强化学习笔记-百度AI Studio
强化学习7日打卡营-世界冠军带你从零实践
- 课程简介
- 什么是强化学习
- Q-learning基础算法
- 强化学习算法DQN
- 强化学习算法Policy-Gradient
- 强化学习DDPG算法
- 总结
课程简介
最近正在学强化学习的知识,虽然自己之前也有听过别的一些课程,但是基础还不太牢固,所以选择了报名百度AI Studio的强化学习打卡营,给我带来了一些小惊喜,总体来说课程的框架逻辑很清晰,为了让没有基础的同学也能听懂,并没有将特别高深的数学推导,老师用了比较简单的逻辑梳理的形式进行了课程的讲解,通过这种方式反而让我这个了解过一些推导的人思路更加清晰了,高度归纳的课程在短短5天的时间就从普通的Q-learning讲到了DDPG,这大大缩短了一些想要自学的同学了解强化学习框架的时间,而且代码方面老师也搭好了,可以让学院快速的实现相关代码,课程还是比较良心了,希望在国内可以看到更多这样的课程,推动我国AI领域的发展。话不多说,接下来就我自己的学习历程做了一些简单的笔记,希望可以帮到大家。
什么是强化学习
首先要明白,强化学习对标的不是ML和DL,而是监督学习和非监督学习,也就是说它是一种学习的方式。

强化学习与监督学习的最大区别在于,强化学习注重怎么做的问题,而监督学习注重是什么的问题。
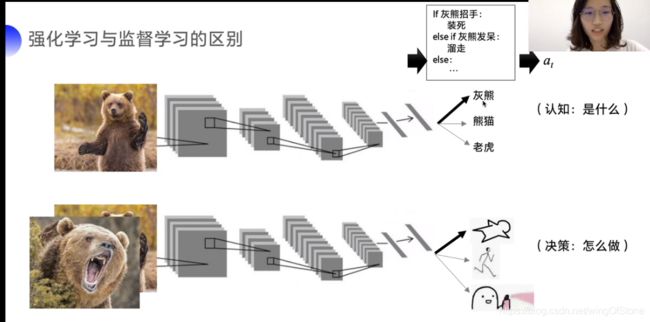
监督学习不能直接做动作,而是根据模型预测结果,结合人的先验知识去做动作,而通过强化学习会直接告诉你在什么样的状态下做什么决策是最好的。
基于强化学习的算法主要分两大类,即model-based和model-free的,这里课程重点讲了基于model-free的。
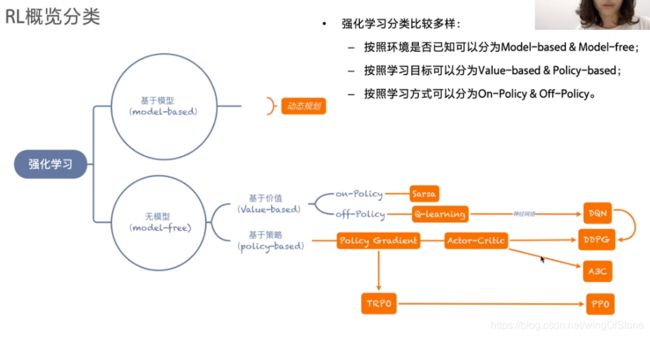
在model-free的算法之中,又分values-based和policy-based,其中values-based的意思是说,会对每种行为的效用做出一个评估,那么在决策的时候就会选择效用最大的那个行为,而policy-based的预测是一个概率分布,也就是执行每种动作的概率。

在了解算法之前我们需要了解一个概念,MDP(马尔科夫决策过程),这个概念是强化学习实现的基础,它的大意就是说,我们要训练的智能体是通过和环境互动得到进化的,而和环境互动有几个要素,即S(state), A(action), P(probabilty), R(reward),首先智能体在每一步的学习的探索中总有自己所处的状态S,那么智能体会结合S和P(这个P是在学习中不断更新的)做出动作A,同时环境根据A给到智能体奖励R。
那么这个R是怎么定义的呢?我们可以把它定义为,做了这个决策以后的,每一步的所有回报都加起来,但是这样会产生一些问题,首先,未来是不是和现在同等重要呢,如果我要炒股,我把10年后的收益的重要性和一个月内收益的重要性等同,那这样学习的话可能会遇到模型允许短期没有收益的情况,这可能不是我们想要的,其次,未来到底有多少步才算终止,未来到底是不是可以估计的,这都要打个问号,由此就引入了折扣因子。
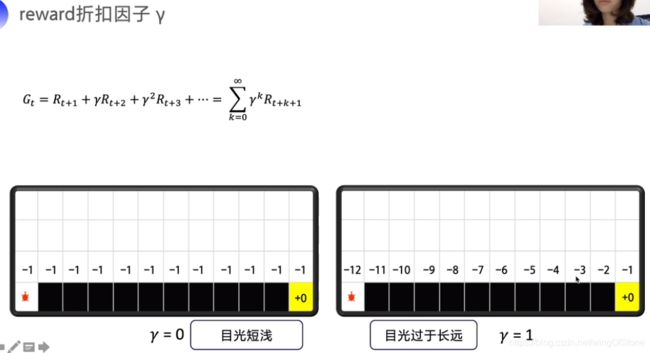
通过这个折扣因子,我们就可以通过调节γ来调整未来回报的重要度了。
Q-learning基础算法
有了上面的这个基础概念,我们下面来看一下强化学习一个比较简单的算法Q-learning,它的意思是说用一个Q函数Q(s,a)来预测未来的回报,s和a的含义上面也都讲过了,就是当下的状态和动作,那么最后肯定会选择Q值最大的动作来做。那怎么用Q值来替代上面的总回报Gt呢,我们先看下面这个推导。

通过上图的推导,Gt的表示方式就大大的简化了,那么通过Q值来表示就是下图。
![]()
上图的意思就是说,只需要知道当期的回报和利用下一期的状态和动作估算的Q值就可以更新我们的Q函数了。 为了控制每次Q的更新幅度,又引入了α因子,也是属于(0,1)之间的,相当于学习率的参数。Q-learning算法的流程如下图所示。

最简单的Q-learning算法就是Q表格法了,

Q表格行索引就是state,列索引就是action,Q表格算法初始化的时候会新建一个空的Q表格,那么对应的表格中的每个值也就是对于未来回报的预期,智能体通过不断的探索与学习会更新Q表格中的值,智能体在做行动的时候会查询Q表格,从而知道每个state下做每个action的回报,但一开始的时候Q表格肯定是不完善的,所以一开始的时候根据Q表格去做动作相当于探索的过程,等到Q表格更新到一定程度,根据Q表格就可以做出较优的决策了。
强化学习算法DQN
上一节我们讲了Q-learning算法的基础和Q表格法,但Q表格法不足以解决所有问题,尤其是状态空间很大很大或者说状态空间是连续的情况下,我们是没有办法把所有的状态下对应的回报列出来的,于是科学家就想要说用神经网络来替代Q表格作为Q-learning算法的Q函数。

在神经网络的设计中,一般采用输入一个s预测多个a的模式,这样效率会比较高。实际上DQN整个算法的流程相对于Q表格法来说没有太大的改变,核心还是在于把Q表格换成了神经网络,那么针对DQN算法的效果优化,科学家提出了两个非常重要的技巧,就是经验回放和固定Q目标。
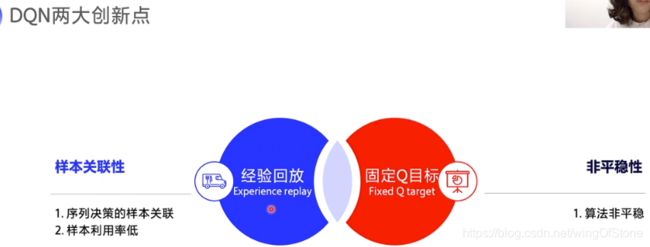
经验回放的意思就是说,在模型和环境互动的过程中,每一条数据就会被保存下来,放到一个经验池里面,在模型训练的时候还会把他们取出来(打乱)训练,这么做的好处就是可以打破样本之间的相关性以及提高数据的利用率。
固定Q目标的意思就是说,我们更新Q函数的公式里面,对于未来的预测实际上是Q函数的预测值,那我们在更新Q函数的过程中,我们的预测标准也会不断的变化,也就是再给你一个同样的state你的预测值却跟原来不同了,这样会让神经网络感到困惑,就像射箭的时候靶子一直在移动,那么固定Q目标的方法就是,在初始化的时候初始化两个神经网络,一个是Q_eval,一个是Q_target,Q_eval就是负责学习与更新的Q函数,Q_target只用来预测未来回报而不训练自己(更新通过参数赋值),初始化的时候两个神经网络是一摸一样的,Q_target会在每N轮训练结束的时候把Q_eval的参数赋值给自己,这样的话未来回报的预测标准就不会一直变,模型就更加容易收敛。
强化学习算法Policy-Gradient
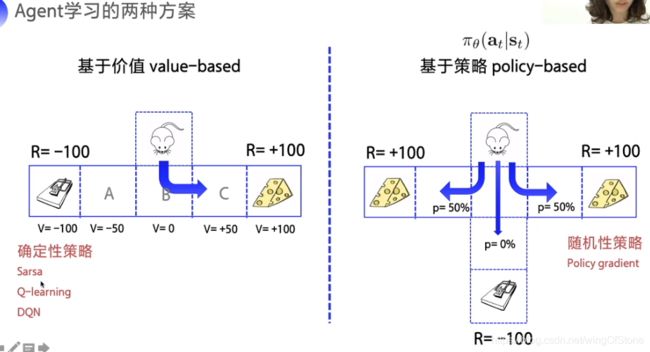
policy-gradient算法是属于policy-based类型的,它跟Q-learning这种的有什么区别呢?我们可以看一下下图。
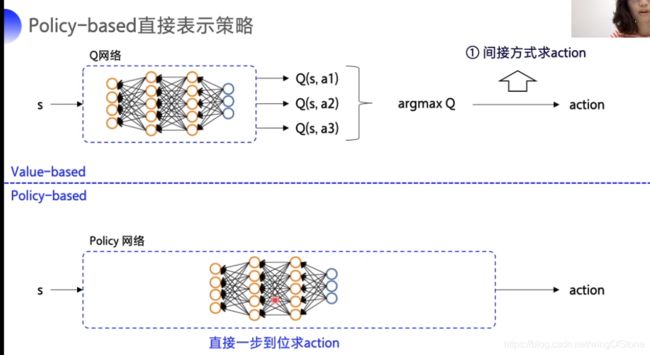
关于这个区别其实在上面的文章中也提过,就是说Q-learning这样的value-based的算法会对每个动作估计一个回报,然后选择回报最大的动作,而policy-based的算法输出的是动作的概率分布,也就是每个动作执行的概率。
在神经网络的构造中也是以softmax为激活函数直接吐出每个动作的概率。
policy-gradient的核心思想也是让回报最大,体现在它的算法里有一个“轨迹”的概念,就是做出一个动作后所有可能的一系列状态和动作的序列就是一条轨迹,那么回报最大也就是每条轨迹的回报最大。
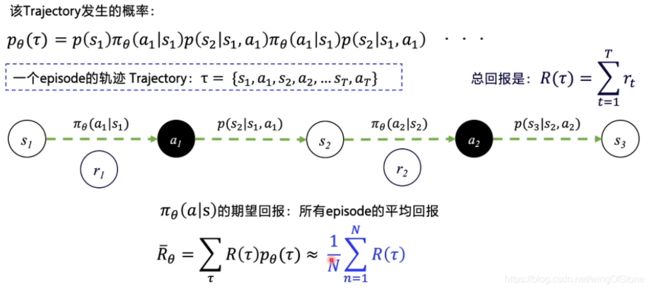
每条轨迹发生的概率可以用Pθ(τ)来表示,那么所有回报的期望就是Pθ(τ)乘以该轨迹的回报R(τ),但实际上我们不可能模拟出所有轨迹,所以就取模拟N次的平均值作为我们的期望回报。
在policy-gradient的方式里,就是不断更新策略使得回报最大化,那么怎么更新呢,学过神经网络的同学应该都知道梯度下降这种算法,在policy-gradient算法里面就是梯度上升,通过不断的更新策略θ的参数以提高回报,这个梯度就是期望回报的梯度。这个梯度的推导过程课程里没有讲述,所以大家先暂时记住这个式子。
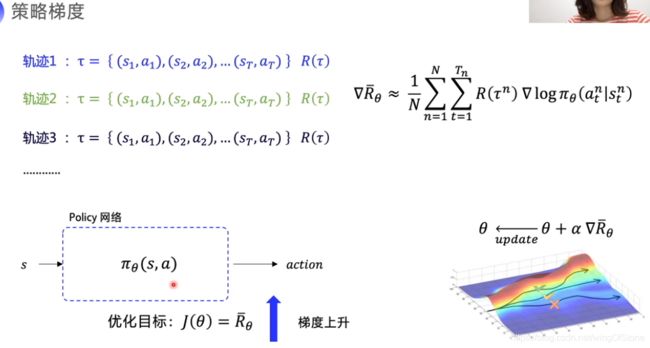
有了梯度我们就可以得到损失函数了,如下图。
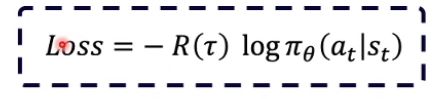
有没有感觉很熟悉的样子,没错,就是那个常用的交叉熵。
policy-gradient算法的流程图如下所示。

圈圈圈住的那一行就是我们的更新公式,其中γ依然还是折扣因子,α同样是控制更新速度的一个变量,和DQN算法中的一样。
那么policy-gradient算法也是可以处理连续动作的,上图。

可以看到说如果是离散动作的话就输出每种动作的概率,如果是离散动作的话会直接输出一个常数的值出来,这个值可以是机械手臂弯曲的角度,也可以是通电的电压等。
强化学习DDPG算法
DQN算法是一个非常好用的算法,但也有其缺点,那就是DQN算法不能处理连续型的动作,因为没办法把每个动作的回报都评估一遍,DDPG算法可以说是DQN算法的升级版,可以有效解决这个问题。
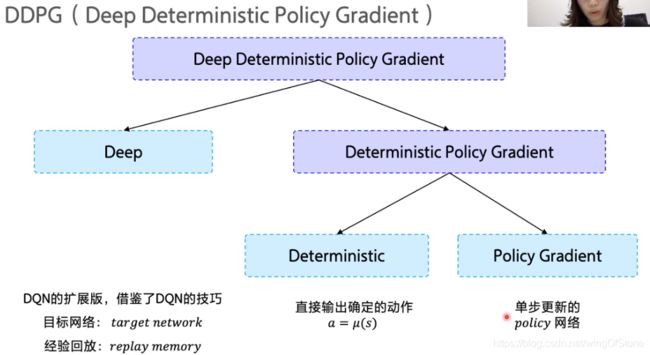
它既包含了DQN算法的思想,也借鉴了policy gradient算法的优点,为了把这两种算法融合起来,剔除了一种模式叫做Actor-Critic模式。

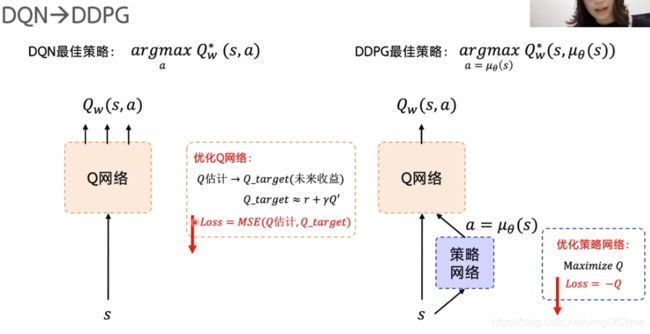
在Actor-Critic结构里面,Q函数的部分主要用作评估动作好坏,故是Critic,而策略网络的部分则用来输出action,即Actor。由于有环境反馈的存在,Critic会评价的越来越准,反馈给Actor,Actor更新自己迎合critic给自己打的分尽量的高,这种模式的学习与更新如下图所示。
两种网络的损失函数如下图所示。
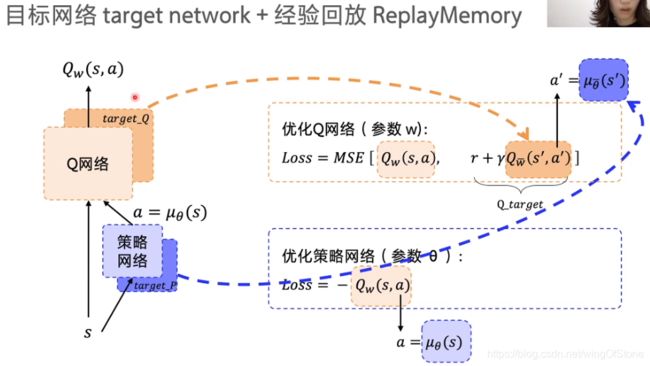
可以看出其实在损失函数这部分跟之前讲的DQN和policy-gradient算法差别不大,这种结合的方式也非常的巧妙,DDPG是一个非常强大的算法,在实际工作中运用也很广泛,关于DDPG的核心思想就讲到这里,下面附上DDPG算法的总结图。
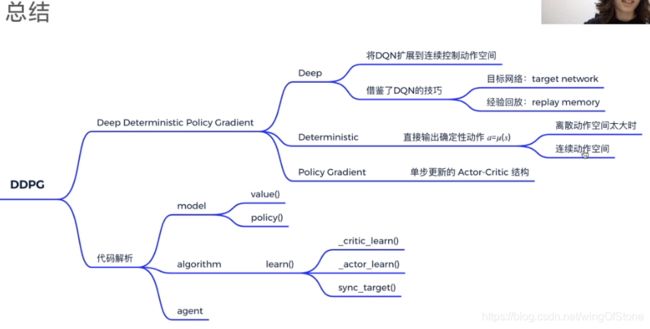
总结
本文是基于百度AI Studio推出的免费课程进行的总结,说实话这个课程还是比较良心的,我也从中获得了不少收获。写本文的目的对几种重要的算法的思想做了一个总结,主要是概念层面的,并不涉及到数学推导,希望读者能够通过阅读本文对几种常见的强化学习算法有一个了解,由于作者是第一次写这种博文,可能有很多不足之处,如果大家能够通过阅读我的文章有一点点的收获,我也就知足了。
好了,就到这里,有缘再见!