python--数据挖掘开头(KNN使用,OneR介绍)
一、亲和性分析实例
我们拿这个实例来看看数据挖掘是什么!
数据挖掘有一个常用的场景,即顾客在买一件商品时,商家可以趁机了解他们还想买什么,然后把顾客们愿意同时买的商品放在一起以提升营业额。当商家得到的数据足够多的时候就可以对其进行亲和性分析,以确定哪些商品适合放在一起。
1.什么是亲和性?
亲和性分析是来确定样本之间的相似度。
亲和性运用场景:
1.投放广告
2.推荐商品或电影
3.寻找有亲缘关系的人
亲和性有多种测量方法:
1.统计两个商品一起出售的频率
2.统计顾客买了1后再买2的比率
2.规则的衡量
‘如果顾客买了A,那么该顾客可能愿意买B’这个就是一个规则
我们引入两个定义来衡量规则
支持度:规则应验的次数
置信度:规则应验次数/’如果’时间出现次数
二、分类
1.什么是分类?
分类是数据挖掘领域最为常用的方法之一
2.分类实例
Iris植物分类:
数据集一共有150条植物数据,每条有四个特征:sepal length、sepal width、petal length、petal width
数据集有三种类别:Iris Setosa、Iris Versicolour、Iris Virginica
数据导入与处理:
from sklearn.datasets import load_iris
import numpy as np
dataset=load_iris()
x=dataset.data
y=dataset.target
print(x)
att=x.mean(axis=0)#求均值
x_d=np.array(x>att,dtype='int')#0、1化
print(x_d)
处理结果:
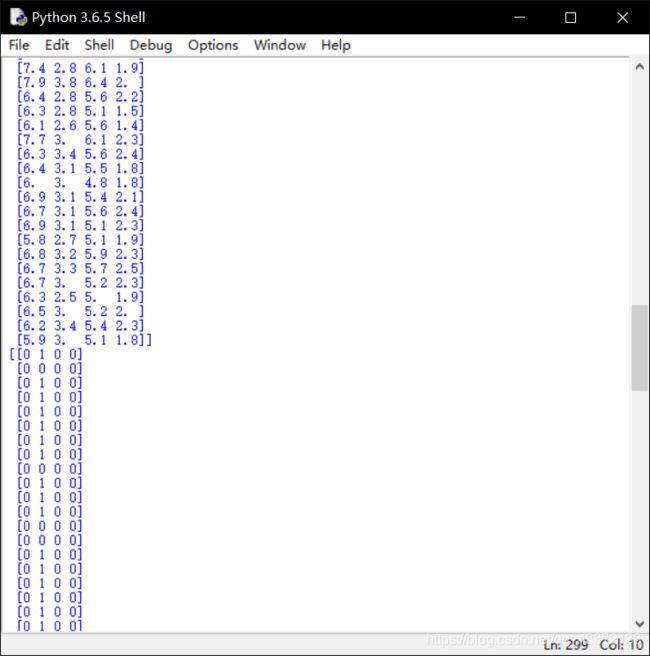
3.OneR算法
OneR算法是找出一个最能影响种类的特征进行分类
OneR算法流程:
1.找出每一个特征在其值为0时最多的种类,1时最多的种类
2.算出每一个特征在0,1时的错误率相加作为这一个特征的错误率
3.选取错误率最小的特征作为rule
4.对测试数据进行预测
4.算法代码
from sklearn.datasets import load_iris
from collections import defaultdict
from operator import itemgetter
from sklearn.cross_validation import train_test_split
import numpy as np
dataset=load_iris()
x=dataset.data
y=dataset.target
att=x.mean(axis=0)
x_d=np.array(x>att,dtype='int')
x_train,x_test,y_train,y_test=train_test_split(x_d,y,random_state=14)
def train_feature_value(x_d,y,feature_index,value):
class_counts=defaultdict(int)
for sample,i in zip(x_d,y):
if sample[feature_index]==value:
class_counts[i]+=1
sorted_class_counts=sorted(class_counts.items(),key=itemgetter(1),reverse=True)#排序
most_frequent_class=sorted_class_counts[0][0]
incorrect_predictions=[class_count for class_value,class_count in class_counts.items() if class_value!=most_frequent_class]#统计错误的个数
error=sum(incorrect_predictions)
return most_frequent_class,error
def train_on_feature(x,y,f_i):
values=set(x[:,f_i])
predictors={}
errors=[]
for i in values:
most_class,error=train_feature_value(x,y,f_i,i)
predictors[i]=most_class
errors.append(error)
total_error=sum(errors)
return predictors,total_error
all_predictors={}
errors={}
for f_i in range(x_train.shape[1]):
predictors,total_error=train_on_feature(x_train,y_train,f_i)
all_predictors[f_i]=predictors
errors[f_i]=total_error
best_v,best_e=sorted(errors.items(),key=itemgetter(1))[0]
model={'va':best_v,'pr':all_predictors[best_v]}
def predict(x_test,model):
variable=model['va']
predictor=model['pr']
y_predicted=np.array([predictor[int(sample[variable])]for sample in x_test])
return y_predicted
y_predicted=predict(x_test,model)
a=np.mean(y_predicted==y_test)
print(a)
运行结果:

三、估计器分类
为了实现大量的分类算法,scikit-learn把相关的功能封装成了所谓的估计器。
估计器主要包括两个函数:
1.fit()训练算法
2.predict()预测
其接收的数据类型为numpy数组或类似格式
scikit-learn提供了大量的估计器,例如SVM、随机森林、神经网络等
1.knn
从http://archive.ics.uci.edu/ml/datasets/Ionosphere下载电离层数据
将数据进行简单的处理
然后用sklearn中封装好了的包
一次检验无法避免偶然性
于是我们采用交叉验证
交叉验证就是多做几次‘一次检验’然后求均值,但是测试集中的数据只能出现一次
由于knn需要选取临近的个数
所以这时候我们就需要调参
import numpy as np
from sklearn.cross_validation import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.cross_validation import cross_val_score
import matplotlib.pyplot as plt
import csv
x=np.zeros((351,34),dtype='float')
y=np.zeros((351,),dtype='bool')
filename='C:/Users/F.S.Z/Desktop/数据挖掘学习ing/电离层-data.csv'
#导入数据
with open(filename,'r') as f:
reader=csv.reader(f)
for i,row in enumerate(reader):
data=[float(datum) for datum in row[:-1]]
x[i]=data
y[i]=row[-1]=='g'
'''
#分离训练集和数据集
x_train,x_test,y_train,y_test=train_test_split(x,y,random_state=14)
#knn掉包运用
a=KNeighborsClassifier()
a.fit(x_train,y_train)
y_predict=a.predict(x_test)
'''
#交叉测试
e=list(range(1,21))
d=[]
for i in e:
a=KNeighborsClassifier(n_neighbors=i)
scores=cross_val_score(a,x,y,scoring='accuracy')
b=np.mean(scores)*100
d.append(round(b,2))
plt.plot(e,d,'-o')
for i,j in zip(e,d):
plt.text(i,j,j,ha='center',va='bottom',fontsize=11)
plt.show()
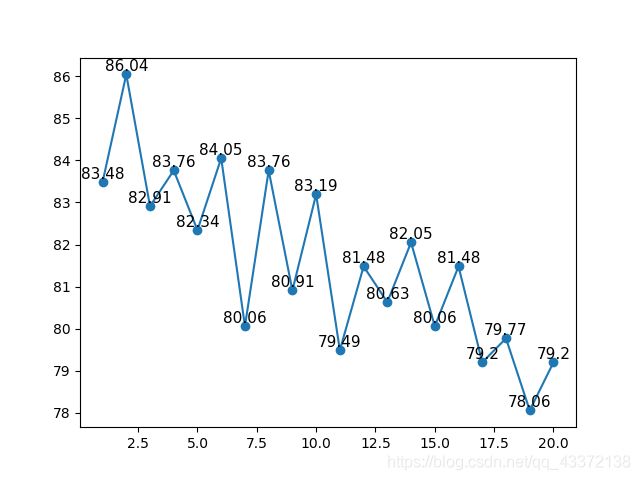
可见随着临近个数的增加,正确率在减少
2.数据规范化
由于数据之间存在着差异,例如体重,有的动物是几吨,有的是几克
这些数据的差异会导致模型准确率的下降
于是我们需要将数据规范化
#将数据变成0,1之间的数
from sklearn.preprocessing import MinMaxScaler
x=MinMaxScaler().fit_transform(数据)
#每条数据各特征值和为1
from sklearn.preprocessing import Normalizer
#各特征的均值为0,方差为1
from sklearn.preprocessing import StandardScaler
#将数值型特征二值化
from sklearn.preprocessing import Binarizer
3.流水线
为了减少复杂度,引入流水线
简单看一下代码即可
from sklearn.pipeline import Pipeline
a=Pipeline([('scale',MinMaxScaler()),('predict',KNeighborsClassifier())])
scores=cross_val_score(a,x,y,scoring='accuracy')