python爬虫(三):BeautifulSoup 【6. 实例】
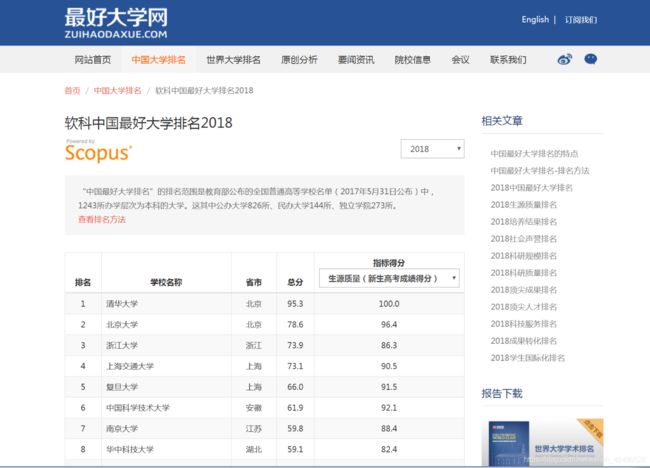
爬取最好大学网的大学排名
需要掌握的其它知识:
(1)列表
list1=[1,2,3],list1.append([3,4])
(2)format用法
.format 比 % 更好用,按位置替换,详细了解可以参考网址
https://blog.csdn.net/u014770372/article/details/76021988
(3)输出的格式
print("{}\t{:^20}\t{}".format("排名","学校名称","总分"))
\t:制表符
^:居中,默认是左对齐
20:宽度,默认是10
(4)find_all('td').string
find_all()方法因为找到了多个td,所以是个列表,不能直接.string,要这样
soup.find_all('td')[0].string
soup.find_all('td')[1].string
输出结果:
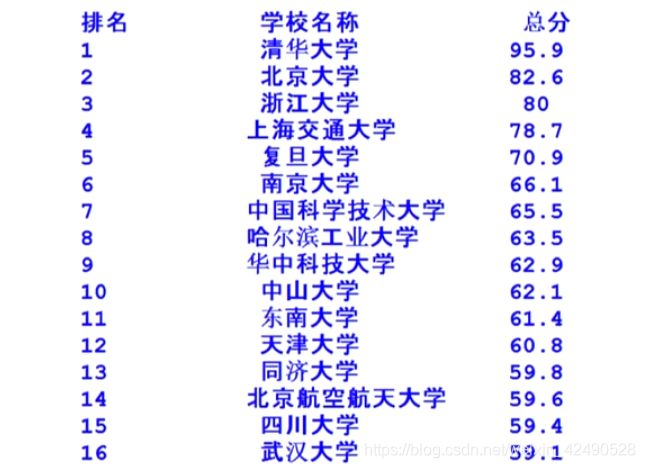
# requests库连接网站取出数据,bs4库html解析
import requests
from bs4 import BeautifulSoup
import bs4
# 获取网页内容
def getHTMLText(url):
try:
r = requests.get(url, timeout = 30)
# 判断网页状态,200为正常
r.raise_for_status()
# 修改编码,apparent_coding是基于文本内容分析出的格式
r.encoding = r.apparent_encoding
return r.text
except:
# 异常则返回一个空字符串
return ""
# 提取网页内容(r.text)到合适的数据结构(列表)
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, 'html.parser')
# 观察发现大学信息都在标签tbody-tr-td中,遍历子节点的标签,找出td
for i in soup.find('tbody').children:
# isinstance是python判断变量类型的函数,bs4.element.Tag是标签,如soup.a
# Tag的常用操作有.name .attrs .string
if isinstance(i, bs4.element.Tag):
# 可简写为tds = i('td')
tds = i('td')
# 取出大学排名、名称、评分,加到ulist列表中
ulist.append([tds[0].string, tds[1].string, tds[2].string])
# 输出信息,num是输出信息的条数
def printUnivList(ulist, num):
# 格式化输出
# 表头
print("{:^10}\t{:^6}\t{:^10}".format("排名", "学校名称", "总分"))
# 表内容
for i in range(num):
u = ulist[i]
print("{:^10}\t{:^6}\t{:^10}".format(u[0], u[1],u[2]))
# 主函数
def main():
# 大学信息放到列表unifo中
uinfo = []
url = 'http://www.zuihaodaxue.com/zuihaodaxuepaiming2018.html'
html = getHTMLText(url)
fillUnivList(uinfo, html)
printUnivList(uinfo, 20)
main()
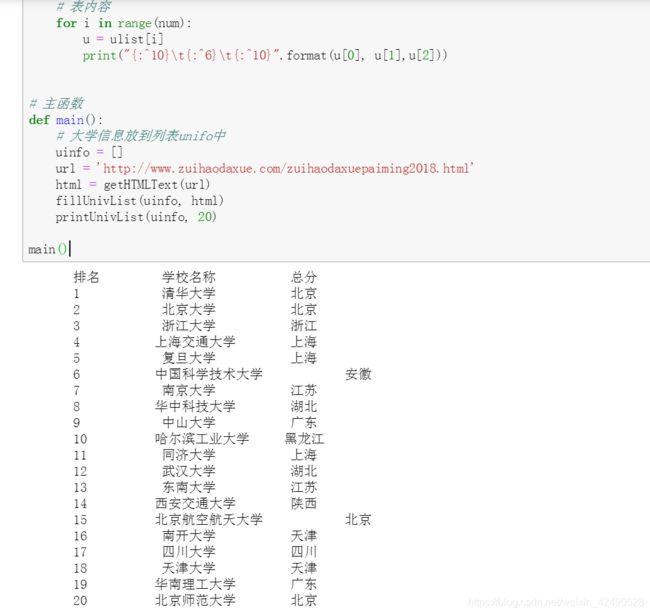
中文输出对齐问题:


def printUnivList(ulist, num):
print("{0}\t{1:{3}^10}\t{2}".format("排名","学校名称","总分", chr(12288)))
for i in range(num):
u=ulist[i]
print("{0}\t{1:{3}^10}\t{2}".format(u[0],u[1],u[2], chr(12288)))
源代码:
# requests库连接网站取出数据,bs4库html解析
import requests
from bs4 import BeautifulSoup
import bs4
# 获取网页内容
def getHTMLText(url):
try:
r = requests.get(url, timeout = 30)
# 判断网页状态,200为正常
r.raise_for_status()
# 修改编码,apparent_coding是基于文本内容分析出的格式
r.encoding = r.apparent_encoding
return r.text
except:
# 异常则返回一个空字符串
return ""
# 提取网页内容(r.text)到合适的数据结构(列表)
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, 'html.parser')
# 观察发现大学信息都在标签tbody-tr-td中,遍历子节点的标签,找出td
for i in soup.find('tbody').children:
# isinstance是python判断变量类型的函数,bs4.element.Tag是标签,如soup.a
# Tag的常用操作有.name .attrs .string
if isinstance(i, bs4.element.Tag):
# 可简写为tds = i('td')
tds = i('td')
# 取出大学排名、名称、评分,加到ulist列表中
ulist.append([tds[0].string, tds[1].string, tds[2].string])
# 输出信息,num是输出信息的条数
def printUnivList(ulist, num):
# 格式化输出
# 表头
print("{:^10}\t{:^6}\t{:^10}".format("排名", "学校名称", "总分"))
# 表内容
for i in range(num):
u = ulist[i]
print("{:^10}\t{:^6}\t{:^10}".format(u[0], u[1],u[2]))
# 主函数
def main():
# 大学信息放到列表unifo中
uinfo = []
url = 'http://www.zuihaodaxue.com/zuihaodaxuepaiming2018.html'
html = getHTMLText(url)
fillUnivList(uinfo, html)
printUnivList(uinfo, 20)
main()