使用
-
创建
#创建:需要用一个list或者tuple作为输入集合 s1 = set([1,2,3,4,5]) print(s1, type(s1)) s2 = set((1,2,3,4,5)) print(s2, type(s2)) s3 = set("lucky") print(s3, type(s3)) -
作用
# 作用:列表去重 li1 = [1,2,4,6,7,5,4,3,22,2,3,46,7,8,1,3,5] s4 = set(li1) li2 = list(s4) print(li2) -
添加
s5 = set([1,2,3,4,5]) # 不能直接插入一个数字元素 # s5.update(6) # 报错 # s5.update([6,7,8]) # s5.update((6,7,8)) # s5.update("678") s5.update([(6,7,8)]) print(s5) -
删除
s6 = set([1,2,3,4,5]) # 从左侧开始删除 data = s6.pop() print(data, s6) # 按元素删除,如果元素不存在报KeyError的异常 s6.remove(4) # s6.remove(7) print(s6) -
遍历
s7 = set([1,2,3,4,5]) for key in s7: print("--------", key) for index, key in enumerate(s7): print(index, key)
3、交集与并集
s8 = set([1,2,3,4,5])
s9 = set([3,4,5,6,7])
#交集
print(s8 & s9)
#并集
print(s8 | s9)
六、空值
说明:是python中一个特殊的值,用None表示
注意:None不能理解为0,因为0是有意义的,而None是没有任何实际意义的
作用:
1、定义变量时,不知道初始值要赋值成什么,可以写赋值为None。当你有确定的值时在进行赋值
2、在字典中查找数据时,如果没有找到会返回一个None
c = None
print(c)
七、变量类型问题
变量的类型要根据对应的数据来判断具体是什么类型,变量的类型是变化的
a = 1
print(a, type(a))
a = "lucky"
print(a, type(a))
a = True
print(a, type(a))
八、类型转换
1、list/tuple/string->set
s1 = set([1,2,3,4,5])
s2 = set((1,2,3,4,5))
s3 = set("lucky")
print(s1, s2, s3)
2、tuple/set/string ->list
l1 = list((1,2,3,4,5))
l2 = list(set([1,2,3,4,5]))
l3 = list("lucky")
print(l1, l2, l3)
3、list/set/string->tuple
t1 = tuple([1,2,3,4,5])
t2 = tuple(set([1,2,3,4,5]))
t3 = tuple("lucky")
print(t1, t2, t3)
九、可更改(mutable)与不可更改(immutable)对象
1、说明
在 python 中,strings, tuples, 和 numbers 是不可更改的对象,而 list,dict 集合则是可以修改的对象
2、不可变类型
变量对应的值中的数据是不能被修改,如果修改就会生成一个新的值从而分配新的内存空间
不可变类型:
- 数值(int,float,bool)
-
字符串(string)
-
元组(tuple)

结果:两个不同的存储地址
3、可变类型
变量对应的值中的数据可以被修改,但内存地址保持不变
可变类型:
列表(list)
字典(dict)
集合(set)

结果:两个相同的存储地址
[‘刘备’, ‘关羽’, ‘张飞’, ‘赵云’]

结果:两个相同的存储地址
{‘name’: ‘刘备’, ‘age’: 20}
