Redisson基础资料汇总
一.前言
分布式系统有一个著名的理论CAP,指在一个分布式系统中,最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三项中的两项,CAP原则是常用的一个原则。
C一致性:
在分布式环境当中,对于多个数据源,多个数据库对数据的访问能不能满足隔离性,一致性,原子性等要求,是分布式系统的重点和难点
A可用性:
在多机部署的基础上,通过负载均衡或服务注册等技术保证服务对用户可用
P分区容错性:
对服务进行拆分,进行多机部署
BASE理论
Basically Available (基本可用),
Soft state(软状态)
Eventually consistent(最终一致性)相当于CAP原则中的一致性和可用性的权衡结果
在微服务系统中,一个请求存在多级跨服务调用,往往需要牺牲强一致性来保证系统高可用,比如通过分布式事务,异步消息等手段完成。但还是有的场景,需要阻塞所有节点的所有线程,对共享资源的访问。比如并发时“超卖”情况。如下图,假如某个时刻,redis里面的某个商品库存为1,此时两个请求同时到来,其中一个请求执行到下图的第3步,更新数据库的库存为0,但是第4步还没有执行,而另外一个请求执行到了第2步,发现库存还是1,就继续执行第3步。这样的结果,是导致卖出了2个商品,然而其实库存只有1个。
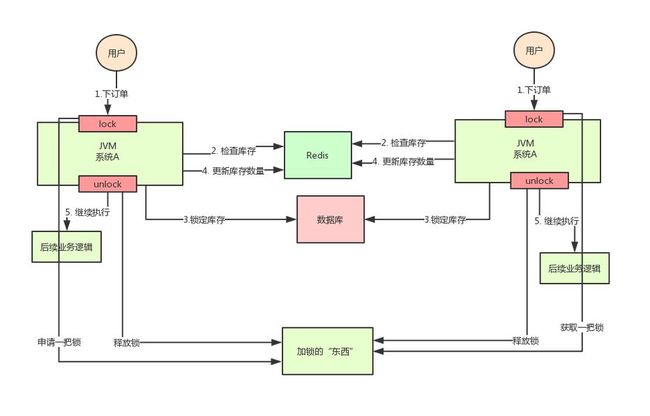
两个A系统,运行在两个不同的JVM里面,他们加的锁只对属于自己JVM里面的线程有效,对于其他JVM的线程是无效的。Java提供的synchronized或者ReentrantLock等原生锁机制在多机部署场景下失效了,因为两台机器加的锁不是同一个锁,要保证两台机器加的锁是同一个锁,就需要分布式锁,在整个系统提供一个全局、唯一的获取锁的“东西”,然后每个系统在需要加锁时,都去问这个“东西”拿到一把锁,这样不同的系统拿到的就可以认为是同一把锁。
要实现分布式锁就需要依赖中间件,数据库、redis、zookeeper等
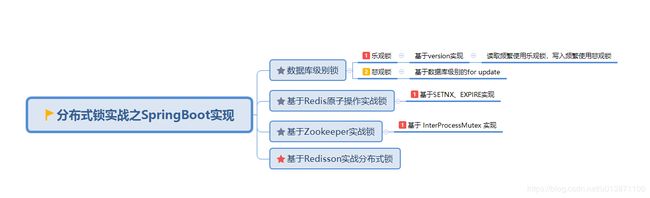
不管使用什么中间件,有如下几点特性是实现分布式锁需要考虑到的.
互斥:在同一时刻,必须保证锁至多只能被一个客户端持有。
死锁: 如果一个线程获得锁,然后挂了,并没有释放锁,致使其他节点(线程)永远无法获取锁,这就是死锁。分布式锁必须做到避免死锁。
性能: 高并发分布式系统中,线程互斥等待会成为性能瓶颈,需要好的中间件和实现来保证性能。
锁特性:考虑到复杂的场景,分布式锁不能只是加锁,然后一直等待。最好实现如Java Lock的一些功能如:锁判断,超时设置,可重入性等。确保客户端只能解锁自己持有的锁。
Zookeeper与Redisson技术选型
结合项目架构,引入Redisson,Redisson相关资料非常详细,这里只是做个索引式的总结记录,建立架构体系.
二.简介
Redisson是一个在Redis的基础上实现的Java驻内存数据网格(In-Memory Data Grid),它不仅提供了一系列的分布式的Java常用对象,还提供了许多分布式服务。其中包括
(BitSet, Set, Multimap, SortedSet, Map, List, Queue, BlockingQueue, Deque, BlockingDeque, Semaphore, Lock, AtomicLong, CountDownLatch, Publish / Subscribe, Bloom filter, Remote service, Spring cache, Executor service, Live Object service, Scheduler service)
Redisson提供了使用Redis的最简单和最便捷的方法。Redisson的宗旨是促进使用者对Redis的关注分离(Separation of Concern),从而让使用者能够将精力更集中地放在处理业务逻辑上。
Redisson在基于NIO的Netty框架上,充分的利用了Redis键值数据库提供的一系列优势,在Java实用工具包中常用接口的基础上,为使用者提供了一系列具有分布式特性的常用工具类。使得原本作为协调单机多线程并发程序的工具包获得了协调分布式多机多线程并发系统的能力,大大降低了设计和研发大规模分布式系统的难度。同时结合各富特色的分布式服务,更进一步简化了分布式环境中程序相互之间的协作。
详情查看Wiki:Wiki
Redission官方网站
GitHub地址

三.功能
1.扩展Java应用程序(Scaling Java applications )
基于Redis的对象、集合、锁、同步器和Java上分布式应用所需的服务。
2.缓存(Caching)
基于Redis的Java缓存实现,如jcacheapi、Hibernate二级缓存、Spring缓存和应用程序级缓存。
3.数据库缓存(Data source caching)
基于Redis的Java缓存,用于数据库、web服务或任何其他数据源,使用Read-Through、Write-Through和Write-Behind策略。
4.分布式Java任务调度与执行(Distributed Java tasks scheduling and execution)
Java上的任务处理可以与基于Redis的ExecutorService和ScheduledExecutorService的分布式实现并行运行。
5.分布式数据处理(Distributed data processing)
基于Java的MapReduce编程模型,处理Redis中存储的大量数据。
6.简易 Redis Java客户端(Easy Redis Java client)
Redisson是最高级、最简单的RedisJava客户端。它的学习曲线为零,因此您不需要知道任何Redis命令就可以开始使用它。
7.Session集群(Web session clustering Web)
使用基于Redis的Tomcat会话管理器和Spring会话实现的用户会话负载平衡。
8.微服务(Microservices)
基于Redis的可重用Java微服务通信使用RPC、消息传递和缓存。
9.消息传递(Messaging)
基于Java消息发布/代理的发布/消息传递。
四.特色

1.Redis配置支持(Supported Redis configurations)
Redis集群模式(Cluster)
Redis哨兵模式(Sentinel)
Redis主/从模式(Master / Slave)
Redis单节点模式(Single)
拓展:单节点模式不用说了,集群,哨兵,主从模式的区别参阅:Redis集群详解,Redis Cluster原理 (跑题了,但是我觉得早晚会拐回来看的,先上截图)
2.分布式锁和同步器 (Distributed Java locks and synchronizers)
锁(Lock):即中文版提的可重入锁(Reentrant Lock)
公平锁(FairLock)
联锁(MultiLock)
红锁(RedLock)
读写锁(ReadWriteLock)
信号量(Semaphore)
可过期性信号量(PermitExpirableSemaphore)
闭锁(CountDownLatch)
3.分布式集合 (Distributed Java collections)
映射(Map)
多值映射(Multimap)
集(Set)
列表(List)
有序集(SortedSet)
计分排序集(ScoredSortedSet)
字典排序集(LexSortedSet)
队列/双端队列(Queue/Deque)
阻塞队列/阻塞双端队列(Blocking Queue/Deque)
优先队列/优先双端队列(Priority Queue/Deque)
延迟队列(Delayed Queue)
流(Stream)
Transfer Queue
Ring Buffer
4.与Java框架的集成 (Integration with Java frameworks)
Spring Framework
Spring Cache
Spring Session
Spring Data Redis
Spring Boot Starter
Hibernate 2nd Level Cache
JCache API (JSR-107) implementation
Tomcat Session Manager
5.分布式对象 (Distributed Java objects)
通用对象holder(Object holder)
二进制流holder(Binary stream holder)
地理空间对象holder(Geospatial holder)
BitSet
原子整长型(AtomicLong)
原子双精度浮点(AtomicDouble)
订阅分发(PublishSubscribe)
布隆过滤器(Bloom filter)
基数估计算法(HyperLogLog)
限流器(RateLimiter)
6.分布式服务 (Distributed Java services)
分布式远程服务(Remote service )
分布式实时对象服务(Live Object service)
分布式执行服务(Executor service)
分布式调度任务服务(Scheduler service)
分布式映射归纳服务(MapReduce service)
事务(Transactions)
7.自动序列化与反序列化 (Supported codecs)
FST,JBoss Marshalling,Jackson JSON,Avro,Smile,CBOR,MsgPack,Amazon Ion,Kryo,LZ4,Snappy,JDK Serialization
8.Redis服务管理 (Managed Redis services support)
支持云托管服务模式
亚马逊云:AWS ElastiCache,AWS ElastiCache Cluster
微软云:Azure Redis Cache
谷歌云:Google Cloud Memorystore
9.引擎 (Engine)
自动连接管理(Automatic connection management)
同步接口(Synchronous interface)
异步接口(Asynchronous interface)
反应界面(Reactive interface)
支持Android平台(Supports Android platform)
支持OSGI(Supports OSGI)
支持SSL连接(Supports SSL connection)
五.简单案例
Redis 没有对 Java 提供原生支持,想要在程序中集成 Redis,需要使用 Redis 的第三方库,Redisson 在 java.util 中常用接口的基础上,提供了一系列具有分布式特性的工具类,下面是一个简单的案例,Redisson的更多功能还需要在实际项目中不断的去挖掘,发现,领会,运用,码云:https://gitee.com/liuyandeng/redisson-demo
docker安装redis
1.获取 redis 镜像
docker pull redis
2.创建本机redis配置文件挂载目录
mkdir -p /usr/local/redis/conf
3.从官网http://download.redis.io/redis-stable/redis.conf获取redis.conf
4.修改默认配置文件,并上传到挂载目录下
bind 127.0.0.1 #注释掉这部分,这是限制redis只能本地访问
protected-mode no #默认yes,开启保护模式,限制为本地访问
5.执行命令
docker run --name redis --restart=always -p 6379:6379 -v /usr/local/redis/conf:/etc/redis -v /usr/local/redis/data:/data -d redis redis-server /etc/redis/redis.conf --requirepass "123456" --appendonly yes
命令解释说明:
--name redis //指定该容器别名
--restart=always //随docker启动
-p 6379:6379 //端口映射:前表示主机部分,:后表示容器部分。
-v //挂载目录,规则与端口映射相同。
-d redis //后台模式启动redis,后面还有参数,不能放在前面
redis-server /etc/redis/redis.conf //以配置文件启动redis,加载容器内的conf文件,最终找到的是挂载的目录/usr/local/redis/conf/redis.conf
--requirepass "123456" //设置密码为123456
--appendonly yes //开启redis的AOF持久化,默认为false,不持久化redis集群搭建参考:
基于Docker搭建redis集群
加入依赖
org.redisson
redisson
3.13.2
客户端连接配置
@Bean("singleClient")
public RedissonClient singleClient() {
Config config = new Config();
config.useSingleServer()
.setTimeout(1000000)
.setAddress("redis://ip:6379")
.setPassword("123456");
//默认连接上 127.0.0.1:6379
RedissonClient redisson = Redisson.create(config);
return redisson;
}使用 RList 操作 Redis 列表
RList 是 Java 的 List 集合的分布式并发实现。
public RList rlist(RedissonClient singleClient) {
// RList 继承了 java.util.List 接口
RList rlist = singleClient.getList("rlist");
rlist.clear();
rlist.add("test001");
rlist.add("test002");
rlist.add("http://cgfytop.cn");
rlist.remove(-1);
boolean contains = rlist.contains("test001");
System.out.println("List size: " + rlist.size());
System.out.println("Is list contains 'test001': " + contains);
rlist.forEach(System.out::println);
// singleClient.shutdown();
return rlist;
} 使用 RMap 操作 Redis 哈希
Redisson 还包括 RMap,它是 Java Map 集合的分布式并发实现
public RMap rmap(RedissonClient singleClient) {
// RMap 继承了 java.util.concurrent.ConcurrentMap 接口
RMap rmap = singleClient.getMap("rmap");
rmap.put("name", "晨港飞燕");
rmap.put("city", "天津");
rmap.put("link", "http://www.cgfytop.cn");
boolean contains = rmap.containsKey("link");
System.out.println("Map size: " + rmap.size());
System.out.println("Is map contains key 'link': " + contains);
String value = rmap.get("name");
System.out.println("Value mapped by key 'name': " + value);
boolean added = rmap.putIfAbsent("link", "https://www.baidu.com") == null;
System.out.println("Is value mapped by key 'link' added: " + added);
return rmap;
}
使用 RLock 实现 Redis 分布式锁
RLock 是 Java 中可重入锁的分布式实现,redission实现了JDK中的Lock接口,所以使用方式一样,只是Redssion的锁是分布式的。如下:
config.useClusterServers()
.addNodeAddress("redis://192.168.31.101:7001")
.addNodeAddress("redis://192.168.31.101:7002")
.addNodeAddress("redis://192.168.31.101:7003")
.addNodeAddress("redis://192.168.31.102:7001")
.addNodeAddress("redis://192.168.31.102:7002")
.addNodeAddress("redis://192.168.31.102:7003");
RedissonClient redisson = Redisson.create(config);
RLock lock = redisson.getLock("anyLock");
lock.lock();
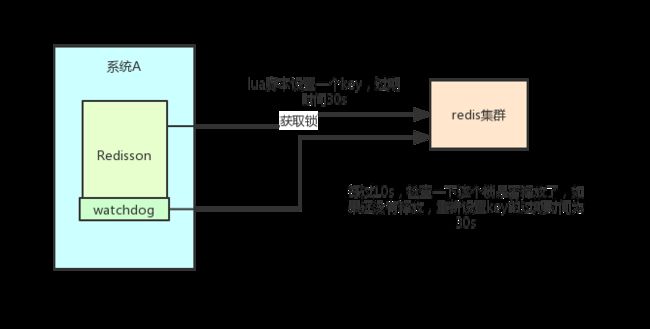
lock.unlock();我们只需要通过它的api中的lock和unlock即可完成分布式锁,他帮我们考虑了很多细节:
redisson所有指令都通过lua脚本执行,redis支持lua脚本原子性执行
redisson设置一个key的默认过期时间为30s,如果某个客户端持有一个锁超过了30s怎么办?
redisson中有一个watchdog的概念,翻译过来就是看门狗,它会在你获取锁之后,每隔10秒帮你把key的超时时间设为30s
这样的话,就算一直持有锁也不会出现key过期了,其他线程获取到锁的问题了。
redisson的“看门狗”逻辑保证了没有死锁发生。
(如果机器宕机了,看门狗也就没了。此时就不会延长key的过期时间,到了30s之后就会自动过期了,其他线程可以获取到锁)
六.其他
1.Redission与RedisTemplate的关系
自行了解,说是两者结合对redis操作更完善,我觉得redisson的分布式锁是亮点.
Jedis与Redisson选型对比
spring-boot-starter-fast-redis
Springboot集成Jedis + Redisson(已自测)
springbootCache整合redisTemplate/redisson
2.Redis三种集群模式的简介
Redis有三种集群模式,分别是:
* 主从模式
* Sentinel模式
* Cluster模式
主从模式介绍
| 主从模式是三种模式中最简单的,在主从复制中,数据库分为两类:主数据库(master)和从数据库(slave)。 主从复制有如下特点: * 主数据库可以进行读写操作,当读写操作导致数据变化时会自动将数据同步给从数据库 * 从数据库一般都是只读的,并且接收主数据库同步过来的数据 * 一个master可以拥有多个slave,但是一个slave只能对应一个master * slave挂了不影响其他slave的读和master的读和写,重新启动后会将数据从master同步过来 * master挂了以后,不影响slave的读,但redis不再提供写服务,master重启后redis将重新对外提供写服务 * master挂了以后,不会在slave节点中重新选一个master 工作机制: 当slave启动后,主动向master发送SYNC命令。master接收到SYNC命令后在后台保存快照(RDB持久化)和缓存保存快照这段时间的命令,然后将保存的快照文件和缓存的命令发送给slave。slave接收到快照文件和命令后加载快照文件和缓存的执行命令。 复制初始化后,master每次接收到的写命令都会同步发送给slave,保证主从数据一致性。
安全设置: 当master节点设置密码后, 客户端访问master需要密码 启动slave需要密码,在配置文件中配置即可 客户端访问slave不需要密码 从上面可以看出,master节点在主从模式中唯一,若master挂掉,则redis无法对外提供写服务。 |
Sentinel模式介绍
| 主从模式的弊端就是不具备高可用性,当master挂掉以后,Redis将不能再对外提供写入操作,因此sentinel应运而生。 sentinel中文含义为哨兵,顾名思义,它的作用就是监控redis集群的运行状况, 特点如下:
* sentinel模式是建立在主从模式的基础上,如果只有一个Redis节点,sentinel就没有任何意义 * 当master挂了以后,sentinel会在slave中选择一个做为master,并修改它们的配置文件,其他slave的配置文件也会被修改,比如slaveof属性会指向新的master * 当master重新启动后,它将不再是master而是做为slave接收新的master的同步数据 * sentinel因为也是一个进程有挂掉的可能,所以sentinel也会启动多个形成一个sentinel集群 * 多sentinel配置的时候,sentinel之间也会自动监控 * 当主从模式配置密码时,sentinel也会同步将配置信息修改到配置文件中,不需要担心 * 一个sentinel或sentinel集群可以管理多个主从Redis,多个sentinel也可以监控同一个redis * sentinel最好不要和Redis部署在同一台机器,不然Redis的服务器挂了以后,sentinel也挂了 工作机制: * 每个sentinel以每秒钟一次的频率向它所知的master,slave以及其他sentinel实例发送一个 PING 命令 * 如果一个实例距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值, 则这个实例会被sentinel标记为主观下线。 * 如果一个master被标记为主观下线,则正在监视这个master的所有sentinel要以每秒一次的频率确认master的确进入了主观下线状态 * 当有足够数量的sentinel(大于等于配置文件指定的值)在指定的时间范围内确认master的确进入了主观下线状态, 则master会被标记为客观下线 * 在一般情况下, 每个sentinel会以每 10 秒一次的频率向它已知的所有master,slave发送 INFO 命令 * 当master被sentinel标记为客观下线时,sentinel向下线的master的所有slave发送 INFO 命令的频率会从 10 秒一次改为 1 秒一次 * 若没有足够数量的sentinel同意master已经下线,master的客观下线状态就会被移除; 若master重新向sentinel的 PING 命令返回有效回复,master的主观下线状态就会被移除
当使用sentinel模式的时候,客户端就不要直接连接Redis,而是连接sentinel的ip和port,由sentinel来提供具体的可提供服务的Redis实现,这样当master节点挂掉以后,sentinel就会感知并将新的master节点提供给使用者。 |
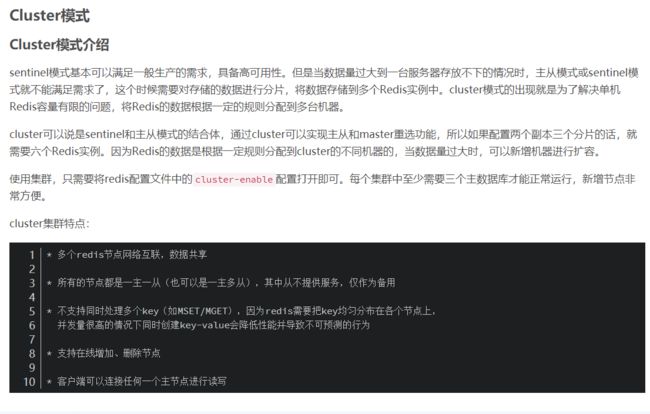
Cluster模式介绍
| sentinel模式基本可以满足一般生产的需求,具备高可用性。但是当数据量过大到一台服务器存放不下的情况时,主从模式或sentinel模式就不能满足需求了,这个时候需要对存储的数据进行分片,将数据存储到多个Redis实例中。cluster模式的出现就是为了解决单机Redis容量有限的问题,将Redis的数据根据一定的规则分配到多台机器。
cluster可以说是sentinel和主从模式的结合体,通过cluster可以实现主从和master重选功能,所以如果配置两个副本三个分片的话,就需要六个Redis实例。因为Redis的数据是根据一定规则分配到cluster的不同机器的,当数据量过大时,可以新增机器进行扩容。
使用集群,只需要将redis配置文件中的cluster-enable配置打开即可。每个集群中至少需要三个主数据库才能正常运行,新增节点非常方便。
cluster集群特点: * 多个redis节点网络互联,数据共享 * 所有的节点都是一主一从(也可以是一主多从),其中从不提供服务,仅作为备用 * 不支持同时处理多个key(如MSET/MGET),因为redis需要把key均匀分布在各个节点上, 并发量很高的情况下同时创建key-value会降低性能并导致不可预测的行为 * 支持在线增加、删除节点 * 客户端可以连接任何一个主节点进行读写 |
3.redis-cli命令
Redis 命令用于在 redis 服务上执行操作,要在 redis 服务上执行命令需要一个 redis 客户端,Redis 客户端在我们之前下载的的 redis 的安装包中.
linux安装redis-cli:
wget http://download.redis.io/redis-stable.tar.gz
tar -xzvf redis-stable.tar.gz
cd redis-stable
make
cp src/redis-cli /usr/local/bin/
Redis 客户端的基本语法为:$ redis-cli
在远程服务上执行命令:$ redis-cli -h host -p port -a password4.CountDownLantch:
这个是在多线程的时候使用的,比如说我启动很多个线程,去执行某个任务,然后把任务进行切分,都完成之后有一个等待,等待所有线程都达到这里之后,在一起往下走,把异步再变成同步
参考连接:
https://redisson.org
https://www.cnblogs.com/cjsblog/p/11273205.html
https://blog.csdn.net/loushuiyifan/article/details/82497455
https://baijiahao.baidu.com/s?id=1649462207261213608&wfr=spider&for=pc
附件
官方中文文档
Rui Gu edited this page on 24 Mar 2018 · 30 revisions
- 1. 概述
- 2. 配置方法
- 2.1. 程序化配置
- 2.2. 文件方式配置
- 2.2.1 通过JSON或YAML格式配置
- 2.2.2 通过Spring XML命名空间配置
- 2.3. 常用设置
- 2.4. 集群模式
- 2.4.1. 集群设置
- 2.4.2. 通过JSON、YAML和Spring XML文件配置集群模式
- 2.5. 云托管模式
- 2.5.1. 云托管模式设置
- 2.5.2. 通过JSON、YAML和Spring XML文件配置云托管模式
- 2.6. 单Redis节点模式
- 2.6.1. 单节点设置
- 2.6.2. 通过JSON、YAML和Spring XML文件配置单节点模式
- 2.7. 哨兵模式
- 2.7.1. 哨兵模式设置
- 2.7.2. 通过JSON、YAML和Spring XML文件配置哨兵模式
- 2.8. 主从模式
- 2.8.1. 主从模式设置
- 2.8.2. 通过JSON、YAML和Spring XML文件配置主从模式
- 3. 程序接口调用方式
- 3.1. 异步执行方式
- 3.2. 异步流执行方式
- 4. 数据序列化
- 5. 单个集合数据分片(Sharding)
- 6. 分布式对象
- 6.1. 通用对象桶(Object Bucket)
- 6.2. 二进制流(Binary Stream)
- 6.3. 地理空间对象桶(Geospatial Bucket)
- 6.4. BitSet
- 6.4.1. 数据分片(Sharding)(分布式RoaringBitMap)
- 6.5. 原子整长形(AtomicLong)
- 6.6. 原子双精度浮点(AtomicDouble)
- 6.7. 话题(订阅分发)
- 6.7.1. 模糊话题
- 6.8. 布隆过滤器(Bloom Filter)
- 6.8.1. 数据分片(Sharding)
- 6.9. 基数估计算法(HyperLogLog)
- 6.10. 整长型累加器(LongAdder)
- 6.11. 双精度浮点累加器(DoubleAdder)
- 6.12. 限流器(RateLimiter)
- 7. 分布式集合
- 7.1. 映射(Map)
- 7.1.1. 映射(Map)的元素淘汰(Eviction),本地缓存(LocalCache)和数据分片(Sharding)
- 7.1.2. 映射持久化方式(缓存策略)
- 7.1.3. 映射监听器(Map Listener)
- 7.1.4. LRU有界映射
- 7.2. 多值映射(Multimap)
- 7.2.1. 基于集(Set)的多值映射(Multimap)
- 7.2.2. 基于列表(List)的多值映射(Multimap)
- 7.2.3. 多值映射(Multimap)淘汰机制(Eviction)
- 7.3. 集(Set)
- 7.3.1. 集(Set)淘汰机制(Eviction)
- 7.3.2. 集(Set)数据分片(Sharding)
- 7.4. 有序集(SortedSet)
- 7.5. 计分排序集(ScoredSortedSet)
- 7.6. 字典排序集(LexSortedSet)
- 7.7. 列表(List)
- 7.8. 队列(Queue)
- 7.9. 双端队列(Deque)
- 7.10. 阻塞队列(Blocking Queue)
- 7.11. 有界阻塞队列(Bounded Blocking Queue)
- 7.12. 阻塞双端队列(Blocking Deque)
- 7.13. 阻塞公平队列(Blocking Fair Queue)
- 7.14. 阻塞公平双端队列(Blocking Fair Deque)
- 7.15. 延迟队列(Delayed Queue)
- 7.16. 优先队列(Priority Queue)
- 7.17. 优先双端队列(Priority Deque)
- 7.18. 优先阻塞队列(Priority Blocking Queue)
- 7.19. 优先阻塞双端队列(Priority Blocking Deque)
- 7.1. 映射(Map)
- 8. 分布式锁(Lock)和同步器(Synchronizer)
- 8.1. 可重入锁(Reentrant Lock)
- 8.2. 公平锁(Fair Lock)
- 8.3. 联锁(MultiLock)
- 8.4. 红锁(RedLock)
- 8.5. 读写锁(ReadWriteLock)
- 8.6. 信号量(Semaphore)
- 8.7. 可过期性信号量(PermitExpirableSemaphore)
- 8.8. 闭锁(CountDownLatch)
- 9. 分布式服务
- 9.1. 分布式远程服务(Remote Service)
- 9.1.1. 分布式远程服务工作流程
- 9.1.2. 发送即不管(Fire-and-Forget)模式和应答回执(Ack-Response)模式
- 9.1.3. 异步调用
- 9.1.4. 取消异步调用
- 9.2. 分布式实时对象(Live Object)服务
- 9.2.1. 介绍
- 9.2.2. 使用方法
- 9.2.3. 高级使用方法
- 9.2.4. 注解(Annotation)使用方法
- 9.2.5. 使用限制
- 9.3. 分布式执行服务(Executor Service)
- 9.3.1. 分布式执行服务概述
- 9.3.2. 任务
- 9.3.3. 取消任务
- 9.4. 分布式调度任务服务(Scheduler Service)
- 9.4.1. 分布式调度任务服务概述
- 9.4.2. 设定任务计划
- 9.4.3. 通过CRON表达式设定任务计划
- 9.4.4. 取消计划任务
- 9.5. 分布式映射归纳服务(MapReduce)
- 9.5.1. 介绍
- 9.5.2. 映射(Map)类型的使用范例
- 9.5.3. 集合(Collection)类型的使用范例
- 9.1. 分布式远程服务(Remote Service)
- 10. 额外功能
- 10.1. 对Redis节点的操作
- 10.2. 复杂多维对象结构和对象引用的支持
- 10.3. 命令的批量执行
- 10.4. 脚本执行
- 10.5. 底层Redis客户端
- 11. Redis命令和Redisson对象匹配列表
- 12. 独立节点模式
- 12.1. 概述
- 12.2. 配置方法
- 12.2.1. 配置参数
- 12.2.2. 通过JSON和YAML配置文件配置独立节点
- 12.3. 初始化监听器
- 12.4. 嵌入式运行方法
- 12.5. 命令行运行方法
- 12.6. Docker方式运行方法
- 13. 工具
- 13.1. 集群管理工具
- 13.1.1. 创建集群
- 13.1.2. 踢出节点
- 13.1.3. 数据槽迁移
- 13.1.4. 添加从节点
- 13.1.5. 添加主节点
- 13.1. 集群管理工具
- 14. 第三方框架整合
- 14.1. Spring框架整合
- 14.2. Spring Cache整合
- 14.2.1. 本地缓存
- 14.2.2. 数据分片
- 14.2.3. JSON和YAML配置
- 14.3. Hibernate整合
- 14.3.1. 本地缓存
- 14.3.2. 数据分片
- 14.4. Java缓存标准规范JCache API (JSR-107)
- 14.5. Tomcat会话管理器(Tomcat Session Manager)
- 14.6. Spring Session会话管理器
- 14.7. JMX与Dropwizard Metrics
- 15. 项目依赖列表
官方英文文档
Nikita Koksharov edited this page on 12 May · 96 revisions
- 1. Overview
- 2. Configuration
- 2.1. Programmatically configuration
- 2.2. Declarative configuration
- 2.2.1. YAML file based configuration
- 2.2.1. Spring XML namespace configuration
- 2.3. Common settings
- 2.4. Cluster mode
- 2.4.1. Settings
- 2.4.2. YAML and Spring XML config format
- 2.5. Replicated mode
- 2.5.1. Settings
- 2.5.2. YAML and Spring XML config format
- 2.6. Single instance mode
- 2.6.1. Settings
- 2.6.2. YAML and Spring XML config format
- 2.7. Sentinel mode
- 2.7.1. Settings
- 2.7.2. YAML and Spring XML config format
- 2.8. Master slave mode
- 2.8.1. Settings
- 2.8.2. YAML and Spring XML config format
- 2.9. Proxy mode
- 2.9.1. Settings
- 2.9.2. YAML config format
- 3. Operations execution
- 3.1. Async way
- 3.2. Reactive way
- 4. Data serialization
- 5. Data partitioning (sharding)
- 5.1. Common operations over objects
- 6. Distributed objects
- 6.1. Object holder
- 6.2. Binary stream holder
- 6.3. Geospatial holder
- 6.4. BitSet
- 6.4.1. Data partitioning
- 6.5. AtomicLong
- 6.6. AtomicDouble
- 6.7. Topic
- 6.7.1. Pattern
- 6.8. Bloom filter
- 6.8.1. Data partitioning
- 6.9. HyperLogLog
- 6.10. LongAdder
- 6.11. DoubleAdder
- 6.12. RateLimiter
- 7. Distributed collections
- 7.1. Map
- 7.1.1. Eviction, local cache and data partitioning
- 7.1.2. Persistence
- 7.1.3. Listeners
- 7.1.4. LRU bounded
- 7.2. Multimap
- 7.2.1. Set based Multimap
- 7.2.2. List based Multimap
- 7.2.3. Eviction
- 7.3. Set
- 7.3.1. Eviction and data partitioning
- 7.4. SortedSet
- 7.5. ScoredSortedSet
- 7.6. LexSortedSet
- 7.7. List
- 7.8. Queue
- 7.9. Deque
- 7.10. Blocking Queue
- 7.11. Bounded Blocking Queue
- 7.12. Blocking Deque
- 7.13. Blocking Fair Queue
- 7.14. Blocking Fair Deque
- 7.15. Delayed Queue
- 7.16. Priority Queue
- 7.17. Priority Deque
- 7.18. Priority Blocking Queue
- 7.19. Priority Blocking Deque
- 7.20. Stream
- 7.21. Ring Buffer
- 7.22. Transfer Queue
- 7.23. Time Series
- 7.1. Map
- 8. Distributed locks and synchronizers
- 8.1. Lock
- 8.2. Fair Lock
- 8.3. MultiLock
- 8.4. RedLock
- 8.5. ReadWriteLock
- 8.6. Semaphore
- 8.7. PermitExpirableSemaphore
- 8.8. CountDownLatch
- 9. Distributed services
- 9.1. Remote service
- 9.1.1. Message flow
- 9.1.2. Fire-and-forget and ack-response modes
- 9.1.3. Asynchronous, Reactive and RxJava2 calls
- 9.1.4. Asynchronous, Reactive and RxJava2 call cancellation
- 9.2. Live Object service
- 9.2.1. Introduction
- 9.2.2. Usage
- 9.2.3. Search by Object properties
- 9.2.4. Advanced Usage
- 9.2.5. Annotations
- 9.2.6. Restrictions
- 9.3. Executor service
- 9.3.1. Overview
- 9.3.2. Workers
- 9.3.3. Tasks
- 9.3.4. Tasks with Spring beans
- 9.3.5. Task execution cancellation
- 9.4. Scheduler service
- 9.4.1. Overview
- 9.4.2. Workers
- 9.4.3. Scheduling a task
- 9.4.4. Scheduling a task with Spring beans
- 9.4.5. Scheduling a task with cron expression
- 9.4.6. Tasks scheduling cancellation
- 9.5. MapReduce service
- 9.5.1. Overview
- 9.5.2. Map example
- 9.5.3. Collection example
- 9.1. Remote service
- 10. Additional features
- 10.1. Operations with Redis nodes
- 10.2. References to Redisson objects
- 10.3. Execution batches of commands
- 10.4. Transactions
- 10.5. Scripting
- 10.6. Low level Redis client
- 11. Redis commands mapping
- 12. Standalone node
- 12.1. Overview
- 12.2. Configuration
- 12.2.1. Settings
- 12.2.2. YAML config format
- 12.3. Initialization listener
- 12.4. How to run as embedded node
- 12.5. How to run from command-line
- 12.6. How to run using Docker
- 13. Tools
- 13.1. Cluster management tool
- 13.1.1. Create Redis cluster
- 13.1.2. Remove Redis node
- 13.1.3. Move slots between Redis nodes
- 13.1.4. Add slave Redis node
- 13.1.5. Add master Redis node
- 13.1. Cluster management tool
- 14. Integration with frameworks
- 14.1. Spring Framework
- 14.2. Spring Cache
- 14.2.1. Local cache and data partitioning
- 14.2.2. YAML config format
- 14.3. Hibernate Cache
- 14.3.1. Local cache and data partitioning
- 14.4. JCache API (JSR-107) implementation
- 14.4.1. Asynchronous, Reactive and RxJava2 interfaces
- 14.4.2. Local cache
- 14.5. MyBatis Cache
- 14.5.1. Local cache and data partitioning
- 14.6. Tomcat Session Manager
- 14.7. Spring Session
- 14.8. Spring Transaction Manager
- 14.9. Spring Data Redis
- 14.10. Spring Boot Starter
- 14.11. Statistics monitoring (JMX and other systems)
- 15. Dependency list
推荐文章
- Java data structures powered by Redis.
Introduction to Redisson (pdf) - Reaching 500K Ops/Sec With Only 3 Redis Nodes
- Redisson PRO vs. Jedis: Which Is Faster?
- Redis Users Rejoice! The JCache API Is Here
- A Look at the Java Distributed In-Memory Data Model
(Powered by Redis) - Creating Distributed Java Applications With Redis
- Redis Java client with code example
- Redis Java client for Azure Cache
- Redis Java client for AWS Elasticache
- Lettuce Replacement:
Why Redisson is the Best Lettuce Alternative - Apache Ignite Replacement:
Why Redisson is the Best Alternative - Hazelcast Replacement:
Why Redisson is the Best Hazelcast Alternative - The Top 5 Redis-Based Java Objects
- A Redis-based Ring Buffer for Java
- How to install Redis
- Glossary of Terms
- Distributed tasks Execution and Scheduling in Java,
powered by Redis - Introducing Redisson Live Objects (Object Hash Mapping)
- Java Remote Method Invocation with Redisson
- Java Multimaps With Redis
- Distributed lock with Redis
- A Guide to Redis with Redisson
- Advanced Adventure for JSR-107 Caching
- Feature Comparison: Redisson vs Jedis
- Feature Comparison: Redisson vs Lettuce
- Feature Comparison: Redis vs Apache Ignite
- Feature Comparison: Redis vs Hazelcast
- Feature Comparison: Redis vs Ehcache
- Jedis Alternative:
Why Redisson is the Best Jedis Replacement - Ehcache Alternative:
Why Redisson is the Best Ehcache Replacement - A Redis-based Java Time Series Collection
- Redis Streams for Java