网络爬虫篇——入门
Github项目:https://github.com/lei940324/spider/blob/master/网络爬虫——入门.md
公众号:https://mp.weixin.qq.com/s/Ew8HyrsUyiZ2dhnp1-TOJw
首先我们要明确网络爬虫是个啥东西。其实网络爬虫说白了就是爬取网络上你能看得到的数据,那些不能获得的数据,比如别人的银行卡密码(我也想知道啊)就别想了,况且就算能得到那显然也是违法的。
那这么说,感觉也没啥用啊,别着急,如果你想大量获取一些数据,靠人工复制的话,你是不是会崩溃?这时候爬虫就可以闪亮登场了,况且百度、谷歌的核心业务本质上就是爬虫,抢火车票也是一种爬虫,这么一想,是不是觉得爬虫有些用了?
现在是大数据时代,要进行数据挖掘首要问题就是数据获取,没数据可以说人工智能,深度学习什么的,通通实现不了。最后网络爬虫上手很容易,只要你有一些python基础,几行代码可能就可以实现批量数据获取,下面开始进行学习吧。
准备工作
安装谷歌浏览器
下载谷歌浏览器,以后爬虫都是用Google Chrome,包括使用selenium就是控制的Google Chrome浏览器。
安装有关爬虫的第三方库
电脑需安装有关爬虫的第三方库,包括:requests,lxml,selenium,openpyxl;这四个库可以直接通过pip安装。需要注意的是,lxml坑比较多,有的电脑安装过程会报错,把报错信息复制一下,网上查查,一般都有解决方案。
掌握python基础内容
需要掌握python的基础内容,包括常用函数的使用,字符串,列表,字典等概念都需要熟练掌握,内容不多,关键是实战。可以通过学习网上教程、购买书籍、观看视频进行学习。
网上教程推荐:
- 廖雪峰教程
- 菜鸟教程
书籍推荐:
- python无师自通
- python编程快速上手 让繁琐工作自动化
- python 3网络爬虫开发实战
- python网络爬虫从入门到实践
学习xpath基础
xpath定位是解析HTML文件的利器,因此也要学习xpath,可以参考XPath 教程。为了防止刚开始就接触这么理论的东西,会严重打击各位的积极性,因此随后我会写一篇精简版的xpath入门文章。
安装谷歌浏览器插件:XPath Helper
XPath Helper可以极大方便地使用Xpath进行定位。谷歌安插件还挺麻烦的,这里给出百度云链接进行下载:
百度云链接:https://pan.baidu.com/s/1llpDrQRvq1TB5xh5ZV25Pg
提取码:zvzp
将文件进行解压,打开浏览器<<<右上角三个点<<<更多工具<<<拓展程序,把右上角开发者模式打开,点击加载已解压的拓展程序,选择刚才解压的路径,搞定。


把该图标右下角按钮打开,这样浏览器右上方会有X的标志,打开一个网页,再点击该标志会出现两个黑框,说明安装成功。


安装谷歌浏览器驱动程序chromedriver
谷歌浏览器驱动程序chromedriver在后文selenium需要用到,可以从百度云里下载。
链接:https://pan.baidu.com/s/1WJjXcAPn2fNwBbDZ3RcGVw
提取码:4pgm
将下载的exe程序放到python安装路径,例如:F:\Anaconda3\。
爬虫思路
实现网络数据抓取,其实流程无非就这几步:
发送请求<<<获取响应内容<<<解析数据内容<<<清洗数据<<<存储数据
使用python发送请求一般用requests,解析数据进行定位用xpath,也就是lxml库,存储数据如果数据量比较少的话,直接存入excel就行,使用openpyxl库,如果requests用不了再考虑用selenium,selenium库是模拟打开浏览器进行操作,所以更像人,缺点是效率低。优先使用前者,因为可以用多线程,这两种模式基本就够爬90%以上的网站了,不需要考虑什么异步IO库,因为爬取数据过快很容易被网站封IP,而且爬亦有道,爬数据的同时还要考虑网站能不能承受你的爬取速度,所以不是追求极致效率的话,用requests基本就够用了。
还有一个要讲的是网址的构造,举一个微博的例子:https://s.weibo.com/weibo?q=股市&Refer=index&page=2。从这个网址可以看出q=""里面是关键词,这里关键词是股市,page="2"代表页码为2,所以如果想批量爬取数据,首先需要获得待爬网址列表,因此可以通过以下代码进行构建:
keyword=''
urls=[]
for i in range(1,51): #获取1到50页
urls.append(f'https://s.weibo.com/weibo?q={keyword}&Refer=index&page={i})
requests+lxml库的基本使用
无需表头信息的请求
首先需要导入import requests
构建网址,这里我们以百度首页为例
url = 'https://www.baidu.com/'
发送请求,常用的就是get和post方式,大部分时候都是用get,一般登陆网站要用到post,通过post方式提交表单。
req = requests.get(url)
解析响应信息
req.raise_for_status() #判断响应是否成功,否则报错
req.encoding = 'utf-8' #编码设定,一般都为'utf-8'
data=req.text #获取响应文本
下面是data的截图,貌似是一堆乱七八糟的东西…这谁顶得住,莫怕,其实返回的是网页源码,可以在浏览器里,百度首页点击右键,选择查看网页源代码,如果跟data一致,说明请求成功了。那获取这个有什么用呢?仔细浏览你会发现数据都隐藏在这些源码里,后面的工作就是通过xpath定位进行解析。

提取数据,一个比较简单的方法是通过正则表达式,但是缺点是太不稳定,假如网站稍一更换源码,数据就可能提取错误,因此解析数据首选xpath。这里假定你已经了解了xpath的相关知识并安装了XPath Helper插件,下面我们开始。
比如想提取百度一下,右键点击百度一下,选择检查,可以发现他在input标签里,使用XPath Helper工具输入//input,发现搜索框也变黄色了,说明只通过input定位还不够,继续精确条件,输入//input[@type="submit"],这样就定位到百度一下按钮了。
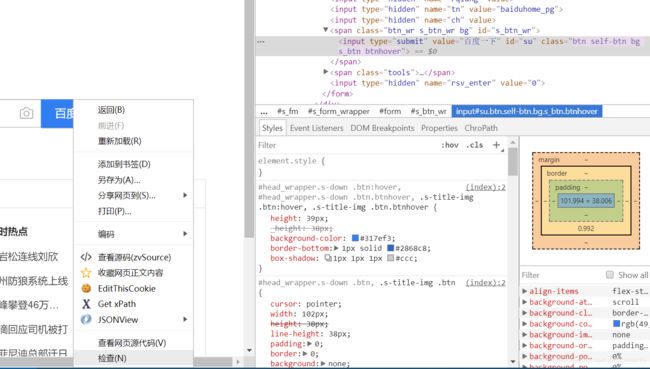


那么如何得到它的文本呢,下面就用不到浏览器了,需要在python敲代码,将得到的data转化为lxml对象进行解析,comment显示就是百度一下,大功告成!
from lxml import etree
selector = etree.HTML(data)
comment = selector.xpath('//input[@type="submit"]//text()')
提供表头信息的请求
大部分的网址其实都有反爬虫机制,所以一般情况都要构造表头信息进行伪装,下面介绍一些常用到的headers信息:
User-Agent:User Agent中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。
Cookie:有时也用其复数形式 Cookies,指某些网站为了辨别用户身份、进行 session 跟踪而储存在用户本地终端上的数据,可以理解为登陆信息。
基本知道这两个信息就够用了,下面举爬取微博的例子:
url = 'https://s.weibo.com/weibo?q=%E4%B8%AD%E7%BE%8E%E8%B4%B8%E6%98%93%E6%88%98&Refer=index'

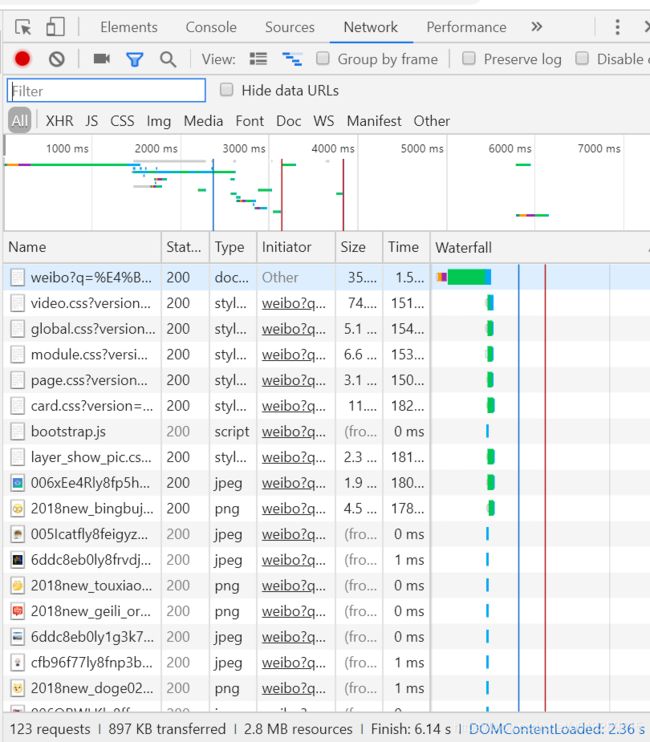
那么如何获取表头信息呢?使用谷歌浏览器点击F12打开开发者工具,点击Network。什么,空的?别慌,点击F5刷新一下界面。

是不是出来一大堆东西,一般翻到第一个,点击一下就可以看到表头信息了,在里面找到User-Agent和Cookie的信息,复制下来。



然后开始构造表头信息,要注意的是,header是字典类型
header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.6788.400 QQBrowser/10.3.2910.400",
'Cookie':"SINAGLOBAL=4293099610477.9463.1549550182199; UM_distinctid=16a00235a5d7d-091ed8d22e5b52-33514776-e1000-16a00235a5f12d; un=15806527017; wvr=6; UOR=,,login.sina.com.cn; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WWzpLexbJaLHOf3D4eAUn3N5JpX5KMhUgL.Fo-Ee0eNeoepe0e2dJLoIpRLxK.L1hzL1KS3Ig2LxK-L1h-LB-eLxK-LB-BL1K5t; ALF=1590827260; SSOLoginState=1559291261; SCF=AiIaD5kzjZ9YogeGOj7-S7f5oSh9HnUJ5R94XcInM3enyheIxpfW9zaRFuxv6mAwWZkocwGEa6FB5rCS9rbD6XY.; SUB=_2A25x9JXQDeRhGeNM6FEW8i3NyD-IHXVSg4AYrDV8PUNbmtBeLUGikW9NTj86A0bR7mdPyzPY5BsDmh2gP1xnSjpS; SUHB=0FQrNyhKBgW3ZH; _s_tentry=-; Apache=6709001313915.11.1559291283748; WBStorage=0a656b6f5b1c1bfe|undefined; ULV=1559291283897:52:17:5:6709001313915.11.1559291283748:1559216419881"}
发送请求,这里加上我们刚才构造的表头信息
req = requests.get(url, headers=header)
解析响应信息,得到数据data
req.raise_for_status() #判断响应是否成功,否则报错
req.encoding = 'utf-8' #编码设定,一般都为'utf-8'
data=req.text #获取响应文本
下面是获取各条微博信息,跟上文一样,使用XPath Helper进行定位。
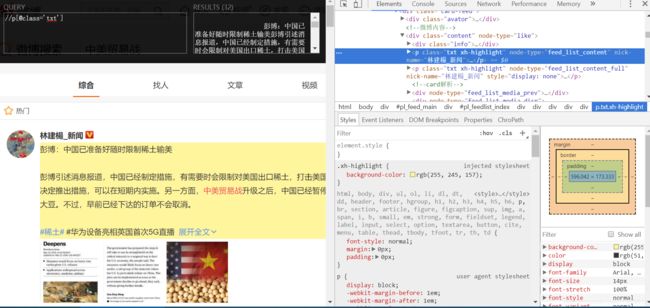
抓取每条信息内容,这里进行一个循环遍历得到文本。将获取的文本进行清洗,去除未展开全文的文本,以及# #等之内的内容,这里就要用到正则表达式,这里多说一句,关于解析数据,我只推荐学正则和xpath,都非常实用,这里给出正则表达式的中文官方文档,尽量读一遍:re — 正则表达式操作,并且要熟练运用,然后把清洗后的数据放入datas列表里。
import re
datas=[]
del1 = re.compile('(\s)+|/|更多内容请见长微博。| 收起全文|收起全文|\(.*?\)|【(.*?)】')
del2 = re.compile('((.*?))|『(.*?)』|《(.*?)》|O.*|- 来自.*|d$')
data = selector.xpath("//p[@class='txt']")
for t in data:
txt = t.xpath('.//text()')
txt = ''.join(map(lambda x: x.strip() , txt))
txt=re.sub(del1, '', txt)
txt=re.sub(del2, '', txt)
datas.append(txt)
最后把datas里的数据存入excel文件,这里需要用到openpyxl的一些基本操作,可以参考openpyxl的基本操作,基本介绍了常用的命令。
data_value=set() #纪录已填入数据
wb=openpyxl.Workbook()
sheet = wb.active
italic24Font = Font(bold=True)
sheet['A1']='情绪语句'
sheet['A1'].font = italic24Font
row_num=sheet.max_row
#去掉无法识别字符
ILLEGAL_CHARACTERS_RE = re.compile(r'[\000-\010]|[\013-\014]|[\016-\037]')
for i in range(len(datas)):
if datas[i] not in data_value:
datas[i] = ILLEGAL_CHARACTERS_RE.sub(r'', items[i].value)
sheet.cell(row=row_num+1, column=1).value = datas[i]
data_value.add(datas[i])
row_num += 1
wb.save('') #保存路径
存入excel结果显示,大功告成!

异步加载请求构建
有时候你会发现,明明数据就在那里,偏偏网页源代码里没有,或者网站一次加载不全,需要手动点击才会加载,那很有可能该网站采用的是异步加载技术,那怎么办?别慌,慢慢分析呗。这里以爬取豆瓣电影为例。网址:https://movie.douban.com/tag/#/。从网站我们能看到一次只能加载出20个电影介绍,想看更多的话,需要点击加载更多。
这时候我们点击F12打开开发者选项,发现都是空的,什么都没有,点击加载更多按钮,找到XHR选项,发现随着点击加载出一个网址,点击右键打开它,发现原来加载的数据都在这里啊。




那我们分析网址的规律,再次点击加载更多,会发现又出来一个网址。

查看这两个网址的命名规律:
第一个:https://movie.douban.com/j/new_search_subjects?sort=U&range=0,10&tags=&start=40
第二个:https://movie.douban.com/j/new_search_subjects?sort=U&range=0,10&tags=&start=20
会发现除了最后start=不同,而且每20个递增,其他的都是相同的,说明真相只有一个,它就是真正响应的网址,那用requests请求一下不就OK了,原来这么简单嘛,不过有一点不同的是,网页返回的是json信息,所以我们这里使用json库进行解析。
import requests
import json
for a in range(3):
url_visit = 'https://movie.douban.com/j/new_search_subjects?sort=U&range=0,10&tags=&start={}'.format(a*20)
file = requests.get(url_visit).json()#这里跟之前的不一样,因为返回的是 json 文件
for i in range(20):
dict=file['data'][i] #取出字典中 'data' 下第 [i] 部电影的信息
title=dict['title']
rate=dict['rate']
url=dict['cover']
res = requests.get(url)
with open(r'C:\Users\Administrator\Desktop\图片\{}-{}.jpg'
.format(title,rate),'wb') as ff:
ff.write(res.content)
selenium库的基本使用
关于selenium的基本操作可以参考:python+selenium常用命令总结以及selenium中文官方文档。
现在大部分网站其实都是用的异步加载技术,如果JS渲染没有加密,那么分析相对比较容易,这样可以用requests构建请求,但很遗憾,很多大厂的网站都有加密,解析起来太过复杂,那么我们就不要正面刚了,采用selenium进行模拟爬取,它的优点就是所见即所爬,管你是静态页面还是JS渲染页面,只要能看到,我就能爬取出来。所以一般我看到网站是异步加载的,就直接用selenium进行爬取,没心思进行解析。下面我们还是以模拟登陆微博以获取cookie信息为例(怎么又是我):
首先导入用到的模块
from selenium.webdriver.chrome.options import Options
from selenium import webdriver
import time
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
url为微博登陆网址
url='https://passport.weibo.cn/signin/login'
构建带有参数的谷歌浏览器
chrome_options = Options()
chrome_options.add_argument('--no-sandbox') #解决DevToolsActivePort文件不存在的报错
chrome_options._arguments = ['disable-infobars'] #去掉谷歌浏览器正在被自动测试控制字样
chrome_options.add_argument('window-size=1920x3000') #指定浏览器分辨率
chrome_options.add_argument('--disable-gpu') #谷歌文档提到需要加上这个属性来规避bug
chrome_options.add_argument('--hide-scrollbars') #隐藏滚动条, 应对一些特殊页面
# 调用带参数的谷歌浏览器
driver = webdriver.Chrome(chrome_options=chrome_options)
driver.maximize_window() #窗口最大化
加载网站
driver.get(url)
print('正在加载界面....')

通过检查,找到登陆按钮的ID信息
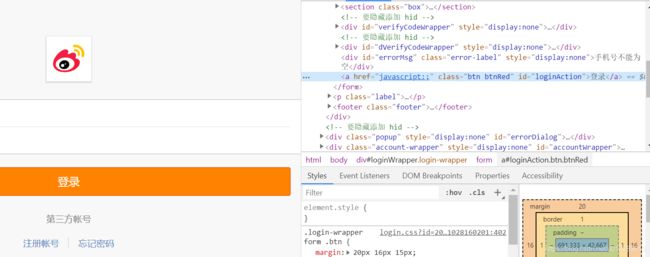
等待最大响应时间为10秒,判断其登录框是否出现
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "loginAction")))
同样通过检查,找到账号和密码的ID信息
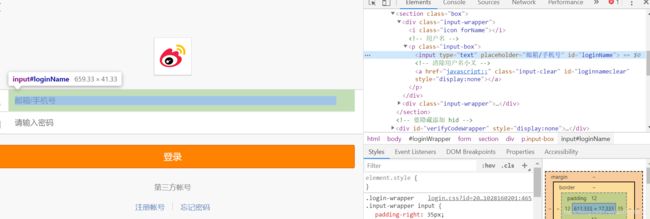

定位之后填入你的账号和密码,这里username改为你的账号,password改为你的密码,注意这里要是字符串格式,例如username=‘123456’。
driver.find_element_by_id("loginName").send_keys(username)
driver.find_element_by_id("loginPassword").send_keys(password)
点击登陆按钮
driver.find_element_by_id("loginAction").click()
print('已登录,正在获取cookie....')
等待网页加载成功,这里随便选的一个控件进行定位,判断其是否存在,若存在说明页面已经加载,等待3秒,获取其cookies
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.NAME, "viewport")))
time.sleep(3)
cookies = driver.get_cookies()
获取到的信息是字典格式,需要转化为字符串格式,大功告成!
cookie_list = []
for dict in cookies:
cookie = dict['name'] + '=' + dict['value']
cookie_list.append(cookie)
cookie = ';'.join(cookie_list)
print('获取cookie成功\ncookie:%s'%cookie)
以上讲解了requests+lxml以及selenium库的简单使用,基本够爬取90%以上的网站了,但是不足之处在于,用的都是单线程,只能一个个网站去爬,效率太过低下,因此随后的内容,就要开始多线程的讲解,并且还有关于selenium内嵌结构如何处理。