jdk8
1.Lambda表达式
Lambda 允许把函数作为一个方法的参数(函数作为参数传递进方法中)。
(parameters) -> expression
或
(parameters) ->{ statements; }
可选类型声明:不需要声明参数类型,编译器可以统一识别参数值。
可选的参数圆括号:一个参数无需定义圆括号,但多个参数需要定义圆括号。
可选的大括号:如果主体包含了一个语句,就不需要使用大括号。
可选的返回关键字:如果主体只有一个表达式返回值则编译器会自动返回值,大括号需要指定明表达式返回了一个数值。
例子
(int a, int b) -> { return a + b; }
() -> System.out.println("Hello World");
(String s) -> { System.out.println(s); }
() -> 42
() -> { return 3.1415 };
注意:只有在需要函数式接口的时候才可以传递Lambda
1.1 函数式接口
函数式接口是只包含一个抽象方法声明的接口
java.lang.Runnable 就是一种函数式接口,在 Runnable 接口中只声明了一个方法 void run(),相似地,ActionListener 接口也是一种函数式接口,我们使用匿名内部类来实例化函数式接口的对象,有了 Lambda 表达式,这一方式可以得到简化。
1.2 方法引用
Java 8中方法也是一种对象,可以By名字来引用。不过方法引用的唯一用途是支持Lambda的简写,使用方法名称来表示Lambda。不能通过方法引用来获得诸如方法签名的相关信息。
方法引用的分类
方法引用分为4类,常用的是前两种。方法引用也受到访问控制权限的限制,可以通过在引用位置是否能够调用被引用方法来判断。具体分类信息如下:
引用静态方法
ContainingClass::staticMethodName
例子: String::valueOf,对应的Lambda:(s) -> String.valueOf(s)
比较容易理解,和静态方法调用相比,只是把.换为::
引用特定对象的实例方法
containingObject::instanceMethodName
例子: x::toString,对应的Lambda:() -> this.toString()
与引用静态方法相比,都换为实例的而已
引用特定类型的任意对象的实例方法
ContainingType::methodName
例子: String::toString,对应的Lambda:(s) -> s.toString()
太难以理解了。难以理解的东西,也难以维护。建议还是不要用该种方法引用。
实例方法要通过对象来调用,方法引用对应Lambda,Lambda的第一个参数会成为调用实例方法的对象。
引用构造函数
lassName::new
例子: String::new,对应的Lambda:() -> new String()
构造函数本质上是静态方法,只是方法名字比较特殊。
2.流
Stream 不是集合元素,它不是数据结构并不保存数据,它是有关算法和计算的,它更像一个高级版本的 Iterator。原始版本的 Iterator,用户只能显式地一个一个遍历元素并对其执行某些操作;高级版本的 Stream,用户只要给出需要对其包含的元素执行什么操作,比如 “过滤掉长度大于 10 的字符串”、“获取每个字符串的首字母”等,Stream 会隐式地在内部进行遍历,做出相应的数据转换。
Stream 就如同一个迭代器(Iterator),单向,不可往复,数据只能遍历一次,遍历过一次后即用尽了,就好比流水从面前流过,一去不复返。
而和迭代器又不同的是,Stream 可以并行化操作,迭代器只能命令式地、串行化操作。顾名思义,当使用串行方式去遍历时,每个 item 读完后再读下一个 item。而使用并行去遍历时,数据会被分成多个段,其中每一个都在不同的线程中处理,然后将结果一起输出。Stream 的并行操作依赖于 Java7 中引入的 Fork/Join 框架(JSR166y)来拆分任务和加速处理过程。Java 的并行 API 演变历程基本如下:
1.0-1.4 中的 java.lang.Thread
5.0 中的 java.util.concurrent
6.0 中的 Phasers 等
7.0 中的 Fork/Join 框架
8.0 中的 Lambda
2.1 流的构造和转换
// 1. Individual values
Stream stream = Stream.of("a", "b", "c");
// 2. Arrays
String [] strArray = new String[] {"a", "b", "c"};
stream = Stream.of(strArray);
stream = Arrays.stream(strArray);
// 3. Collections
List list = Arrays.asList(strArray);
stream = list.stream();
需要注意的是,对于基本数值型,目前有三种对应的包装类型 Stream:
IntStream、LongStream、DoubleStream。当然我们也可以用 Stream、Stream >、Stream,但是 boxing 和 unboxing 会很耗时,所以特别为这三种基本数值型提供了对应的 Stream。
数值流的构造
IntStream.of(new int[]{1, 2, 3}).forEach(System.out::println);
IntStream.range(1, 3).forEach(System.out::println);
IntStream.rangeClosed(1, 3).forEach(System.out::println);
流转换为其它数据结构
// 1. Array
String[] strArray1 = stream.toArray(String[]::new);
// 2. Collection
List list1 = stream.collect(Collectors.toList());
List list2 = stream.collect(Collectors.toCollection(ArrayList::new));
Set set1 = stream.collect(Collectors.toSet());
Stack stack1 = stream.collect(Collectors.toCollection(Stack::new));
// 3. String
String str = stream.collect(Collectors.joining()).toString();
2.2 流的操作
当把一个数据结构包装成 Stream 后,就要开始对里面的元素进行各类操作了。常见的操作可以归类如下。
Intermediate:
map (mapToInt, flatMap 等)、 filter、 distinct、 sorted、 peek、 limit、 skip、 parallel、 sequential、 unordered
Terminal:
forEach、 forEachOrdered、 toArray、 reduce、 collect、 min、 max、 count、 anyMatch、 allMatch、 noneMatch、 findFirst、 findAny、 iterator
Short-circuiting:
anyMatch、 allMatch、 noneMatch、 findFirst、 findAny、 limit
map/flatMap用法
它的作用就是把 input Stream 的每一个元素,映射成 output Stream 的另外一个元素。
转换大写:
List<String> output = wordList.stream().
map(String::toUpperCase).
collect(Collectors.toList());
平方数
List<Integer> nums = Arrays.asList(1, 2, 3, 4);
List<Integer> squareNums = nums.stream().
map(n -> n * n).
collect(Collectors.toList());
map 生成的是个 1:1 映射,每个输入元素,都按照规则转换成为另外一个元素。还有一些场景,是一对多映射关系的,这时需要 flatMap。
一对多
Stream<List<Integer>> inputStream = Stream.of(
Arrays.asList(1),
Arrays.asList(2, 3),
Arrays.asList(4, 5, 6)
);
Stream<Integer> outputStream = inputStream.
flatMap((childList) -> childList.stream());
filter
filter 对原始 Stream 进行某项测试,通过测试的元素被留下来生成一个新 Stream。
Integer[] sixNums = {1, 2, 3, 4, 5, 6};
Integer[] evens =
Stream.of(sixNums).filter(n -> n%2 == 0).toArray(Integer[]::new);
经过条件“被 2 整除”的 filter,剩下的数字为 {2, 4, 6}。
forEach
forEach 方法接收一个 Lambda 表达式,然后在 Stream 的每一个元素上执行该表达式。
// Java 8
roster.stream()
.filter(p -> p.getGender() == Person.Sex.MALE)
.forEach(p -> System.out.println(p.getName()));
// Pre-Java 8
for (Person p : roster) {
if (p.getGender() == Person.Sex.MALE) {
System.out.println(p.getName());
}
}
对一个人员集合遍历,找出男性并打印姓名。可以看出来,forEach 是为 Lambda 而设计的,保持了最紧凑的风格。而且 Lambda 表达式本身是可以重用的,非常方便。当需要为多核系统优化时,可以 parallelStream().forEach(),只是此时原有元素的次序没法保证,并行的情况下将改变串行时操作的行为,此时 forEach 本身的实现不需要调整,而 Java8 以前的 for 循环 code 可能需要加入额外的多线程逻辑。
另外一点需要注意,forEach 是 terminal 操作,因此它执行后,Stream 的元素就被”消费”掉了,你无法对一个 Stream 进行两次 terminal 运算。下面的代码是错误的:
stream.forEach(element -> doOneThing(element));
stream.forEach(element -> doAnotherThing(element));
findFirst
这是一个 termimal 兼 short-circuiting 操作,它总是返回 Stream 的第一个元素,或者空。
这里比较重点的是它的返回值类型:Optional。这也是一个模仿 Scala 语言中的概念,作为一个容器,它可能含有某值,或者不包含。使用它的目的是尽可能避免 NullPointerException。
Optional 的两个用例
String strA = " abcd ", strB = null;
print(strA);
print("");
print(strB);
getLength(strA);
getLength("");
getLength(strB);
public static void print(String text) {
// Java 8
Optional.ofNullable(text).ifPresent(System.out::println);
// Pre-Java 8
if (text != null) {
System.out.println(text);
}
}
public static int getLength(String text) {
// Java 8
return Optional.ofNullable(text).map(String::length).orElse(-1);
// Pre-Java 8
// return if (text != null) ? text.length() : -1;
};
在更复杂的 if (xx != null) 的情况中,使用 Optional 代码的可读性更好,而且它提供的是编译时检查,能极大的降低 NPE 这种 Runtime Exception 对程序的影响,或者迫使程序员更早的在编码阶段处理空值问题,而不是留到运行时再发现和调试。
可以参考:
https://blog.csdn.net/aitangyong/article/details/54564100
reduce
这个方法的主要作用是把 Stream 元素组合起来。它提供一个起始值(种子),然后依照运算规则(BinaryOperator),和前面 Stream 的第一个、第二个、第 n 个元素组合。从这个意义上说,字符串拼接、数值的 sum、min、max、average 都是特殊的 reduce。例如 Stream 的 sum 就相当于
Integer sum = integers.reduce(0, (a, b) -> a+b); 或
Integer sum = integers.reduce(0, Integer::sum);
也有没有起始值的情况,这时会把 Stream 的前面两个元素组合起来,返回的是 Optional。
reduce 的用例
// 字符串连接,concat = "ABCD"
String concat = Stream.of("A", "B", "C", "D").reduce("", String::concat);
// 求最小值,minValue = -3.0
double minValue = Stream.of(-1.5, 1.0, -3.0, -2.0).reduce(Double.MAX_VALUE, Double::min);
// 求和,sumValue = 10, 有起始值
int sumValue = Stream.of(1, 2, 3, 4).reduce(0, Integer::sum);
// 求和,sumValue = 10, 无起始值
sumValue = Stream.of(1, 2, 3, 4).reduce(Integer::sum).get();
// 过滤,字符串连接,concat = "ace"
concat = Stream.of("a", "B", "c", "D", "e", "F").
filter(x -> x.compareTo("Z") > 0).
reduce("", String::concat);
上面代码例如第一个示例的 reduce(),第一个参数(空白字符)即为起始值,第二个参数(String::concat)为 BinaryOperator。这类有起始值的 reduce() 都返回具体的对象。而对于第四个示例没有起始值的 reduce(),由于可能没有足够的元素,返回的是 Optional,请留意这个区别
limit/skip
limit 返回 Stream 的前面 n 个元素;skip 则是扔掉前 n 个元素(它是由一个叫 subStream 的方法改名而来)。
public void testLimitAndSkip() {
List<Person> persons = new ArrayList();
for (int i = 1; i <= 10000; i++) {
Person person = new Person(i, "name" + i);
persons.add(person);
}
List<String> personList2 = persons.stream().
map(Person::getName).limit(10).skip(3).collect(Collectors.toList());
System.out.println(personList2);
}
private class Person {
public int no;
private String name;
public Person (int no, String name) {
this.no = no;
this.name = name;
}
public String getName() {
System.out.println(name);
return name;
}
}
min/max/distinct
min 和 max 的功能也可以通过对 Stream 元素先排序,再 findFirst 来实现,但前者的性能会更好,为 O(n),而 sorted 的成本是 O(n log n)。同时它们作为特殊的 reduce 方法被独立出来也是因为求最大最小值是很常见的操作。
Match
Stream 有三个 match 方法,从语义上说:
allMatch:Stream 中全部元素符合传入的 predicate,返回 true
anyMatch:Stream 中只要有一个元素符合传入的 predicate,返回 true
noneMatch:Stream 中没有一个元素符合传入的 predicate,返回 true
它们都不是要遍历全部元素才能返回结果。例如 allMatch 只要一个元素不满足条件,就 skip 剩下的所有元素,返回 false。对清单 13 中的 Person 类稍做修改,加入一个 age 属性和 getAge 方法。
用 Collectors 来进行 reduction 操作
java.util.stream.Collectors 类的主要作用就是辅助进行各类有用的 reduction 操作,例如转变输出为 Collection,把 Stream 元素进行归组。
groupingBy/partitioningBy
按照年龄归组
Map<Integer, List<Person>> personGroups = Stream.generate(new PersonSupplier()).
limit(100).
collect(Collectors.groupingBy(Person::getAge));
Iterator it = personGroups.entrySet().iterator();
while (it.hasNext()) {
Map.Entry<Integer, List<Person>> persons = (Map.Entry) it.next();
System.out.println("Age " + persons.getKey() + " = " + persons.getValue().size());
}
3.新时间日期 API
在旧版的 Java 中,日期时间 API 存在诸多问题,其中有:
非线程安全 − java.util.Date 是非线程安全的,所有的日期类都是可变的,这是Java日期类最大的问题之一。
设计很差 − Java的日期/时间类的定义并不一致,在java.util和java.sql的包中都有日期类,此外用于格式化和解析的类在java.text包中定义。java.util.Date同时包含日期和时间,而java.sql.Date仅包含日期,将其纳入java.sql包并不合理。另外这两个类都有相同的名字,这本身就是一个非常糟糕的设计。
时区处理麻烦 − 日期类并不提供国际化,没有时区支持,因此Java引入了java.util.Calendar和java.util.TimeZone类,但他们同样存在上述所有的问题。
Java 8 在 java.time 包下提供了很多新的 API。以下为两个比较重要的 API:
Local(本地) − 简化了日期时间的处理,没有时区的问题。
Zoned(时区) − 通过指定的时区处理日期时间。
新的java.time包涵盖了所有处理日期,时间,日期/时间,时区,时刻(instants),过程(during)与时钟(clock)的操作。
LocalDate、LocalTime、LocalDateTime 类的实例是不可变的对象,分别表示使用 ISO-8601 日历系统的日期、时间、日期和时间。它们提供了简单的日期或时间,并不包含当前的时间信息,也不包含与时区相关的信息。(注:ISO-8601日历系统是国际标准化组织制定的现代公民的日期和时间的表示法。)
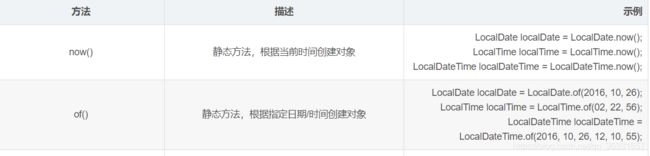
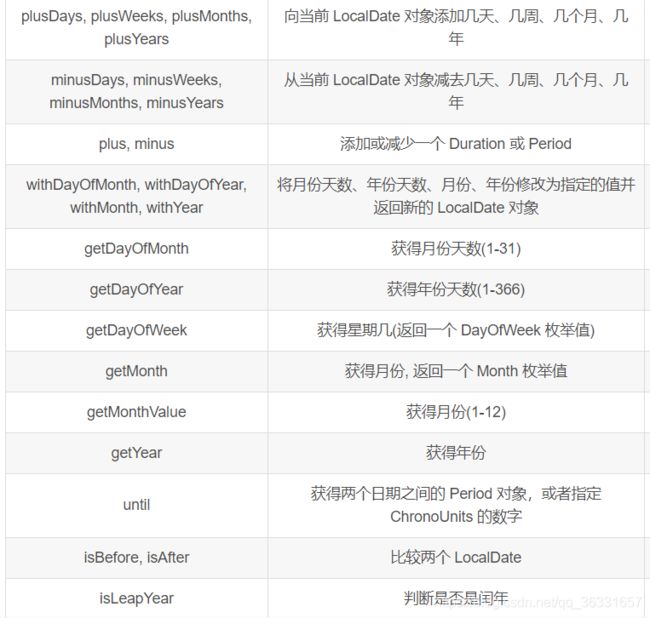
@Test
public void testLocalDateTime() {
// 获取当前的日期时间
LocalDateTime ldt = LocalDateTime.now();
System.out.println("当前时间: " + ldt);
LocalDateTime ldt2 = LocalDateTime.of(2016, 11, 21, 10, 10, 10);
System.out.println("使用指定数据: " + ldt2);
LocalDateTime ldt3 = ldt2.plusYears(20);
System.out.println("加20年: " + ldt3);
LocalDateTime ldt4 = ldt2.minusMonths(2);
System.out.println("减2个月: " + ldt4);
System.out.println("年: " + ldt.getYear());
System.out.println("月: " + ldt.getMonthValue());
System.out.println("日: " + ldt.getDayOfMonth());
System.out.println("时: " + ldt.getHour());
System.out.println("分: " + ldt.getMinute());
System.out.println("秒: " + ldt.getSecond());
}
Instant 时间戳
用于“时间戳”的运算。它是以Unix元年(传统的设定为UTC时区1970年1月1日午夜时分)开始所经历的描述进行运算。
@Test
public void testInstant() {
// 默认使用 UTC 时区(0时区)
Instant ins = Instant.now();
System.out.println(ins);
// 偏移8个时区
OffsetDateTime odt = ins.atOffset(ZoneOffset.ofHours(8));
System.out.println(odt);
// 获取纳秒
System.out.println(ins.getNano());
// 在 1970年1月1日 00:00:00 加5秒
Instant ins2 = Instant.ofEpochSecond(5);
System.out.println(ins2);
}
Duration 和 Period
Duration:用于计算两个“时间”间隔
Period:用于计算两个“日期”间隔
@Test
public void testDurationAndPeriod() {
try {
Instant ins1 = Instant.now();
Thread.sleep(1000); // 休息一秒
Instant ins2 = Instant.now();
System.out.println("所耗费时间为:" + Duration.between(ins1, ins2));
System.out.println("----------------------------------");
LocalDate ld1 = LocalDate.now();
LocalDate ld2 = LocalDate.of(2011, 1, 1);
Period pe = Period.between(ld2, ld1);
System.out.println(pe.getYears());
System.out.println(pe.getMonths());
System.out.println(pe.getDays());
} catch (InterruptedException e) {
}
}
日期的操纵
TemporalAdjuster : 时间校正器。有时我们可能需要获取例如:将日期调整到“下个周日”等操作。
TemporalAdjusters : 该类通过静态方法提供了大量的常用TemporalAdjuster 的实现。
@Test
public void testTemporalAdjuster() {
LocalDateTime ldt = LocalDateTime.now();
System.out.println("当前日期: " + ldt);
LocalDateTime ldt2 = ldt.withDayOfMonth(10);
System.out.println("设置为这个月的10号: " + ldt2);
LocalDateTime ldt3 = ldt.with(TemporalAdjusters.next(DayOfWeek.SUNDAY));
System.out.println("下个周日: " + ldt3);
// 自定义:下一个工作日
LocalDateTime ldt5 = ldt.with((l) -> {
LocalDateTime ldt4 = (LocalDateTime) l;
DayOfWeek dow = ldt4.getDayOfWeek();
if (dow.equals(DayOfWeek.FRIDAY)) {
return ldt4.plusDays(3);
} else if (dow.equals(DayOfWeek.SATURDAY)) {
return ldt4.plusDays(2);
} else {
return ldt4.plusDays(1);
}
});
System.out.println("自定义:下一个工作日: " + ldt5);
}
解析与格式化
java.time.format.DateTimeFormatter 类:该类提供了三种
格式化方法:
预定义的标准格式
语言环境相关的格式
自定义的格式
@Test
public void testDateTimeFormatter() {
// DateTimeFormatter dtf = DateTimeFormatter.ISO_LOCAL_DATE;
DateTimeFormatter dtf = DateTimeFormatter.ofPattern("yyyy年MM月dd日 HH:mm:ss E");
LocalDateTime ldt = LocalDateTime.now();
String strDate = ldt.format(dtf);
System.out.println(strDate);
LocalDateTime newLdt = ldt.parse(strDate, dtf);
System.out.println(newLdt);
}
时区的处理:ZonedDate、ZonedTime、ZonedDateTime
Java8 中加入了对时区的支持,带时区的时间分别为:ZonedDate、ZonedTime、ZonedDateTime。
其中每个时区都对应着 ID和 地区ID ,都为 “{区域}/{城市}” 的格式。例如 :Asia/Shanghai 等。
ZoneId:该类中包含了所有的时区信息
getAvailableZoneIds() : 可以获取所有时区信息
of(id) : 用指定的时区信息获取 ZoneId 对象
@Test
public void testZoned() {
LocalDateTime ldt = LocalDateTime.now(ZoneId.of("Asia/Shanghai"));
System.out.println(ldt);
ZonedDateTime zdt = ZonedDateTime.now(ZoneId.of("US/Pacific"));
System.out.println(zdt);
}
@Test
public void testZoneId() {
Set<String> set = ZoneId.getAvailableZoneIds();
set.forEach(System.out::println);
}
4.非阻塞异步编程
在jdk8之前,我们使用java的多线程编程,一般是通过Runnable中的run方法进行的。这种方法有个明显的缺点:没有返回值。这时候,大家会使用Callable+Future的方式去实现,代码如下。
public static void main(String[] args) throws Exception {
ExecutorService executor = Executors.newSingleThreadExecutor();
Future<String> stringFuture = executor.submit(new Callable<String>() {
@Override
public String call() throws Exception {
Thread.sleep(2000);
return "async thread";
}
});
Thread.sleep(1000);
System.out.println("main thread");
System.out.println(stringFuture.get());
}
这无疑是对高并发访问的一种缓冲方法。这种方式有一个致命的缺点就是阻塞式调用,当调用了get方法之后,会有大量的时间耗费在等待返回值之中。
不管怎么看,这种做法貌似都不太妥当,至少在代码美观性上就看起来很蛋疼。而且某些场景无法使用,比如:
多个异步线程执行时间可能不一致,我们的主线程不能一直等着。
两个异步任务之间相互独立,但是第二个依赖第一个的执行结果
在这种场景下,CompletableFuture的优势就展现出来了 。同时,CompletableFuture的封装中使用了函数式编程,这让我们的代码显得更加简洁、优雅。
CompletableFuture使用详解
runAsync和supplyAsync方法
CompletableFuture提供了四个静态方法来创建一个异步操作。
public static CompletableFuture<Void> runAsync(Runnable runnable)
public static CompletableFuture<Void> runAsync(Runnable runnable, Executor executor)
public static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier)
public static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier, Executor executor)
没有指定Executor的方法会使用ForkJoinPool.commonPool() 作为它的线程池执行异步代码。如果指定线程池,则使用指定的线程池运行。以下所有的方法都类同。
runAsync方法不支持返回值。
supplyAsync可以支持返回值
/**
* 无返回值
*
* @throws Exception
*/
@Test
public void testRunAsync() throws Exception {
CompletableFuture<Void> future = CompletableFuture.runAsync(() -> {
try {
TimeUnit.SECONDS.sleep(1);
} catch (Exception ignored) {
}
System.out.println("run end ...");
});
future.get();
}
/**
* 有返回值
*
* @throws Exception
*/
@Test
public void testSupplyAsync() throws Exception {
CompletableFuture<Long> future = CompletableFuture.supplyAsync(() -> {
System.out.println("run end...");
return System.currentTimeMillis();
});
Long time = future.get();
System.out.println(time);
}
计算结果完成时的回调方法
当CompletableFuture的计算结果完成,或者抛出异常的时候,可以执行特定的操作。
public CompletableFuture<T> whenComplete(BiConsumer<? super T,? super Throwable> action)
public CompletableFuture<T> whenCompleteAsync(BiConsumer<? super T,? super Throwable> action)
public CompletableFuture<T> whenCompleteAsync(BiConsumer<? super T,? super Throwable> action, Executor executor)
public CompletableFuture<T> exceptionally(Function<Throwable,? extends T> fn)
这里需要说的一点是,whenComplete和whenCompleteAsync的区别。
whenComplete:使用执行当前任务的线程继续执行whenComplete的任务。
whenCompleteAsync:使用新的线程执行任务。
exceptionally:执行出现异常时,走这个方法。
* @throws Exception
*/
@Test
public void testWhenComplete() throws Exception {
CompletableFuture.runAsync(() -> {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("运行结束");
}).whenComplete((t, action) -> {
System.out.println("执行完成");
}).exceptionally(t -> {
System.out.println("出现异常:" + t.getMessage());
return null;
});
TimeUnit.SECONDS.sleep(2);
}
thenApply
当一个线程依赖另一个线程时,可以使用thenApply方法把这两个线程串行化,第二个任务依赖第一个任务的返回值。
/**
* 当一个线程依赖另一个线程时,可以使用 thenApply 方法来把这两个线程串行化。
* 第二个任务依赖第一个任务的结果
*
* @throws Exception
*/
@Test
public void testThenApply() throws Exception {
CompletableFuture<Long> future = CompletableFuture.supplyAsync(() -> {
long result = new Random().nextInt();
System.out.println("result:" + result);
return result;
}).thenApply(t -> {
long result = t * 5;
System.out.println("result2:" + result);
return result;
});
Long result = future.get();
System.out.println(result);
}
handle
handle是执行任务完成时对结果的处理。与thenApply方法处理方式基本一致,
不同的是,handle是在任务完成后执行,不管这个任务是否出现了异常,而thenApply只可以执行正常的任务,任务出现了异常则不执行。
/**
* handle 是执行任务完成时对结果的处理。
* handle 方法和 thenApply 方法处理方式基本一样。
* 不同的是 handle 是在任务完成后再执行,还可以处理异常的任务。
* thenApply 只可以执行正常的任务,任务出现异常则不执行 thenApply 方法。
*
* @throws Exception
*/
@Test
public void testHandle() throws Exception {
CompletableFuture<Integer> future = CompletableFuture.supplyAsync(() -> {
int i = 10 / 0;
return i;
}).handle((p, t) -> {
int result = -1;
if (t == null) {
result = p * 2;
} else {
System.out.println(t.getMessage());
}
return result;
});
System.out.println(future.get());
}
thenAccept
thenAccept用于接收任务的处理结果,并消费处理,无返回结果。
/**
* 接收任务的处理结果,并消费处理,无返回结果。
*
* @throws Exception
*/
@Test
public void testThenAccept() throws Exception {
CompletableFuture<Void> future = CompletableFuture.supplyAsync(() -> {
return new Random().nextInt();
}).thenAccept(num -> {
System.out.println(num);
});
System.out.println(future.get());
}
thenRun
上个任务执行完之后再执行thenRun的任务,二者只存在先后执行顺序的关系,后者并不依赖前者的计算结果,同时,没有返回值。
/**
* 该方法同 thenAccept 方法类似。不同的是上个任务处理完成后,并不会把计算的结果传给 thenRun 方法。
* 只是处理玩任务后,执行 thenRun 的后续操作。
*
* @throws Exception
*/
@Test
public void testThenRun() throws Exception {
CompletableFuture<Void> future = CompletableFuture.supplyAsync(() -> {
return new Random().nextInt();
}).thenRun(() -> {
System.out.println("进入了thenRun");
});
System.out.println(future.get());
}
thenCombine
thenCombine会把两个CompletableFuture的任务都执行完成后,把两个任务的返回值一块交给thenCombine处理(有返回值)。
public void testThenCombine() throws Exception {
CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> {
return "hello";
}).thenCombine(CompletableFuture.supplyAsync(() -> {
return "world";
}), (t1, t2) -> {
return t1 + " " + t2;
});
System.out.println(future.get());
}
thenAcceptBoth
当两个CompletableFuture都执行完成后,把结果一块交给thenAcceptBoth处理(无返回值)
CompletableFuture<Void> future = CompletableFuture.supplyAsync(() -> {
return "hello";
}).thenAcceptBoth(CompletableFuture.supplyAsync(() -> {
return "world";
}), (t1, t2) -> {
System.out.println(t1 + " " + t2);
});
System.out.println(future.get());
}
applyToEither
两个CompletableFuture,谁执行返回的结果快,就用哪个的结果进行下一步操作(有返回值)。
public void testApplyToEither() throws Exception {
CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> {
try {
Thread.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
return "hello";
}).applyToEither(CompletableFuture.supplyAsync(() -> {
return "world";
}), (t) -> {
return t;
});
System.out.println(future.get());
}
acceptEither
两个CompletableFuture,谁执行返回的结果快,就用哪个的结果进行下一步操作(无返回值)。
public void testAcceptEither() throws Exception {
CompletableFuture<Void> future = CompletableFuture.supplyAsync(() -> {
return "hello";
}).acceptEither(CompletableFuture.supplyAsync(() -> {
return "world";
}), t1 -> {
System.out.println(t1);
});
System.out.println(future.get());
}
runAfterEither
两个CompletableFuture,任何一个完成了都会执行下一步操作
public void testRunAfterEither() throws Exception {
CompletableFuture<Void> future = CompletableFuture.supplyAsync(() -> {
return "hello";
}).runAfterEither(CompletableFuture.supplyAsync(() -> {
return "world";
}), () -> {
System.out.println("执行完了");
});
System.out.println(future.get());
}
runAfterBoth
两个CompletableFuture,都完成了才会执行下一步操作。
public void testRunAfterBoth() throws Exception {
CompletableFuture<Void> future = CompletableFuture.supplyAsync(() -> {
return "hello";
}).runAfterBoth(CompletableFuture.supplyAsync(() -> {
return "world";
}), () -> {
System.out.println("执行完了");
});
System.out.println(future.get());
}
thenCompose
thenCompose方法允许对两个CompletableFuture进行流水线操作,当第一个操作完成时,将其结果作为参数传递给第二个操作。
public void testThenCompose() throws Exception {
CompletableFuture<Integer> future = CompletableFuture.supplyAsync(() -> {
int t = new Random().nextInt();
System.out.println(t);
return t;
}).thenCompose(param -> {
return CompletableFuture.supplyAsync(() -> {
int t = param * 2;
System.out.println("t2=" + t);
return t;
});
});
System.out.println(future.get());
}