Python网络爬虫自动收集51CTO技术文章
项目实现:使用Python网络爬虫收集51cto<大数据>频道所有文章题目以及相关链接,可通过程序中相关参数的修改,实现所有的文章收集
项目工具:Fiddler
51cto、csdn等都是禁止网络爬虫访问的,所以,首先得让Python爬虫伪装成浏览器,然后以模拟浏览器的形式对51cto等网站进行访问,此处会用到Fiddler工具。可直接从Fiddler的官网点击打开链接下载Fiddler,下载之后直接打开安装即可。网络上有很多Fiddler的相关配置,在此不做详细介绍。首先,打开51cto的首页,点击左上"频道"--大数据",在页面最下端,看到“加载更多”选项,此时打开Fiddler,点击“加载更多”,此时的Fiddler页面如图所示:
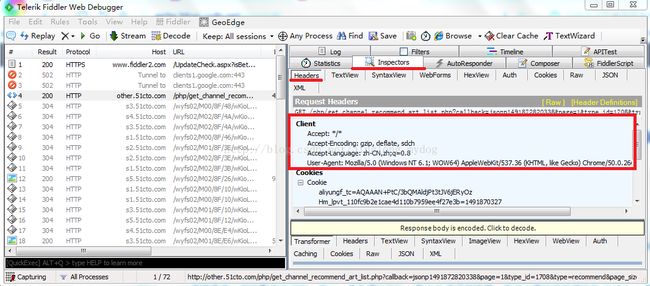
此时,Fiddler界面中的Client就是我们访问51cto网站所使用的真实浏览器的头信息。可以使用该信息让爬虫伪装成该浏览器。在Python程序设计中,我们可以通过如下格式设置头信息:
#模拟浏览器
headers = {"Accept": "*/*",
"Accept-Encoding": "utf-8, gb2312",
"Accept-Language": "zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0",
"Connection": "keep-alive",
"referer": "51cto.com"
}
cjar = http.cookiejar.CookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cjar))
headall = []
for key, value in headers.items():
item = (key, value)
headall.append(item)
opener.addheaders = headall
urllib.request.install_opener(opener)
#创建代理服务器
def use_proxy(proxy_addr, url):
try:
proxy = urllib.request.ProxyHandler({'http': proxy_addr})
opener = urllib.request.build_opener(proxy, urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
data = urllib.request.urlopen(url).read().decode('utf-8')
return data
#异常处理机制
except urllib.error.URLError as e:
if hasattr(e, 'code'):
print(e.code)
if hasattr(e, 'reason'):
print(e.reason)
time.sleep(10)
except Exception as e:
print("exception-->"+str(e))
time.sleep(1)通过Fiddler对网页行为进行分析,并实现文章的自动加载。在获取浏览器头信息的Fiddler的界面中,Fiddler捕捉到了如图的会话信息:
![]()
单击该会话信息,可以看到该会话信息的头部请求详情:

将该网址复制出来,再次点击“加载更多“,可以获得另外的网址,观察规律后发现
(1)type_id是51cto频道的文章类型id,type_size是每次加载的文章数
(2)page字段增加了1,callbac=kjsonp“......”增加了1
因此,我们可以将要爬取文章的URL地址构造为
url = "http://other.51cto.com/php/get_channel_recommend_art_list.php?" \
"callback=jsonp" + str(contentid) + "&page=" + str(page) + \
"&type_id=" + typeid + "&type=recommend&page_size=" + str(pagesize)
对该内容进行分析,我们可以得到以下字段;
"title":"BBC\uff1a\u5927\u6570\u636e\u5e26\u6765\u7684\u5f0a\u75c5\uff1f\u8fd1\u56e0\u6548\u5e94",
"picname":"http:\/\/s4.51cto.com\/wyfs02\/M02\/8F\/4A\/wKiom1jaCFejo_GmAACiPt3NL7056.jpeg-wh_173x112-wm_-s_3294757936.jpeg",
"url":"http:\/\/bigdata.51cto.com\/art\/201703\/535772.htm",
"stime":"2017-03-28
对title进行Unicode解码,并输出对应结果,如图所示

然后,分别打开url与picname的网址,我们就可以分别看到对应的文章以及相关的图片。因此,我们可以让爬虫对我们设置的URL网址进行爬取,通过正则表达式爬取到我们想要的信息。
相关程序如下
#获取所有文章链接
#实现自动加载
def getlisturl(pagestart, pageend, proxy, typeid, contentid, pagesize):
html1 = '''
51CTO大数据文章汇总
'''
fh = open("E:/Python/网络爬虫/9/2.html", "wb")
fh.write(html1.encode('utf-8'))
fh.close()
fh = open("E:/Python/网络爬虫/9/2.html", 'ab')
try:
page = pagestart
#修改page
for page in range(pagestart, pageend+1):
# 第二页出现Exception-->EOL while scanning string literal (, line 1)错误
if page == 2:
page += 1
contentid += 1
continue
# 构造真实网址
url = "http://other.51cto.com/php/get_channel_recommend_art_list.php?" \
"callback=jsonp" + str(contentid) + "&page=" + str(page) + \
"&type_id=" + typeid + "&type=recommend&page_size=" + str(pagesize)
print("contentid=", contentid)
print("page=", page)
print("url:", url)
print("------------------------")
print("第"+str(page)+"页文章")
data = use_proxy(proxy, url)
for i in range(0, pagesize):
titlepat = '"title":"(.*?)"'
urlpat = '"url":"(.*?)"'
stimepat = '"stime":"(.*?)"'
titlelist = re.compile(titlepat, re.S).findall(data)
urllist = re.compile(urlpat, re.S).findall(data)
stimelist = re.compile(stimepat, re.S).findall(data)
dataall = "文章题目:"+eval('u"'+titlelist[i]+'"')+"
" \
"文章链接:"+eval('u"'+urllist[i]+'"')+"
" \
"发表时间:"+eval('u"'+stimelist[i]+'"')+"
"
fh.write(dataall.encode("utf-8"))
contentid += 1
except urllib.error.URLError as e:
if hasattr(e, 'code'):
print(e.code)
if hasattr(e, 'reason'):
print(e.reason)
time.sleep(10)
except Exception as e:
print('Exception-->'+str(e))
time.sleep(1)
fh.close()
html2 = '''
'''
fh = open("E:/Python/网络爬虫/6/1.html", "ab")
fh.write(html2.encode('utf-8'))
fh.close() 程序中有一处设置需要注意:

在爬取到第二页的时候出现错误,网络上有很多该问题的解决方法,现在还没能完全解决,会在后续的学习中改进,因此当前可直接避免扫描该页。
爬取结果如下:
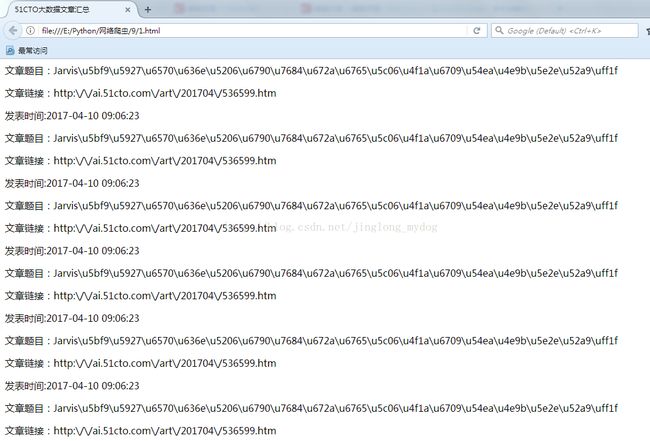
自此,该项目完整结束。也可通过修改type_id与callbac=kjsonp参数爬取其他类型的文章。
完整项目代目如下
#实现自动加载文章,并将其保存到本地.html文件
import urllib.request
import re
import http.cookiejar
import urllib.error
import time
#模拟浏览器
headers = {"Accept": "*/*",
"Accept-Encoding": "utf-8, gb2312",
"Accept-Language": "zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0",
"Connection": "keep-alive",
"referer": "51cto.com"
}
cjar = http.cookiejar.CookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cjar))
headall = []
for key, value in headers.items():
item = (key, value)
headall.append(item)
opener.addheaders = headall
urllib.request.install_opener(opener)
#创建代理服务器
def use_proxy(proxy_addr, url):
try:
proxy = urllib.request.ProxyHandler({'http': proxy_addr})
opener = urllib.request.build_opener(proxy, urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
data = urllib.request.urlopen(url).read().decode('utf-8')
return data
#异常处理机制
except urllib.error.URLError as e:
if hasattr(e, 'code'):
print(e.code)
if hasattr(e, 'reason'):
print(e.reason)
time.sleep(10)
except Exception as e:
print("exception-->"+str(e))
time.sleep(1)
#获取所有文章链接
#实现自动加载
def getlisturl(pagestart, pageend, proxy, typeid, contentid, pagesize):
html1 = '''
51CTO大数据文章汇总
'''
fh = open("E:/Python/网络爬虫/9/2.html", "wb")
fh.write(html1.encode('utf-8'))
fh.close()
fh = open("E:/Python/网络爬虫/9/2.html", 'ab')
try:
page = pagestart
#修改page
for page in range(pagestart, pageend+1):
# 第二页出现Exception-->EOL while scanning string literal (, line 1)错误
if page == 2:
page += 1
contentid += 1
continue
# 构造真实网址
url = "http://other.51cto.com/php/get_channel_recommend_art_list.php?" \
"callback=jsonp" + str(contentid) + "&page=" + str(page) + \
"&type_id=" + typeid + "&type=recommend&page_size=" + str(pagesize)
print("contentid=", contentid)
print("page=", page)
print("url:", url)
print("------------------------")
print("第"+str(page)+"页文章")
data = use_proxy(proxy, url)
for i in range(0, pagesize):
titlepat = '"title":"(.*?)"'
urlpat = '"url":"(.*?)"'
stimepat = '"stime":"(.*?)"'
titlelist = re.compile(titlepat, re.S).findall(data)
urllist = re.compile(urlpat, re.S).findall(data)
stimelist = re.compile(stimepat, re.S).findall(data)
dataall = "文章题目:"+eval('u"'+titlelist[i]+'"')+"
" \
"文章链接:"+eval('u"'+urllist[i]+'"')+"
" \
"发表时间:"+eval('u"'+stimelist[i]+'"')+"
"
fh.write(dataall.encode("utf-8"))
contentid += 1
except urllib.error.URLError as e:
if hasattr(e, 'code'):
print(e.code)
if hasattr(e, 'reason'):
print(e.reason)
time.sleep(10)
except Exception as e:
print('Exception-->'+str(e))
time.sleep(1)
fh.close()
html2 = '''
'''
fh = open("E:/Python/网络爬虫/6/1.html", "ab")
fh.write(html2.encode('utf-8'))
fh.close()
if __name__ == '__main__':
#设置文章类型编号
typeid = "1708"
# 起始文章起始编号
contentid = 1491807788211
pagestart = 0
pageend = 10
pagesize = 19
proxy = "124.88.67.39:80"
getlisturl(pagestart, pageend, proxy, typeid, contentid, pagesize)