数据相似度处理功能实现思路与方法
最近接到一个需求,需求直接来源于业务的一句话,“找出这堆商品信息里面相似的商品,根据名称判断”。
需求看似简单,实则思考起来用技术实现是需要花点心思的。对于这样的需求,首先要有一个思路和思考的过程:
1、业务具体想要的是什么? -- 名称相似度超过一定比例的两个商品可以算成一个或者一组商品,用来后续组合处理
2、什么样的数据才算是相似的? -- 两个名称相似度超过70%,算是描述的同一种商品
3、怎么实现相似度的计算的方法? -- 通过余弦值算法可以计算字符串相似程度
4、什么样的数据结构提供给业务,是可以让他们一眼看出来哪些数据是相似的? -- 通过SQL分组,并使用DENSE_RANK方法,将同组的数据进行数字编号。
5、算法能否进行优化用来增加业务需求命中率和计算性能(除了余弦值计算,分词、单字切割、名词加权计算、计算复杂度O(n)或O(n2)等等)?
对于当前需求,分为以上5步骤去进行考虑,区分哪些是权重价值比较高的行为,需要重点思考:
1、4代表着理解业务需求的程度,影响着这次结果能否让需求提出方干系人的满意
2、3、5代表着需求所需要思考的技术实现,影响着交付结果的质量
根据干系人需要的紧急程度和质量价值分析,我们可以将第5步骤作为可选项。
1、2、4与业务相关,此处不做详细描述,针对于第3步骤,实现方法如下:
余弦值算法:
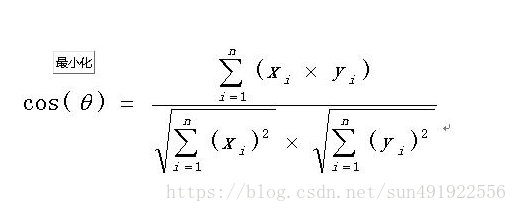
余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,夹角等于0,即两个向量相等,这就叫"余弦相似性"。
举例:
名称A:新西兰红玫瑰Queen苹果12个140g以上/个
名称B:新西兰红玫瑰Queen苹果6个150g以上/个
第一步,语句拆分
名称A:新 西 兰 红 玫 瑰 Q u e e n 苹 果 1 2 个 1 4 0 g 以 上 / 个
名称B:新 西 兰 红 玫 瑰 Q u e e n 苹 果 6 个 1 5 0 g 以 上 / 个
第二步,列出所有单字组合(去重)
总语句:新 西 兰 红 玫 瑰 Q u e n 苹 果 1 2 个 4 0 g 以 上 / 6 5
第三步,计算字频
名称A:新[1]西[1]兰[1]红[1]玫[1]瑰[1]Q[1]u[1]e[2]n[1]苹[1]果[1]1[2]2[1]个[2]4[1]0[1]g[1]以[1]上[1]/[1]6[0]5[0]
名称B:新[1]西[1]兰[1]红[1]玫[1]瑰[1]Q[1]u[1]e[2]n[1]苹[1]果[1]1[1]2[0]个[2]4[0]0[1]g[1]以[1]上[1]/[1]6[1]5[1]
第四步,写出字频向量。
名称A:(1,1,1,1,1,1,1,1,2,1,1,1,2,1,2,1,1,1,1,1,1,0,0)
名称B:(1,1,1,1,1,1,1,1,2,1,1,1,1,0,2,0,1,1,1,1,1,1,1)
第五步,套用公式
值= (A1*B1+A2*B2+A3*B3+A1*B1+.......)/ 根号(A各项平方之和) * 根号(B各项平方之和)
值=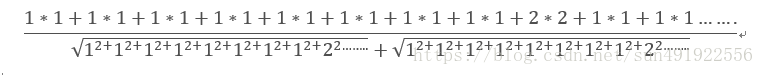
值= 26 / 根号(30) * 根号(27)
值= 26 / 28.4604
=0.9135
值越大越相似,=1则代表完全相同。=0则代表完全不同
代码如下:
///
/// 计算字符串名称(余弦值算法)
///
///
///
/// sourceNameL = sourceName.ToCharArray().Select(o => o.ToString()).ToList();
List targNameL = targName.ToCharArray().Select(o => o.ToString()).ToList();
////结巴组件智能分词
//List sourceNameL = segmenter.Cut(sourceName).Select(o => o.ToString()).ToList();
//List targNameL = segmenter.Cut(targName).Select(o => o.ToString()).ToList();
List allL = new List();
sourceNameL.ForEach(o =>
{
if (!allL.Contains(o))
{
allL.Add(o);
}
});
targNameL.ForEach(o =>
{
if (!allL.Contains(o))
{
allL.Add(o);
}
});
#endregion
#region 名称包含直接返回
//如果出现名称包含则认为是相等
if (sourceName.IndexOf(targName) > 0)
{
return true;
}
if (targName.IndexOf(sourceName) > 0)
{
return true;
}
#endregion
#region 第三步,计算词频。
var sourceint = new List();
var targint = new List();
//遍历原名称集合,按照单字符判断是否存在于目标字符串中 ,例如: 可口可乐金装300ml → 可 口 可 乐 金 装 3 0 0 m l
allL.ForEach(o =>
{
sourceint.Add(sourceNameL.Count(sl => sl == o));
targint.Add(targNameL.Count(sl => sl == o));
});
#endregion
#region 第四部,余弦值公式计算
//分子
int fenzi = 0;
for (int i = 0; i < allL.Count(); i++)
{
fenzi += sourceint[i] * targint[i];
}
//分母
int sourcemax = 0;
sourceint.ForEach(o =>
{
sourcemax += (o * o);
});
int tagmax = 0;
targint.ForEach(o =>
{
tagmax += (o * o);
});
var fenmu = Math.Sqrt(sourcemax) * Math.Sqrt(tagmax);
#endregion
#region 结果比对
double res = fenzi / fenmu;
#endregion
//判断占比
if (res > ThresholdValue)
{
return true;
}
return false;
} 此处设定的阈值为0.7,超过70%相似,则默认为相似数据。
针对于第5步优化建议:
1、分词的工具,上述代码使用的是 单字分割,分词工具有结巴分词、盘古分词、Lucene分词等
2、考虑如果去掉无用的词组,例如:语气词、连接词等
3、对名词或关键词组设定加权规则,例如:美国(3)/红蛇果(3)4个(1)180g(1)以上(1)/(0)个(1)
4、对于遍历一组数据查找一般情况下需要嵌套两层遍历,Foreach(){ Foreach(){ } },复杂度为O(n2),在计算时可以考虑第一层遍历时,判断为相似数据则进行打标关联操作,后续遍历则进行跳过打标数据,复杂度则小于O(n2),计算过程则约到后端速度越快。
针对于优化相似度算法 或者 提升计算性能的方法还有很多,需求的实现任务范围则需要根据业务的需要价值分析进行裁剪或扩充。