MySQL数据库
MySQL快速入门
- MySQL概述
- 1.1mysql是什么
- 1.2mysq简介
- 1.3mysql的优点
- MySQL数据库操作
- 2.1创建数据库
- 2.12表的一些常见约束
- 2.2 删除数据库
- 2.3 数据表
- 2.31 创建表
- 2.4 插入表数据
- 2.5 修改表数据
- 2.6 删除表数据
- 关键字汇总
- 练习:
- 3. 单表查询
- 3.1条件查询
- 3.11 比较运算符
- 3.12 比较运算符
- 3.13 逻辑运算符
- 3.14 模糊查询
- 3.15 逻辑删除
- 3.16 范围查询
- 3.17 空判断
- 4. 函数
- 4.1聚合函数
- 4.11 求和(sum)
- 4.12 统计(count)
- 4.13 平均数(avg)
- 4.14 最大值(max)
- 4.15 最小值(min)
- 4.16 常见内置函数
- 5. 排序
- 6. 分组
- 6.1 分组后过滤(having)
- 6.2 取别名
- 6.3 去重复
- 6.4 子查询
- 6.5分页查询
- 7. 多表查询
- 7.1 内连接查询
- 7.2 等值连接
- 7.3外连接
- 7.31 左外连接
- 7.32 右外连接
- 7.4 查询结果连接(union all)
- 7.5 多个表连接(3表或以上)
- 7.6 外键约束
- 8. 数据库的高级应用
- 8.1 存储过程
- 8.11无参数存储过程
- 8.12 有参存储过程
- 8.2 视图
- 8.3 事务
- 8.4 索引
- 8.41 索引是什么
- 8.42 索引的优点
- 8.43 索引的缺点
MySQL概述
1.1mysql是什么
mysql是一个数据库,用来管理数据的,就像车库是用来管理车辆。其他产品有
oracle。mysql是一个关系型的数据库。mysql数据库是表的集合
1.2mysq简介
MySQL是一个流行的关系型数据库管理系统,开发者为瑞典MySQL AB公司。目前属于 Oracle 旗下公司。MySQL被广泛地应用在Internet上的中小型网站中。在 WEB 应用方面 MySQL 是最好的RDBMS(Relational Database Management System:关系数据库管理系统)应用软件之一。
1.3mysql的优点
(1)MySQL 是开源的,所以你不需要支付额外的费用。
(2)MySQL 支持大型的数据库。可以处理拥有上千万条记录的大型数据库。
(3)MySQL 使用标准的 SQL 数据语言形式,具有通用性。
(4)MySQL 可以运行于多个系统上,并且支持多种语言。这些编程语言包括 C、
Python、Java等。
MySQL数据库操作
2.1创建数据库
-- 通过代码创建数据库
CREATE DATABASE 数据库名 CHARSET = 'utf8';
– 创建一个以自己命名的数据库,字符是utf8的字符编码
– 选中数据库: USE 测试;
2.12表的一些常见约束
1,主键约束:不能为空,唯一性 primary key
2,非空约束:不能为空 not null
3,自增约束:自然数挨个自增 ,每次只加1 ,AUTO_INCREMENT
4,默认值约束:在建表的时候就会给一个默认值 DEFAULT
2.2 删除数据库
– 删除指定的数据库:
DROP DATABASE 数据库名称;
2.3 数据表
2.31 创建表
CREATE TABLE student(
id INT PRIMARY KEY COMMENT '学生编号',
NAME VARCHAR(20) COMMENT '学生姓名',
age INT COMMENT '年龄',
sex CHAR(1) COMMENT '性别',
brithday DATE COMMENT '出生日期'
);
注意事项:
varchar 表示字符串
char 表示字符
int 表示整形
date表示日期,年-月-日
datetime表示日期,年-月-日-时-分-秒
double(3,2) 表示小数类型 3表示总共3位,2表示小数点后2位
2.4 插入表数据
– 用代码的方式插入数据
INSERT INTO 表名 (字段1 , 字段2) VALUE(数据1 , 数据2);
2.5 修改表数据
– 用代码的方式修改表数据:
UPDATE student SET 字段 = '数据' WHERE 字段 = '数据';
2.6 删除表数据
– 清空表有2种方式,
一种是TRUNCATE 表名;
还有一种是DELETE FROM 表名;
TRUNCATE 表名; – 清空表,再次插入数据,数据从1开始,数据不可回滚 。
DELETE FROM 表名; – 清空表,再次插入数据,会跳过原来的id,数据信息写入服务器日志,数据可以 回滚。
关键字汇总
create 表示创建,
table表示表,
PRIMARY KEY表示主键,
comment 表示注释,
insert 表示插入 into表示哪张表名 ,
value表示数值,
update 表示修改,
set表示设置,
delete表示删除
where表示条件
练习:
用代码的方式创建一张医生信息表
表名(doctor)
字段:医生编号,医生姓名,医生年龄,医生性别,医生地址,医生入职日期
1 鲁班 12 男 上路 2001-9-9
1 诸葛亮 15 女 北京 2002-9-9
…
总共写10条数据
将鲁班的地址修改为广州
将诸葛亮这条信息删除
答案如下:
CREATE TABLE doctor(
id INT PRIMARY KEY COMMENT '编号',
NAME VARCHAR(20) COMMENT '姓名',
age INT COMMENT '年龄',
sex CHAR(1) COMMENT '性别',
address VARCHAR(20) COMMENT '地址',
jobTime DATETIME COMMENT '入职日期'
)
INSERT INTO doctor VALUE (1,'鲁班',19,'男','上路','2001-9-8'),
(2,'诸葛亮',19,'男','上路','2001-9-8'),
(3,'张三',3,'女','广州','2001-9-8'),
(4,'李四',35,'男','广州','2001-9-8'),
(5,'王五',67,'女','上路','2001-9-8'),
(6,'赵六',44,'男','上路','2001-9-8'),
(7,'田七',22,'男','广州','2001-9-8'),
(8,'王八',12,'男','广东省广州市番禹区大学城北青蓝街28号创智大厦4栋9楼','2001-
9-8'),
(9,'小九',77,'女','深圳','2001-9-8'),
(10,'老十',23,'男','深圳','2001-9-8')
– 将鲁班的地址修改为广州
UPDATE doctor SET address = '广州' WHERE NAME = '鲁班'
– 将诸葛亮这条信息删除
DELETE FROM doctor WHERE NAME = '诸葛亮'
3. 单表查询
SELECT * FROM doctor; – 全表查询(加大了服务的负担,所有字段都会遍历一遍,查询速度慢)
SELECT NAME FROM doctor; – 单字段查询(查询速度快,只查我们所需的字段信息即可)
如果是查询3个字段 SELECT NAME,age,address FROM doctor;
3.1条件查询
3.11 比较运算符
( = > >= < <= !=)
– 查询编号是5号的医生姓名
SELECT NAME FROM doctor WHERE id = 5;
– 查询出年龄大于20岁的医生信息
SELECT * FROM doctor WHERE age >= 20;
– 查询出所有的女医生
SELECT * FROM doctor WHERE sex = '女'
– 查询出地址住在北京的所有医生
SELECT * FROM doctor WHERE address = '北京'
– 查询出地址不在广州的所有医生
SELECT * FROM doctor WHERE address != '广州'
– 查询出编号是9号的医生信息
SELECT * FROM doctor WHERE id = 9
3.12 比较运算符
(+,-,*,/,%)
将李四的年龄乘以2查询出来
SELECT age * 2 FROM doctor WHERE NAME = '李四'
– 练习:
查询出年龄是偶数的所有医生
SELECT * FROM doctor WHERE age % 2 = 0;
3.13 逻辑运算符
与(and) 或(or)非(not)
and表示并且
or 表示或者
not 表示取反
– 查询年龄大于30岁的男医生
SELECT * FROM doctor WHERE age >= 30 AND sex = '男'
– 查询年龄大于30岁或者年龄小于20岁的医生
SELECT * FROM doctor WHERE age >= 30 OR age < 20;
– 查询出地址不在广州的医生
SELECT * FROM doctor WHERE address NOT IN('广州');
3.14 模糊查询
模糊查询适用于varchar类型
like表示像什么什么的意思 % 表示任意个任意字符 _ 表示一个任意字符
注意:用了like就不能再用=,用了=就不要在用like
– 查询姓名姓张的医生信息
SELECT * FROM doctor WHERE NAME LIKE '张%'
– 查询姓名姓张且名字只有2个字的医生信息
SELECT * FROM doctor WHERE NAME LIKE '张_'
– 查询姓名姓张且名字只有3个字的医生信息
SELECT * FROM doctor WHERE NAME LIKE '张__'
–练习
1,查询不住在北京的医生信息
SELECT * FROM doctor WHERE address != '北京'
2,查询出医生编号,医生姓名,医生性别这几个字段
SELECT id,NAME,sex FROM doctor;
3,将所有男医生的年龄全部增加5岁
UPDATE doctor SET age = age + 5 WHERE sex = '男'
4,查询出在19年之前入职的医生信息
SELECT * FROM doctor WHERE jobTime < '2019-01-01'
5,查询名字是二个字的医生信息
SELECT * FROM doctor WHERE NAME LIKE '__'
6,查询出地址中含有广州的医生信息
SELECT * FROM doctor WHERE address LIKE '%广州%'
7,查询出身高大于1.65的女医生信息
SELECT * FROM doctor WHERE height >= 1.65 AND sex = '女'
8,查询出身高小于1.7或者年龄小于30岁的男医生信息
SELECT * FROM doctor WHERE height < 1.70 OR (age < 30 AND sex = '男')
3.15 逻辑删除
逻辑删除并不是真的把这条删掉,只是把某条数据的状态发生改变。
ALTER TABLE doctor ADD stat INT COMMENT '状态' ##添加状态栏
– 约定(对于一家公司而言,0表示未删除,1表示已删除)
– 逻辑删除,将6号的医生删除
UPDATE doctor SET stat = 1 WHERE id = 6;
练习:将2号医生逻辑删除
update doctor set stat = 1 where id = 2;
3.16 范围查询
连续范围查询:
– 查询出医生编号在3到6号的医生信息
SELECT * FROM doctor WHERE id BETWEEN 3 AND 6; (包括3也包括6)
查询出年龄在20到35岁之间的所有医生信息
select * from doctor where age between 20 and 35;
不连续范围查询:
– 查询出医生编号在3号,4号,6号的医生信息
SELECT * FROM doctor WHERE id IN(3,4,6);
– 查询出不住在北上广的医生信息
SELECT * FROM doctor WHERE address NOT IN('北京','上海','广州');
3.17 空判断
– 查询出填写了身高信息的医生
SELECT * FROM doctor WHERE height IS NOT NULL;
0和null是有区别的
0表示给了内存空间的,只是数值为0而已,
null没有给内存空间的
4. 函数
4.1聚合函数
4.11 求和(sum)
– 计算出所有的男医生的总年龄
SELECT SUM(age) FROM doctor WHERE sex = '男';
– 1,计算出姓张的医生的总年龄
SELECT SUM(age) FROM doctor WHERE NAME LIKE '张%'
– 2,计算出年龄小于30岁的医生的总身高
SELECT SUM(height) FROM doctor WHERE age < 30;
4.12 统计(count)
– 统计出男医生的人数
SELECT COUNT(id) FROM doctor WHERE sex = '男';
– 1,统计出身高大于1.6的医生的人数
SELECT COUNT(id) FROM doctor WHERE height >= 1.6
– 2,统计出年龄大于20岁的女医生的人数
SELECT COUNT(id) FROM doctor WHERE sex = '女' AND age >= 20;
4.13 平均数(avg)
– 计算出女生的平均年龄
SELECT AVG(age) FROM doctor WHERE sex = '女'
4.14 最大值(max)
– 请查询出男生中的最大年龄
SELECT MAX(age) FROM doctor WHERE sex = '男';
4.15 最小值(min)
– 请查询出女生中的最小年龄
SELECT MIN(age) FROM doctor WHERE sex = '女';
4.16 常见内置函数
now() 表示当前系统时间
UPDATE doctor SET jobTime = NOW() WHERE id = 9;
round() 表示四舍五入 – 将张三的身高保留小数点后一位
SELECT ROUND(height,1) FROM doctor WHERE NAME = '张三';
concat() 表示字符串拼接
SELECT CONCAT('亲爱的',NAME) FROM doctor WHERE id = 1
md5() 表示数据加密
SELECT MD5(PASSWORD) FROM USER WHERE id = 1;
5. 排序
对数值进行排序,默认是从小到大(升序),如果想要从大到小(降序)那么就加上desc即可
– 对年龄进行排序,从小到大排列
SELECT * FROM doctor ORDER BY age;
– 对年龄进行排序,从大到小排列(降序)
SELECT * FROM doctor ORDER BY age DESC;
6. 分组
分组就是将一个整体按照一定的条件进行分成2个或2个以上的组
– 统计出男生多少人,女生多少人
SELECT sex,COUNT(id) FROM doctor GROUP BY sex;
– group 表示组,group by 表示通过什 么什么去分组
– 练习1:统计出每个城市的人数
SELECT address,COUNT(id) FROM doctor GROUP BY address;
– 练习2:统计出男生和女生的平均年龄
SELECT sex,AVG(age) FROM doctor GROUP BY sex;
– 练习3:统计出每个城市的最大年龄
SELECT address,MAX(age) FROM doctor GROUP BY address;
– 分组强化
– 对年龄超过25岁以上的人进行分组,分别计算出男生和女生的平均年龄
– (潜在信息平均年龄一定大于25岁)
SELECT sex,AVG(age) FROM doctor WHERE age >= 25 GROUP BY sex
-- sql的编写顺序应 该是where条件在前,分组在后
– 强化分组:
将住在北上广深的医生进行分组,统计出这4个城市的医生的人数
SELECT address,COUNT(id) FROM doctor WHERE address IN('北京','上海','广州','深圳') GROUP BY address
6.1 分组后过滤(having)
过滤是对分组后产生的结果集进行筛选,必须要有分组才有过滤,过滤是和分组进行配合的
请看下面这个典型案例
– avg(age)是在分组后产生的结果集里面做运算算出的结果,
– 而我们把这个结果直接放到where条件里面,肯定会报错。
– 报错的原因就是where在分组之前,结果集还没有产生运算结果也不会有,所以用不了,那么我们要用 having
– 结论:where后面不能接聚合函数,
– 查询出平均年龄大于40岁的所在医生的城市
SELECT address,AVG(age) FROM doctor GROUP BY address HAVING AVG(age) >= 40
– 练习 查询出男生和女生的平均身高,并查询出平均身高高于1.5的性别
SELECT sex,AVG(height) FROM doctor GROUP BY sex HAVING AVG(height) >= 1.5;
6.2 取别名
取别名就是简化字段或者表名的目的,表和字段都可以取别名
SELECT NAME AS 姓名 FROM stu (As可以省略不写)
SELECT address 地址,AVG(score) 平均分 FROM stu GROUP BY address HAVING 平均分 >= 70;
6.3 去重复
– 想从这张表查询出所有的城市
SELECT DISTINCT address FROM stu
distinct 表示去重复的意思,加在字段的前面
6.4 子查询
– 子查询
– 查询语句里面嵌套一个查询语句
– 查询出stu表里面年龄大于平均年龄的所有学生
SELECT AVG(age) FROM stu
-- 得到stu表所有学生的平均年龄
SELECT * FROM stu WHERE age > (SELECT AVG(age) FROM stu)
子查询练习:
1,查询出stu表中高于平均分的学生
SELECT AVG(score) FROM stu SELECT * FROM stu WHERE score > (SELECT AVG(score) FROM stu)
2,查询出stu表中比1组学生最高分还要高的所有学生
SELECT MAX(score) FROM stu WHERE sgroup = '1组'
SELECT * FROM stu WHERE score > (SELECT MAX(score) FROM stu WHERE sgroup = '1 组')
3,查询出stu表中比2组学生平均年龄大的所有学生
SELECT AVG(age) FROM stu WHERE sgroup = '2组'
SELECT * FROM stu WHERE age > (SELECT AVG(age) FROM stu WHERE sgroup = '2组')
6.5分页查询
当数据量很庞大的时候,一次性全部查询出来给服务器造成很大的压力,速度慢,用户体验差。所以需
要分页,一次展示一部分,提高用户体验,减轻服务器的负担。
SELECT * FROM USER LIMIT 0,15;
表示查看第一页,每页显示15条数据
公式:
LIMIT (要查看的页数-1 * 每页显示的条数),每页显示的条数
思考:
每页显示数据是m条,总数据条数是n条。问一共有多少页?
x = n ÷ m
如果x是整数,那么页数就是x
如果x不是整数,那么x取整后加1就是页数
7. 多表查询
商品分类表
| 分类id | 分类名称 |
|---|---|
| 1 | 食品生鲜 |
| 2 | 数码电子 |
| 3 | 男士用品 |
| 4 | 女士用品 |
| 5 | 婴儿用品 |
商品详情表
| 商品编号 | 商品名称 | 商品价格 | 商品描述 | 分类编号 |
|---|---|---|---|---|
| 1 | 卫龙辣条 | 3.5 | 很辣 | 1 |
| 2 | 苹果11 | 6999 | 买不起 | 2 |
| 3 | 三星手机 | 3500 | 可以自爆 | 2 |
| 4 | 七度空间 | 12.8 | 包你干爽 | 4 |
| 5 | 飞科剃须刀 | 58 | 三面刀网 | 3 |
| 6 | 雅诗兰黛小棕瓶 | 399 | 眼霜 | 4 |
| 7 | 火腿肠 | 3.0 | 双汇 | 1 |
多表需求:
使用子查询编写
1,查询出女士用品下面的商品数量
SELECT fid FROM fenlei WHERE fname = '女士用品'
SELECT COUNT(id) FROM shangpin WHERE fid = (SELECT fid FROM fenlei WHERE fname = '女士用品');
2,查询出手机数码分类下的商品的平均价格
SELECT fid FROM fenlei WHERE fname = '手机数码'
SELECT AVG(price) FROM shangpin WHERE fid = (SELECT fid FROM fenlei WHERE fname = '手机数码');
7.1 内连接查询
万能模板:
select * from 主表 inner join 从表 on 主表.主键 = 从表.外键
SELECT * FROM fenlei INNER JOIN shangpin ON fenlei.fid = shangpin.fid;
– 二合一的大表

– inner 表示内部 join表示连接,合称内连接
– on 跟where意思一样,表示连接条件
1,查询出女士用品下面的商品数量
SELECT COUNT(s.id) FROM fenlei f INNER JOIN shangpin s ON f.fid = s.fid AND f.fname = '女士用品'
2,查询出手机数码分类下的商品的平均价格
SELECT AVG(price) FROM fenlei f INNER JOIN shangpin s ON f.fid = s.fid AND f.fname = '手机数码';
3,分别统计出每个商品分类的商品数量
SELECT fenlei.fname,COUNT(shangpin.id) FROM fenlei INNER JOIN shangpin ON fenlei.fid = shangpin.fid GROUP BY fenlei.fname;
4, 查询出每个商品分类下的商品平均价格
SELECT f.fname,AVG(s.price) FROM fenlei f INNER JOIN shangpin s ON f.fid = s.fid GROUP BY f.fname
5,查询出每个商品分类下的商品平均价格,平均价格按从高到低排列
SELECT f.fname,AVG(s.price) FROM fenlei f INNER JOIN shangpin s ON f.fid = s.fid GROUP BY f.fname ORDER BY AVG(s.price) DESC
6,查询出平均价格高于200元的商品分类
SELECT f.fname,AVG(s.price) FROM fenlei f INNER JOIN shangpin s ON f.fid = s.fid GROUP BY f.fname HAVING AVG(s.price) > 200
7.2 等值连接
等值连接属于内连接
SELECT * FROM 主表,从表 WHERE 主表.主键 = 从表.外键
SELECT * FROM fenlei,shangpin WHERE fenlei.fid = shangpin.fid
7.3外连接
7.31 左外连接
左外连接 取左表所有的数据,右表如果没有对应数据的用null表示

练习:
1,查询出所有分类的商品总数量,商品总金额
SELECT f.fname,COUNT(s.id),SUM(s.price) FROM fenlei f LEFT JOIN shangpin s ON f.fid = s.fid GROUP BY f.fname
2,查询出商品描述带有辣字的商品分类
SELECT f.fname FROM fenlei f INNER JOIN shangpin s ON f.fid = s.fid AND s.miaoshu LIKE '%辣%'
或者子查询写法
SELECT fname FROM fenlei WHERE fid IN(SELECT fid FROM shangpin WHERE miaoshu LIKE '%辣%')
3,用一条sql语句查询出每门课都大于80分的学生姓名(表名:TestScores)
Name Course Score
张三 语文 81
张三 数学 75
李四 语文 76
李四 数学 90
王五 语文 81
王五 数学 100
王五 英语 90
按照什么去分组:应该按照名字去分组(题目意思是每门课)
SELECT NAME FROM testscores GROUP BY NAME HAVING MIN(score) >= 80
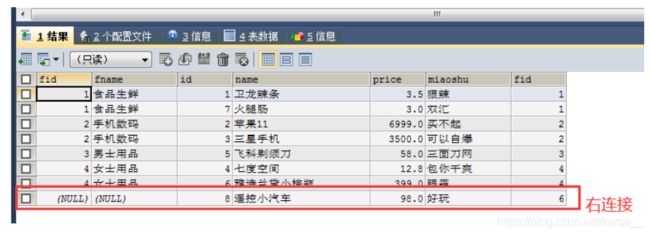
7.32 右外连接
右外连接:取右表中所有数据,左表没有对应的数据的用null表示
SELECT * FROM 主表 RIGHT JOIN 从表 ON 主表.主键 = 从表.外键
SELECT * FROM fenlei RIGHT JOIN shangpin ON fenlei.fid = shangpin.fid -- 右连接
7.4 查询结果连接(union all)
你们公司有一张员工信息表 表名user,分别有A,B,C三个部门,要求查询每个部门工资最高的两位员工信息。部门,工资的字段分别为:dept,money
(SELECT * FROM user2 WHERE dept = 'A' ORDER BY money DESC LIMIT 0,2)
UNION ALL
(SELECT * FROM user2 WHERE dept = 'B' ORDER BY money DESC LIMIT 0,2)
UNION ALL
(SELECT * FROM user2 WHERE dept = 'C' ORDER BY money DESC LIMIT 0,2)
7.5 多个表连接(3表或以上)
1、有3个表:
Student表(学号、姓名)
Course课程表(课程编号,课程名称)
SC 选课表(学号,课程编号,成绩)
CREATE TABLE student(
stu_no INT PRIMARY KEY COMMENT '学号',
stu_name VARCHAR(20) COMMENT '学生姓名'
);
CREATE TABLE course(
c_id INT PRIMARY KEY COMMENT '课程编号',
c_name VARCHAR(20)COMMENT '课程名称'
) ;
CREATE TABLE sc(
stu_no INT COMMENT '学号', c_id INT COMMENT '课程编号',
score INT COMMENT '成绩'
);
3表示连接语句:
SELECT * FROM student s INNER JOIN sc ON s.`stu_no` = sc.`stu_no` INNER JOIN course c ON c.`c_id` = sc.`c_id`
7.6 外键约束
主表不能随便删除或者修改,因为主表中的主键字段被从表所引用,所以需要外键约束来限制非法删除
在表创建好了之后,添加外键约束代码:
ALTER TABLE 从表 ADD CONSTRAINT 外键名字 FOREIGN KEY(外键) REFERENCES 主表(主键);
创建外键约束后,主表不能删除。只能先删除从表,后删除主表
删除外键约束
ALTER TABLE orders(从表的表名) DROP FOREIGN KEY FK_abc(外键名字) -- 删除外键约束
8. 数据库的高级应用
8.1 存储过程
存储过程就是将一段sql语句封装起来,一次编译,多次运行
存储过程的好处:
1,提高sql语句的复用性
2,减少数据库服务器的压力,如果不用存储过程,那么每执行一次sql语句,都要编译。用了存储过程后,只 需要编译一次。
8.11无参数存储过程
创建存储过程的代码:
DELIMITER $$
CREATE
PROCEDURE `数据库名`.`存储过程名称`()
BEGIN
存储过程语句
END$$
DELIMITER ;
调用存储过程:
call 存储过程名称();
练习:
请编写一个无参的存储过程,名字叫query_sum
这个存储过程可以返回每个用户所下订单的总金额
DELIMITER $$
CREATEP
ROCEDURE `多表11班`.`query_sum`()
BEGIN
SELECT u.username,SUM(o.totalprice) FROM USER u INNER JOIN orders o ON u.userid = o.uno GROUP BY o.uno;
END$$
DELIMITER ;
CALL query_sum()
8.12 有参存储过程
DELIMITER $$
CREATE
PROCEDURE `多表11班`.`big_Num2`(IN a INT) -- 定义一个形参a,指定数据类型为int
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i <= a
DO
INSERT INTO fenlei VALUE(NULL,'家具');
SET i = i + 1;
END WHILE;
END$$
DELIMITER ;
带参存储过程调用需要传入参数
call big_Num2(200)
练习:插入1200条数据到user表中
DELIMITER $$
CREATE
PROCEDURE `多表11班`.`yiQian`(IN num INT)
BEGIN
DECLARE i INT DEFAULT 1200;
WHILE i <= num
DO
INSERT INTO USER VALUE(NULL,CONCAT('白龙马',i),'男', 99, '123' ,'13712341234');
SET i = i+1;
END WHILE;
END$$
DELIMITER ;
--调用
CALL yiQian(2400);
进阶练习二(带点难度):
要求:模糊查询输入一个名字的一部分,可以查询出这个用户所下的订单平均价格
DELIMITER $$
USE `多表11班`$$
DROP PROCEDURE IF EXISTS `query_likeName`$$
CREATE DEFINER=`root`@`localhost` PROCEDURE `query_likeName`(IN uName VARCHAR(20))
BEGIN
SELECT u.username,AVG(o.totalprice) FROM USER u INNER JOIN orders o ON u.userid = o.uno AND username LIKE CONCAT('%',uName,'%') GROUP BY o.uno;
END$$
DELIMITER ;
--调用
CALL query_likeName('悟')
8.2 视图
视图的概念:
视图简而言之就是存储查询语句的一个虚拟表(查询语句的封装)
视图的应用场景:
一,工作中存在很常见的一个工作场景时,开放数据库中的部分表字段给第三方,但是某些表中又有一些敏感 的字段不能开放,那么能应用的解决方案有
1、开发接口,
2、建立中间表 第一种无疑是增加了很多的工作量,第二种又增加了资源的消耗。而能够利用视图则很好的解决了这个场景带 来的问题。
二、简化复杂的查询操作。对于一些复杂的查询操作,如果用一条语句来执行,语句的可读性可能会大大减 低,如果能引入视图的概念,则能较好的把复杂的语句化整为零。
视图的作用:
1,程序在发送sql语句的时候,减少代码的长度,减少传送的字节数
2,提高数据的安全性,看不到数据是来自于哪一种表,也看不到数据来自于那一张表中的字段(取别名)
创建一个视图:
CREATE
VIEW `多表11班`.`v_username`
AS
(SELECT * FROM USER u INNER JOIN orders o ON u.userid = o.uno);
调用视图:
视图本质上是一张表,所以我们直接通过select * from 视图调用即可
SELECT * FROM v_username;
8.3 事务
事务有一个前提:引擎必须是InnoDB
事务就是把一串连续的操作整合一个最小的单元,不可分割的一个整体,要么全部成功,要么全部失败
事务的一些特性:4个特性(原子性,一致性,隔离性,持久性)
事务的作用:保证数据的一致性。
建表:
CREATE TABLE `money` (
`name` varchar(20) DEFAULT NULL COMMENT '用户名',
`yue` int(11) DEFAULT NULL COMMENT '余额'
) ENGINE=InnoDB DEFAULT CHARSET=utf8
插入数据
INSERT INTO money VALUE('猪八戒',1000),('嫦娥',10);
正常的事务(全部成功)
-- 开启事务
BEGIN;
UPDATE money SET yue = yue - 500 WHERE NAME = '猪八戒';
-- 正常转账
UPDATE money SET yue = yue + 500 WHERE NAME = '嫦娥';
-- 没有发生异常,我们就提交
COMMIT;
--mysql是自动提交,事务就是将自动提交设置为手动提交,当发生异常的情况下我们可以选择不提交
回滚的事务(全部失败)
-- 猪八戒给嫦娥转500
-- 开启事务
BEGIN;
UPDATE money SET yue = yue - 500 WHERE NAME = '猪八戒';
-- 机器故障
UPDATE money SET yue = yue + 500 WHERE NAME = '嫦娥2';
-- 如果发生了意外,我们可以回滚(撤销)
ROLLBACK;
8.4 索引
8.41 索引是什么
首先我们可以举个例子,字典大家应该都使用过,我们可以使用目录快速定位到所要查找的内容,那么索引跟目录的作用类似,在数据库表记录中,利用索引,可以快速过滤查找到数据记录。
生活中的案例:火车的车厢号码,字典的目录
8.42 索引的优点
1,索引用于快速找出在某个列中有一特定值的行,不使用索引,MySQL必须从第一条记录开始读完整个表,直 到找出相关的行,表越大,查询数据所花费的时间就越多,如果表中查询的列有一个索引,MySQL能够快速到 达一个位置去搜索数据文件,而不必查看所有数据,那么将会节省很大一部分时间,大大加快数据的查询速度
8.43 索引的缺点
1.虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE 和DELETE,因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件
2.但是,在互联网应用中,查询的语句远远大于增删改的语句,甚至可以占到80%~90%,所以也不要 太在意,只是在大数据导入时,可以先删除索引,再批量插入数据,最后再添加索引
建议不要使用索引的几种情况:
1. 区分度不是很大的字段,例如 性别 sex
2. 2. 频繁更新的字段
3. 3. 字符串类型的字段 或者 文本类型的字段
4. 4. 不在where列中出现的索引
索引失效的几种情况:
1. 查询列中有函数计算
2. 查询列中有模糊查询,"%cloum",可以使用"cloum%" 代替,如果要使用"%column%",那么select 列中是索引列
3. 如果查询条件中有or, 索引会失效,除非所有条件都加上索引
4. 使用不等于(!= 或者 <>) 5. is null 或者 is not null 6. 字符串不加引号,会导致索引失效
给表(已经创建好的表)添加索引的代码:
CREATE INDEX index_name ON 表名(NAME(20)); 给表中的name字段添加索引
删除索引
drop index index_name on 表名;
看执行时间
在cmd中
set profiling = 1 --开启时间检测 执行查询语句
show profiles; -- 查看执行时间