C/C++部分笔试题分析
- C/C++笔试题分析
- 1. 看似考察fork()函数的题目
- 问题
- 答案
- 解析
- 2. 通过函数交换两个变量的值
- 问题
- 分析
- 3. 括号匹配
- 问题
- 解&解析
- 4. C++的多态
- 问题
- 解答
- 代码解析
- 1. 输出部分
- 2. 内存泄漏部分
- 总结
- 5. C++中的const成员函数
- 用途
- 声明方式
- 注意
- 小结
- 1. 看似考察fork()函数的题目
C/C++笔试题分析
以下是在参加各公司笔试时遇到的部分问题的一些总结。
1. 看似考察fork()函数的题目
问题
写出以下代码的运行结果
#include 答案
xxx@xxx:~$ g++ t2.cpp -o t2.o
xxx@xxx:~$ ./t2.o
glob = 7,var = 89
glob = 7,var = 89解析
本题的难点主要出在pid变量上,很容易因为fork()函数的返回值误导(主线程返回0,子线程返回其PID),认为两个线程中的pid变量不同,导致对结果的误判。
本题目的考察点是运算符的结合顺序。
代码中的if(pid = fork() < 0)一行,包含了两个运算:赋值运算和判断大小。
C中,大小判断运算符(>、<、>=、<=、==)的优先级高于赋值运算(=)
因此这段代码的实际运算顺序为:
if(pid = (fork() < 0))
if(pid = 0) //假设此处fork()未出错
if(0) //此时两个进程的变量pid == 0
之后,因为两个进程变量pid均为0,都会执行这段代码
else if (pid == 0) {
glob++;
var++;
}因此得出上述结果。
2. 通过函数交换两个变量的值
问题
以下哪个函数和函数调用能实现交换iA和iB的值?
(此处是选项中一个==错误==的答案)
#include 分析
这是一个错误解法。swap函数是对的(可自行测试),错误出在调用方法上。
此处定义指针时(21、22行)==没有==定义指针的指向(指向NULL),就直接给这两个指针指向的内存地址赋值(23、24行)运行会导致Segment Fault。
修改方法如下:
//调用开始
int *piA = &iA;
int *piB = &iB;
swap(piA,piB);
//调用结束即定义指针时将指针指向iA和iB的内存地址。
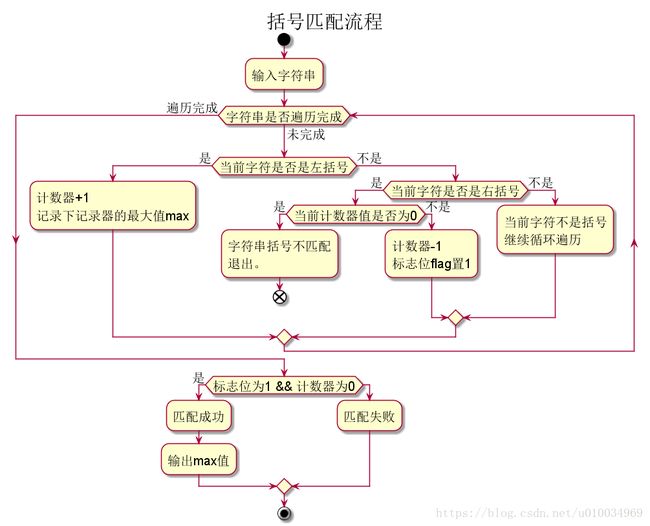
3. 括号匹配
问题
编写一个程序,判断一串字符里的括号是否配对,配对的话输出最大层数。(题目中只要求判断圆括号)
例如:
(1((2)3) 不配对
(ss( s ) ) 配对,层数2
解&解析
本题目可以使用堆栈的思路去解(如果在这里实现堆栈的数据结构就太小题大做了)
解法如下:
#includeif(a[i]=='('){ // 如果是左括号直接入栈
s[++top]=a[i];
if(top > *max)
*max = top;
continue;
}
if(a[i]==')'){ // 如果是右括号,则尝试匹配
temp = s[top];
if(temp=='('){
flag = 1;
top--;
continue;
}else{
flag = 0;
break;
}
}
}
if(flag&&(top==0)){
return 1;
}else{
return 0;
}
}
int main(){
int N,i;
scanf("%d",&N);
int len;
int max;
char a[10000]={'\0'};
scanf("%s",a);
len = strlen(a);
if(MatchCheck(a,len,&max))
printf("match, %d\n",max);
else
printf("Not match\n");
return 0;
} 在这里我们使用了一个10000个元素的char数组作为堆栈,并使用整型变量top作为栈顶指针。
获取到键盘的输入后,将键盘输入作为字符数组传入处理函数中并进行遍历。遍历到左括号时,入栈,栈顶指针+1,同时记录下栈顶指针的最大值(即最大匹配层数),遍历到右括号时,测试右括号和栈顶元素是否匹配,匹配则出栈,栈顶指针-1。遍历结束,判断是否匹配过且栈是否为空(top == 0),是则返回1,否则返回0。
上述代码参考了https://www.cnblogs.com/ncuhwxiong/p/6685629.html的代码。实际上源代码考虑了不同括号下的情况,若只像本题这样仅考虑一种括号的情况,还可以将堆栈部分省略如下:
#includeif(a[i]=='('){
top++;
if(top > *max)
*max = top;
continue;
}
if(a[i]==')'){
if(top > 0){ //Warning
flag = 1;
top--;
continue;
}else{
return 0;
}
}
}
if(flag&&(top==0)){
return 1;
}else{
return 0;
}
}
int main(){
int N,i;
scanf("%d",&N);
int len;
int max;
char a[10000]={'\0'};
scanf("%s",a);
len = strlen(a);
if(MatchCheck(a,len,&max))
printf("match, %d\n",max);
else
printf("Not match\n");
return 0;
} 本代码的逻辑如下:
4. C++的多态
C++的多态性用一句话概括就是:在基类的函数前加上virtual关键字,在派生类中重写该函数,运行时将会根据对象的实际类型来调用相应的函数。如果对象类型是派生类,就调用派生类的函数;如果对象类型是基类,就调用基类的函数。
问题
有如下代码:
#include 问:程序的输出是什么?该程序会不会导致内存泄漏?
解答
先说结果。
在关键函数(A、B的构造函数和析构函数)加打印信息(代码中注释处)测试结果。
xxx@xxx:~$ ./test.o
A()
B()
CB
~A()从结果可以看到,代码调用了A和B的构造函数,调用了B的GetStr()方法,执行了A的析构函数。
因此,B的构造函数中动态申请的10个字符串的空间没能被delete掉,导致内存泄漏。
代码解析
(参考:https://www.cnblogs.com/cxq0017/p/6074247.html)
1. 输出部分
涉及知识点:虚函数
基类A中,GetStr()函数的定义:
virtual char * GetStr()
{
return str;
}这里使用了关键字virtual,即定义了一个虚函数GetStr()。
在A类的派生类B类中也定义了一个非虚函数GetStr(),这时使用的是晚绑定。
晚绑定和早绑定:
将函数体和函数调用关联起来,就叫绑定。
在程序运行之前(也就是编译和链接时),执行的绑定是早绑定。
迟绑定发生在运行时,基于不同类型的对象。当一种语言实现迟绑定时,必须有某种机制确定对象的具体类型然后调用合适的成员函数。
即:
编译器使用晚绑定时候,就会在运行时再去确定对象的类型以及正确的调用函数。
调用基类对象的虚方法的时候(a->GetStr())会去判断实际上对象的类型(例如这里的*a实际上是个指向B类对象的指针),然后执行对应类型的函数(此处执行了B类的GetStr()函数)。
若我们删掉virtual关键字使得其不为虚函数,即:
class A
{
public:
char str[10];
A()
{
printf("A()\n"); //自行加入
sprintf(str,"%s","CA");
}
~A()
{
printf("~A()\n"); //自行加入
}
char * GetStr() //修改为非虚函数
{
return str;
}
};输出结果:
xxx@xxx:~$ ./12.o
A()
B()
CA
~A()如结果所示,删除了virtual关键字后,调用了A类的函数。
2. 内存泄漏部分
此处首先要注意的是子类和父类的构造函数之间的关系。
构造原则如下:
如果子类没有定义构造方法,则调用父类的无参数的构造方法。
如果子类定义了构造方法,不论是无参数还是带参数,在创建子类的对象的时候,首先执行父类无参数的构造方法,然后执行自己的构造方法。
在创建子类对象时候,如果子类的构造函数没有显式调用父类的构造函数,则会调用父类的默认无参构造函数。
在创建子类对象时候,如果子类的构造函数没有显式调用父类的构造函数且父类自己提供了无参构造函数,则会调用父类自己的无参构造函数。
在创建子类对象时候,如果子类的构造函数没有显式调用父类的构造函数且父类只定义了自己的有参构造函数,则会出错(如果父类只有有参数的构造方法,则子类必须显式调用此带参构造方法)。
如果子类调用父类带参数的构造方法,需要用初始化父类成员对象的方式。
例如:
#include
从程序的输出我们可以看到,在执行了新建B类对象的时候依次执行了A、B的构造函数。
但是在delete a的时候,执行了A类的析构函数而不是B类析构函数。因此无法释放新建B类对象时动态申请的内存,造成内存泄漏。
结论:一般情况下,基类的析构函数==必须==声明为虚函数,即:
class A
{
public:
char str[10];
A()
{
printf("A()\n"); //自行加入
sprintf(str,"%s","CA");
}
virtual ~A()
{
printf("~A()\n"); //自行加入
}
virtual char * GetStr()
{
return str;
}
};程序输出:
laohuajian@kitking:~$ ./12.o
A()
B()
B GetStr()
CB
~B()
~A()此时执行了B类的析构函数。
总结
使用基类对象指针指向子类对象,需要注意virtual关键字的使用。
5. C++中的const成员函数
用途
如果一个成员函数在逻辑上不会修改对象的状态(字段),就应该定义为const函数。
声明方式
类内定义:
class Screen {
public:
char get() const;
};类外定义:
char Screen::get() const {
return _screen[_cursor];
}注意const关键字的位置。
注意
若将成员成员函数声明为const,则该函数不允许修改类的数据成员。
例如:
class Screen { int _cursor; public: int ok() const {return _cursor; } int error(intival) const { _cursor = ival; } };注意:这里的error()函数会编译报错。
把一个成员函数声明为const**可以保证这个成员函数不修改数据成员,但是,如果数据成员是指针,则const成员函数并不能保证不修改指针指向的对象**,编译器不会把这种修改检测为错误。
例如下面的代码。
class Name { public: void setName(const string &s) const; private: char *m_sName; }; void setName(const string &s) const { m_sName = s.c_str(); // 错误!不能修改m_sName; for (int i = 0; i < s.size(); ++i) m_sName[i] = s[i]; // 不好的风格,但不是错误的。 }上述代码中的第10行会报错,因为改变了指针成员变量
m_sName的指向。但是第13、14行不会报错,因为这里修改的是指针指向的对象而不是指针本身的指向。
const成员函数可以被具有相同参数列表的非const成员函数重载,在这种情况下,类对象的常量性决定调用哪个函数。
例如:
定义:
class Screen { public: char get(int x,int y); char get(int x,int y) const; };调用:
const Screen cs; Screen cc2; char ch = cs.get(0, 0); // 调用const成员函数 ch = cs2.get(0, 0); // 调用非const成员函数
小结
- const成员函数可以访问非const对象的非const数据成员、const数据成员,也可以访问const对象内的所有数据成员;
- 非const成员函数可以访问非const对象的非const数据成员、const数据成员,但不可以访问const对象的任意数据成员;
- 作为一种良好的编程风格,在声明一个成员函数时,若该成员函数并不对数据成员进行修改操作,应尽可能将该成员函数声明为const 成员函数。