基于 Python 的 11 种经典数据降维算法|主成分分析(PCA)降维
主成分分析(PCA)降维
PCA 是一种基于从高维空间映射到低维空间的映射方法,也是最基础的无监督降维算法,其目标是向数据变化最大的方向投影,或者说向重构误差最小化的方向投影。它由 Karl Pearson 在 1901 年提出,属于线性降维方法。与 PCA 相关的原理通常被称为最大方差理论或最小误差理论。这两者目标一致,但过程侧重点则不同。
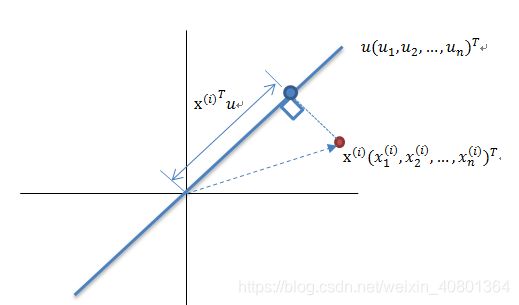
最大方差理论降维原理
将一组 N 维向量降为 K 维(K 大于 0,小于 N),其目标是选择 K 个单位正交基,各字段两两间 COV(X,Y) 为 0,而字段的方差则尽可能大。因此,最大方差即使得投影数据的方差被最大化,在这过程中,我们需要找到数据集 Xmxn 的最佳的投影空间 Wnxk、协方差矩阵等,其算法流程为: 算法输入:数据集 Xmxn;
-
按列计算数据集 X 的均值 Xmean,然后令 Xnew=X−Xmean;
-
求解矩阵 Xnew 的协方差矩阵,并将其记为 Cov;
-
计算协方差矩阵 COV 的特征值和相应的特征向量;
-
将特征值按照从大到小的排序,选择其中最大的 k 个,然后将其对应的 k 个特征向量分别作为列向量组成特征向量矩阵 Wnxk;
-
计算 XnewW,即将数据集 Xnew 投影到选取的特征向量上,这样就得到了我们需要的已经降维的数据集 XnewW。
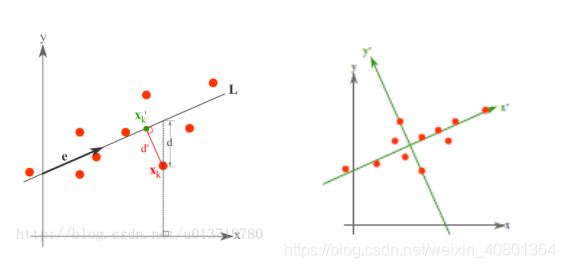
最小误差理论降维原理
而最小误差则是使得平均投影代价最小的线性投影,这一过程中,我们则需要找到的是平方错误评价函数 J0(x0) 等参数。
详细步骤可参考**《从零开始实现主成分分析 (PCA) 算法》**:https://blog.csdn.net/u013719780/article/details/78352262
主成分分析(PCA)代码实现
from __future__ import print_function
from sklearn import datasets
import matplotlib.pyplot as plt
import matplotlib.cm as cmx
import matplotlib.colors as colors
import numpy as np
%matplotlib inline
def shuffle_data(X, y, seed=None):
if seed:
np.random.seed(seed)
idx = np.arange(X.shape[0])
np.random.shuffle(idx)
return X[idx], y[idx]
# 正规化数据集 X
def normalize(X, axis=-1, p=2):
lp_norm = np.atleast_1d(np.linalg.norm(X, p, axis))
lp_norm[lp_norm == 0] = 1
return X / np.expand_dims(lp_norm, axis)
# 标准化数据集 X
def standardize(X):
X_std = np.zeros(X.shape)
mean = X.mean(axis=0)
std = X.std(axis=0)
# 做除法运算时请永远记住分母不能等于 0 的情形
# X_std = (X - X.mean(axis=0)) / X.std(axis=0)
for col in range(np.shape(X)[1]):
if std[col]:
X_std[:, col] = (X_std[:, col] - mean[col]) / std[col]
return X_std
# 划分数据集为训练集和测试集
def train_test_split(X, y, test_size=0.2, shuffle=True, seed=None):
if shuffle:
X, y = shuffle_data(X, y, seed)
n_train_samples = int(X.shape[0] * (1-test_size))
x_train, x_test = X[:n_train_samples], X[n_train_samples:]
y_train, y_test = y[:n_train_samples], y[n_train_samples:]
return x_train, x_test, y_train, y_test
# 计算矩阵 X 的协方差矩阵
def calculate_covariance_matrix(X, Y=np.empty((0,0))):
if not Y.any():
Y = X
n_samples = np.shape(X)[0]
covariance_matrix = (1 / (n_samples-1)) * (X - X.mean(axis=0)).T.dot(Y - Y.mean(axis=0))
return np.array(covariance_matrix, dtype=float)
# 计算数据集 X 每列的方差
def calculate_variance(X):
n_samples = np.shape(X)[0]
variance = (1 / n_samples) * np.diag((X - X.mean(axis=0)).T.dot(X - X.mean(axis=0)))
return variance
# 计算数据集 X 每列的标准差
def calculate_std_dev(X):
std_dev = np.sqrt(calculate_variance(X))
return std_dev
# 计算相关系数矩阵
def calculate_correlation_matrix(X, Y=np.empty([0])):
# 先计算协方差矩阵
covariance_matrix = calculate_covariance_matrix(X, Y)
# 计算 X, Y 的标准差
std_dev_X = np.expand_dims(calculate_std_dev(X), 1)
std_dev_y = np.expand_dims(calculate_std_dev(Y), 1)
correlation_matrix = np.divide(covariance_matrix, std_dev_X.dot(std_dev_y.T))
return np.array(correlation_matrix, dtype=float)
class PCA():
"""
主成份分析算法 PCA,非监督学习算法.
"""
def __init__(self):
self.eigen_values = None
self.eigen_vectors = None
self.k = 2
def transform(self, X):
"""
将原始数据集 X 通过 PCA 进行降维
"""
covariance = calculate_covariance_matrix(X)
# 求解特征值和特征向量
self.eigen_values, self.eigen_vectors = np.linalg.eig(covariance)
# 将特征值从大到小进行排序,注意特征向量是按列排的,即 self.eigen_vectors 第 k 列是 self.eigen_values 中第 k 个特征值对应的特征向量
idx = self.eigen_values.argsort()[::-1]
eigenvalues = self.eigen_values[idx][:self.k]
eigenvectors = self.eigen_vectors[:, idx][:, :self.k]
# 将原始数据集 X 映射到低维空间
X_transformed = X.dot(eigenvectors)
return X_transformed
def main():
# Load the dataset
data = datasets.load_iris()
X = data.data
y = data.target
# 将数据集 X 映射到低维空间
X_trans = PCA().transform(X)
x1 = X_trans[:, 0]
x2 = X_trans[:, 1]
cmap = plt.get_cmap('viridis')
colors = [cmap(i) for i in np.linspace(0, 1, len(np.unique(y)))]
class_distr = []
# Plot the different class distributions
for i, l in enumerate(np.unique(y)):
_x1 = x1[y == l]
_x2 = x2[y == l]
_y = y[y == l]
class_distr.append(plt.scatter(_x1, _x2, color=colors[i]))
# Add a legend
plt.legend(class_distr, y, loc=1)
# Axis labels
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.show()
if __name__ == "__main__":
main()
最终,我们将得到降维结果如下。其中,如果得到当特征数 (D) 远大于样本数 (N) 时,可以使用一点小技巧实现 PCA 算法的复杂度转换。
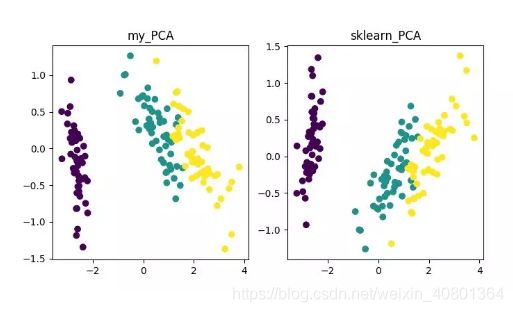
PCA 降维算法展示
当然,这一算法虽然经典且较为常用,其不足之处也非常明显。它可以很好的解除线性相关,但是面对高阶相关性时,效果则较差;同时,PCA 实现的前提是假设数据各主特征是分布在正交方向上,因此对于在非正交方向上存在几个方差较大的方向,PCA 的效果也会大打折扣。