信用卡评分模型学习笔记总结
一些基本概念
M1,M2,M3,…
M表示月份,简单理解逾期多少个月了
评分卡类型
反欺诈评分卡,申请评分卡,行为评分卡,催收评分卡
是对未来一段时间内违约/逾期/失联概率的预测,概率越高,分数越低,越不安全。
一.申请评分卡模型
用在申请环节,以申请当日及过去信息为基础,预测未来放款的违约概率。
申请评分卡常用的特征
个人信息:学历 性别 收入
负债信息:在本金融机构或其他机构的负债情况
消费能力:商品购买记录
历史信用记录:历史逾期行为
新兴数据:人际社交,网络足迹,出行
非平衡样本的解决方法
过采样 容易过拟合
欠采样 容易丢失信息
SMOTE算法 不能对有缺失值和类别变量做处理
SMOTE算法介绍:
采样K近邻
从K近邻中随机挑选N个样本进行随机线性插值
new=xi+rand(0,1)*(yj-xi),j=1…N
其中xi为少类中的一个观测点,yj为从K近邻中随机抽取的样本。
申请评分卡的模型构造过程
1.数据预处理:时间格式,缺失值,极值
2.特征构造:计数,比例,距离
3.特征选择:相关性 差异性 显著性
4.模型参数估计:回归系数 模型复杂度
数据预处理:
带%的百分比,需要转化为浮点数
日期格式需要转化为python的时间
工作年限中将“<1year ”转化为0 “>10years”转化为11
文本类数据的处理:主题提取
缺失值处理
补缺 或者 作为一种状态
构建特征:
计数:过去1年内申请贷款的次数
求和:过去1年内网店消费总额
比例:贷款申请额度占年收入比例
时间差:第一次开户距今时长
波动率:过去3年内每份工作的工作时间标准差
特征分箱
将连续变量离散化或者把多状态的离散变量合并成少状态
一方面避免特征中无意义的波动对评分带来的波动,使其更加稳定。
另一方面避免了极端值的影响。同时可以将缺失值作为独立的一个箱
将所有变量变换到相似的尺度
特征分箱方法:
有监督
best-ks:让分箱后组别的分布的差异性变大
对于连续变量x,将其排序得到{x1,x2,x3,…,xk},计算没一点的KS值,选取最大的KS对应的特征值xm,将x分为两部分。重复以上分箱步骤,直到满足终止条件
终止条件有:
下一步分箱后,最小的箱占比低于设定的阈值(0.05)
下一步分箱后,该箱子全部为某一类
下一步分享后,badrate不单调
卡方分箱(比Best-KS应用更广,可用于多类)
将具有最小卡方值的相邻区间合并在一起,直到满足终止条件
首先,预先设定卡方阈值
根据要离散的属性进行排序
计算每一对相邻区间的卡方值,将卡方值最小的一对区间进行合并
卡方阈值的确定
根据显著性水平和自由度,推荐使用0.9,0.95,0.99置信度,区间数目大概10到15.
无监督
等频 等距 聚类
WOE编码
经验上讲,WOE的绝对值波动范围在0.1到3
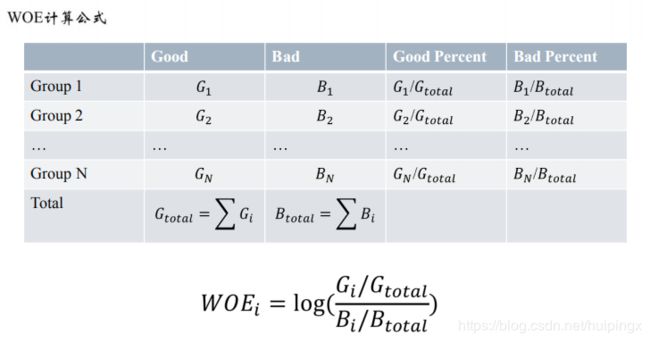
WOE要求回归模型系数为负
变量挑选
变量之间的共线性易造成信息冗余,降低显著性,甚至导致符号失真
挑选依据
带约束:Lasso
特征重要性:随机森林
模型拟合优度和复杂度:基于AIC的逐步回归
变量信息度:IV
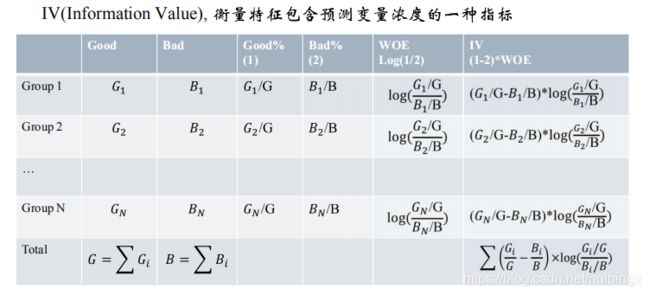

过高的IV可能会有潜在的风险,只能用于二分类的目标变量
<=0.02 没有预测性 不用
0.02 to 0.1 弱预测
0.1 to 0.2 一定预测
0.2+ 高预测
单变量分析和多变量分析
单变量分析:变量的显著性(IV),变量的分布,变量的业务含义
需要检验IV是否达到阈值
bad rate单调 (可以放宽到U型)
单一区间占比不能过高
多变量分析:共线性
相关性高的话:
选择IV高的,选择分箱均衡的

逻辑回归在申请评分卡的应用


逻辑回归的变量挑选
lasso 逐步回归 随机森林
lasso
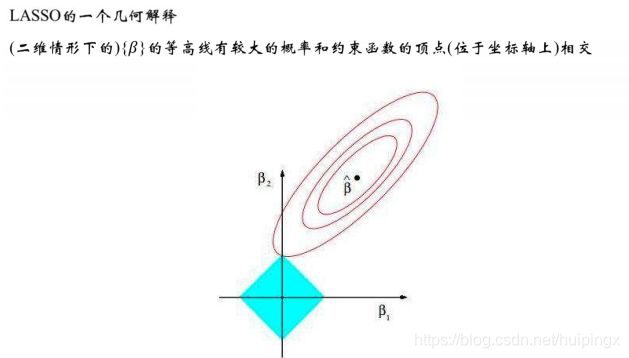
随机森林的特征重要性
对于每棵决策树,利用袋外的数据进行预测,记录其误差,将特征扰动重新计算误差项,前后两次误差的差值作为衡量特征重要性的指标。
带权重的逻辑回归
由于误判代价不同,增加逾期类样本的权重

评分卡模型评价标准
模型的区分度
KS:好坏人群的分数的分布差异
将样本按概率由高到低排序,计算好样本占总的好样本的累积比例和坏样本占总的坏样本的累积比例,两条曲线在Y轴方向上的相差最大值就是KS
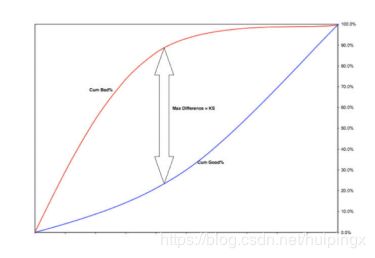
KS阈值
>0.3:好
0.2 to 0.3:可用
0 to 0.2 :较差
<0:模型错误
Divergence:好坏人群的分数/违约概率距离

Gini:表示分数段中的坏样本浓度的差异

模型的准确度
AUC值
>0.7:有很强的区分度
0.6 to 0.7:一定的区分度
0.5 to 0.6:有较弱的区分度
低于0.5:区分度弱于随机猜测
模型稳定性
PSI:通常要求低于25%

评分卡分数的计算

二.行为评分卡模型的开发
根据贷款人放贷后的表现行为,预测未来违约概率的模型。行为评分卡预测的是条件概率P(未来违约/当前没有违约)
用在贷款发放之后,到期之前的时间段
适用的产品
还款周期长或者循环授信类
不适宜按月还息,本金一次还清的产品。因为最后一期风险比较高
观察期:搜集变量的时间窗口,通常3年以内
观察期不应过长,否则大量客户无法进入模型,不应过短,否则构建变量有效性不够
变量构造:
基于时间切片的衍生
如:观察期之前180天内,平均每个月的逾期次数
常用时间切片
(1,2)个月 (1,2)个季度 半年 1年 1年半 2年
**还款率类型特征:**本月还款率=本月总还款额/上月末总欠款额

额度使用率类型特征:额度使用率=本月使用额度/授信总额度

**逾期类型特征:**过去6个月最大逾期状态,过去6个月M1,M2,M3的次数
**消费类型特征:**提现类型特征
**表现期:**搜集是否出现坏样本的时间窗口,6个月-1年
行为评分卡模型的开发
特征构造
构造了时间窗口为1,3,6,12个月的观察期
每种观察期包括特征类型有预期类(最大逾期状态,M1/M2等的次数),额度使用类(最大月额度使用率,平均月额度使用率,月额度使用率增加的月份),还款类(最大月还款率,最小月还款率,平均月还款率)
特征挑选
IV VIF<10
基于GBDT的变量挑选
从GBDT中抽出4个最重要的变量,按照重要性逐渐添加新的变量,当新添加的变量符号为正舍弃,否则保留,直到添加最后一个变量为止。
对于上述挑出来的变量,重新进行逻辑回归,若还有不显著的变量,对每一个不显著的变量,单独建立逻辑回归模型,检验显著性。
带L1约束的逻辑回归模型
三.催收评分卡模型的开发(还款率模型)
逾期客户类型与风险等级

催收评分卡模型:还款率模型 账龄滚动模型 失联预测模型
失联预测模型:在逾期阶段,对于尚能联系到的人群预测其未来失联的概率
常用指标:
逾期天数 逾期金额占比 个人信息(性别,年龄,收入,工作)联系人信息(是否是夫妻 子女 同事 朋友) 运营商信息(在网时长 高频联系人)
账龄滚动模型:预测逾期人群从轻度逾期变成重度逾期的概率
常用指标:逾期天数 历史还款率信息 个人信息(性别 年龄 收入 工作),debt burden ratio
还款率预测模型:预测经过催收后,最终催收回的欠款的比率
模型常用指标:逾期天数 历史还款率信息 个人信息(性别 年龄 收入 工作),debt burden ratio 联系人信息(是否是夫妻 子女 同事 朋友)