通俗易懂ELMO原理+中文词嵌入实现(训练神雕侠侣小说)
1. 前言
今天给大家介绍一篇2018年提出的论文《Deep contextualized word representations》,在这篇论文中提出了一个很重要的思想ELMo。本文作者推出了一种新的基于深度学习框架的词向量表征模型,这种模型不仅能够表征词汇的语法和语义层面的特征,也能够随着上下文语境的变换而改变。简单来说,本文的模型其实本质上就是基于大规模语料训练后的双向语言模型内部隐状态特征的组合。实验证明,新的词向量模型能够很轻松的与NLP的现有主流模型相结合,并且在六大NLP任务的结果上有着巨头的提升。同时,作者也发现对模型的预训练是十分关键的,能够让下游模型去融合不同类型的半监督训练出的特征。
2.ELMo简介
ELMo是一种新型深度语境化词表征,可对词进行复杂特征(如句法和语义)和词在语言语境中的变化进行建模(即对多义词进行建模)。我们的词向量是深度双向语言模型(biLM)内部状态的函数,在一个大型文本语料库中预训练而成。
说到词向量,我们一定会联想到word2vec,因为在它提出的词向量概念给NLP的发展带来了巨大的提升。而ELMo的主要做法是先训练一个完整的语言模型,再用这个语言模型去处理需要训练的文本,生成相应的词向量,所以在文中一直强调ELMo的模型对同一个字在不同句子中能生成不同的词向量。
但是与word2vec不同的是ELMo采用双向LSTM,即给定的一个句子![]()
![]() ,我们构建的语言模型就是通过一个词汇的上下文去,预测一个词
,我们构建的语言模型就是通过一个词汇的上下文去,预测一个词![]() :
:

该语言模型的输入就是词向量(获取的途径多种多样,作者提了一个是字符卷积),然后通过一个多层的前向LSTM网络,在LSTM的每一层,我们都能输出基于文本的一个向量表示。其最后的一层的输出,经过一层softmax归一,就可以来预测词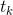 ,大概流程长下面这样。
,大概流程长下面这样。

现在流行使用双向语言模型,于是我们可以将正向LSTM和反向LSTM拼接起来(注意两个LSTM的参数是不进行共享的),而我们的目标函数就是取这两个方向语言模型的最大似然。
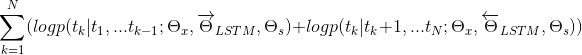
于是最终结构形式便如下:

3.论文模型结构
ELMO是一个结合双向语言模型表示层的语言模型,对于每个词,一个具有L层的双向语言模型(论文中使用的双向LSTM)会计算出2L+1个表示:
![]()
其中![]() 表示双向语言模型的第一层,每一层都是由双向LSTM拼接而成。
表示双向语言模型的第一层,每一层都是由双向LSTM拼接而成。
而前面也说了,ELMO本质上就是一个任务导向的,双向语言模型(biLM)内部的隐状态层的组合。通用的表达式如下,

其中, 是用来控制ELMO模型生成的向量大小,原文中说该系数对于后续的模型优化过程有好处(在附件中,作者强调了这个参数的重要性,因为biLM的内核表达,与任务需要表达,存在一定的差异性,所以需要这么一个参数去转换。并且,这个参数对于,last-only的情况(就是只取最后一层,ELMO的特殊情况),尤其重要),另一个参数s,原论文只说了softmax-normalized weights,其实它的作用等同于层间的归一化处理。
是用来控制ELMO模型生成的向量大小,原文中说该系数对于后续的模型优化过程有好处(在附件中,作者强调了这个参数的重要性,因为biLM的内核表达,与任务需要表达,存在一定的差异性,所以需要这么一个参数去转换。并且,这个参数对于,last-only的情况(就是只取最后一层,ELMO的特殊情况),尤其重要),另一个参数s,原论文只说了softmax-normalized weights,其实它的作用等同于层间的归一化处理。
有时候我们并不需要从头开始去训练对应的词向量,我们只需要将ELMO与预训练的词向量hk结合,让模型去训练学习ELMO的内部状态的线性组合,然后,生成一个共同的词向量![]() ,简单来说,就是用预训练的词向量来取代原来的语料库的词向量,相当于finetune,并用于后期的训练。
,简单来说,就是用预训练的词向量来取代原来的语料库的词向量,相当于finetune,并用于后期的训练。

至此,整个模型结构已经说清楚了。作者在实验论证该预训练模型之前,阐述了一下其预训练过程。最终作者用于实验的预训练模型,为了平衡语言模型之间的困惑度以及后期NLP模型的计算复杂度,采用了2层Bi-Big-Lstm,共计4096个单元,输入及输出维度为512维,并且在第一层和第二层之间使用残差网络进行连接,包括最初的那一层文本向量(用了2048个过滤器, 进行基于字符的卷积计算),整个ELMO会为每一个词提供一个3层的输出,而下游模型学习的就是这3层输出的组合。另外,作者强调了一下,对该模型进行FINE-TUNE训练的话,对具体的NLP任务会有提升的作用。
作者的论文的实验部分,具体展示了ELMO模型在六大nlp任务上的表现,证实了该模型的有效性。
4.总结
1.ELMO模型只取最后一层的输出,和多层的线性组合,实验结果发现,只取最后一层也取得了很好的效果,而且多层的效果提升并不是特别的明显(较之于只取最后一层),结果见下图:

2.ELMo的假设前提一个词的词向量不应该是固定的,所以在一词多意方面ELMo的效果一定比word2vec要好。
3.word2vec的学习词向量的过程是通过中心词的上下窗口去学习,学习的范围太小了,而ELMo在学习语言模型的时候是从整个语料库去学习的,而后再通过语言模型生成的词向量就相当于基于整个语料库学习的词向量,更加准确代表一个词的意思。
4.ELMO可以广泛的应用到任何自然语言处理的下游任务,可以用于求解相似问题
5.代码实现
我在我的github上开源了一个我利用ELMO模型训练金庸的武侠小说小说神雕侠侣,这里我并没有使用预训练模型来,而是直接以小说作为语料库进行训练。这里以\n为分隔符,一共分隔了14200个短文本,以i5-8400的cpu进行训练,训练时间为2小时50分钟,平均训练速率为1.4it/s,最终损失在3.45左右。
[['小龙女', 0.72927003860473633],
['李莫愁', 0.64811800956726074],
['黄蓉', 0.62415822315216064],
['郭襄', 0.60209492921829224],
['说', 0.6064872646331787],
['周伯通', 0.59836891555786133],
['法王', 0.5962932949066162],
['郭靖', 0.5876373634338379],
['陆无双', 0.58300589084625244]]文字参考链接:
1、https://www.jianshu.com/p/d93912d5280e
2、https://www.cnblogs.com/huangyc/p/9860430.html
代码参考:
https://github.com/huseinzol05/NLP-Models-Tensorflow/tree/master/embedded
详细内容请参考我的github:
https://github.com/RundongChou/elmo-chinese-oversimplified