第十届中国大学生服务外包创新创业大赛
基于TextCNN的电商产品短文本分类
分类一直是数据科学界研究的重点问题,它被广泛地应用到生活的各个方面。伴随着电商行业的快速发展。商品的数量越来越多,需要对商品制定分类,便于找寻自己所需的商品。针对现在每天都会产生的大量商品名称,如果人工去为商品分类,不仅工作量巨大,速度慢,而且也会出现分类错误的情况。因此本项目旨在寻找一种分类方法,能够实现商品的快速准确的分类,降低人工成本以及出错率。
Github项目完整内容链接:https://github.com/Cynicicm/Service-outsourcing
项目宣传视频链接:https://pan.baidu.com/s/1jFQ3mY7QW1waBWzvP2JOQg 提取码:n0fp
项目创意
本项目采用基于CNN的文本分类模型实现自动分类。文本分类模型大体上分为基于传统机器学习和基于深度学习的文本分类模型,后者与前者最主要的区别是随着数据规模的增加其性能也不断增长。本项目的数据集在万级以上,因此基于深度学习的文本分类模型能够更加完美地解释它。
随着现在大数据时代的到来,基于深度学习模型的文本分类模型已经成为了主流,其中CNN模型在文本分类任务中是兼具效率与质量的理想模型。因此基于CNN的文本分类模型具有良好的商业价值和社会应用价值。
项目特色
- 采用针对大量数据集的深度学习框架从而可以自动地从已构建的数据集上归纳出一套分类规则;
- 采用结巴中文分词技术能够将句子最精确地切开,适合文本分析;
- 采用One-Hot技术使文本数值化能够有效降低异常值对模型的影响,增强模型稳定性;
- 采用目前业界普遍认为准确度最高的模型TextCNN进行文本分类,兼具效率与质量;
- 采用MVC架构实现用户与系统之间的交互,支持多种查询数据的方式,可视化效果好。
数据集
数据集请自行下载: https://pan.baidu.com/s/1Fw9Zb9gV3Y6GaloOSne6hQ 提取码: r1p0
训练结果模型地址:https://pan.baidu.com/s/1hZSDZmBfbA04E_NKfm0taA 提取码:wznj
通过比对模型的训练的结果,最终采取训练集:验证集为 19:1 .
数据集划分如下:
- 训练集: 475,000
- 验证集: 25,000
- 测试集: 4,500,000
环境
- python 3
- jieba(中文分词) 0.39
- pandas 0.24.1
- numpy 1.16.2
- tensorflow 1.13.1
数据预处理
我们希望能够得知商品信息,自动对其进行分类,比如针对“腾讯QQ币148元148QQ币148个直充148Q币148个Q币148个QQB★自动充值”这样一个商品信息,预期得到“本地生活--游戏充值--QQ充值”,那么首先第一步就是要对原始数据进行预处理,在本项目中主要处理以下问题:
-
除去非文本部分
-
处理中文编码
-
处理某些行堆积几百条数据
-
结巴中文分词处理
-
one-hot表示数据与标签
CNN文本分类模型
CNN的大致结构:

CNN配置参数
CNN可配置的参数如下所示,在train_cnn.py中。
class TCNNConfig(object):
"""CNN配置参数"""
# 模型参数
embedding_dim = 128 # 词向量维度
seq_length = 40 # 序列长度
num_classes = 1199 # 类别数
num_filters = 128 # 卷积核数目
filter_sizes = 3,4,5 # 卷积核尺寸
vocab_size = 160000 # 词汇表大小
fc_hidden_size = 1024 # 全连接层神经元
dropout_keep_prob = 0.5 # 防止过拟合
dropout # 保留比例
learning_rate = 0.001 # 学习率
batch_size = 256 # 每批训练大小
num_epochs = 40 # 总迭代轮次
evaluate_every = 800 # 每多少步进行一次验证参数变化过程
| 参数 | 第一次 | 第二次 | 第三次 | 第四次 |
|---|---|---|---|---|
| num_epochs | 35 | 35 | 100 | 40 |
| batch_size | 64 | 512 | 256 | 256 |
| Learn_rate | 0.001 | 0.01 | 0.001 | 0.001 |
| 训练集验证集比例 | 19:1 | 19:1 | 4:1 | 19:1 |
| 最终结果 | 第一次 | 第二次 | 第三次 | 第四次 |
|---|---|---|---|---|
| Recall | 0.628637 | 0.824505 | 0.843764 | 0.857021 |
| accuracy | 0.624419 | 0.823446 | 0.83916 | 0.857925 |
| F | 0.625825 | 0.823799 | 0.840695 | 0.853659 |
根据上表,在这里我们展示第四次效果最佳情况下的一些结果变化过程. 再此之前我们先解释一下一些结果值的概念。
现在假设我们的分类目标只有两类,计为正例(positive)和负例(negtive)分别是:
1)True positives(TP): 被正确地划分为正例的个数,即实际为正例且被分类器划分为正例的实例数(样本数);
2)False positives(FP): 被错误地划分为正例的个数,即实际为负例但被分类器划分为正例的实例数;
3)False negatives(FN):被错误地划分为负例的个数,即实际为正例但被分类器划分为负例的实例数;
4)True negatives(TN): 被正确地划分为负例的个数,即实际为负例且被分类器划分为负例的实例数。
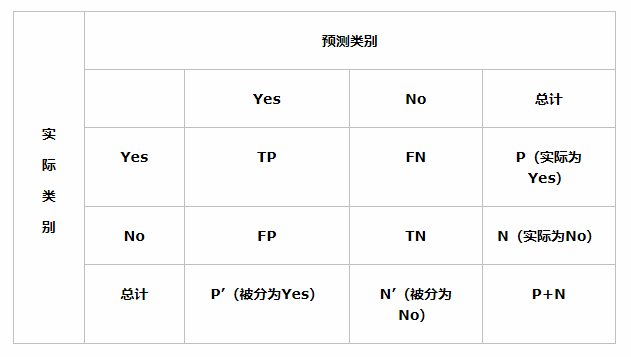
首先有关TP、TN、FP、FN的概念。大体来看,TP与TN都是分对了情况,TP是正类,TN是负类。
则推断出,FP是把错的分成了对的,而FN则是把对的分成了错的。
1.准确率(Accuracy)。顾名思义,就是所有预测正确(正类负类)的占总的比重。
Accuracy=(TP+TN)/(TP+TN+FP+FN)
2.精确率(Precison),查准率。即正确预测为正的占全部预测为正的比例。
Precision=TP/(TP+FP)
3.召回率(Recall),查全率。即正确预测为正的占全部实际为正的比例。
Recall=TP/(TP+FN)
4.F1值,算数平均数除以几何平均数,且越大越好。
2/F1=1/Precision+1/Recall
5.Epoch,使用训练集的全部数据对模型进行一次完成训练,被称之为“一代训练”。
6.Batch,使用训练集中的一小部分样本对模型权重进行一次反向传播的参数更
新,这一部分样本被称为“一批数据”。
7.Iteration,使用一个Batch数据对模型进行一次参数更新的过程,被称之为“一
次训练”。
结语
整个模型读取450万待预测数据并处理的效率为 128,571个/分钟,打标签的效率为 97,825个/分钟、准确率为 85.792%,为训练集打标签的准确率为 91.593%。实际上如果原始数据集更加规范准确、每类商品信息的数据集更大,我们模型的准确率会更高。
文件说明
data_helper.py 包含数据预处理函数,以及对文件的操作函数都在里面
predict_cnn.py 提供模型的预测
textCNN.py CNN模型
train_cnn.py 训练模型
运行步骤:
每次更改训练集需要重新运行步骤1,2再进行预测
1.运行data_helper.py 构造词汇表,获得数据分类
2.运行train_cnn.py 进行模型的训练(在logs文件可以找到相关日志文件查看记录)
3.运行predict_cnn.py进行预测