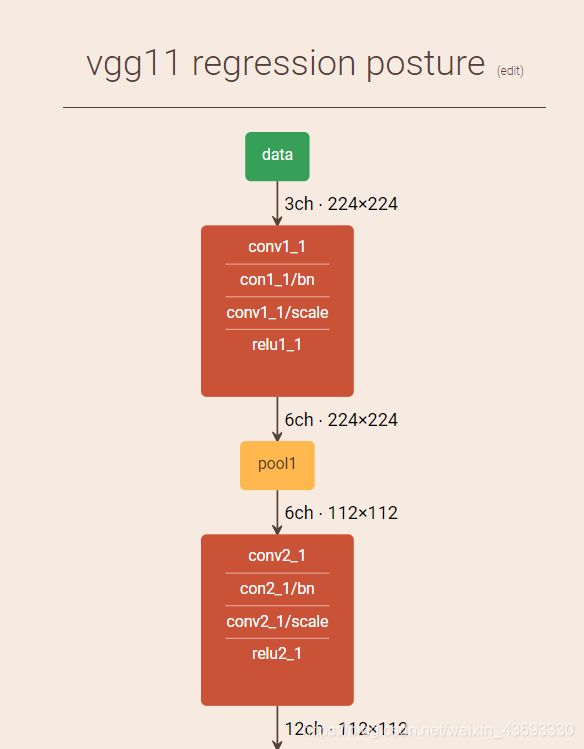
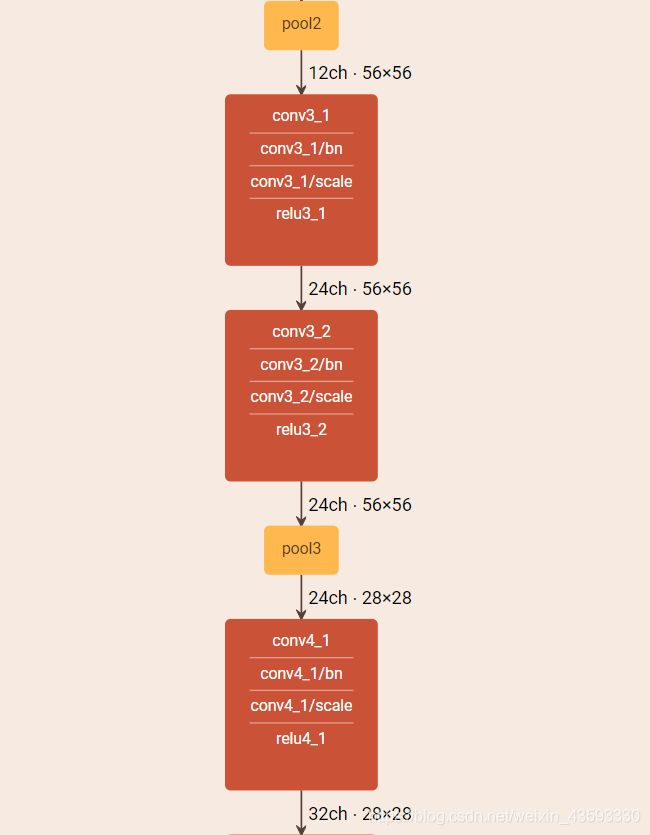
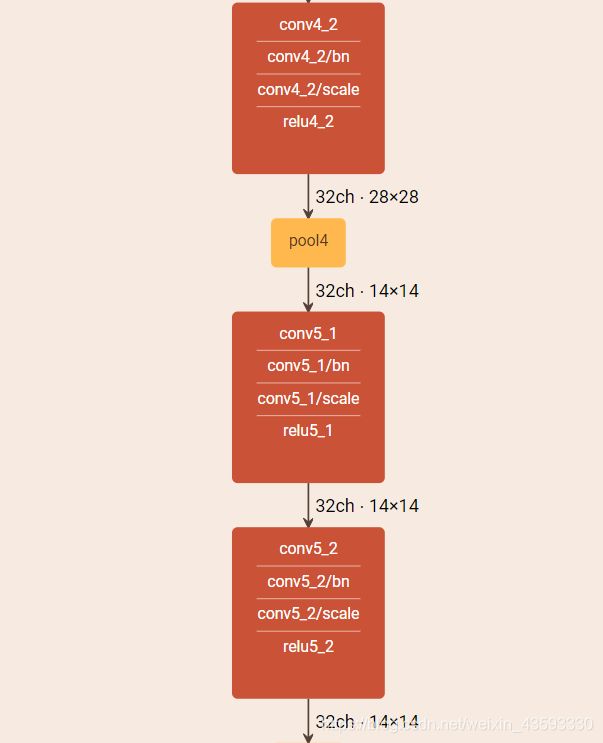
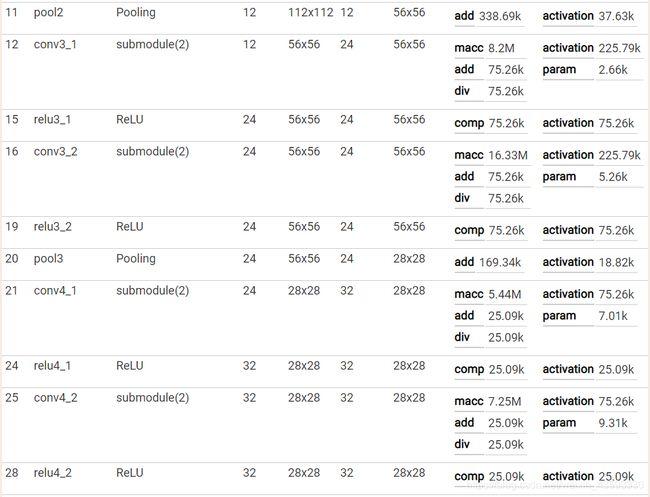
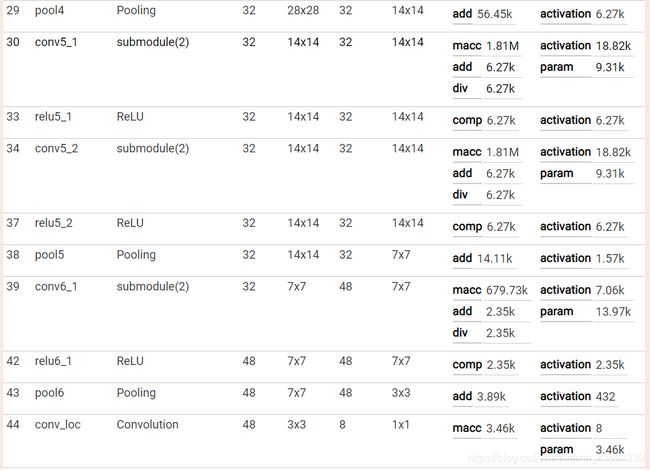
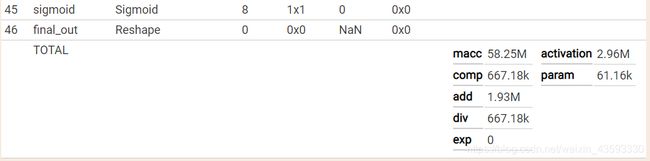
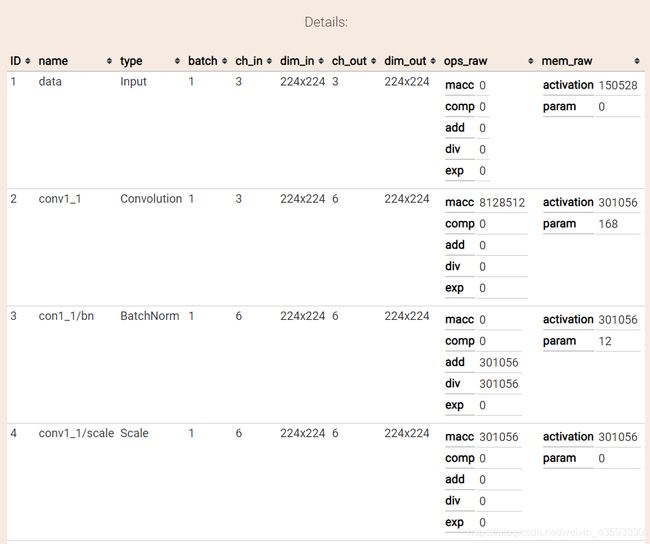
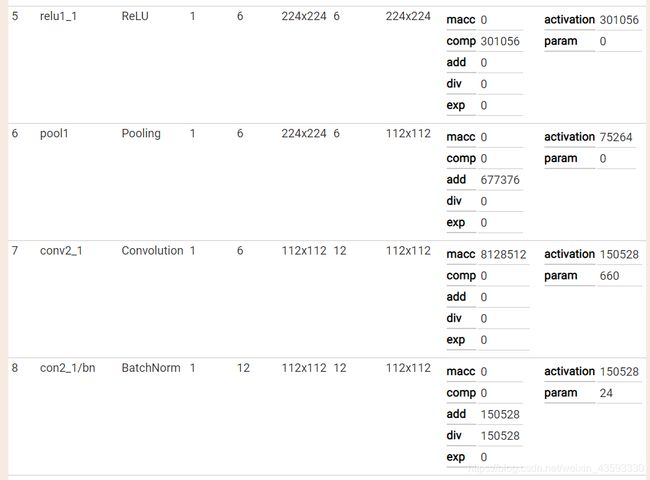
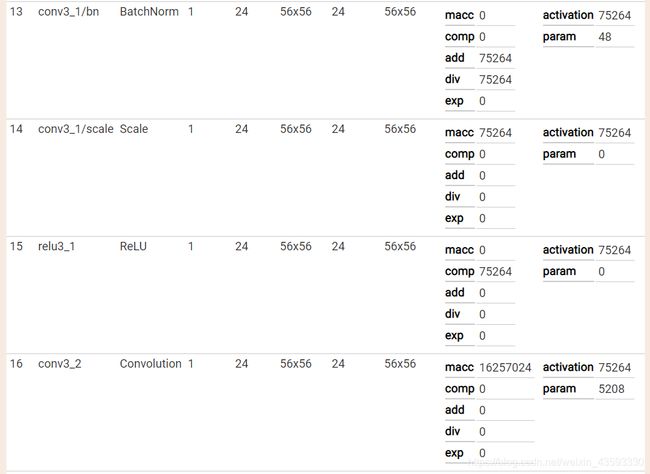
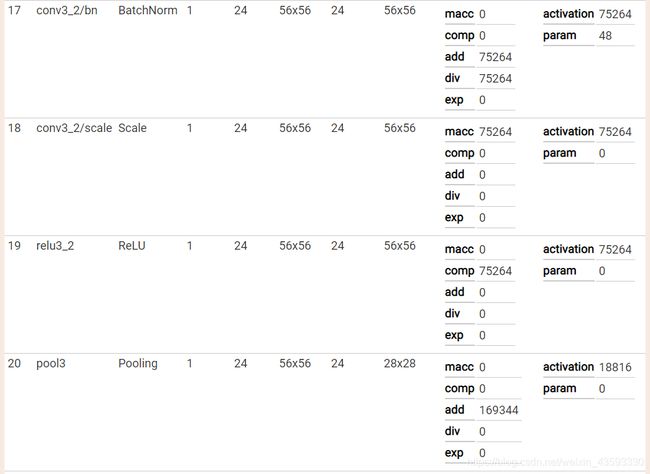
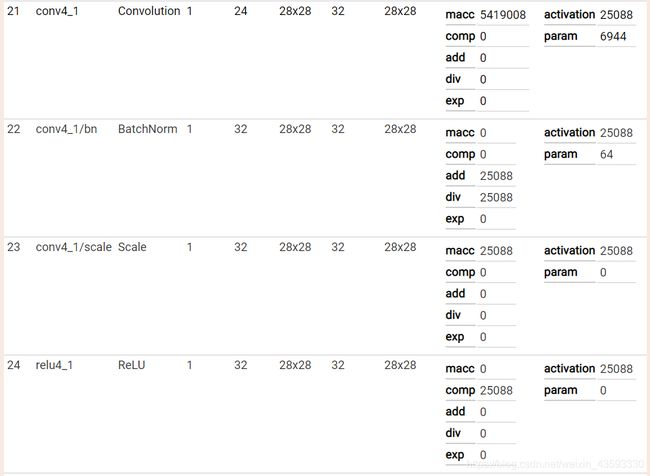
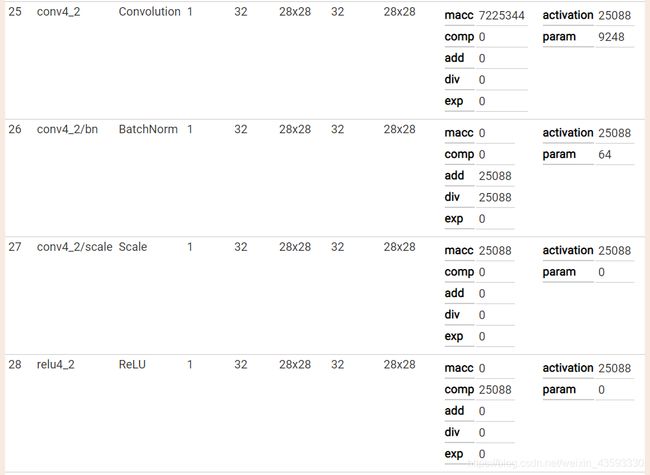
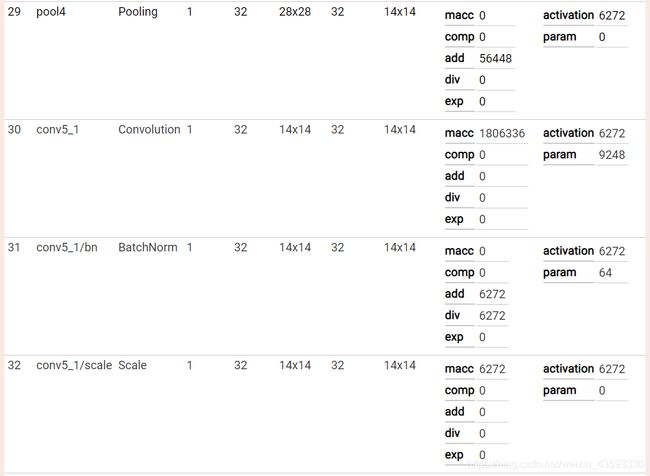
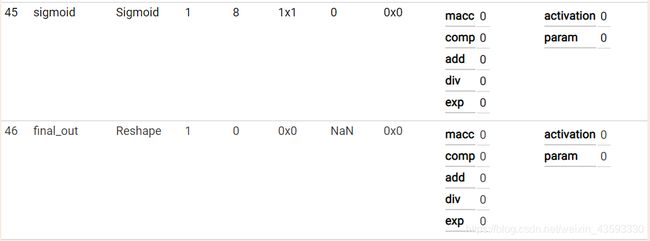
caffe网络结构可视化
可视化网址
http://dgschwend.github.io/netscope/#/editor
deploy_vgg11_regression.prototxt
# Enter your network definition here.
# Use Shift+Enter to update the visualization.
###----------------
name: "vgg11_regression_posture"
layer {
name: "data"
type: "Input"
top: "data"
input_param {
shape: {
dim: 1
dim: 3
dim: 224
dim: 224
}
}
}
layer {
name: "conv1_1"
type: "Convolution"
bottom: "data"
top: "conv1_1"
convolution_param {
num_output: 6
pad: 1
kernel_size: 3
stride: 1
}
}
layer {
name: "con1_1/bn"
type: "BatchNorm"
bottom: "conv1_1"
top: "conv1_1"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
batch_norm_param {
moving_average_fraction: 0.999000012875
eps: 9.99999993923e-09
synchronize: true
}
}
layer {
name: "conv1_1/scale"
type: "Scale"
bottom: "conv1_1"
top: "conv1_1"
param {
lr_mult: 1.0
decay_mult: 0.000
}
param {
lr_mult: 1.0
decay_mult: 0.000
}
scale_param {
filler {
type: "constant"
value: 1.0
}
bias_term: true
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "relu1_1"
type: "ReLU"
bottom: "conv1_1"
top: "conv1_1"
}
layer {
bottom: "conv1_1"
top: "pool1"
name: "pool1"
type: "Pooling"
pooling_param {
kernel_size: 3
stride: 2
pool: AVE
}
}
###----------------
layer {
name: "conv2_1"
type: "Convolution"
bottom: "pool1"
top: "conv2_1"
convolution_param {
num_output: 12
pad: 1
kernel_size: 3
stride: 1
}
}
layer {
name: "con2_1/bn"
type: "BatchNorm"
bottom: "conv2_1"
top: "conv2_1"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
batch_norm_param {
moving_average_fraction: 0.999000012875
eps: 9.99999993923e-09
synchronize: true
}
}
layer {
name: "conv2_1/scale"
type: "Scale"
bottom: "conv2_1"
top: "conv2_1"
param {
lr_mult: 1.0
decay_mult: 0.000
}
param {
lr_mult: 1.0
decay_mult: 0.000
}
scale_param {
filler {
type: "constant"
value: 1.0
}
bias_term: true
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "relu2_1"
type: "ReLU"
bottom: "conv2_1"
top: "conv2_1"
}
layer {
bottom: "conv2_1"
top: "pool2"
name: "pool2"
type: "Pooling"
pooling_param {
kernel_size: 3
stride: 2
pool: AVE
}
}
###----------------
layer {
name: "conv3_1"
type: "Convolution"
bottom: "pool2"
top: "conv3_1"
convolution_param {
num_output: 24
pad: 1
kernel_size: 3
stride: 1
}
}
layer {
name: "conv3_1/bn"
type: "BatchNorm"
bottom: "conv3_1"
top: "conv3_1"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
batch_norm_param {
moving_average_fraction: 0.999000012875
eps: 9.99999993923e-09
synchronize: true
}
}
layer {
name: "conv3_1/scale"
type: "Scale"
bottom: "conv3_1"
top: "conv3_1"
param {
lr_mult: 1.0
decay_mult: 0.000
}
param {
lr_mult: 1.0
decay_mult: 0.000
}
scale_param {
filler { 帮我
type: "constant"
value: 1.0
}
bias_term: true
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "relu3_1"
type: "ReLU"
bottom: "conv3_1"
top: "conv3_1"
}
layer {
name: "conv3_2"
type: "Convolution"
bottom: "conv3_1"
top: "conv3_2"
convolution_param {
num_output: 24
pad: 1
kernel_size: 3
stride: 1
}
}
layer {
name: "conv3_2/bn"
type: "BatchNorm"
bottom: "conv3_2"
top: "conv3_2"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
batch_norm_param {
moving_average_fraction: 0.999000012875
eps: 9.99999993923e-09
synchronize: true
}
}
layer {
name: "conv3_2/scale"
type: "Scale"
bottom: "conv3_2"
top: "conv3_2"
param {
lr_mult: 1.0
decay_mult: 0.000}
param {
lr_mult: 1.0
decay_mult: 0.000}
scale_param {
filler {
type: "constant"
value: 1.0
}
bias_term: true
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "relu3_2"
type: "ReLU"
bottom: "conv3_2"
top: "conv3_2"}
layer {
bottom: "conv3_2"
top: "pool3"
name: "pool3"
type: "Pooling"
pooling_param {
kernel_size: 3
stride: 2
pool: AVE
}
}
###----------------
layer {
name: "conv4_1"
type: "Convolution"
bottom: "pool3"
top: "conv4_1"
convolution_param {
num_output: 32
pad: 1
kernel_size: 3
stride: 1
}
}
layer {
name: "conv4_1/bn"
type: "BatchNorm"
bottom: "conv4_1"
top: "conv4_1"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
batch_norm_param {
moving_average_fraction: 0.999000012875
eps: 9.99999993923e-09
synchronize: true
}
}
layer {
name: "conv4_1/scale"
type: "Scale"
bottom: "conv4_1"
top: "conv4_1"
param {
lr_mult: 1.0
decay_mult: 0.000
}
param {
lr_mult: 1.0
decay_mult: 0.000
}
scale_param {
filler { type: "constant" value: 1.0}
bias_term: true
bias_filler { type: "constant" value: 0.0}}}
layer {
name: "relu4_1"
type: "ReLU"
bottom: "conv4_1"
top: "conv4_1"
}
layer {
name: "conv4_2"
type: "Convolution"
bottom: "conv4_1"
top: "conv4_2"
convolution_param {
num_output: 32
pad: 1
kernel_size: 3
stride: 1
}
}
layer {
name: "conv4_2/bn"
type: "BatchNorm"
bottom: "conv4_2"
top: "conv4_2"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0}
batch_norm_param {
moving_average_fraction: 0.999000012875
eps: 9.99999993923e-09
synchronize: true
}
}
layer {
name: "conv4_2/scale"
type: "Scale"
bottom: "conv4_2"
top: "conv4_2"
param {
lr_mult: 1.0
decay_mult: 0.000}
param {
lr_mult: 1.0
decay_mult: 0.000
}
scale_param {
filler {
type: "constant"
value: 1.0
}
bias_term: true
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "relu4_2"
type: "ReLU"
bottom: "conv4_2"
top: "conv4_2"
}
layer {
bottom: "conv4_2"
top: "pool4"
name: "pool4"
type: "Pooling"
pooling_param {
kernel_size: 3
stride: 2
pool: AVE
}
}
###----------------
layer {
name: "conv5_1"
type: "Convolution"
bottom: "pool4"
top: "conv5_1"
convolution_param {
num_output: 32
pad: 1
kernel_size: 3
stride: 1
}
}
layer {
name: "conv5_1/bn"
type: "BatchNorm"
bottom: "conv5_1"
top: "conv5_1"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
batch_norm_param {
moving_average_fraction: 0.999000012875
eps: 9.99999993923e-09
synchronize: true
}
}
layer {
name: "conv5_1/scale"
type: "Scale"
bottom: "conv5_1"
top: "conv5_1"
param {
lr_mult: 1.0
decay_mult: 0.000
}
param {
lr_mult: 1.0
decay_mult: 0.000
}
scale_param {
filler {
type: "constant"
value: 1.0
}
bias_term: true
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "relu5_1"
type: "ReLU"
bottom: "conv5_1"
top: "conv5_1"
}
layer {
name: "conv5_2"
type: "Convolution"
bottom: "conv5_1"
top: "conv5_2"
convolution_param {
num_output: 32
pad: 1
kernel_size: 3
stride: 1
}
}
layer {
name: "conv5_2/bn"
type: "BatchNorm"
bottom: "conv5_2"
top: "conv5_2"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0}
param {
lr_mult: 0.0
decay_mult: 0.0}
batch_norm_param {
moving_average_fraction: 0.999000012875
eps: 9.99999993923e-09
synchronize: true
}
}
layer {
name: "conv5_2/scale"
type: "Scale"
bottom: "conv5_2"
top: "conv5_2"
param {
lr_mult: 1.0
decay_mult: 0.000}
param {
lr_mult: 1.0
decay_mult: 0.000}
scale_param {
filler {
type: "constant"
value: 1.0
}
bias_term: true
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "relu5_2"
type: "ReLU"
bottom: "conv5_2"
top: "conv5_2"
}
layer {
bottom: "conv5_2"
top: "pool5"
name: "pool5"
type: "Pooling"
pooling_param {
kernel_size: 3
stride: 2
pool: AVE
}
}
###----------------
layer {
name: "conv6_1"
type: "Convolution"
bottom: "pool5"
top: "conv6_1"
convolution_param {
num_output: 48
pad: 1
kernel_size: 3
stride: 1
}
}
layer {
name: "conv6_1/bn"
type: "BatchNorm"
bottom: "conv6_1"
top: "conv6_1"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
batch_norm_param {
moving_average_fraction: 0.999000012875
eps: 9.99999993923e-09
synchronize: true
}
}
layer {
name: "conv6_1/scale"
type: "Scale"
bottom: "conv6_1"
top: "conv6_1"
param {
lr_mult: 1.0
decay_mult: 0.000
}
param {
lr_mult: 1.0
decay_mult: 0.000
}
scale_param {
filler {
type: "constant"
value: 1.0}
bias_term: true
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "relu6_1"
type: "ReLU"
bottom: "conv6_1"
top: "conv6_1"}
layer {
bottom: "conv6_1"
top: "pool6"
name: "pool6"
type: "Pooling"
pooling_param {
kernel_size: 3
stride: 2
pool: AVE
}
}
###----------------
layer {
name: "conv_loc"
type: "Convolution"
bottom: "pool6"
top: "conv_loc"
convolution_param {
num_output: 8
pad: 0
kernel_size: 3
}
}
layer {
name: "sigmoid"
type: "Sigmoid"
bottom: "conv_loc"
top: "sigmoid"
}
layer {
name: "final_out"
type: "Reshape"
bottom: "sigmoid"
top: "final_out"
reshape_param {
shape {
dim: 0
dim: -1
}
}
}
可视化结果