python爬虫:爬取全国航班信息
目标网站
携程:https://flights.ctrip.com/domestic/schedule/
思路分析
- 获取到所有的地方航班
打开网址,可以看到如下内容:

这一步目的是获取到这里显示的所有的航班。 - 得到一个地方航班的所有线路
随便打开一个航班,可以看到这个地方航班所有的线路,如下图:
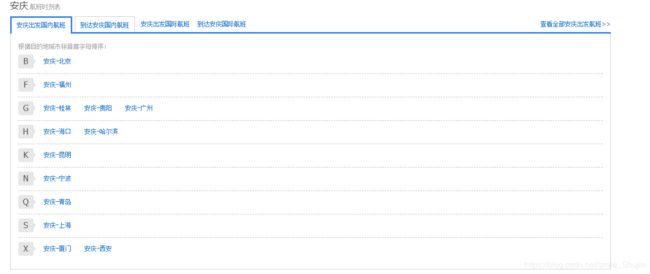
这一步目的是获取到这里显示的所有的线路。 - 得到一条线路的所有航班信息
打开一条线路,可以看到这条线路上所有运行的航班:

这一步的目的是获取到这条线路所有的航班信息 - 通过循环获取到所有的信息
以上三步能得到一个地方航班的 一条线路的 航班信息,接下来要做的是,通过循环获取到所有地方航班的航班信息。
代码分析及实现
这里我使用的是BeautifulSoup库。
所需模块:
import requests
from bs4 import BeautifulSoup
- 获取到所有的地方航班
通过开发者工具可以看到每个li标签里都存放着对应首字母开头的地方航班,每个a标签的内容是地方航班的名称以及链接:
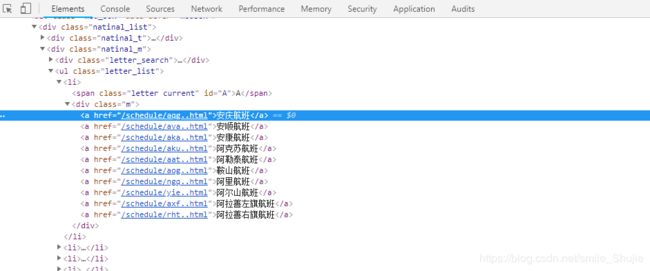
我们需要得到所有的li标签,再得到每个li标签里的a标签,把航班名称和对应的链接存在一个字典中,下面是代码实现:
# 得到所有地方航班及链接
def getAllFlights():
flights = {} # {'安庆航班': 'https://flights.ctrip.com/schedule/aqg..html', ...}
url = 'https://flights.ctrip.com/schedule'
headers = {
'user-agent':random.choice(UserAgents),
'accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'accept-encoding':'gzip, deflate, br',
'accept-language':'zh-CN,zh;q=0.9',
'upgrade-insecure-requests':'1'
}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'lxml')
letter_list = soup.find( attrs={'class':'letter_list'} ).find_all('li')
for li in letter_list:
for a in li.find_all('a'):
flights[a.get_text()] = url + a['href'][9:]
return flights
这里的请求头user-agent是我从一个集合中随机获取的,也可以随便写一个。
返回的flights为一个字典,键为航班名称,值为链接。
- 得到一个地方航班的所有线路
这一步的数据获取与上一步相似,直接贴出代码:
# 得到一个地方航班的所有线路
def getFlightLines(url):
flightlines = {} # {'安庆-北京': 'http://flights.ctrip.com/schedule/aqg.bjs.html', ...}
headers = {
'Referer': 'https://flights.ctrip.com/schedule/',
'user-agent':random.choice(UserAgents)
}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'lxml')
letter_list = soup.find(attrs={'id': 'ulD_Domestic'}).find_all('li')
for li in letter_list:
for a in li.find_all('a'):
flightlines[a.get_text()] = a['href']
return flightlines
这个方法需要传入一个变量url,这个变量就是航班的链接,如:https://flights.ctrip.com/schedule/aqg..html
最后返回的flightlines是一个字典,键为线路名称,值为链接。
- 得到一条线路的所有航班信息
点击一条线路( 如:安庆-广州 )进入到航班信息页面,按F12打开开发者工具:
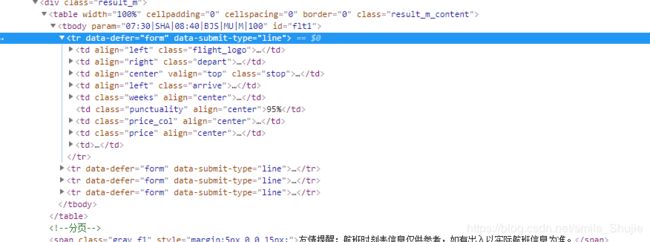 可以看到所有的航班都存放在tbody标签中,每个tr标签对应着一个航班的信息,我们只要通过分析每个tr标签,把我们想要的信息获取出来即可,代码:
可以看到所有的航班都存放在tbody标签中,每个tr标签对应着一个航班的信息,我们只要通过分析每个tr标签,把我们想要的信息获取出来即可,代码:
# 得到这条线路的所有航班信息
def getFlightInfo(url):
flightInfos = []
headers = {
'Host': 'flights.ctrip.com',
'user-agent': random.choice(UserAgents)
}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'lxml')
flights_tr = soup.find(attrs={'id':'flt1'}).find_all('tr')
for tr in flights_tr: # 遍历每个一航班
flightInfo = {}
info_td = tr.find_all('td')
# 航班编号
flight_no = info_td[0].find('strong').get_text().strip()
flightInfo['flight_no'] = flight_no
# 起飞时间
flight_stime = info_td[1].find('strong').get_text().strip()
flightInfo['flight_stime'] = flight_stime
# 起飞机场
flight_sairport = info_td[1].find('div').get_text().strip()
flightInfo['flight_sairport'] = flight_sairport
# 降落时间
flight_etime = info_td[3].find('strong').get_text().strip()
flightInfo['flight_etime'] = flight_etime
# 降落机场
flight_eairport = info_td[3].find('div').get_text().strip()
flightInfo['flight_eairport'] = flight_eairport
# 班期
flight_schedule = []
for s in info_td[4].find(attrs={'class':'week'}).find_all(name='span', attrs={'class':'blue'}):
flight_schedule.append(s.get_text().strip())
flight_schedule = ' '.join( flight_schedule )
flightInfo['flight_schedule'] = flight_schedule
# 准点率
flight_punrate = info_td[5].get_text().strip()
flightInfo['flight_punrate'] = flight_punrate
# 价格
flight_price = info_td[6].get_text().strip()
flightInfo['flight_price'] = flight_price
flightInfos.append(flightInfo)
return flightInfos
实现起来并不复杂,关键的地方我都已写好了注释。
我们只需要传入一条线路的url给这个方法,即可获得该条线路所有的航班信息,这个方法返回的是一个集合,集合中存放字典,字典中存放着航班编号、起飞时间等信息。
到此所需要的方法都已经封装好了,最后梳理一下流程:
1、调用getAllFlights()方法,得到所有的地方航班;
2、循环取出每一个地方航班,把每一个地方航班的链接传到getFlightLines()方法中,得到该地方航班的所有线路;
3、循环取出每一条线路,把每一条线路的链接传到getFlightInfo()方法中,得到该条线路的所有的航班信息;
4、循环取出每一个航班信息,进行数据库存储等操作。
流程实现参考代码(仅参考)
这里只是根据我的需求来进行的代码编写和数据库的存储,有需要的朋友可以参考以下代码的逻辑处理来满足自己的需求。

好啦,到此所有的流程均已结束。
以上代码并不是最优的,可以根据实际使用进优化。
注意:以上内容仅供学习交流使用,请勿用于违法目的。