1.Python数据库的学习笔记
SQLite是一个软件库,实现了自给自足的、无服务器的、零配置的、事务性的 SQL 数据库引擎。
SQLite是一个增长最快的数据库引擎,这是在普及方面的增长,与它的尺寸大小无关。SQLite 源代码不受版权限制。
下面简单介绍一下有关SQLite库的函数
| 1 | SQLite COUNT 函数 SQLite COUNT 聚集函数是用来计算一个数据库表中的行数。 |
| 2 | SQLite MAX 函数 SQLite MAX 聚合函数允许我们选择某列的最大值。 |
| 3 | SQLite MIN 函数 SQLite MIN 聚合函数允许我们选择某列的最小值。 |
| 4 | SQLite AVG 函数 SQLite AVG 聚合函数计算某列的平均值。 |
| 5 | SQLite SUM 函数 SQLite SUM 聚合函数允许为一个数值列计算总和。 |
| 6 | SQLite RANDOM 函数 SQLite RANDOM 函数返回一个介于 -9223372036854775808 和 +9223372036854775807 之间的伪随机整数。 |
| 7 | SQLite ABS 函数 SQLite ABS 函数返回数值参数的绝对值。 |
| 8 | SQLite UPPER 函数 SQLite UPPER 函数把字符串转换为大写字母。 |
| 9 | SQLite LOWER 函数 SQLite LOWER 函数把字符串转换为小写字母。 |
| 10 | SQLite LENGTH 函数 SQLite LENGTH 函数返回字符串的长度。 |
| 11 | SQLite sqlite_version 函数 SQLite sqlite_version 函数返回 SQLite 库的版本。 |
2.用爬虫获取中国大学排名
代码如下

# -*- coding: utf-8 -*-
"""
Spyder Editor
This is a temporary script file.
"""
import requests
import pandas as pd
import numpy as np
from bs4 import BeautifulSoup
import sqlite3
allUniv=[]
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding = 'utf-8'
return r.text
except:
return ""
def fillUnivList(soup):
data = soup.find_all('tr')
for tr in data:
ltd = tr.find_all('td')
if len(ltd)==0:
continue
singleUniv = []
for td in ltd:
singleUniv.append(td.string)
allUniv.append(singleUniv)
def printUnivList(num):
with open(r'C:\Users\lenovo\Desktop\test.xls','w') as f:
f.write("{1:^2}{2:{0}^10}{3:{0}^4}{4:{0}^8}{5:{0}^6}\n".format((chr(12288)),"排名","学校名称","省市","总分","顶尖成果"))
for i in range(num):
u=allUniv[i]
f.write("{1:^4}{2:{0}^10}{3:{0}^5}{4:{0}^8.1f}{5:{0}^10}\n".format((chr(12288)),u[0],u[1],u[2],eval(u[3]),u[9]))
f.close()
if 1:
print("successful")
else:
print("fail")
def main(num):
url='http://www.zuihaodaxue.cn/zuihaodaxuepaiming2018.html'
html = getHTMLText(url)
soup = BeautifulSoup(html,"html.parser")
fillUnivList(soup)
printUnivList(num)
main(600)
下面是保存结果
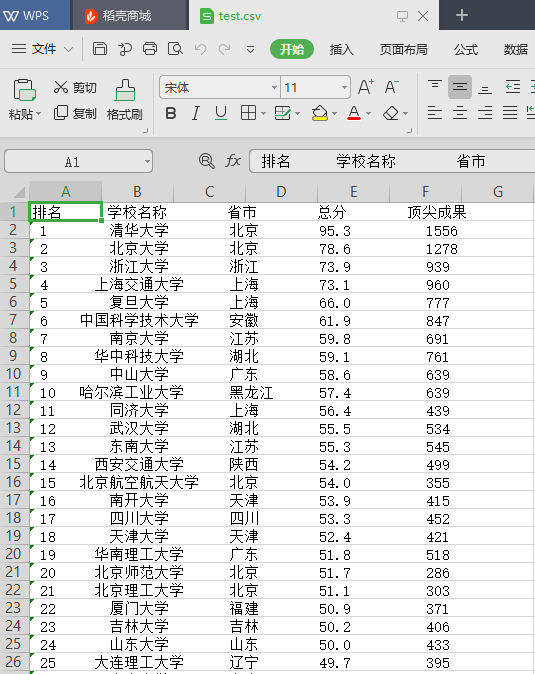
查询我们自己学校的代码为
import requests
from bs4 import BeautifulSoup
allUniv=[]
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding = 'utf-8'
return r.text
except:
return ""
def fillUnivList(soup):
data = soup.find_all('tr')
for tr in data:
ltd = tr.find_all('td')
if len(ltd)==0:
continue
singleUniv = []
for td in ltd:
singleUniv.append(td.string)
allUniv.append(singleUniv)
def printUnivList(num):
a="广东技术师范学院"
print("{1:^4}{2:{0}^8}{3:{0}^6}{4:{0}^6}{5:{0}^8}".format((chr(12288)),"排名","学校名称","省市","总分","顶尖成果"))
for i in range(num):
u=allUniv[i]
if a in u:
print("{1:^4}{2:{0}^10}{3:{0}^5}{4:{0}^8.1f}{5:{0}^10}".format((chr(12288)),u[0],u[1],u[2],eval(u[3]),u[9]))
def main(num):
url='http://www.zuihaodaxue.cn/zuihaodaxuepaiming2018.html'
html = getHTMLText(url)
soup = BeautifulSoup(html,"html.parser")
fillUnivList(soup)
printUnivList(num)
main(600)
然后就能查出我们学校的排名了,结果如下

接着再经过以下代码就可以获得以学生国际化为标准的广东大学排名
def printUnivList(num):
a="广东技术师范学院"
print("{1:^4}{2:{0}^8}{3:{0}^6}{4:{0}^6}{5:{0}^8}".format((chr(12288)),"排名","学校名称","省市","总分","顶尖成果"))
for i in range(num):
u=allUniv[i]
if a in u:
print("{1:^4}{2:{0}^10}{3:{0}^5}{4:{0}^8.1f}{5:{0}^10}".format((chr(12288)),u[0],u[1],u[2],eval(u[3]),u[9]))