爬虫新手入门实战项目(爬取笔趣阁小说并下载)
网络爬虫是什么?简单来说就是一个脚本,他能帮助我们自动采集我们需要的资源。
-
爬虫步骤
-
获取数据
# 导入模块
import requests
import re
url = 'https://www.biqudu.com/43_43821/'
模拟头部信息
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36"}
用浏览器打开网页(我用的是谷歌浏览器),按 F12 打开检查元素。
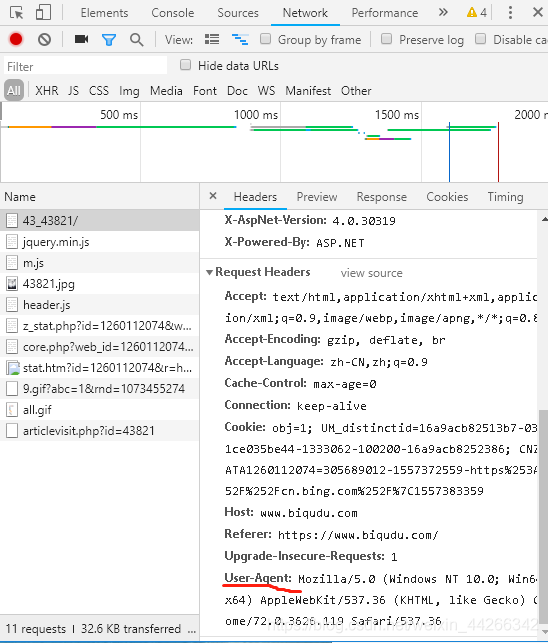
将 User-Agent 复制下来。
模拟浏览器发送 http 请求
response = requests.get(url, headers=headers, verify=False)
因为这里是 https 请求,如果不加 verify=False 会报错。
编码方式(不添加编码,看到的网页会有乱码)
response.encoding = 'utf-8'
目标网页源代码
html = response.text
- 分析数据加载流程(使用正则表达式)
def multiple_replace(text, adict):
rx = re.compile('|'.join(map(re.escape, adict)))
def one_xlat(match):
return adict[match.group(0)]
return rx.sub(one_xlat, text)
提取小说名字
# 因为列表中只有一个元素,所以是 [0]
title = re.findall(r'', html)[0]
# print(title)
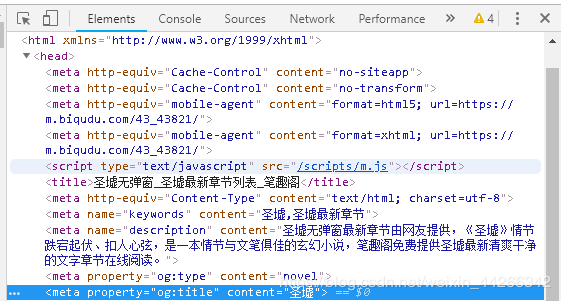
如图,一般情况下小说标题都在 head 的 meter 里面。
获取每一章节的信息
dl = re.findall(r'《圣墟》正文 .*?', html, re.S)[0] # re.S 匹配不可见字符
chapter_info_list = re.findall(r'href="(.*?)">(.*?)<', dl)
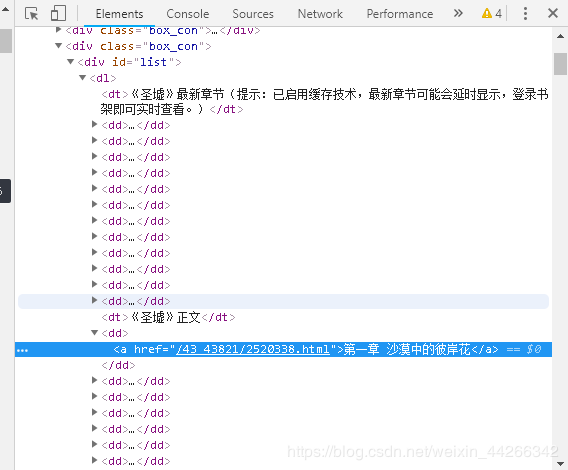
要以唯一字段开头结尾
《圣墟》正文 .*?
这是唯一字段ka,如果不是唯一字段,会导致匹配不准确。
- 下载数据
循环每一个章节并下载
for chapter_info in chapter_info_list:
# chapter_title = chapter_info[0]
# chapter_url = chapter_info[1]
chapter_url, chapter_title = chapter_info
# 不用加号拼接,会增加新的字符串对象,增加内存
chapter_url = "https://www.biqudu.com%s" % chapter_url
# 下载章节内容
chapter_response = requests.get(chapter_url, headers=headers, verify=False)
chapter_response.encoding = 'utf-8'
chapter_html = chapter_response.text # 网页源码
# 提取章节内容
chapter_content = re.findall(r'(.*?)',
chapter_html, re.S)[0]
- 清洗数据
adict = {'
': '', '\t': '', ' ': '\n', ';<="="/js/"></>': ''}
chapter_content = multiple_replace(chapter_content, adict)
5.保存数据
with open('%s.txt' % title, 'a', encoding='utf-8') as f:
f.write(chapter_title)
f.write(chapter_content)
f.write('\n')
print(chapter_url)