jvm(8) -- Serial收集器、ParNew收集器、Parallel Scavenge收集器
文章目录
- 1.Serial收集器
- ①特点
- ②、应用场景
- ③、设置参数
- ④Stop TheWorld说明
- 2.ParNew收集器
- ①特点
- ②应用场景
- ③设置参数
- ④为什么只有ParNew能与CMS收集器配合
- 3.Parallel Scavenge收集器
- ①特点
- ②应用场景
- ③设置参数
- ④吞吐量与收集器关注点说明
- A)、吞吐量(Throughput)
- B)、垃圾收集器期望的目标(关注点)
- 1)、停顿时间
- 2)、吞吐量
- 3)、覆盖区(Footprint)
查询JDK默认GC: java -XX:+PrintCommandLineFlags -version

摘自:
https://www.jianshu.com/p/29460c44c664
1.Serial收集器
推荐文章:https://www.breakyizhan.com/javamianshiti/2850.html
Serial,是单线程执行垃圾回收的。当需要执行垃圾回收时,程序会暂停一切手上的工作,然后单线程执行垃圾回收。
因为新生代的特点是对象存活率低,所以收集算法用的是复制算法,把新生代存活对象复制到老年代,复制的内容不多,性能较好。
Serial(串行)垃圾收集器是最基本、发展历史最悠久的收集器;
JDK1.3.1前是HotSpot新生代收集的唯一选择;
①特点
针对新生代;
采用复制算法;
单线程收集;
进行垃圾收集时,必须暂停所有工作线程,直到完成;
即会"Stop The World";
Serial/Serial Old组合收集器运行示意图如下:
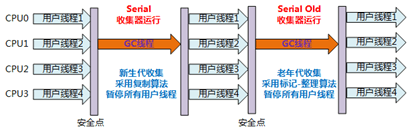
②、应用场景
依然是HotSpot在Client模式下默认的新生代收集器;
也有优于其他收集器的地方:
简单高效(与其他收集器的单线程相比);
对于限定单个CPU的环境来说,Serial收集器没有线程交互(切换)开销,可以获得最高的单线程收集效率;
在用户的桌面应用场景中,可用内存一般不大(几十M至一两百M),可以在较短时间内完成垃圾收集(几十MS至一百多MS),只要不频繁发生,这是可以接受的
③、设置参数
“-XX:+UseSerialGC”:添加该参数来显式的使用串行垃圾收集器;
④Stop TheWorld说明
JVM在后台自动发起和自动完成的,在用户不可见的情况下,把用户正常的工作线程全部停掉,即GC停顿;
会带给用户不良的体验;
从JDK1.3到现在,从Serial收集器-》Parallel收集器-》CMS-》G1,用户线程停顿时间不断缩短,但仍然无法完全消除;
单线程地好处就是减少上下文切换,减少系统资源的开销。但这种方式的缺点也很明显,在GC的过程中,会暂停程序的执行。若GC不是频繁发生,这或许是一个不错的选择,否则将会影响程序的执行性能。 对于新生代来说,区域比较小,停顿时间短,所以比较使用。
2.ParNew收集器
引文章链接:https://www.jianshu.com/p/29460c44c664
ParNew收集器是Serial收集器新生代的多线程实现,注意在进行垃圾回收的时候依然会stop the world,只是相比较Serial收集器而言它会运行多条进程进行垃圾回收。
ParNew收集器在单CPU的环境中绝对不会有比Serial收集器更好的效果,甚至由于存在线程交互的开销,该收集器在通过超线程技术实现的两个CPU的环境中都不能百分之百的保证能超越Serial收集器。当然,随着可以使用的CPU的数量增加,它对于GC时系统资源的利用还是很有好处的。它默认开启的收集线程数与CPU的数量相同,在CPU非常多(譬如32个,现在CPU动辄4核加超线程,服务器超过32个逻辑CPU的情况越来越多了)的环境下,可以使用-XX:ParallelGCThreads参数来限制垃圾收集的线程数。
-UseParNewGC: 打开此开关后,使用ParNew + Serial Old的收集器组合进行内存回收,这样新生代使用并行收集器,老年代使用串行收集器。
引文章链接:https://www.breakyizhan.com/javamianshiti/2852.html
ParNew垃圾收集器是Serial收集器的多线程版本。
①特点
除了多线程外,其余的行为、特点和Serial收集器一样;
如Serial收集器可用控制参数、收集算法、Stop The World、内存分配规则、回收策略等;
两个收集器共用了不少代码;
ParNew/Serial Old组合收集器运行示意图如下:

②应用场景
在Server模式下,ParNew收集器是一个非常重要的收集器,因为除Serial外,目前只有它能与CMS收集器配合工作;
但在单个CPU环境中,不会比Serail收集器有更好的效果,因为存在线程交互开销。
③设置参数
“-XX:+UseConcMarkSweepGC”:指定使用CMS后,会默认使用ParNew作为新生代收集器;
“-XX:+UseParNewGC”:强制指定使用ParNew;
“-XX:ParallelGCThreads”:指定垃圾收集的线程数量,ParNew默认开启的收集线程与CPU的数量相同;
④为什么只有ParNew能与CMS收集器配合
CMS是HotSpot在JDK1.5推出的第一款真正意义上的并发(Concurrent)收集器,第一次实现了让垃圾收集线程与用户线程(基本上)同时工作;
CMS作为老年代收集器,但却无法与JDK1.4已经存在的新生代收集器Parallel Scavenge配合工作;
因为Parallel Scavenge(以及G1)都没有使用传统的GC收集器代码框架,而另外独立实现;而其余几种收集器则共用了部分的框架代码;
3.Parallel Scavenge收集器

文章链接:https://www.jianshu.com/p/29460c44c664
Parallel是采用复制算法的多线程新生代垃圾回收器,似乎和ParNew收集器有很多的相似的地方。但是Parallel Scanvenge收集器的一个特点是它所关注的目标是吞吐量(Throughput)。所谓吞吐量就是CPU用于运行用户代码的时间与CPU总消耗时间的比值,即吞吐量=运行用户代码时间 / (运行用户代码时间 + 垃圾收集时间)。停顿时间越短就越适合需要与用户交互的程序,良好的响应速度能够提升用户的体验;而高吞吐量则可以最高效率地利用CPU时间,尽快地完成程序的运算任务,主要适合在后台运算而不需要太多交互的任务。
Parallel Old收集器是Parallel Scavenge收集器的老年代版本,采用多线程和”标记-整理”算法。这个收集器是在jdk1.6中才开始提供的,在此之前,新生代的Parallel Scavenge收集器一直处于比较尴尬的状态。原因是如果新生代Parallel Scavenge收集器,那么老年代除了Serial Old(PS MarkSweep)收集器外别无选择。由于单线程的老年代Serial Old收集器在服务端应用性能上的”拖累“,即使使用了Parallel Scavenge收集器也未必能在整体应用上获得吞吐量最大化的效果,又因为老年代收集中无法充分利用服务器多CPU的处理能力,在老年代很大而且硬件比较高级的环境中,这种组合的吞吐量甚至还不一定有ParNew加CMS的组合”给力“。直到Parallel Old收集器出现后,”吞吐量优先“收集器终于有了比较名副其实的应用,在注重吞吐量及CPU资源敏感的场合,都可以优先考虑Parallel Scavenge加Parallel Old收集器。
-UseParallelGC: 虚拟机运行在Server模式下的默认值,打开此开关后,使用Parallel Scavenge + Serial Old的收集器组合进行内存回收。-UseParallelOldGC: 打开此开关后,使用Parallel Scavenge + Parallel Old的收集器组合进行垃圾回收
文章链接:https://www.breakyizhan.com/javamianshiti/2853.html
Parallel Scavenge垃圾收集器因为与吞吐量关系密切,也称为吞吐量收集器(Throughput Collector)。
①特点
(A)、有一些特点与ParNew收集器相似
新生代收集器;
采用复制算法;
多线程收集;
(B)、主要特点是:它的关注点与其他收集器不同
CMS等收集器的关注点是尽可能地缩短垃圾收集时用户线程的停顿时间;
而Parallel Scavenge收集器的目标则是达一个可控制的吞吐量(Throughput);
关于吞吐量与收集器关注点说明详见本节后面;
②应用场景
高吞吐量为目标,即减少垃圾收集时间,让用户代码获得更长的运行时间;
当应用程序运行在具有多个CPU上,对暂停时间没有特别高的要求时,即程序主要在后台进行计算,而不需要与用户进行太多交互;
例如,那些执行批量处理、订单处理、工资支付、科学计算的应用程序;
③设置参数
Parallel Scavenge收集器提供两个参数用于精确控制吞吐量:
(A)、"-XX:MaxGCPauseMillis"
控制最大垃圾收集停顿时间,大于0的毫秒数;
MaxGCPauseMillis设置得稍小,停顿时间可能会缩短,但也可能会使得吞吐量下降;
因为可能导致垃圾收集发生得更频繁;
(B)、"-XX:GCTimeRatio"
设置垃圾收集时间占总时间的比率,0 GCTimeRatio相当于设置吞吐量大小; 垃圾收集执行时间占应用程序执行时间的比例的计算方法是: 1 / (1 + n) 例如,选项-XX:GCTimeRatio=19,设置了垃圾收集时间占总时间的5%–1/(1+19); 默认值是1%–1/(1+99),即n=99; 垃圾收集所花费的时间是年轻一代和老年代收集的总时间; 如果没有满足吞吐量目标,则增加代的内存大小以尽量增加用户程序运行的时间; 此外,还有一个值得关注的参数: (C)、"-XX:+UseAdptiveSizePolicy" 开启这个参数后,就不用手工指定一些细节参数,如: 新生代的大小(-Xmn)、Eden与Survivor区的比例(-XX:SurvivorRation)、晋升老年代的对象年龄(-XX:PretenureSizeThreshold)等; JVM会根据当前系统运行情况收集性能监控信息,动态调整这些参数,以提供最合适的停顿时间或最大的吞吐量,这种调节方式称为GC自适应的调节策略(GC Ergonomiscs); 这是一种值得推荐的方式: (1)、只需设置好内存数据大小(如"-Xmx"设置最大堆); (2)、然后使用"-XX:MaxGCPauseMillis"或"-XX:GCTimeRatio"给JVM设置一个优化目标; (3)、那些具体细节参数的调节就由JVM自适应完成; 这也是Parallel Scavenge收集器与ParNew收集器一个重要区别; 更多目标调优和GC自适应的调节策略说明请参考: 《Memory Management in the Java HotSpot™ Virtual Machine》 5节 Ergonomics – Automatic Selections and Behavior Tuning:http://www.oracle.com/technetwork/java/javase/tech/memorymanagement-whitepaper-1-150020.pdf 《Java Platform, Standard Edition HotSpot Virtual Machine Garbage Collection Tuning Guide》 第2节 Ergonomics:http://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/ergonomics.html#ergonomics CPU用于运行用户代码的时间与CPU总消耗时间的比值; 即吞吐量=运行用户代码时间/(运行用户代码时间+垃圾收集时间); 高吞吐量即减少垃圾收集时间,让用户代码获得更长的运行时间; 停顿时间越短就适合需要与用户交互的程序; 良好的响应速度能提升用户体验; 高吞吐量则可以高效率地利用CPU时间,尽快完成运算的任务; 主要适合在后台计算而不需要太多交互的任务; 在达到前面两个目标的情况下,尽量减少堆的内存空间; 可以获得更好的空间局部性; 完④吞吐量与收集器关注点说明
A)、吞吐量(Throughput)
B)、垃圾收集器期望的目标(关注点)
1)、停顿时间
2)、吞吐量
3)、覆盖区(Footprint)