python爬取链家北京二手房信息(BeautifulSoup)
一、准备
使用的包有:urllib.request、bs4、pandas、numpy、re、time
urllib.request:用来打开和浏览url中内容
bs4:爬取网页
pandas:生成数据表,并保存为csv文件
numpy:循环的时候用了一下,个人感觉好像可以不用,但是没试过
re:使用正则表达式提取需要的内容
time:为了防止访问网站过于频繁报错,使用time.sleep()暂停一段时间
首先引入包
from urllib.request import urlopen
from bs4 import BeautifulSoup
import pandas as pd
import numpy as np
import re
import time二、抓取数据
本博客抓取的信息有:
Direction(房屋朝向)、District(所在商业区)、Floor(楼层)、Garden(房屋所在小区)、Layout(户型)、Price(总价)、Renocation(房屋装修)、Size(面积)、Year(年份)、Id(房屋编号)
ps:本程序抓取的数据,Id由于是科学计数法在csv文件中显示,因此不可以使用(只有Id有问题),需要的朋友可以修改代码解决这个问题,结果会在最后贴出

房屋编号并不在页面中显示,而是在代码里

1、了解一下目标网站的URL结构,例如 https://bj.lianjia.com/ershoufang/dongcheng/pg2/
- bj表示城市,北京
- ershoufang是频道名称,二手房
- dongcheng是城区名称,东城区
- pg2是页面码,第二页

我们要抓取北京的二手房信息,所以前半部分(http://bj.lianjia.com/ershoufang/)是不会变的,而需要遍历城区和页数。使用两层循环,外层遍历城区,内层遍历页数。
chengqu = {'dongcheng': '东城区', 'xicheng': '西城区', 'chaoyang': '朝阳区', 'haidian': '海淀区', 'fengtai': '丰台区',
'shijingshan': '石景山区','tongzhou': '通州区', 'changping': '昌平区', 'daxing': '大兴区', 'shunyi': '顺义区',
'fangshan': '房山区'}
for cq in chengqu.keys():
url = 'https://bj.lianjia.com/ershoufang/' + cq + '/' # 组成所选城区的URL
...
for j in np.arange(1, int(total_page) + 1):
page_url = url + 'pg' + str(j) # 组成所选城区页面的URL
....2、其中,需要获取所选城区包含的总页数,提取div标签中class=page-box house-lst-page-box的第三个子标签属性page-data的值。
![]()
total_page = re.sub('\D', '', bsObj.find('div', 'page-box house-lst-page-box').contents[0].attrs['page-data'])[:-1] # 获取所选城区总页数3、对需要信息进行提取,此时,你需要一点点的在页面代码中去找你需要的部分,并且观察提取出来的内容的格式,转换成我们需要存储的格式
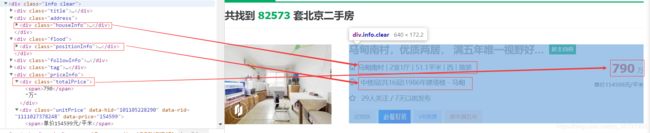
把class为houseInfo、positionInfo、totalPrice的div和class为noresultRecommend img LOGCLICKDATA的a标签提取出来,使用get_text()获取内容,然后使用split分割成list
page_html = urlopen(page_url)
page_bsObj = BeautifulSoup(page_html)
info = page_bsObj.findAll("div", {"class": "houseInfo"})
position_info = page_bsObj.findAll("div", {"class": "positionInfo"})
totalprice = page_bsObj.findAll("div", {"class": "totalPrice"})
idinfo = page_bsObj.findAll("a", {"class": "noresultRecommend img LOGCLICKDATA"})
for i_info, i_pinfo, i_tp, i_up, i_id in zip(info, position_info, totalprice, unitprice, idinfo):
i_info=i_info.get_text().split('|') #['马甸南村','2室1厅','51.1平米','西','简装']
i_pinfo=i_pinfo.get_text().split('-')#['中楼层(共16层)1986年建塔楼','马甸']
i_pinfo[0] = re.findall(r"\d+\.?\d*", i_pinfo[0])#[['16','1986'],'马甸']
i_info[2] = re.findall(r"\d+\.?\d*",i_info[2].replace(' ',''))#['马甸南村','2室1厅',51.1,'西','简装']统计导入list中,再生成数据表,保存为csv文件
house_direction = [] # 房屋朝向Direction
house_districe = [] # 房屋所在商业区Districe
house_floor = [] # 房屋楼层Floor
house_garden = [] # 房屋所在小区Garden
house_id = [] # 房屋编号Id
house_layout = [] # 房屋户型Layout
t_price = [] # 房屋总价Price
house_renovation = [] # 房屋装修Renovation
house_size = [] # 房屋面积Size
house_year = [] # 建造年份Year
if len(i_info) == 5 and len(i_pinfo) == 2 and len(i_pinfo[0])==2 and ('data-housecode'in i_id.attrs):#到了后面有的没有楼层或年份,或中没有data-housecode属性
# 从houseinfo中获取房屋所在小区、户型、面积、朝向、装修、有无电梯各字段
house_garden.append(i_info[0].replace(' ',''))
house_layout.append(i_info[1].replace(' ',''))
house_size.append(i_info[2])
house_direction.append(i_info[3].replace(' ', ''))
house_renovation.append(i_info[4].replace(' ',''))
# 从positioninfo中获房屋楼层、建造年份、位置各字段
house_floor.append(i_pinfo[0][0])
house_year.append(i_pinfo[0][1])
house_districe.append(i_pinfo[1])
# 获取房屋总价和单价
t_price.append(i_tp.span.string)
#获取房屋id
house_id.append(str(i_id.attrs['data-housecode']))
# 将数据导入pandas之中生成数据表
file2=open('lianjia.csv','a+',newline='')
house_data = pd.DataFrame()
house_data['Id'] = house_id
house_data['Region'] = [chengqu[cq]] * len(house_garden)
house_data['Gargen'] = house_garden
house_data['District'] = house_districe
house_data['Layout'] = house_layout
house_data['Size'] = house_size
house_data['Direction'] = house_direction
house_data['Renocation'] = house_renovation
house_data['Floor'] = house_floor
house_data['Year'] = house_year
house_data['Price'] = t_price
# 将数据存入到csv中,便于后续分析
house_data.to_csv(file2, header=False,encoding='gb2312',index=None)
file2.close()
time.sleep(60)三、最后加上全部代码~
from urllib.request import urlopen
from bs4 import BeautifulSoup
import pandas as pd
import numpy as np
import re
import time
chengqu = {'dongcheng': '东城区', 'xicheng': '西城区', 'chaoyang': '朝阳区', 'haidian': '海淀区', 'fengtai': '丰台区',
'shijingshan': '石景山区','tongzhou': '通州区', 'changping': '昌平区', 'daxing': '大兴区', 'shunyi': '顺义区',
'fangshan': '房山区'}
for cq in chengqu.keys():
url = 'https://bj.lianjia.com/ershoufang/' + cq + '/' # 组成所选城区的URL
html = urlopen(url)
bsObj = BeautifulSoup(html)
total_page = re.sub('\D', '', bsObj.find('div', 'page-box fr').contents[0].attrs['page-data'])[:-1] # 获取所选城区总页数
#print('total_page', total_page)
house_direction = [] # 房屋朝向Direction
house_districe = [] # 房屋所在商业区Districe
# house_elevator = [] # 有无电梯Elevator
house_floor = [] # 房屋楼层Floor
house_garden = [] # 房屋所在小区Garden
house_id = [] # 房屋编号Id
house_layout = [] # 房屋户型Layout
t_price = [] # 房屋总价Price
house_renovation = [] # 房屋装修Renovation
house_size = [] # 房屋面积Size
house_year = [] # 建造年份Year
for j in np.arange(1, int(total_page) + 1):
print("at the ",cq," page ",j,"/",total_page)
page_url = url + 'pg' + str(j) # 组成所选城区页面的URL
# print (page_url)
page_html = urlopen(page_url)
page_bsObj = BeautifulSoup(page_html)
info = page_bsObj.findAll("div", {"class": "houseInfo"})
position_info = page_bsObj.findAll("div", {"class": "positionInfo"})
totalprice = page_bsObj.findAll("div", {"class": "totalPrice"})
unitprice = page_bsObj.findAll("div", {"class": "unitPrice"})
idinfo = page_bsObj.findAll("a", {"class": "noresultRecommend img LOGCLICKDATA"})
for i_info, i_pinfo, i_tp, i_up, i_id in zip(info, position_info, totalprice, unitprice, idinfo):
i_info=i_info.get_text().split('|')
i_pinfo=i_pinfo.get_text().split('-')
i_pinfo[0] = re.findall(r"\d+\.?\d*", i_pinfo[0])
i_info[2] = re.findall(r"\d+\.?\d*",i_info[2].replace(' ',''))
if len(i_info) == 5 and len(i_pinfo) == 2 and len(i_pinfo[0])==2 and ('data-housecode'in i_id.attrs):
# 分列houseinfo并依次获取房屋所在小区、户型、面积、朝向、装修、有无电梯各字段
house_garden.append(i_info[0].replace(' ',''))
house_layout.append(i_info[1].replace(' ',''))
house_size.append(i_info[2])
house_direction.append(i_info[3].replace(' ', ''))
house_renovation.append(i_info[4].replace(' ',''))
#house_elevator.append(i_info[5])
# 分列positioninfo并依次获房屋楼层、建造年份、位置各字段
house_floor.append(i_pinfo[0][0])
house_year.append(i_pinfo[0][1])
house_districe.append(i_pinfo[1])
# 获取房屋总价和单价
t_price.append(i_tp.span.string)
#获取房屋id
house_id.append(str(i_id.attrs['data-housecode']))
# 将数据导入pandas之中生成数据表
file2=open('lianjia.csv','a+',newline='')
house_data = pd.DataFrame()
house_data['Id'] = house_id
house_data['Region'] = [chengqu[cq]] * len(house_garden)
house_data['Gargen'] = house_garden
house_data['District'] = house_districe
house_data['Layout'] = house_layout
house_data['Size'] = house_size
house_data['Direction'] = house_direction
house_data['Renocation'] = house_renovation
# house_data[u'有无电梯'] = house_elevator
house_data['Floor'] = house_floor
house_data['Year'] = house_year
house_data['Price'] = t_price
# print (house_data)
# 将数据存入到csv中,便于后续分析
house_data.to_csv(file2, header=False,encoding='gb2312',index=None)
#house_data.to_csv(file, header=True, encoding='gb2312', index=True)
file2.close()
time.sleep(60)
四、运行结果
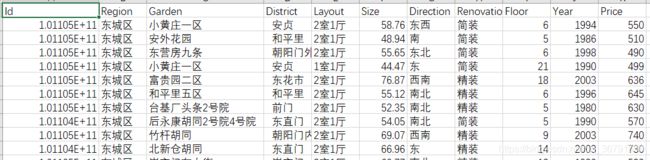 由于是使用office显示的,可以改变数据格式,改变后id变为:
由于是使用office显示的,可以改变数据格式,改变后id变为:
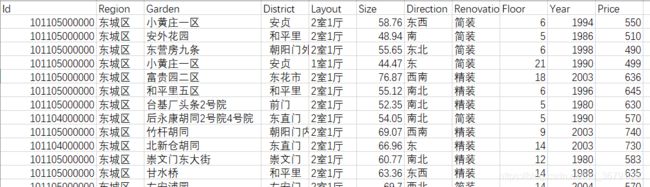
id变成这样也没法用,还好之后的操作中用不到id,如果有需要用id数据的,可以试一下先创建csv文件,把第一列数据格式改掉,也许就行了,或者还有更高级的方法,但是我也没有试。。。
五、参考博客:https://blog.csdn.net/ziyin_2013/article/details/85211814
就酱啦~