python初级实战系列教程《二、爬虫之爬取网页小说》
上节中我们学习了下简单的爬虫技术,本节我们将写一个爬取网页小说的小项目。
1、首先介绍下Beautiful Soup库
官方介绍如下:
Beautiful Soup 提供一些简单的、python 式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。Beautiful Soup 自动将输入文档转换为 Unicode 编码,输出文档转换为 utf-8 编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup 就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。
PyCharm上安装Beautiful Soup:
File -> Default Settings -> Project Interpreter 选择Python的版本
-> 点+号 -> 搜索bs4 安装即可
(注意:Python3的选择bs4进行安装,Python2的选择beautifulSoup)
2、开始爬取小说
网络上随便找个小说就好,这里我们选用,笔趣看的《寒门状元》作为本文要爬取的小说《http://www.biqukan.com/2_2537/》

1、打开网址,然后打开Chrome开发者工具(或者右键,检查)
然后选择Elements
找到如图位置就是我们各个章节的标题 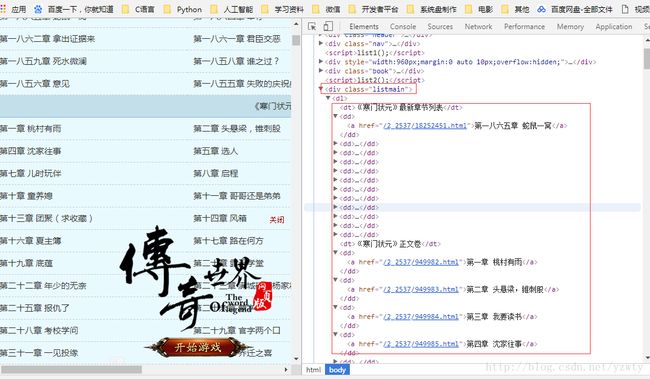
直接find_all(attrs={‘class’: ‘listmain’}) 就可以得到这块东西了
print出来如下:
<div class="listmain">
<dl>
<dt>《寒门状元》最新章节列表dt>
<dd><a href="/2_2537/18252451.html">第一八六五章 蛇鼠一窝a>dd>
<dd><a href="/2_2537/18240646.html">第一八六四章 举荐a>dd>
<dd><a href="/2_2537/18228084.html">第一八六三章 对峙之局a>dd>
<dd><a href="/2_2537/18215275.html">第一八六二章 拿出证据来a>dd>
<dd><a href="/2_2537/18201746.html">第一八六一章 君臣交恶a>dd>
<dd><a href="/2_2537/18187177.html">第一八六〇章 朕没错a>dd>
<dd><a href="/2_2537/18177340.html">第一八五九章 死水微澜a>dd>
<dd><a href="/2_2537/18164126.html">第一八五八章 谁之过?a>dd>
<dd><a href="/2_2537/18152522.html">第一八五七章 护送潜逃a>dd>
<dd><a href="/2_2537/18142239.html">第一八五六章 意见a>dd>
<dd><a href="/2_2537/18131445.html">第一八五五章 失败的庆祝典礼a>dd>
<dd><a href="/2_2537/18117712.html">第一八五四章 毒鸡汤a>dd>
<dt>《寒门状元》正文卷dt>
<dd><a href="/2_2537/949982.html">第一章 桃村有雨a>dd>
<dd><a href="/2_2537/949983.html">第二章 头悬梁,锥刺股a>dd>
<dd><a href="/2_2537/949984.html">第三章 我要读书a>dd>
<dd><a href="/2_2537/949985.html">第四章 沈家往事a>dd>
<dd><a href="/2_2537/949986.html">第五章 选人a>dd>
<dd><a href="/2_2537/949987.html">第六章 争夺a>dd>我们只需把对应的章节找出来即可,所以我们只要把第x章 这样的找出来
然后切片找出第一章到最后一章即可
list_a = []
for i in all_chapter:
for j in i.find_all('a'):
list_a.append(j)
title_list=list_a[12:]
print(title_list)
打印结果如下:
"/2_2537/949982.html">第一章 桃村有雨,
"/2_2537/949983.html">第二章 头悬梁,锥刺股,
"/2_2537/949984.html">第三章 我要读书
...其中”http://www.biqukan.com“+herf (即为每张的内容url)
我们打开第一章内容http://www.biqukan.com/2_2537/949982.html
然后打开Chrome开发者工具(或者右键,检查)
然后选择Elements 
直接find_all(attrs={‘class’: ‘showtxt’}) 就可以得到小说每章的内容了。
得到内容就可以写到文件保存下来了。
完整代码如下:
from bs4 import BeautifulSoup
import urllib.request
from urllib import error
#小说地址
novel_url = "http://www.biqukan.com/2_2537/"
#小说内容前半部分地址
content_base_url = "http://www.biqukan.com"
#小说保存的路径
novel_dir = 'MyNovel/'
#获取所有章节的url和title
def get_url_title():
try:
chapter_request = urllib.request.Request(novel_url)
chapter_response = urllib.request.urlopen(chapter_request, timeout=20)
chapter_content = chapter_response.read()
#使用BeautifulSoup
chapter_beautiful_soup = BeautifulSoup(chapter_content, 'html.parser')
all_chapter = chapter_beautiful_soup.find_all(attrs={"class": "listmain"})
list_a = []
for i in all_chapter:
for j in i.find_all('a'):
list_a.append(j)
#去掉不需要的...
url_title_list = list_a[12:]
return url_title_list
except error.URLError as reason:
print(str(reason))
#下载小说
def down_navel_content(url_title):
#拼接每章的url
contents_url = content_base_url+url_title.attrs.get('href')
#每获取章节名字
content_title = url_title.string
try:
chapter_request = urllib.request.Request(contents_url)
chapter_response = urllib.request.urlopen(chapter_request, timeout=30)
chapter_content = chapter_response.read()
#使用BeautifulSoup
chapter_beautiful_soup = BeautifulSoup(chapter_content, 'html.parser')
#获取小说内容
contents = chapter_beautiful_soup.find_all(attrs={"class": "showtxt"})
for txt in contents:
save_navel(txt, novel_dir+content_title+'.txt')
except error.URLError as reason:
print(str(reason))
def save_navel(content, path):
try:
with open(path, 'w+')as f:
#unicode中的‘\xa0’字符在转换成gbk编码时会出现问题,gbk无法转换'\xa0'字符。
# 所以,在转换的时候必需进行一些前置动作:string.replace(u'\xa0', u' ')
#get_text(strip=True)是去掉空格和换行
f.write(content.get_text(strip=True).replace(u'\xa0', u' '))
except error.URLError as reason:
print(str(reason))
else:
print('下载完成')
if __name__ == '__main__':
novel_chapter = get_url_title()
for chapter in novel_chapter:
down_navel_content(chapter)纸上得来终觉浅,绝知此事要躬行
我,秦始皇,打赏… 
