数据库:mysql:重做日志文件(redo log file)
一、重做日志缓冲(redo log buffer)
1. log block
在InnoDB存储引擎中,重做日志都是以512字节进行存储的。这意味着重做日志缓存、重做日志文件都是以块(block)的方式进行保存的,称之为重做日志块(redo log block),每块的大小为512字节。
若一个页中产生的重做日志数量大于512字节,那么需要分割为多个重做日志块进行存储。此外,由于重做日志块的大小和磁盘扇区大小一样,都是512字节,因此重做日志的写入可以保证原子性,不需要doublewrite技术。
2. redo log buffer 结构

3. log block刷新机制
log buffer根据一定的规则将内存中的log block刷新到磁盘。这个规则具体是:
- 事务提交时
- 当log buffer中有一半的内存空间已经被使用时
- log checkpoint时
二、重做日志文件
1. 重做日志定义
在默认情况下,在InnoDB存储引擎的数据目录下会有两个名为ib_logfile0和ib_logfile1的文件。在MySQL官方手册中将其称为InnoDB存储引擎的日志文件,不过更准确的定义应该是重做日志文件(redo log file)。为什么强调是重做日志文件呢?因为重做日志文件对于InnoDB存储引擎至关重要,它们记录了对于InnoDB存储引擎的事务日志,记录的是关于每个页(Page)的更改的物理情况。
2. 重做日志作用
当实例或介质失败(media failure)时,重做日志文件就能派上用场。例如,数据库由于所在主机掉电导致实例失败,InnoDB存储引擎会使用重做日志恢复到掉电前的时刻,以此来保证数据的完整性。
3. 重做日志(redo log) VS 二进制日志(binlog)
(1) binlog定义
其用来进行POINT-IN-TIME(PIT)的恢复及主从复制(Replication)环境的建立.
(2) 区别
- 重做日志是在InnoDB存储引擎层产生,而二进制日志是在MySQL数据库的上层产生的,并且二进制日志不仅仅针对于InnoDB存储引擎,MySQL数据库中的任何存储引擎对于数据库的更改都会产生二进制日志。
- 两种日志记录的内容形式不同。MySQL数据库上层的二进制日志是一种逻辑日志,其记录的是对应的SQL语句。而InnoDB存储引擎层面的重做日志是物理格式日志,其记录的是对于每个页的修改。
- 两种日志记录写入磁盘的时间点不同,二进制日志只在事务提交完成后进行一次写入。而InnoDB存储引擎的重做日志在事务进行中不断地被写入,这表现为日志并不是随事务提交的顺序进行写入的。

*T1、*T2、*T3表示的是事务提交时的日志.
4. 重做日志文件属性
mysql> SHOW VARIABLES LIKE'innodb%log%';
+----------------------------------+------------+
| Variable_name | Value |
+----------------------------------+------------+
| innodb_log_file_size | 50331648 |
| innodb_log_files_in_group | 2 |
| innodb_log_group_home_dir | ./ |
+----------------------------------+------------+
- innodb_log_file_size
指定每个重做日志文件的大小。在InnoDB1.2.x版本之前,重做日志文件总的大小不得大于等于4GB,而1.2.x版本将该限制扩大为了512GB。 - innodb_log_files_in_group
指定了日志文件组中重做日志文件的数量,默认为2 - innodb_mirrored_log_groups
指定了日志镜像文件组的数量,默认为1,表示只有一个日志文件组,没有镜像。若磁盘本身已经做了高可用的方案,如磁盘阵列,那么可以不开启重做日志镜像的功能 - innodb_log_group_home_dir
指定了日志文件组所在路径,默认为./,表示在MySQL数据库的数据目录下
5. 重做日志大小
重做日志文件的大小设置对于InnoDB存储引擎的性能有着非常大的影响。一方面重做日志文件不能设置得太大,如果设置得很大,在恢复时可能需要很长的时间;另一方面又不能设置得太小了,否则可能导致一个事务的日志需要多次切换重做日志文件。此外,重做日志文件太小会导致频繁地发生async checkpoint,导致性能的抖动。
例如,用户可能会在错误日志中看到如下警告信息:
090924 11:39:44 InnoDB:ERROR:the age of the last checkpoint is 9433712,
InnoDB:which exceeds the log group capacity 9433498.
InnoDB:If you are using big BLOB or TEXT rows,you must set the
InnoDB:combined size of log files at least 10 times bigger than the
InnoDB:largest such row.
090924 11:40:00 InnoDB:ERROR:the age of the last checkpoint is 9433823,
InnoDB:which exceeds the log group capacity 9433498.
InnoDB:If you are using big BLOB or TEXT rows,you must set the
InnoDB:combined size of log files at least 10 times bigger than the
InnoDB:largest such row.
090924 11:40:16 InnoDB:ERROR:the age of the last checkpoint is 9433645,
InnoDB:which exceeds the log group capacity 9433498.
InnoDB:If you are using big BLOB or TEXT rows,you must set the
InnoDB:combined size of log files at least 10 times bigger than the
InnoDB:largest such row.
上面错误集中在InnoDB:ERROR:the age of the last checkpoint is 9433645,InnoDB:which exceeds the log group capacity 9433498。这是因为重做日志有一个capacity变量,该值代表了最后的检查点不能超过这个阈值,如果超过则必须将缓冲池(innodb buffer pool)中脏页列表(flush list)中的部分脏数据页写回磁盘,这时会导致用户线程的阻塞。
6. 重做日志格式


7. 重做日志写入
(1) 重做日志写入写入流程
写入重做日志文件的操作不是直接写,而是先写入一个重做日志缓冲(redo log buffer)中,然后按照一定的条件顺序地写入日志文件。从重做日志缓冲往磁盘写入时,是按512个字节,也就是一个扇区的大小进行写入。因为扇区是写入的最小单位,因此可以保证写入必定是成功的。因此在重做日志的写入过程中不需要有doublewrite。
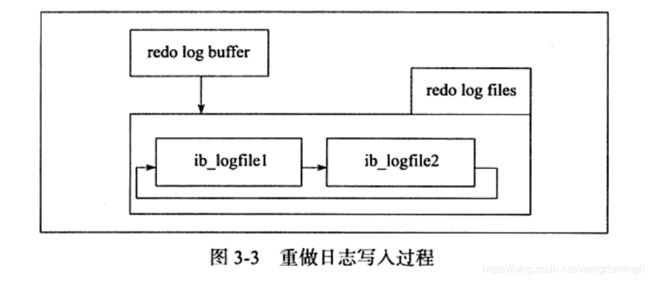
(2)重做日志缓冲写入磁盘上的重做日志文件条件
- 主线程(master thread)中每秒会将重做日志缓冲写入磁盘的重做日志文件中,不论事务是否已经提交。
- 由参数innodb_flush_log_at_trx_commit控制,表示在提交(commit)操作时,处理重做日志的方式。
mysql> show variables like 'innodb_flush_log_at_trx_commit';
+--------------------------------+-------+
| Variable_name | Value |
+--------------------------------+-------+
| innodb_flush_log_at_trx_commit | 1 |
+--------------------------------+-------+
参数innodb_flush_log_at_trx_commit的有效值有0、1、2。
- 0 代表当提交事务时,并不将事务的重做日志写入磁盘上的日志文件,而是等待主线程每秒的刷新。
- 1 表示在执行commit时将重做日志缓冲同步写到磁盘,即伴有fsync的调用。
- 2 表示将重做日志异步写到磁盘,即写到文件系统的缓存中。因此不能完全保证在执行commit时肯定会写入重做日志文件,只是有这个动作发生。
因此为了保证事务的ACID中的持久性,必须将innodb_flush_log_at_trx_commit设置为1,也就是每当有事务提交时,就必须确保事务都已经写入重做日志文件。那么当数据库因为意外发生宕机时,可以通过重做日志文件恢复,并保证可以恢复已经提交的事务。而将重做日志文件设置为0或2,都有可能发生恢复时部分事务的丢失。不同之处在于,设置为2时,当MySQL数据库发生宕机而操作系统及服务器并没有发生宕机时,由于此时未写入磁盘的事务日志保存在文件系统缓存中,当恢复时同样能保证数据不丢失。
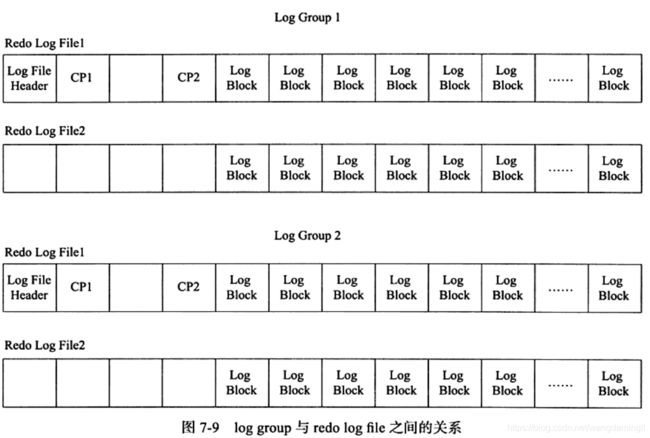
8. 重做日志组
(1) 定义
log group为重做日志组,其中有多个重做日志文件。
(2) 结构
9. 重做日志恢复机制
InnoDB存储引擎在启动时不管上次数据库运行时是否正常关闭,都会尝试进行恢复操作。因为重做日志记录的是物理日志,因此恢复的速度比逻辑日志,如二进制日志,要快很多。
(1) LSN
定义
LSN是Log Sequence Number的缩写,其代表的是日志序列号,单位是字节。在InnoDB存储引擎中,LSN占用8字节,并且单调递增。LSN表示的含义有:
❑重做日志写入的总量
❑checkpoint的位置
❑页的版本
LSN表示事务写入重做日志的字节的总量。例如当前重做日志的LSN为1 000,有一个事务T1写入了100字节的重做日志,那么LSN就变为了1100,若又有事务T2写入了200字节的重做日志,那么LSN就变为了1 300。可见LSN记录的是重做日志的总量,其单位为字节。
查看
mysql> SHOW ENGINE INNODB STATUS\G;
---
LOG
---
Log sequence number 3553029
Log flushed up to 3553029
Pages flushed up to 3553029
Last checkpoint at 3553020
0 pending log flushes, 0 pending chkp writes
1455 log i/o's done, 0.00 log i/o's/second
----------------------
Log sequence number表示当前的LSN,Log flushed up to表示刷新到重做日志文件的LSN,Last checkpoint at表示刷新到磁盘的LSN。
(1) 重做日志恢复
由于checkpoint表示已经刷新到磁盘页上的LSN,因此在恢复过程中仅需恢复checkpoint开始的日志部分。对于图7-12中的例子,当数据库在checkpoint的LSN为10 000时发生宕机,恢复操作仅恢复LSN 10 000~13 000范围内的日志。

10. 重做日志文件记录的内容
InnoDB存储引擎的重做日志是物理日志,因此其恢复速度较之二进制日志恢复快得多。例如对于INSERT操作,其记录的是每个页上的变化。对于下面的表:
//创建表
CREATE TABLE t(a INT,b INT,PRIMARY KEY(a),KEY(b));
//执行sql语句
INSERT INTO t SELECT 1,2;
由于需要对聚集索引页和辅助索引页进行操作,其记录的重做日志大致为:
page(2,3),offset 32,value 1,2 #聚集索引
page(2,4),offset 64,value 2 #辅助索引
可以看到记录的是页的物理修改操作,若插入涉及B+树的split,可能会有更多的页需要记录日志。