AI Studio 项目
文章目录
- 1.项目概述
- 1.1用户界面
- 1.1.1 公开项目
- 1.1.1.1 公开项目-页面简介
- 1.1.1.2 公开项目-项目详情页
- 1.1.2 我的项目
- 1.1.2.1 我的项目-页面简介
- 1.1.2.2 我的项目-项目详情页
- 1.1.3 我的收藏
- 1.1.3.1 我的收藏-页面简介
- 1.1.3.2 我的收藏-项目详情页
- 1.2 创建并运行一个项目
- 1.2.1 项目创建
- 1.2.1.1 项目配置
- 1.2.1.2 添加数据集
- 1.2.2 Fork项目
- 1.2.3 收藏项目
- 2.Notebook项目
- 2.1 页面概览
- 2.2 创建并运行Notebook项目
- 2.3 VisualDL工具
- 3.Notebook环境使用说明
- 3.1 页面概览
- 3.2 菜单栏
- 3.3 快捷工具栏
- 3.4 编辑区 Code Cell
- 3.4.1 命令/编辑模式
- 3.4.2 Code Cell操作
- 3.5 编辑区 Markdown Cell
- 3.5.1 命令/编辑模式
- 3.5.2 Markdown Cell操作
- 3.6 终端
- 3.7 侧边栏
- 3.7.1 环境信息
- 3.7.2 文件夹
- 3.7.3 数据集
- 3.7.4 设置
- 3.8 状态监控区
- 3.8.1 环境变量
- 3.8.2 运行历史
- 3.9 快捷键操作
- 3.10 版本管理
- 3.10.1 创建版本
- 3.10.2 加载历史版本
- 3.10.3 分享项目内容
- 4. 脚本任务
- 4.1 脚本任务项目说明
- 4.2 创建脚本任务项目
- 4.3 页面概览
- 4.4 代码编辑
- 4.4.1 左侧文件管理和数据集
- 4.4.2 右侧文件预览编辑和提交任务
- 4.5 PaddlePaddle脚本任务训练说明
- 4.6 数据集与输出文件路径说明
- 4.7 提交任务
- 4.8 历史任务
- 4.9 空间说明
- 4.9.1 Python 2.7
- 4.9.2 python3.5.5
- 4.10 问题反馈
- 5. 图形化任务
- 5.1 图形化任务说明
- 5.2 创建图形化任务
- 5.3 图形化任务预览
- 5.4 预置算法部署后调用参数样例
- 5.4.1 线性回归的请求及返回说明
- 5.4.2 逻辑回归的请求及返回说明
- 5.4.3 图像分类的请求及返回说明
- 5.4.4 目标检测的请求及返回说明
- 5.5 内置数据集说明及下载地址
- 6. 在线部署及预测
- 6.1 功能说明
- 6.2 通过训练任务生成模型文件
- 6.3 创建一个在线服务
- 6.3.1 第一步 选择模型文件
- 6.3.2 第二步 确认输入输出
- 6.3.3 第三步 制作参数转换器
- 6.3.4 第四步 沙盒部署
- 6.4 测试沙盒服务
- 6.4.1 第一步 点击【测试】打开测试页面
- 6.4.2 第二步 填写json格式请求参数
- 6.4.3 第三步 点击【发送】检验返回结果
- 6.5 部署在线服务
- 6.6 调用在线服务
- 6.6.1 请求方式
- 6.6.2 调用示例
- 参考:
1.项目概述
1.1用户界面

本页亦即项目大厅页, 用于创建, 管理, 查看各种项目。项目管理栏分为三部分内容: a. 平台公开项目; b. 用户自己创建项目; c. 用户收藏的项目.
1.1.1 公开项目
1.1.1.1 公开项目-页面简介

- 创建项目入口,用户可创建不同类别项目
![]()
- 项目分类排序和搜索栏,可按项目专题、项目类型、项目标签和综合排序进行项目排序;也可直接在右侧的搜索栏进行项目名称的搜索.

-
项目信息栏,可看出作者、类型、标签、
fork和收藏次数及公开时间.
-
右上的百度推荐学习项目栏,按项目热度给出推荐,方便您的学习.

- 右下的飞桨热门模型项目栏,按项目热度给出推荐,方便您的学习.
-
底部的项目页栏,可进行翻页查看操作.

1.1.1.2 公开项目-项目详情页
点击单个项目可进入项目详情页.
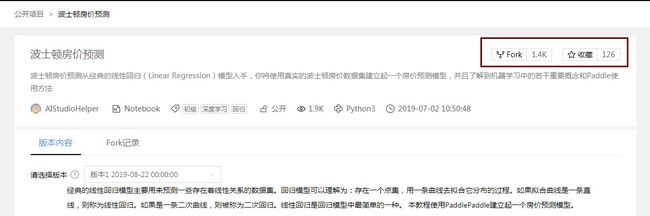
红色框中两个按钮,左侧表示fork该项目,右侧表示收藏该项目.
1.1.2 我的项目
1.1.2.1 我的项目-页面简介
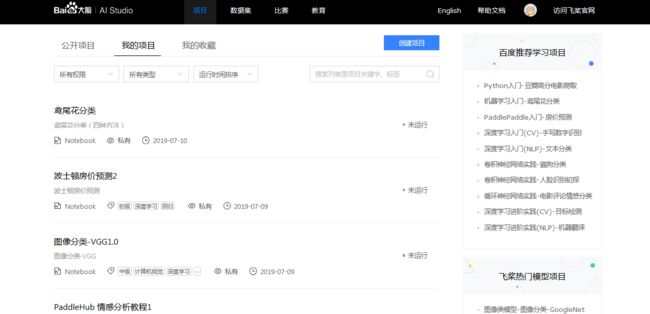
- 项目分类排序和搜索栏,可按所有权限、所有类型和运行时间进行项目排序;也可直接在右侧的搜索栏进行项目名称的搜索。
![]()
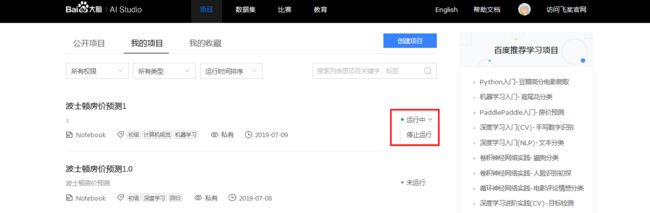
- 查看项目运行状态信息,运行中的项目可快速停止运行.
1.1.2.2 我的项目-项目详情页
- 点击单个项目可进入项目详情页.
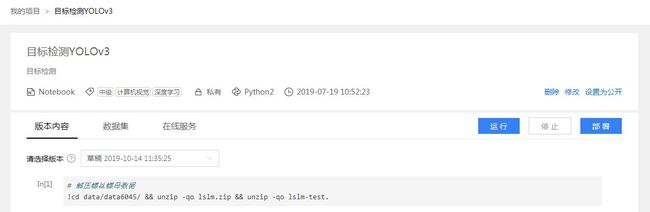
- 支持项目的删除、修改及设置为公开.

- 支持项目的运行、停止和部署

1.1.3 我的收藏
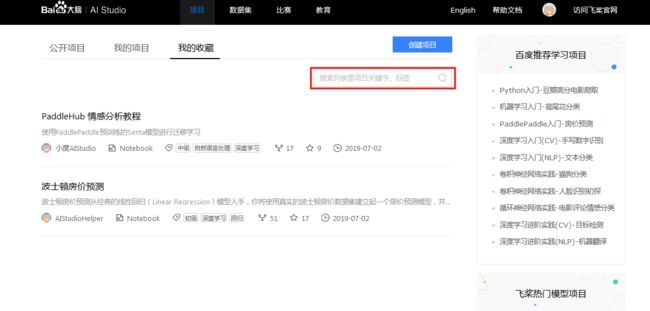
1.1.3.1 我的收藏-页面简介
- 可直接在右侧的搜索栏进行项目名称的搜索.
1.1.3.2 我的收藏-项目详情页
- 点击单个项目可进入项目详情页.
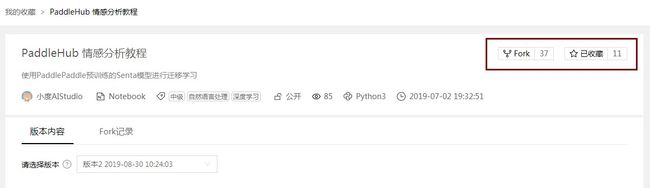
红色框中两个按钮,左侧表示fork该项目,点击右侧蓝色按钮置灰可取消收藏该项目.
1.2 创建并运行一个项目
1.2.1 项目创建
1.2.1.1 项目配置
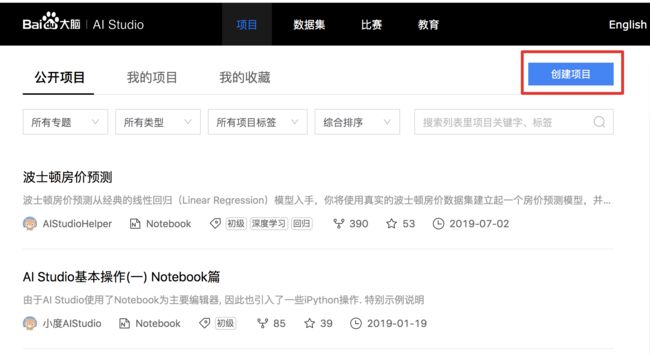
1、项目大厅页, 点击「创建项目」: 
2、则出现创建项目的窗口: 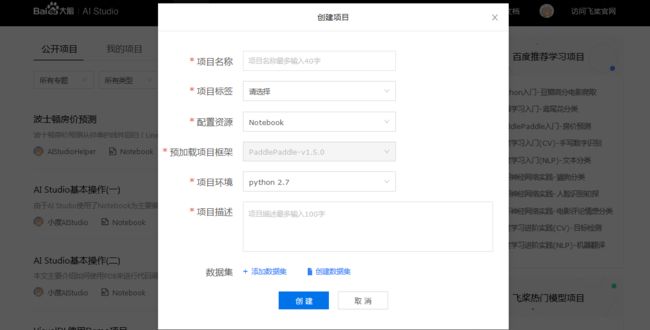
- 项目名称: 用来标识项目, 便于日后进行查找和管理, 创建后支持修改.
- 项目标签: 定义项目属性,最多可选择五个标签,滑动右侧滑动条查看所有标签类别,选择完毕点击确认.
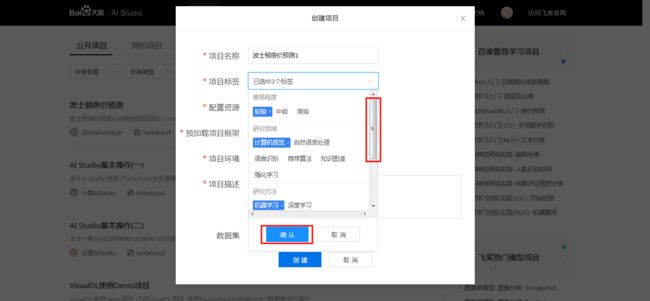
- 配置资源: 程序部署运行环境, 包括Notebook、脚本任务和图像化任务,点击查看详情.
- 预加载项目框架: 深度学习开发框架, 支持
PaddlePaddle多种版本, 未来我们也将集成更多的开发框架. - 项目环境: 语言基础环境, 包括
Python 2.7(默认),Python3.5. - 项目描述: 描述项目背景、用途等, 创建后支持修改.
若无需数据集,可由1、2操作后直接跳转5.
1.2.1.2 添加数据集
3、如果项目涉及到数据集, 可以考虑直接使用系统预置的数据集, 点击「添加数据集」 ![]()
4、然后: 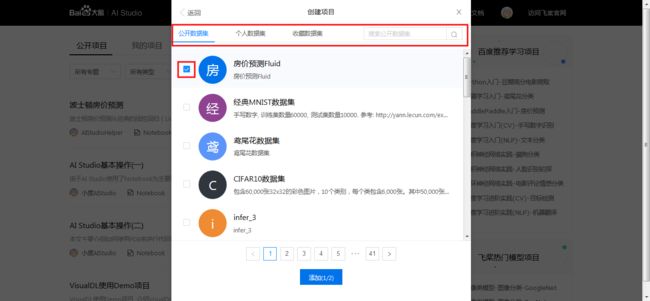
- 数据集分类排序,包括公开数据集、个人数据集和收藏数据集, 同时支持数据集搜索.
- 勾选所需数据集.
- 选择完毕点击添加. 每个项目最多可以引入两个数据集, 便于模型比较在不同数据集下的准确率和召回率. 如无合适的数据集, 用户也可以自行上传创建新数据集.
5、最后点击「创建」并在弹出框中选择「查看」进入项目详情页. 
之后在项目详情页, 对项目进行编辑, 可以对数据集进行变更.
1.2.2 Fork项目
如果不熟悉操作, 则可以直接Fork项目大厅的公开项目,可直接运行,加快学习速度.
1、点击红框内的图标进行Fork. 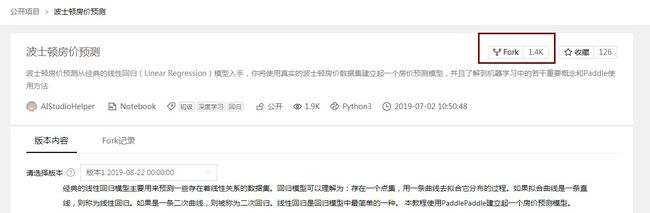
2、填写项目名称和项目描述后点击「创建」,创建成功后此项目将存在于“我的项目”一栏. 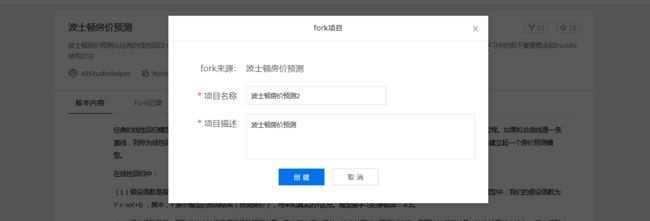
3、点击「运行项目」进入项目详情. 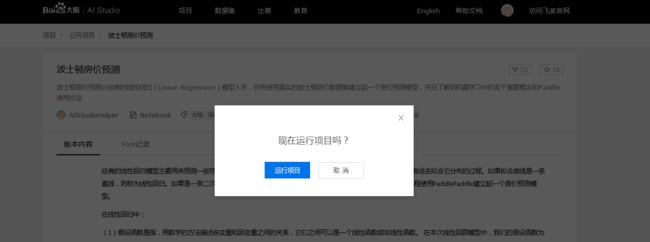
1.2.3 收藏项目
如果对某个公开项目特别钟意,则可以直接收藏,方便以后的查看.
1、点击红框内的图标进行收藏. 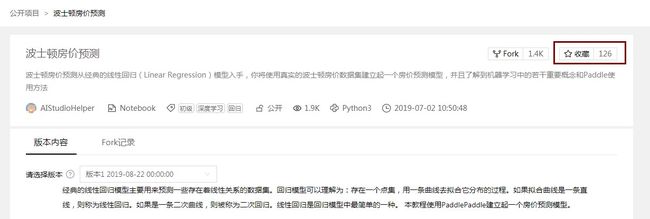
2、图标变为已收藏即收藏成功,收藏成功的项目将存在于“我的收藏”一栏. 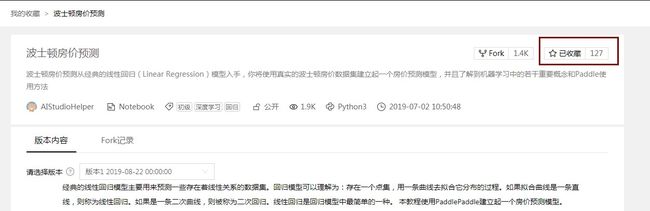
2.Notebook项目
2.1 页面概览
2.2 创建并运行Notebook项目
1、点击项目大厅页面的「创建项目」.

2、选择Notebook项目,完善项目信息,点击「创建」.
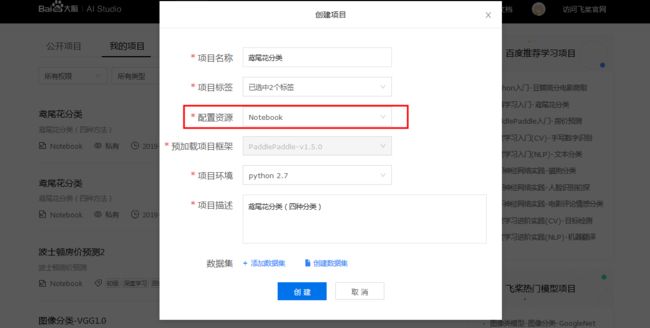
3、项目创建成功,点击「查看」.
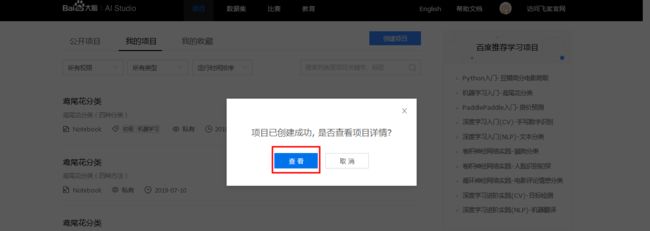
4、至我的项目-项目详情页
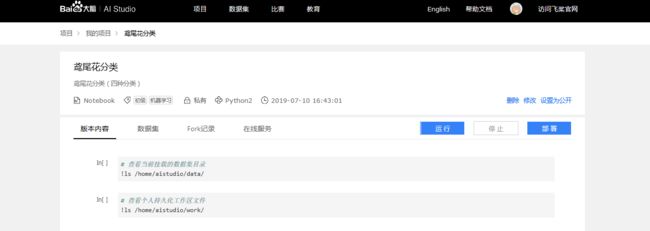
- 项目删除、修改及设置为公开项目操作.

- 版本内容: 展示当前
Notebook最新内容. - 数据集:支持部分数据类型预览.
Fork记录: 项目被其他人Fork的记录.- 在线服务: 用于预测服务.
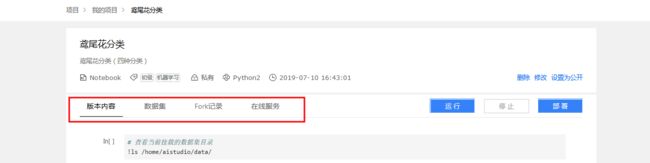
- 项目启停与部署操作.
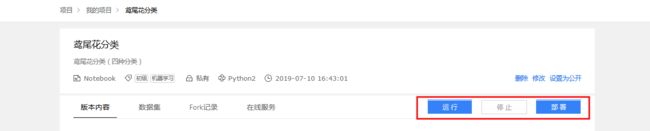
5、点击右方「运行」进行项目环境选择.
- 支持基础版(
CPU环境)与高级版(GPU环境)两种模式选择,默认为基础版,选择完毕点击确认.
6、点击「确定」跳转到项目代码在线编辑Notebook环境,Notebook使用说明详见下一节《项目大厅-Notebook环境使用说明》,代码编辑完成后点击运行,保存之后可在我的项目-项目详情页查看最新版本内容,即如本文档页面概览所示。
2.3 VisualDL工具
VisualDL是一个面向深度学习任务设计的可视化工具,包含了scalar、参数分布、模型结构、图像可视化等功能. AI Studio单机项目已经集成VisualDL工具, Notebook代码编写请参考文档如何在PaddlePaddle中使用VisualDL.
- Step1 训练代码中增加
Loggers来记录不同种类的数据. 注意我们的logdir = "./log", 即需要把log目录放到/home/aistudio/log.
# create VisualDL logger and directory
logdir = "./log"
logwriter = LogWriter(logdir, sync_cycle=10)
# create 'train' run
with logwriter.mode("train") as writer:
# create 'loss' scalar tag to keep track of loss function
loss_scalar = writer.scalar("loss")
- Step2 使用
PaddlePaddle API创建训练训练模型.
def vgg16_bn_drop(input):
pass
- Step3 开始训练并且同时用
VisualDL来采集相关数据
# add record for loss and accuracy to scalar
loss_scalar.add_record(step, loss)
- Step4 在
Web浏览器中输入URL访问.
URL生成规则: 将项目地址中的notebooks及之后部分替换为visualdl.
# Notebooks项目访问URL
url_notebook = 'http://aistudio.baidu.com/user/30799/33852/notebooks/33852.ipynb?redirects=1'
# 替换后visualdl访问URL
url_visualdl = 'http://aistudio.baidu.com/user/30799/33852/visualdl'
3.Notebook环境使用说明
3.1 页面概览
Notebook是用户运行Notebook类型的项目后,在浏览器端所看到的交互式编程界面。
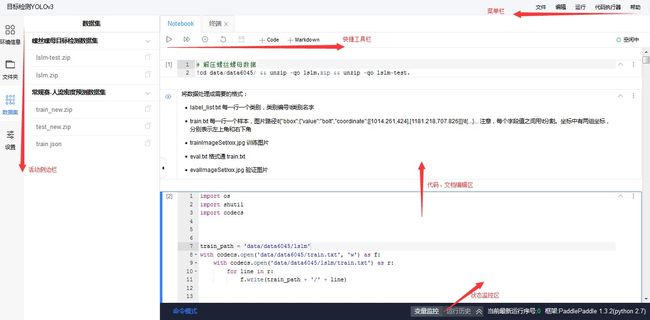
Notebook由以下这几个部分构成:
- 菜单栏
- 快捷工具栏
- 代码编辑区
Code Cell - 代码编辑区
Markdown Cell - 侧边栏
- 状态监控区
以下对每个部分的操作分别说明.
3.2 菜单栏
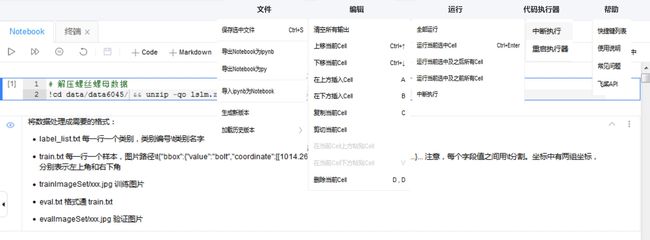
-
文件 :对整体项目文件的操作.
- 保存选中文件: 保存当前Notebook文件(仅保存Notebook文件). - 导出Notebook文件为ipynb: 将Notebook下载为ipynb文件在本地jupyter环境直接运行. - 导出Notebook为py: 将Notebook下载为py文件并通过shell命令执行. - 导入ipynb为Notebook: 将本地编写好的ipynb文件直接上传到Notebook环境中运行. 文件导入为覆盖式导入, 请慎重操作. - 生成新版本: 为了更好的管理项目内容, 或进行公开项目等操作, 需要提前生成版本. 版本即为Notebook文件加上一定数量附件的集合. 一个项目下最多可以有5个版本. 当生成更多版本时, 将进行循环覆盖(最新版本覆盖掉最老版本). - 加载历史版本: 用户可以使用历史版本来覆盖掉当前环境的全部内容, 实现版本回滚. 该操作为全量操作(即清空当前全部内容及文件, 然后将历史版本全部文件导入), 请慎重操作. -
编辑 :对
cell单元的操作. -
运行 :不同方式的
cell运行命令. -
代码执行器 :对环境的操作。
中断:中断
cell运行.重启环境:清空环境缓存变量和环境输出. 全部运行
cell前建议先执行此操作. -
帮助 :使用帮助,包括快捷键、使用说明、常见问题和飞桨
API.
3.3 快捷工具栏

- 运行 :运行某个
code cell. - 全部运行 :运行全部
code cell. - 中断 :中断运行某个
code cell. - 重启 :重启环境,清空环境中的环境变量、缓存变量、输出结果.
- 保存 :保存
Notebook项目文件.
3.4 编辑区 Code Cell
Code Cell是Notebook的代码编写单元。用户在Code Cell内编写代码(支持Python2、Python3)和shell命令,代码/命令在云端执行,并返回结果到Code Cell.
3.4.1 命令/编辑模式
绿色代表块内容可编辑状态-编辑模式(比如输入代码),蓝色代表块可操作状态-命令模式(比如删除Cell,必须回到蓝色),与linux编辑器vi/vim类似,编辑模式和命令模式之间可以用Esc和Enter来切换。
- 编辑模式
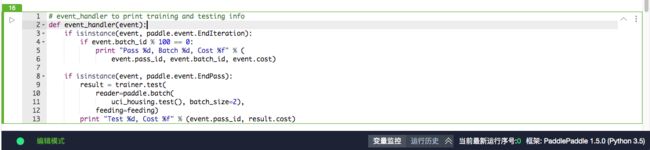
- 命令模式
3.4.2 Code Cell操作

-
新建
Cell从快捷工具栏中新建
Code Cell
![]()
hover在Cell间隙区域新建Code Cell

- 运行
Cell

运行中状态:
![]()
运输后结果输出:

运输后结果输出结果过长时:

-
中止
Cell运行如果发现代码并不尽如人意, 可以点击中断按钮, 打断所有
Cell代码的执行
- 折叠
Cell
![]()
- 其他操作

-
Linux命令运行
Linux命令的方式是在Linux命令前加一个!,就可以在块里运行示例1:安装第三方包

示例2: 查看当前环境中的Python版本和Paddle版本

-
Magic关键字Magic关键字是可以运行特殊的命令。Magic命令的前面带有一个或两个百分号(%或%%), 分别代表行Magic命令和Cell Magic命令。行Magic命令仅应用于编写Magic命令时所在的行, 而Cell Magic命令应用于整个Cell.
| Magic关键字 | 含义 |
|---|---|
%timeit |
测试单行语句的执行时间 |
%%timeit |
测试整个块中代码的执行时间 |
%matplotlib inline |
显示matplotlib 包生成的图形 |
%run |
调用外部python脚本 |
%pdb |
调试程序 |
%pwd |
查看当前工作目录 |
%ls |
查看目录文件列表 |
%reset |
清除全部变量 |
%who |
查看所有全局变量的名称,若给定类型参数,只返回该类型的变量列表 |
%whos |
显示所有的全局变量名称、类型、值/信息 |
%xmode Plain |
设置为当异常发生时只展示简单的异常信息 |
%xmode Verbose |
设置为当异常发生时展示详细的异常信息 |
%debug |
bug调试,输入quit退出调试 |
%bug |
调试,输入quit退出调试 |
%env |
列出全部环境变量 |
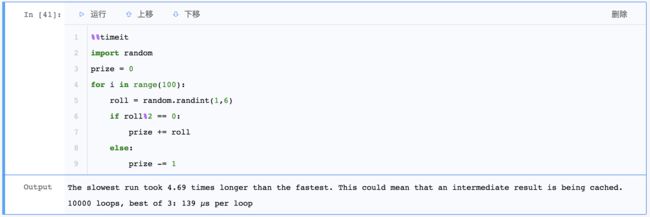
示例1: 使用%%timeit测算整个块的运行时间.
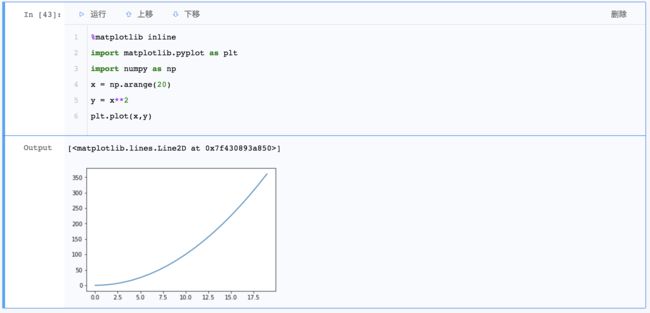
示例2: 块可集成Matplotlib,从而进行绘图, 但需要注意绘图前需要输入%Matplotlib inline并运行, 否则即使运行终端可用的绘图代码段,cell也只会返回一个文件说明, 如下图所示
示例3: 查看所有支持的Magic关键字.

3.5 编辑区 Markdown Cell
Markdown Cell是Notebook中文本编辑单元,通过在Markdown Cell中输入Markdown格式的文本,可以编写文字教程说明.
3.5.1 命令/编辑模式
绿色代表块内容可编辑状态-编辑模式(比如输入文字),蓝色代表块可操作状态-命令模式(预览md展示样式),编辑模式和命令模式之间可以用Esc和Enter来切换。
- 编辑模式

- 命令模式(预览样式)

3.5.2 Markdown Cell操作
- 新建
Cell从快捷工具栏中新建Markdown Cell

hover在Cell间隙区域新建Markdown Cell

- 编辑
Cell支持插入公式、表格、图片、音乐、视频、网页等. 相关Markdown用法可以参考Markdown官网.

3.6 终端
用户可以使用终端来进行一些操作, 与Notebook主界面并行, 例如查询GPU占用率或进行文本编辑.
注意:
Terminal未开放sudo权限.- 当前
Terminal下还未安装pip,vim. - 如果需要编辑文本文件可以使用
Emacs.
3.7 侧边栏
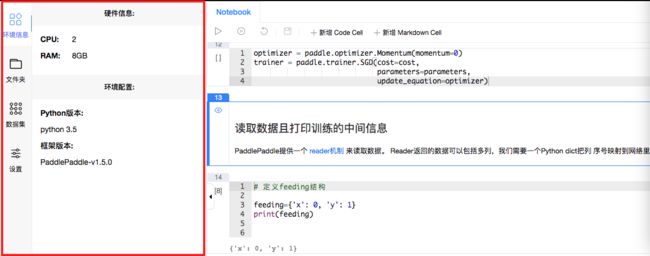
3.7.1 环境信息
展示环境硬件和软件信息
3.7.2 文件夹
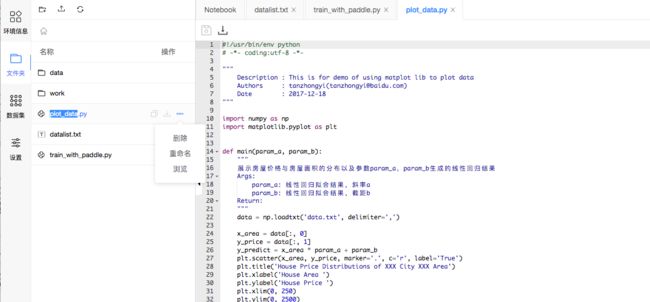
按照树形结构展示/home/aistudio路径下的文件夹和文件。可以在该目录下进行如下操作:
- 文件夹操作: 创建新的文件夹. 鼠标悬浮在文件夹条目上, 会出现操作按钮, 包括删除文件夹、重命名文件夹、路径复制.
- 文件操作: 创建上传文件(上传的单个文件最大
20M). 鼠标悬浮在文件条目上, 会出现操作按钮, 包括下载文件、重命名文件、路径复制. - 更新操作:如果在代码运行过程中磁盘里的文件更新了,可以手动刷新, 在侧边栏查看文件更新的状态.
- 注意:
/home/aistudio/data是非持久化目录,请不要将您的文件放到该目录下,重启后,文件将会丢失.
3.7.3 数据集
在数据集栏中, 可以复制数据集文件的路径, 并置于代码中. 复制数据集路径成功则出现:
![]()
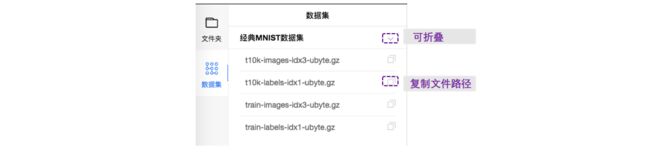
3.7.4 设置
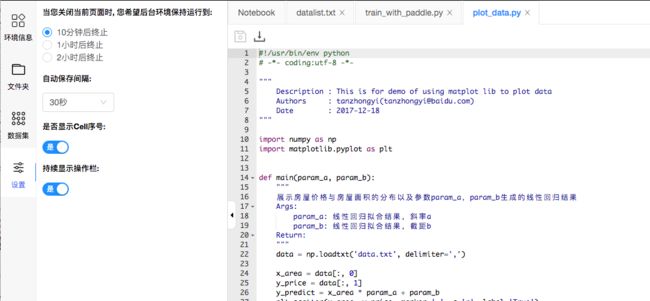
-
设置关闭后环境继续运行时间
您关闭
Notebook页面后,我们将继续为您保留一段时间的环境资源,代码将继续执行. 您可以通过设置配置希望在关闭网页后,环境继续运行的时间. -
设置环境自动保存时间
-
设置是否显示
Cell序号 -
设置操作栏是否展示
3.8 状态监控区
![]()
3.8.1 环境变量

3.8.2 运行历史

3.9 快捷键操作
- 常用操作列表
| 模式 | 内容 | 快捷键(Windows) | 快捷键(Mac) |
|---|---|---|---|
命令模式 (Esc切换) |
运行块 | Shift-Enter |
Shift-Enter |
| 命令模式 | 在下方插入块 | B |
B |
| 命令模式 | 在上方插入块 | A |
A |
| 命令模式 | 删除块 | d-d |
d-d |
| 命令模式 | 切换到编辑模式 | Enter |
Enter |
编辑模式 (Enter切换) |
运行块 | Shift-Enter |
Shift-Enter |
| 编辑模式 | 缩进 | Clrl-] |
`Command-] |
| 编辑模式 | 取消缩进 | Ctrl-[ |
Command-[ |
| 编辑模式 | 注释 | Ctrl-/ |
Command-/ |
| 编辑模式 | 函数内省 | Tab |
Tab |
- 全部操作说明
3.10 版本管理
3.10.1 创建版本
用户可以点击菜单"文件"->“生成版本”, 来生成一个新版本. 每个版本最少会包含一个Notebook文件, 而最大可以达到1GB, 可包含至多1000个附带文件.
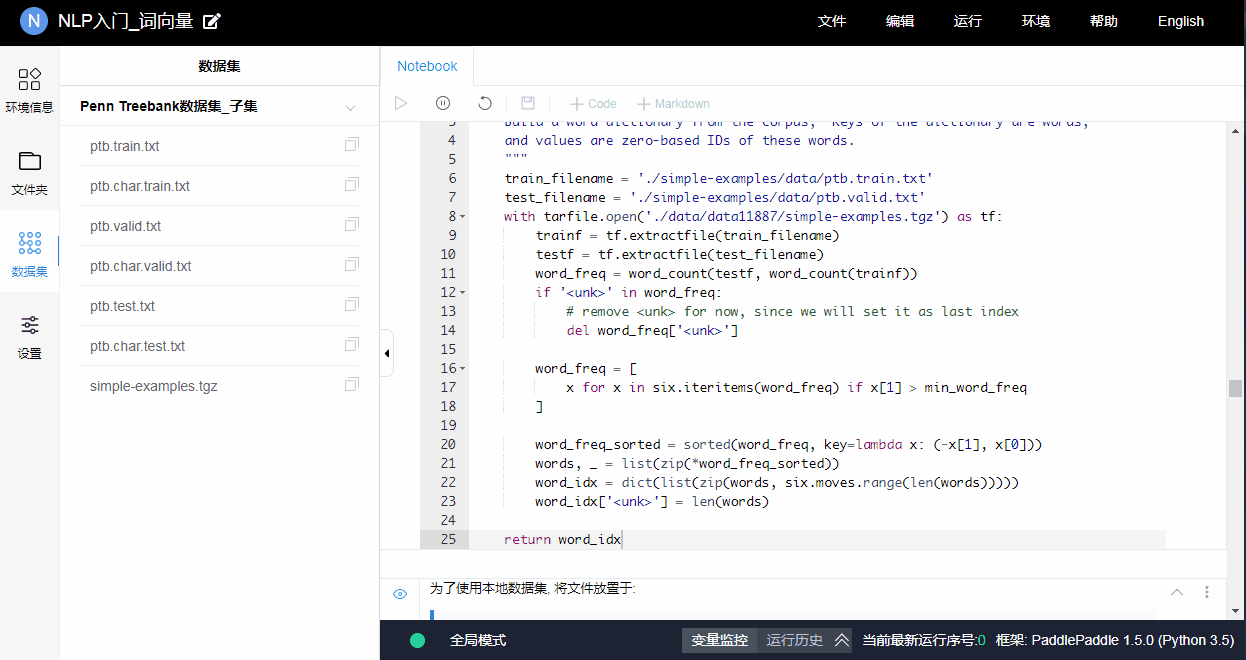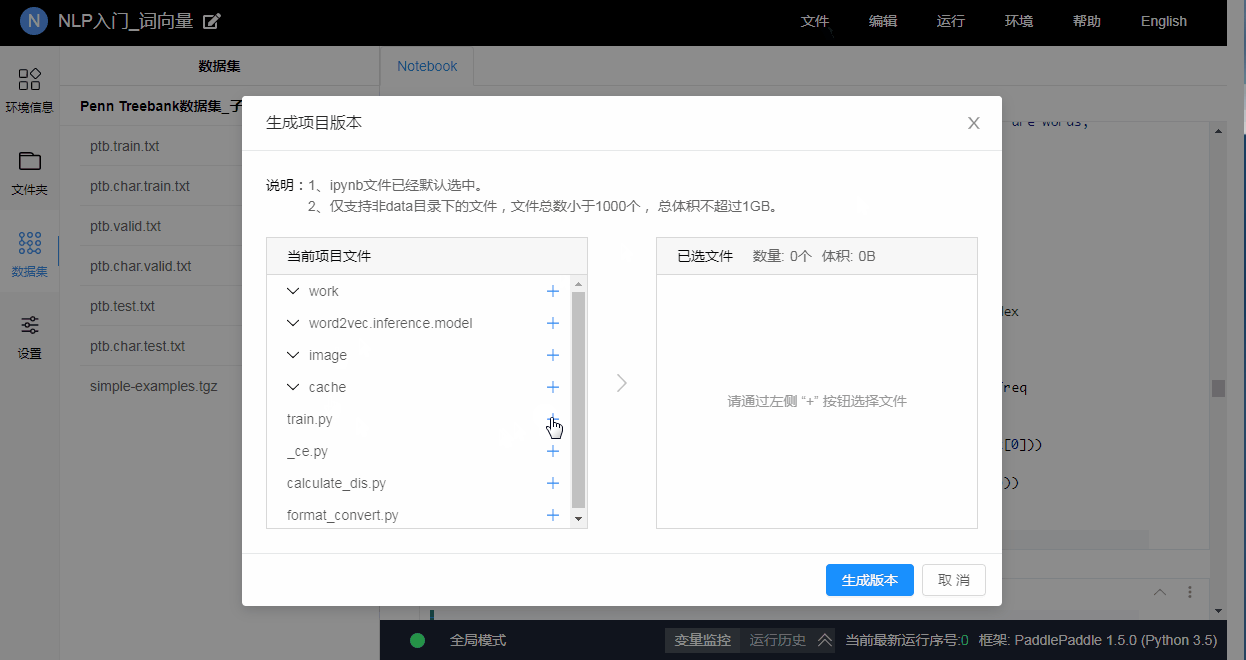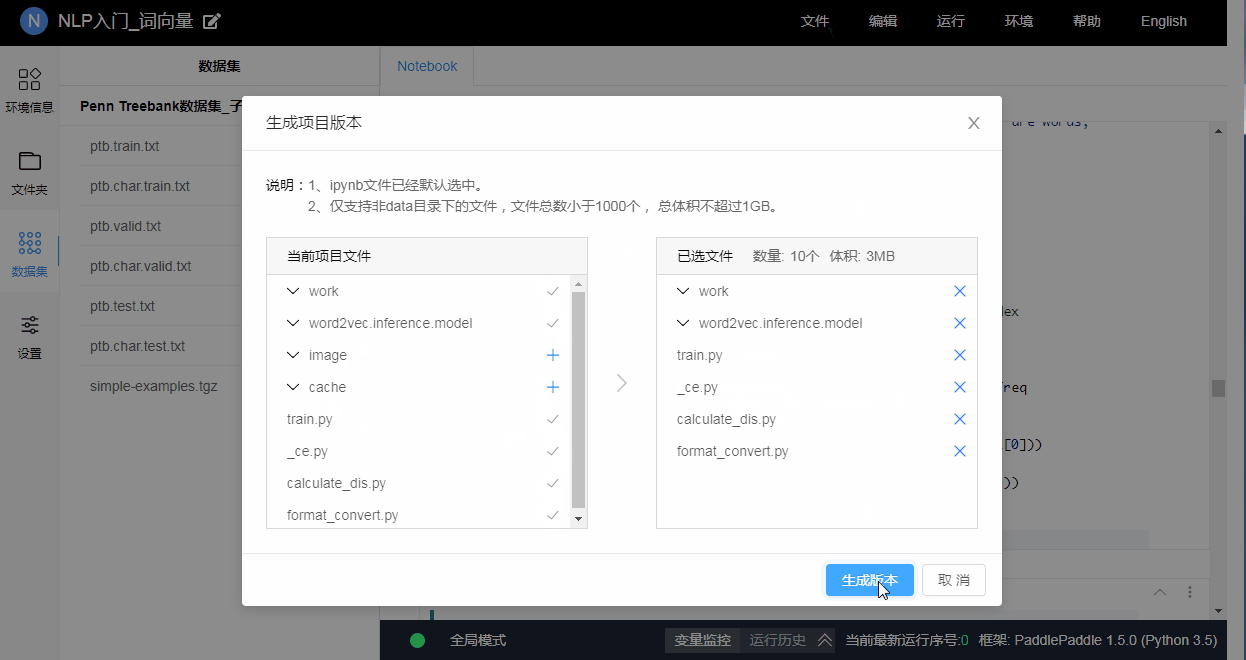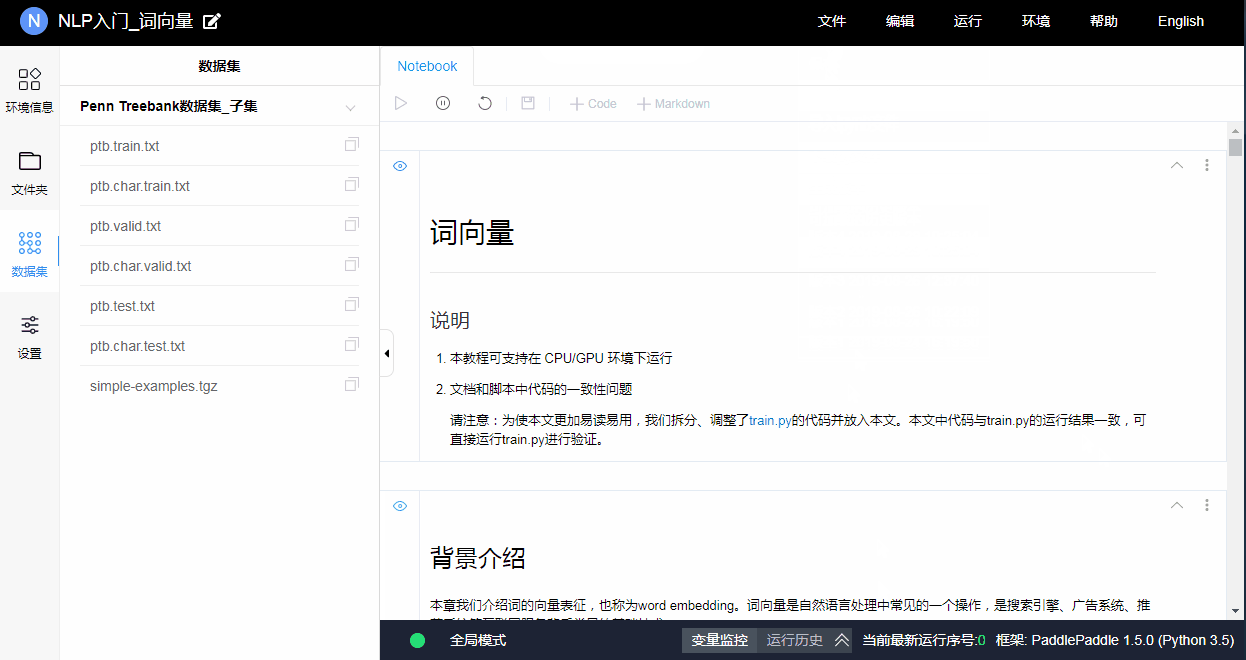
3.10.2 加载历史版本
用户正在编辑的内容会自动置为"草稿"版本, 如果用户对草稿版本的内容不满意, 可以重新加载历史上的版本以重新开始.
注意: 加载历史版本为全量操作, 即当前草稿版本的内容会被全部清空.
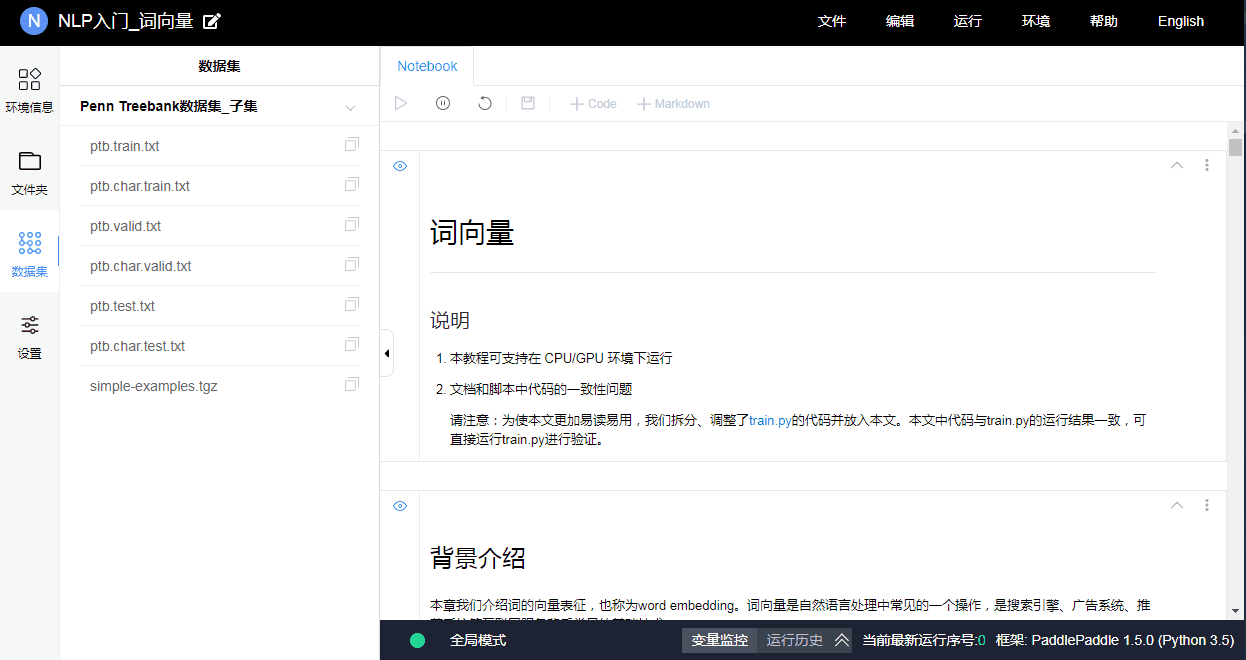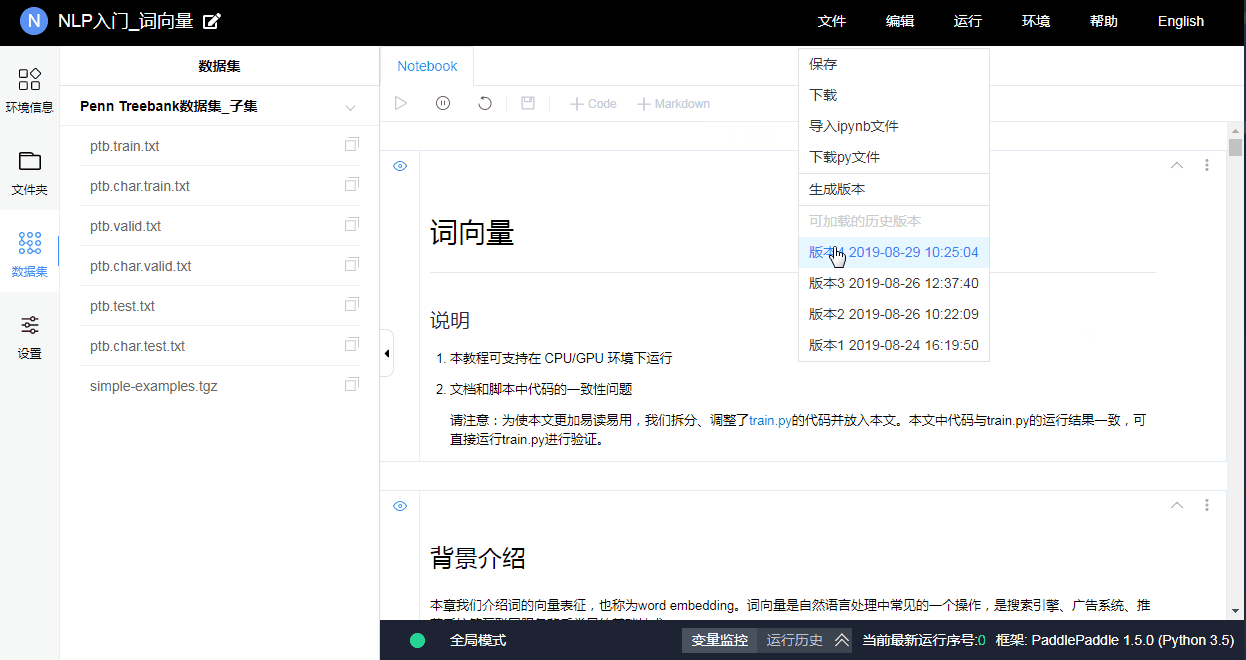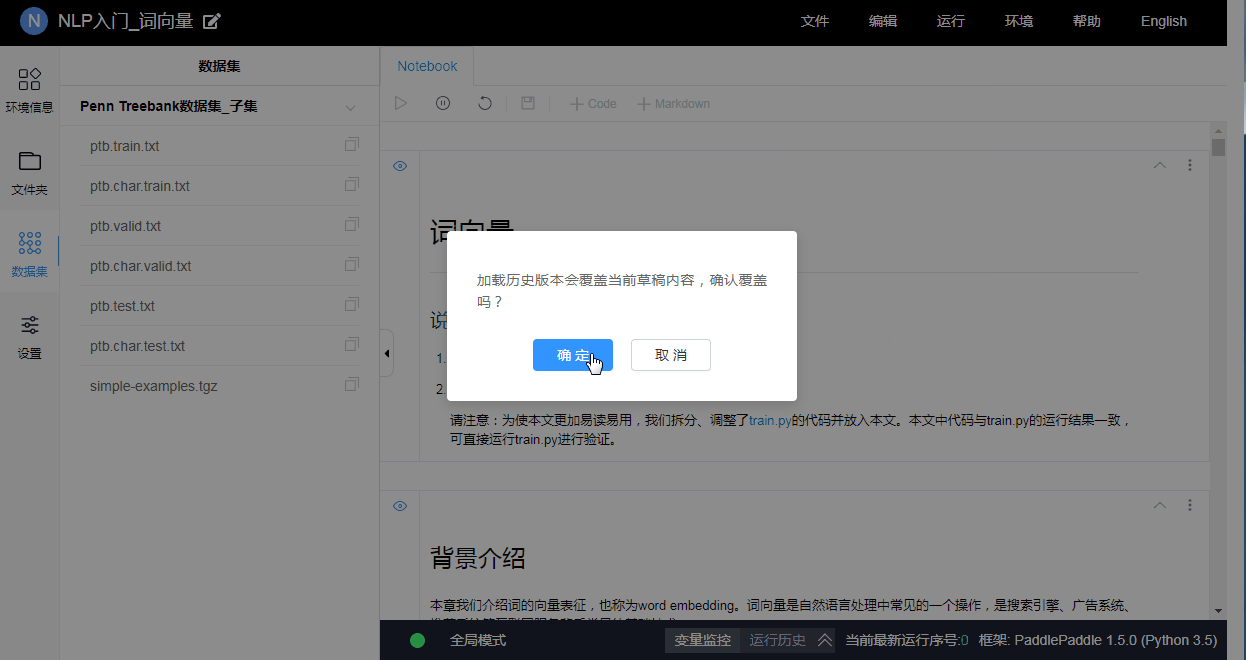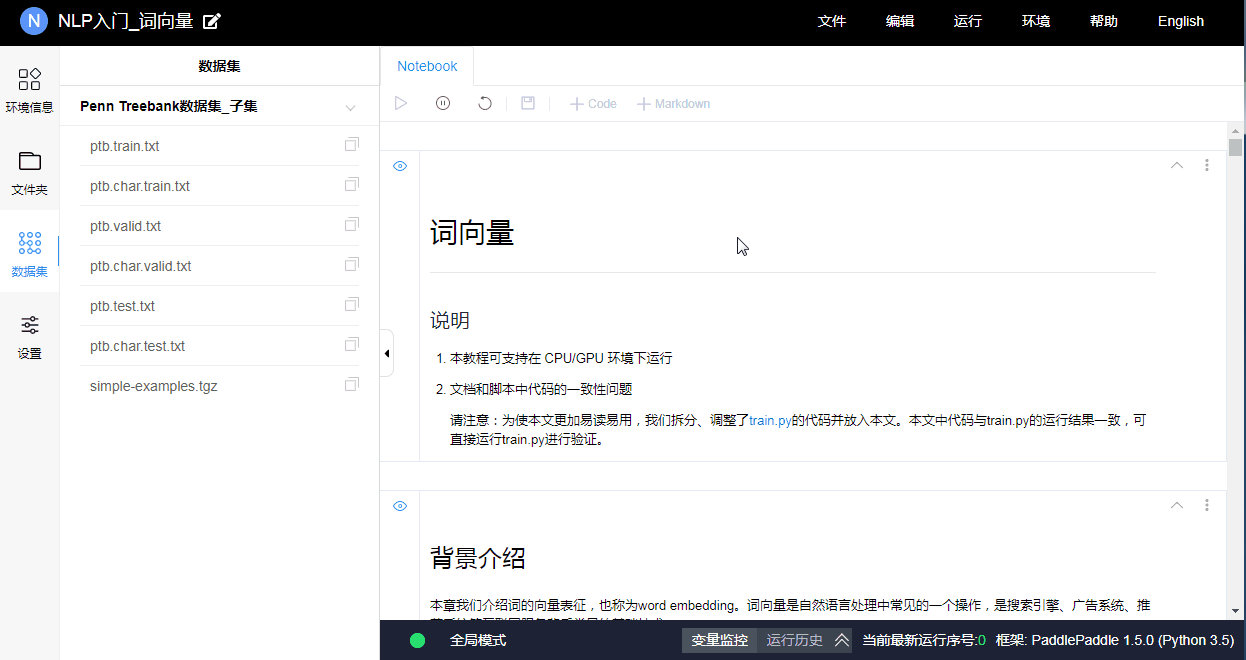
3.10.3 分享项目内容
Notebook项目在没有版本的时候无法公开, 此举是为了保证用户fork您的项目时, 可以获得完整的Notebook及其依赖文件, 这样其他用户才能顺利运行该项目.
- 下方为缺乏版本而不能公开的示例:
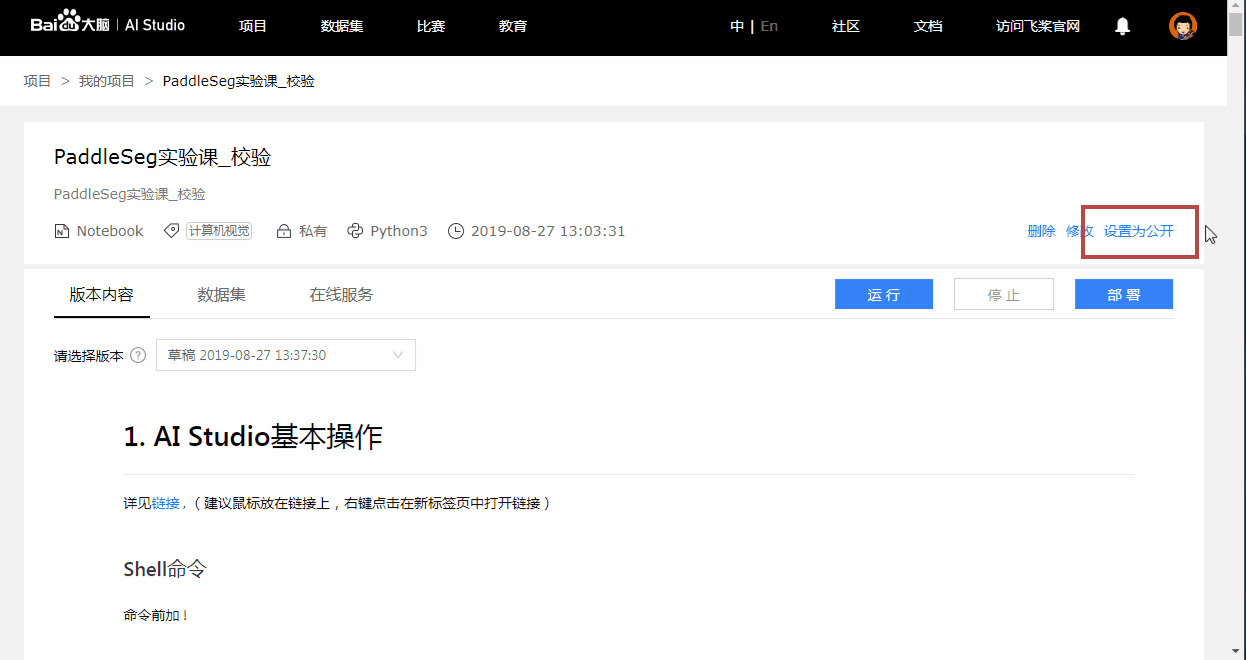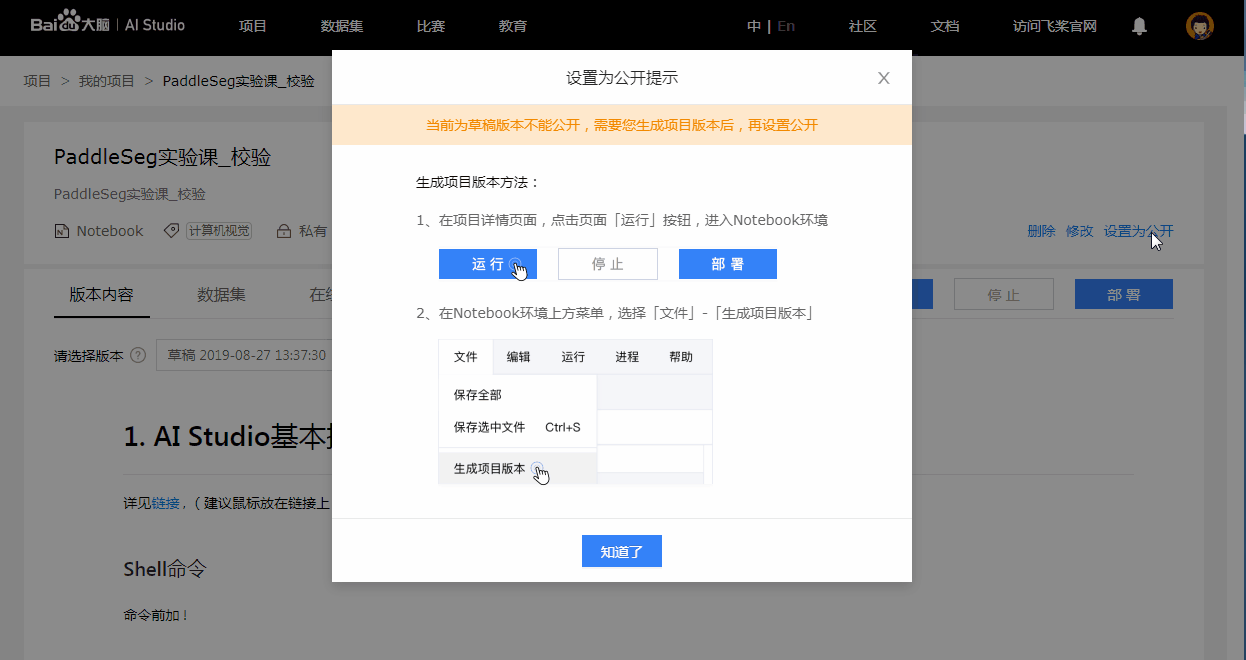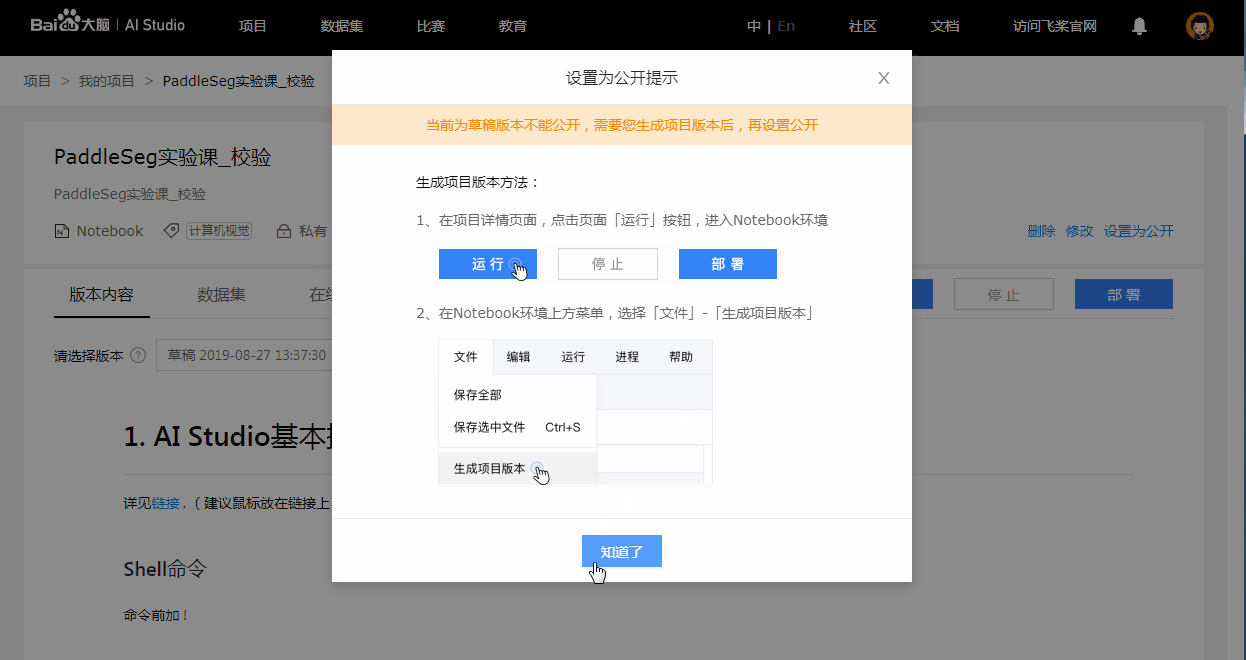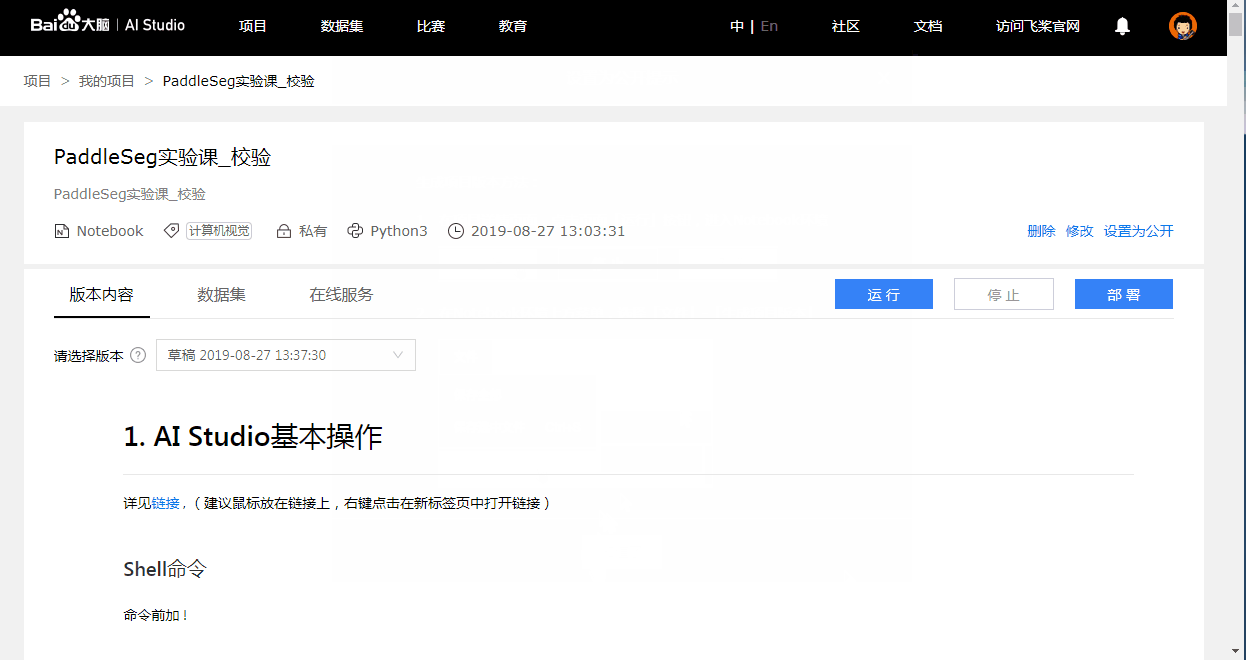
4. 脚本任务
4.1 脚本任务项目说明
脚本任务项目的任务执行由GPU集群作为支撑, 具有实时高速的并行计算和浮点计算能力, 有效解放深度学习训练中的计算压力, 提高处理效率。
用户可以先在Notebook项目中, 利用在线的Notebook功能, 完成代码的编写与调试, 之后在脚本任务项目中运行, 从而提高模型训练速度.
4.2 创建脚本任务项目
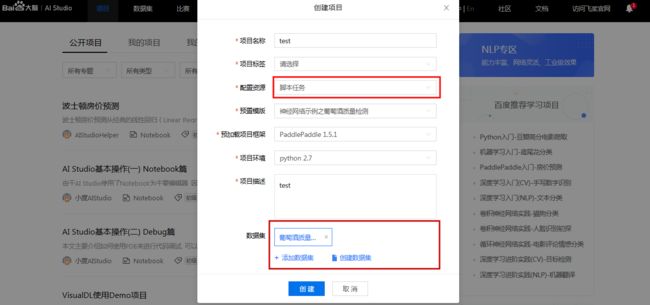
选择脚本任务,可自行更换数据集。
4.3 页面概览
在脚本任务项目详情页中, 用户可以浏览自己创建的项目内容, 编辑项目名称及数据集等信息, 查看集群历史任务信息等.
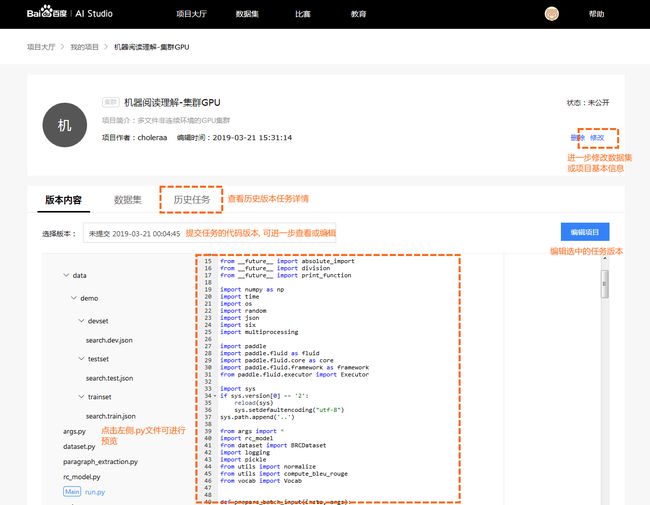
- 版本内容: 默认展示当前
Notebook最新内容. 初始化状态为脚本任务项目示例代码. 用户可以手动选择提交任务时对应的历史版本. - 数据集: 项目所引用的数据集信息.
- 历史任务: 每一次执行任务的记录.
4.4 代码编辑
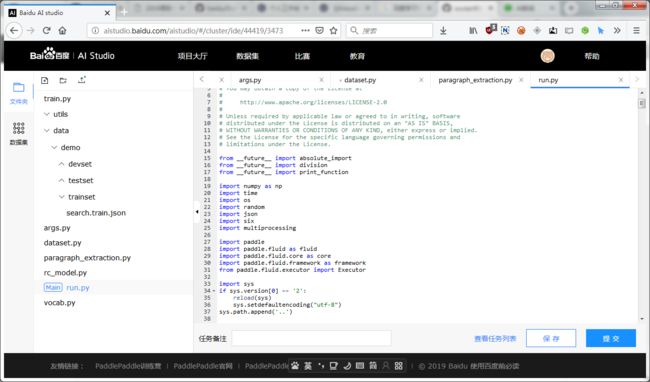
代码编辑界面主要分为左侧: 文件管理和数据集, 和右侧: 代码编辑区和提交任务
4.4.1 左侧文件管理和数据集
文件管理
- 用户可以手动创建文件/文件夹, 对文件/文件夹进行重命名或删除.
- 其中用户可以选择指定文件, 并设置为主文件. 用作整个项目运行的入口.
- 用户也可以手动上传文件(体积上限为
20MB, 体积巨大的文件请通过数据集上传). - 用户可以双击文件, 在右侧将新建一个
tab.用户可以进一步查看或编辑该文件的内容. (目前仅支持.py文件和.txt文件; 同时预览文件的体积上限为1MB)
数据集管理
-
用户可以查看数据集文件, 并复制该文件的相对路径. 最后拼合模板内置绝对路径, 即可使用.
下方有详细介绍.
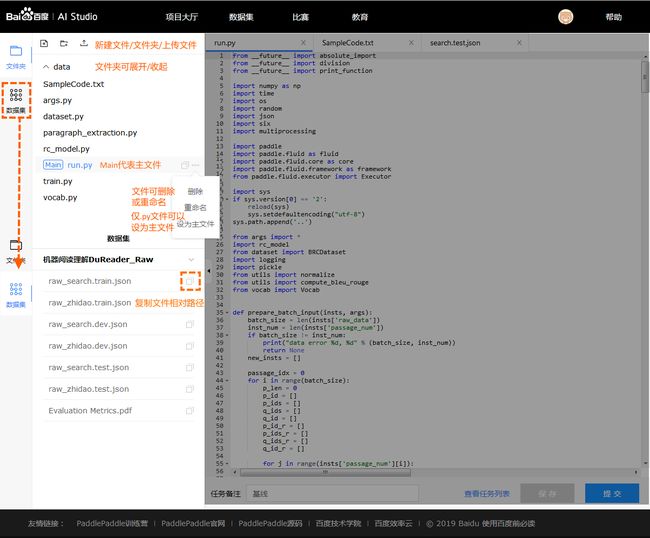
4.4.2 右侧文件预览编辑和提交任务
- 当多个文件被打开时, 用户可以将它们逐一关闭, 当至最后一个文件时即不可关闭
- 选中文件对应的
tab即可对文件内容进行预览和编辑, 但当前仅支持.py和.txt格式的文件 - 点击保存按钮, 会将所有文件的改动信息全部保存, 如用户不提交任务, 直接退出, 则自动保存为一个"未提交"版本
- 提交任务前, 建议写一个备注名称, 方便未来进行不同版本代码/参数的效果比较
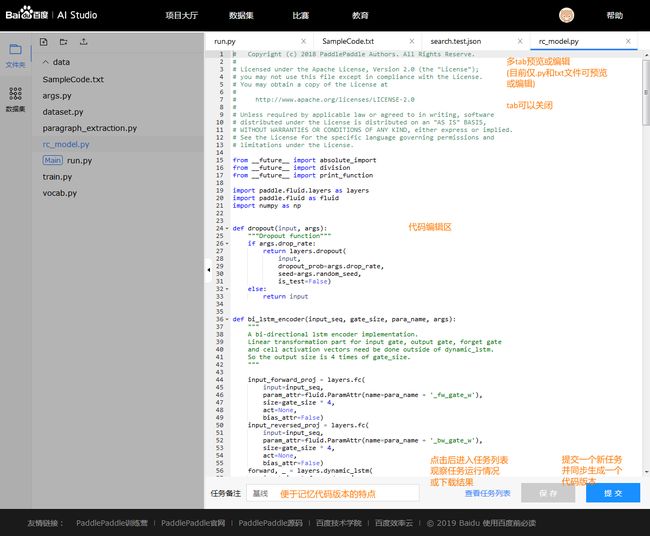
4.5 PaddlePaddle脚本任务训练说明
PaddlePaddle基于集群的分布式训练任务与单机训练任务调用方法不同。基于pserver-trainer架构的的分布式训练任务分为两种角色: parameter server(pserver)和trainer.
在Fluid 中, 用户只需配置单机训练所需要的网络配置, DistributeTranspiler模块会自动地根据当前训练节点的角色将用户配置的单机网路配置改写成pserver和trainer需要运行的网络配置:
t = fluid.DistributeTranspiler()
t.transpile(
trainer_id = trainer_id,
pservers = pserver_endpoints,
trainers = trainers)
if PADDLE_TRAINING_ROLE == "TRAINER":
# 获取pserver程序并执行它
trainer_prog = t.get_trainer_program()
...
elif PADDLE_TRAINER_ROLE == "PSERVER":
# 获取trainer程序并执行它
pserver_prog = t.get_pserver_program(current_endpoint)
...
- 目前脚本任务项目中提供的默认环境
PADDLE_TRAINERS=1(PADDLE_TRAINERS是分布式训练任务中trainer节点的数量) - 非
PaddlePaddle代码请放到if PADDLE_TRAINING_ROLE == "TRAINER":分支下执行, 例如数据集解压任务
更多集群使用说明请参考PaddlePaddle官方文档
4.6 数据集与输出文件路径说明
- 脚本任务项目中添加的数据集统一放到绝对路径
./datasets
# 数据集文件会被自动拷贝到./datasets目录下
CLUSTER_DATASET_DIR = '/root/paddlejob/workspace/train_data/datasets/'
- 脚本任务项目数据集文件路径的获取
在页面左侧数据集中点击复制数据集文件路径, 得到文件的相对路径, 例如点击后复制到剪切板的路径为data65/train-labels-idx1-ubyte.gz.
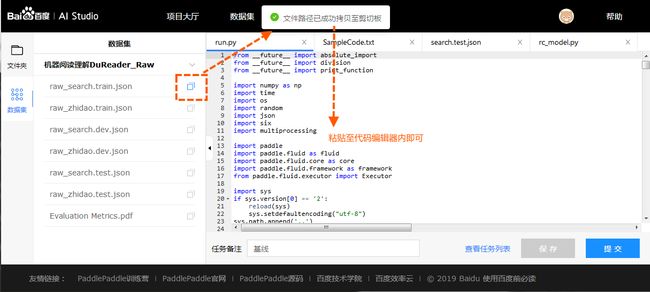
# 数据集文件相对路径
file_path = 'data65/train-labels-idx1-ubyte.gz'
真正使用的时候需要将两者拼合 train_datasets = datasets_prefix + file_path
- 脚本任务项目输出文件路径为
./output
# 需要下载的文件可以输出到'/root/paddlejob/workspace/output'目录
CLUSTER_OUTPUT_DIR = '/root/paddlejob/workspace/output'
4.7 提交任务
点击【运行项目】后进入到任务编辑页面.
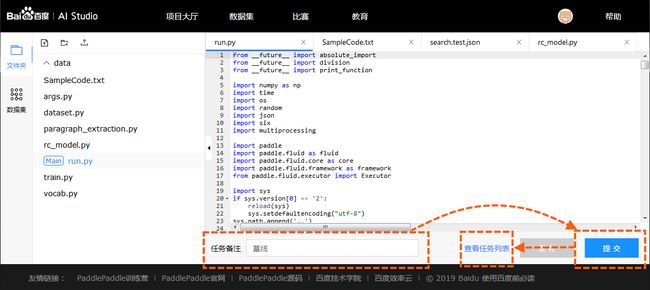
- 提交: 点击提交会发起本次本次任务的执行. 并将代码自动保存为一个版本.
- 任务备注: 任务自定义标识, 用于区分项目内每次执行的任务.
4.8 历史任务
历史任务页面如下所示.

任务操作:
- 下载输出: 下载任务输出文件, 文件格式
xxx(任务编号)_output.tar.gz. - 查看/下载日志: 在任务运行过程中, 点击"查看日志", 可以查看实时日志, 掌握运行进度. 运行结束后, 按钮转为"下载日志". 下载任务执行日志, 日志格式
xxx(任务编号)_log.tar.gz. - 终止任务: 在任务执行过程中, 可以点击终止任务.
- 编辑: 编辑任务对应的代码版本内容.
4.9 空间说明
脚本任务项目空间安装包列表
4.9.1 Python 2.7
| Package | Version |
|---|---|
| attrs | 18.2.0 |
| backports-abc | 0.5 |
| backports.functools-lru-cache | 1.5 |
| backports.shutil-get-terminal-size | 1.0.0 |
| bleach | 3.0.2 |
| certifi | 2018.11.29 |
| chardet | 3.0.4 |
| Click | 7.0 |
| configparser | 3.5.0 |
| cycler | 0.10.0 |
| Cython | 0.29 |
| decorator | 4.3.0 |
| entrypoints | 0.2.3 |
| enum | 0.4.7 |
| enum34 | 1.1.6 |
| Flask | 1.0.2 |
| funcsigs | 1.0.2 |
| functools32 | 3.2.3.post2 |
| future | 0.17.1 |
| futures | 3.2.0 |
| graphviz | 0.10.1 |
| gym | 0.12.1 |
| h5py | 2.8.0 |
| idna | 2.8 |
| ipaddress | 1.0.22 |
| ipykernel | 4.10.0 |
| ipython | 5.8.0 |
| ipython-genutils | 0.2.0 |
| itsdangerous | 1.1.0 |
| Jinja2 | 2.10 |
| jsonschema | 3.0.0a3 |
| jupyter-client | 5.2.4 |
| jupyter-core | 4.4.0 |
| kiwisolver | 1.0.1 |
| MarkupSafe | 1.1.0 |
| matplotlib | 2.2.3 |
| mistune | 0.8.4 |
| nbconvert | 5.3.1 |
| nbformat | 4.4.0 |
| nltk | 3.4 |
| notebook | 5.7.2 |
| numpy | 1.15.4 |
| opencv-python | 3.4.4.19 |
| paddlehub | 1.0.0 |
| paddlepaddle | 1.5.0 |
| pandas | 0.23.4 |
| pandocfilters | 1.4.2 |
| parl | 1.1 |
| pathlib2 | 2.3.3 |
| pexpect | 4.6.0 |
| pickleshare | 0.7.5 |
| Pillow | 5.3.0 |
| pip | 18.1 |
| prettytable | 0.7.2 |
| prometheus-client | 0.5.0 |
| prompt-toolkit | 1.0.15 |
| protobuf | 3.1.0 |
| ptyprocess | 0.6.0 |
| py-cpuinfo | 5.0.0 |
| pyarrow | 0.13.0 |
| pyglet | 1.3.2 |
| Pygments | 2.3.0 |
| pyparsing | 2.3.0 |
| pyrsistent | 0.14.7 |
| python-dateutil | 2.7.5 |
| pytz | 2018.7 |
| PyYAML | 5.1 |
| pyzmq | 17.1.2 |
| rarfile | 3.0 |
| recordio | 0.1.5 |
| requests | 2.22.0 |
| scandir | 1.9.0 |
| scikit-learn | 0.20.0 |
| scipy | 1.1.0 |
| Send2Trash | 1.5.0 |
| setuptools | 40.6.2 |
| simplegeneric | 0.8.1 |
| singledispatch | 3.4.0.3 |
| six | 1.12.0 |
| sklearn | 0.0 |
| subprocess32 | 3.5.3 |
| termcolor | 1.1.0 |
| terminado | 0.8.1 |
| testpath | 0.4.2 |
| tornado | 5.1.1 |
| traitlets | 4.3.2 |
| urllib3 | 1.25.3 |
| visualdl | 1.3.0 |
| wcwidth | 0.1.7 |
| webencodings | 0.5.1 |
| Werkzeug | 0.14.1 |
| wheel | 0.32.3 |
4.9.2 python3.5.5
| Package | Version |
|---|---|
| backcall | 0.1.0 |
| bleach | 3.0.2 |
| certifi | 2018.8.24 |
| chardet | 3.0.4 |
| Click | 7.0 |
| cycler | 0.10.0 |
| Cython | 0.29 |
| decorator | 4.3.0 |
| entrypoints | 0.2.3 |
| Flask | 1.0.2 |
| funcsigs | 1.0.2 |
| future | 0.17.1 |
| graphviz | 0.10.1 |
| gym | 0.12.1 |
| h5py | 2.8.0 |
| idna | 2.8 |
| ipykernel | 5.1.0 |
| ipython | 7.0.1 |
| ipython-genutils | 0.2.0 |
| itsdangerous | 1.1.0 |
| jedi | 0.12.1 |
| Jinja2 | 2.10 |
| jsonschema | 2.6.0 |
| jupyter-client | 5.2.4 |
| jupyter-core | 4.4.0 |
| kiwisolver | 1.0.1 |
| MarkupSafe | 1.0 |
| matplotlib | 2.2.3 |
| mistune | 0.8.3 |
| nbconvert | 5.3.1 |
| nbformat | 4.4.0 |
| nltk | 3.4 |
| notebook | 5.7.0 |
| numpy | 1.15.4 |
| opencv-python | 3.4.4.19 |
| paddlehub | 1.0.0 |
| paddlepaddle | 1.5.0 |
| pandas | 0.23.4 |
| pandocfilters | 1.4.2 |
| parl | 1.1 |
| parso | 0.3.1 |
| pexpect | 4.6.0 |
| pickleshare | 0.7.5 |
| Pillow | 5.3.0 |
| pip | 18.0 |
| prettytable | 0.7.2 |
| prometheus-client | 0.5.0 |
| prompt-toolkit | 2.0.7 |
| protobuf | 3.1.0 |
| ptyprocess | 0.6.0 |
| py-cpuinfo | 5.0.0 |
| pyarrow | 0.13.0 |
| pyglet | 1.3.2 |
| Pygments | 2.3.0 |
| pyparsing | 2.3.0 |
| python-dateutil | 2.7.5 |
| pytz | 2018.7 |
| PyYAML | 5.1 |
| pyzmq | 17.1.2 |
| rarfile | 3.0 |
| recordio | 0.1.7 |
| requests | 2.22.0 |
| scikit-learn | 0.20.0 |
| scipy | 1.1.0 |
| Send2Trash | 1.5.0 |
| setuptools | 40.4.3 |
| simplegeneric | 0.8.1 |
| singledispatch | 3.4.0.3 |
| six | 1.12.0 |
| sklearn | 0.0 |
| termcolor | 1.1.0 |
| terminado | 0.8.1 |
| testpath | 0.3.1 |
| tornado | 5.1.1 |
| traitlets | 4.3.2 |
| urllib3 | 1.25.3 |
| visualdl | 1.3.0 |
| wcwidth | 0.1.7 |
| webencodings | 0.5.1 |
| Werkzeug | 0.14.1 |
| wheel | 0.32.0 |
4.10 问题反馈
如在使用中遇到问题, 可以邮件至 [email protected]
5. 图形化任务
5.1 图形化任务说明
图形化任务旨在使用图形拖拽的方式来设计并训练模型, 并可进行快速部署. 同时还可以生成对应的源码. 最终达成"先实现, 再学习"的目的, 有效提高开发者的效率.
图形化任务使用GPU集群作为支撑, 具有实时高速的并行计算和浮点计算能力.
该功能目前属于Beta版本. 仅对受邀用户开放试用.
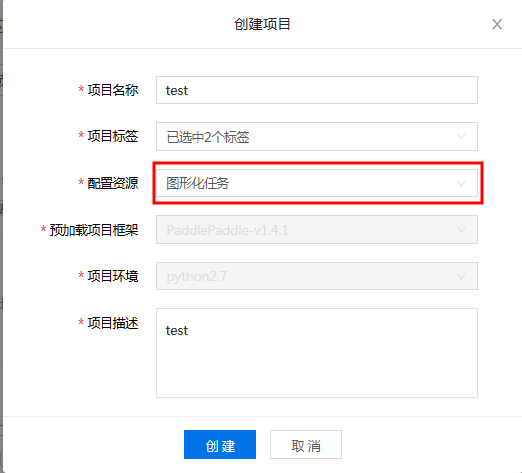
5.2 创建图形化任务
点击创建项目, 然后在"配置资源"中选择"图形化任务", 然后填写必要信息后, 点击"创建"
5.3 图形化任务预览
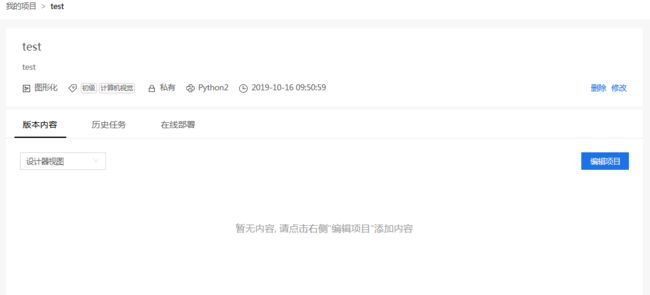
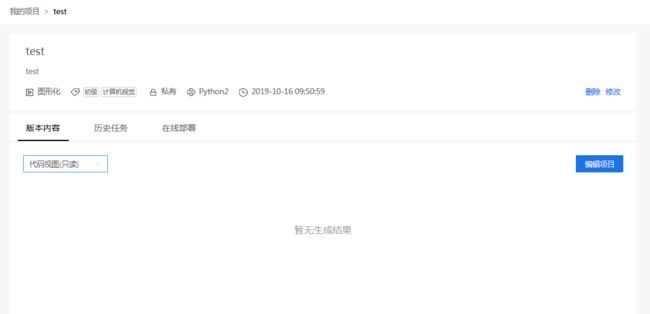
创建成功后, 可以进入项目的预览页面. 预览页面除了项目基本信息外, 可以切换设计器视图和代码视图.
设计器视图预览:
代码视图预览:
进入编辑项目的界面:
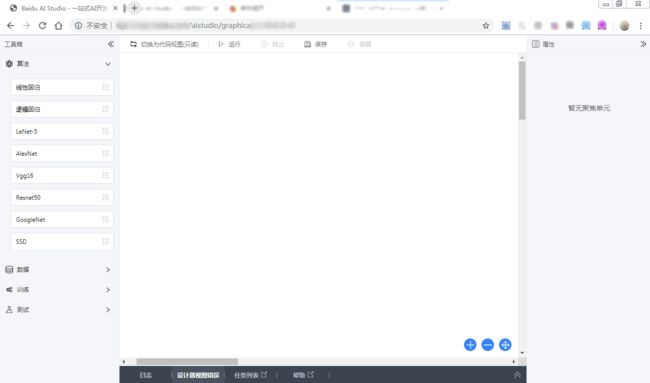
左侧为工具箱, 可以从工具箱向中央画布拖入各种组件:
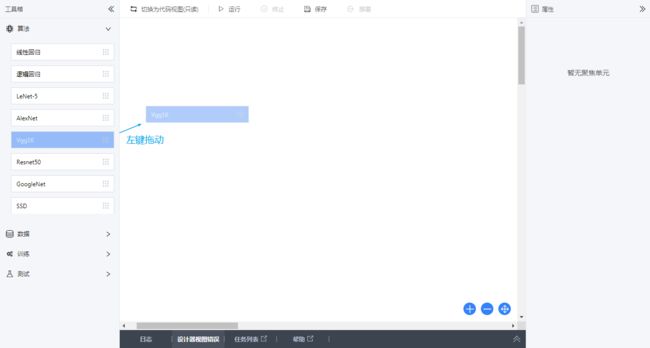
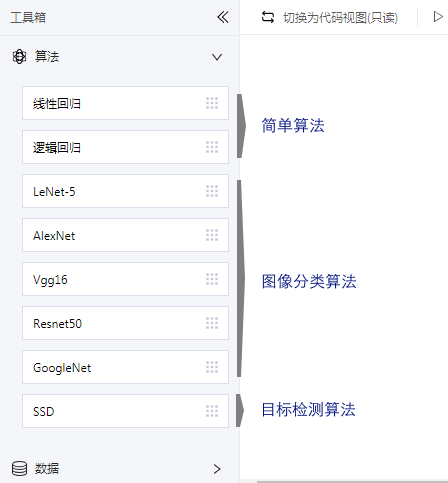
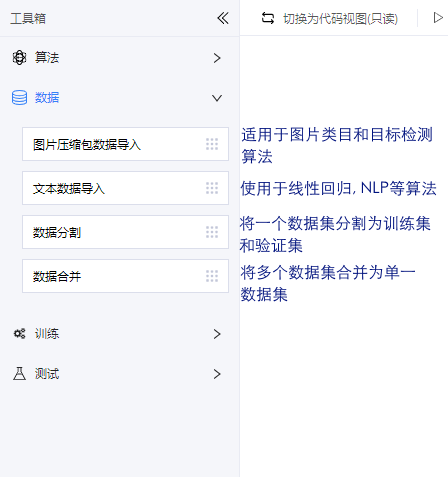
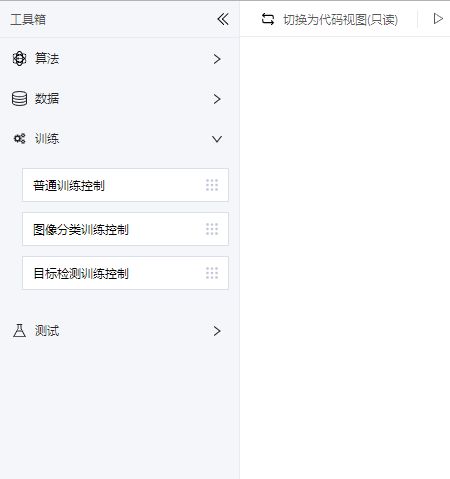
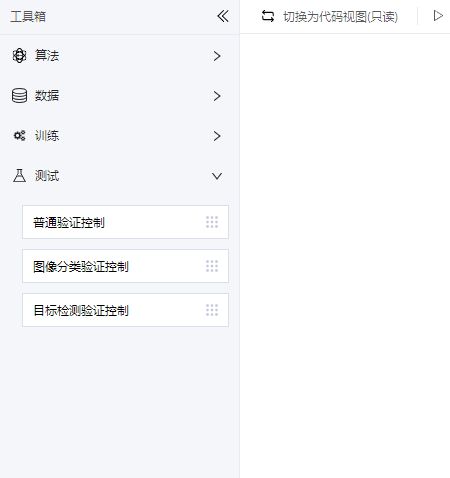
当前工具箱内为算法, 数据, 训练, 测试4类:
算法:
数据:
训练:
测试:
当前尚不支持自定义控件. 近期会予以支持.
最终构建成完成的网络:
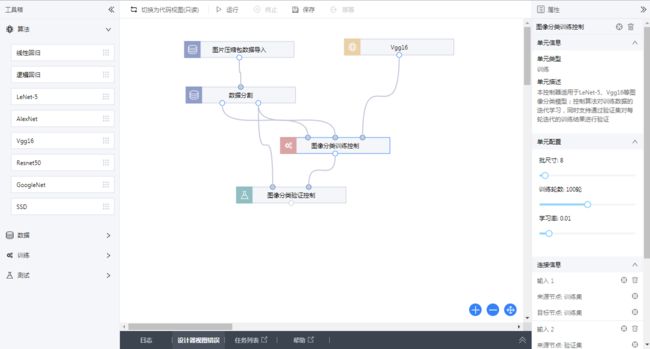
构建完成后可以启动训练:
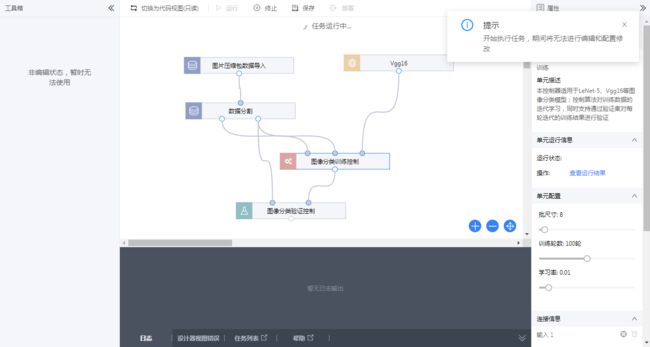
此时左侧工具箱已经锁定, 下方开始输出日志:
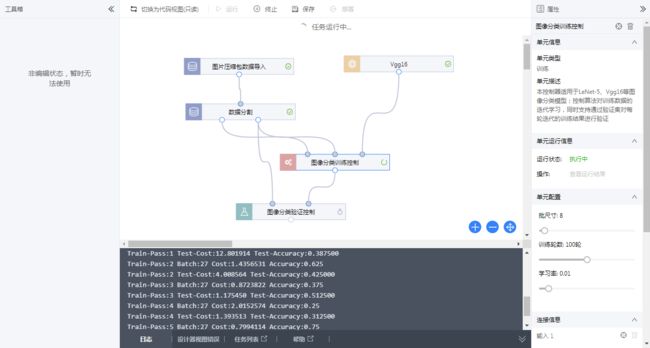
点击"任务列表", 也可以查看当前任务的状态

正式部署: 当运行完成后点击上方"部署"按钮, 即可启动部署流程:
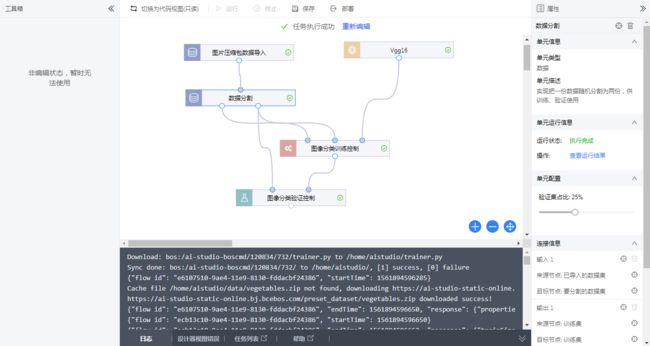
部署需要选定训练好的模型
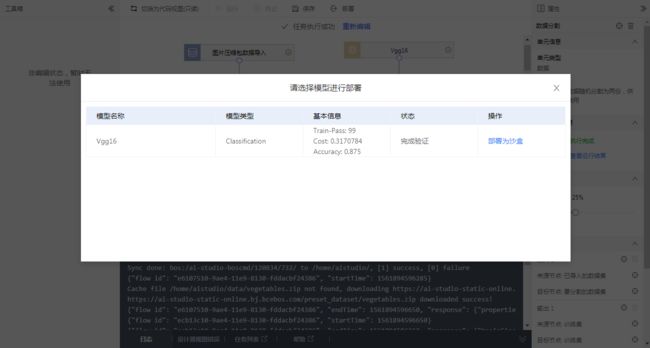
部署过程需要一定时间, 之后会显示为部署完成
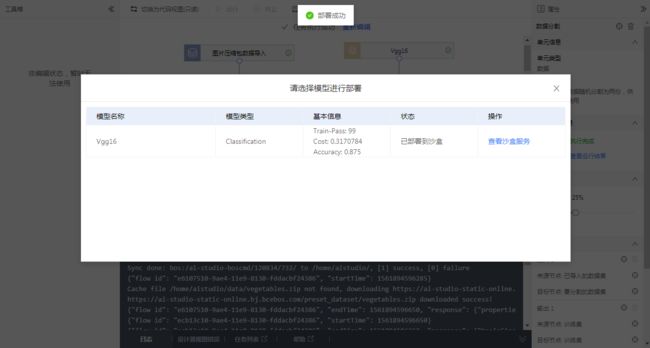
部署后可以看到沙盒. 一个项目最多可配置5个沙盒用于测试
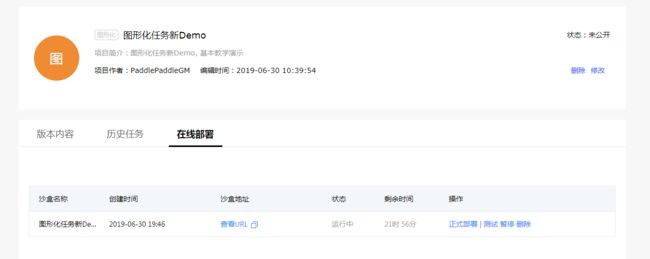
点击测试可以使用自己的数据测试在线接口:
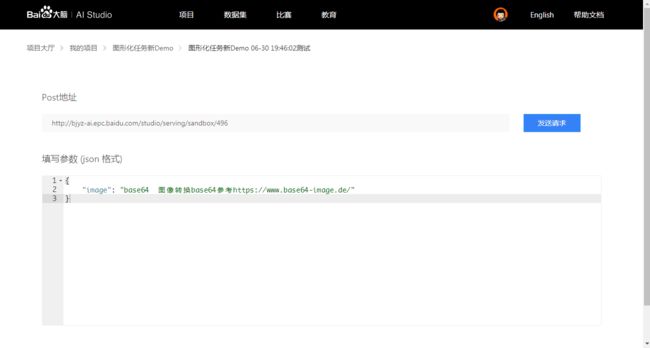
测试后, 如果效果满意, 可以部署为正式API
5.4 预置算法部署后调用参数样例
5.4.1 线性回归的请求及返回说明
请求
| 参数 | 类型 | 说明 | 其他 |
|---|---|---|---|
| text | Array | 房价预测的13维归一化后的数据 |
示例:
{
"text": [-0.41733927, -0.48772237, -0.593381, -0.27259856, -0.7402622, 0.19427446, 0.36716643, 0.5571599, -0.8678825, -0.9873295, -0.30309415, 0.44105193, -0.49243936]
}
返回
| 参数 | 类型 | 说明 | 其他 |
|---|---|---|---|
| predicted_result | Array | 模型的输出 | |
| predicted_label | float | 房价的预测结果 |
示例:
[
{
"predicted_result": [
[
16.114334106445312
]
]
},
{
"predicted_label": 16.114334106445312
}
]
5.4.2 逻辑回归的请求及返回说明
请求
| 参数 | 类型 | 说明 | 其他 |
|---|---|---|---|
| text | Array | 莺尾花的4维归一化后的数据 |
示例:
{
"text": [1.0147785, -1.3129628, -1.3348082, -0.8980088]
}
返回
| 参数 | 类型 | 说明 | 其他 |
|---|---|---|---|
| predicted_result | Array | 模型的输出 | |
| predicted_label | integer | 预测结果,类别标示,对应类别请参考训练数据集的train.txt文件 |
示例:
[
{
"predicted_result": [
[
0.178230881690979,
0.1754814237356186,
0.646287739276886
]
]
},
{
"predicted_label": 2
}
]
5.4.3 图像分类的请求及返回说明
请求
| 参数 | 类型 | 说明 | 其他 |
|---|---|---|---|
| image | String | 数据集的任一张图片的base64编码后的字符串 |
示例:
{
"image":"base64 图像转换base64参考https://www.base64-image.de/"
}
返回
| 参数 | 类型 | 说明 | 其他 |
|---|---|---|---|
| predicted_result | Array | 模型的输出 | |
| predicted_label | integer | 预测结果,类别标示,对应类别请参考训练数据集的train.txt文件 |
示例:
[
{
"predicted_result": [
[
4.15152685017504e-17,
6.219317838507266e-10,
1
]
]
},
{
"predicted_label": 2
}
]
5.4.4 目标检测的请求及返回说明
请求
| 参数 | 类型 | 说明 | 其他 |
|---|---|---|---|
| image | String | PASCAL VOC数据集(或任意图片)的任一张图片的base64编码后的字符串 |
示例:
{
"image":"base64 图像转换base64参考https://www.base64-image.de/"
}
返回
| 参数 | 类型 | 说明 | 其他 |
|---|---|---|---|
| category_id | Integer | PASCAL VOC数据类别标示,对应数据集的label_list文件每个类别的次序 | |
| p1 | Array | box的左上坐标 | |
| p2 | Array | box的左下坐标 | |
| p3 | Array | box的右下坐标 | |
| p4 | Array | box的右上坐标 |
示例:
[
{
"p2": [
211.43447756767273,
213.80889415740967
],
"p3": [
292.56797432899475,
213.80889415740967
],
"category_id": 15,
"p1": [
211.43447756767273,
0
],
"p4": [
292.56797432899475,
0
]
}
]
5.5 内置数据集说明及下载地址
波士顿房价
类型: txt
体积: 40KB
简介: http://www.paddlepaddle.org/documentation/docs/zh/1.2/beginners_guide/quick_start/fit_a_line/README.cn.html
下载地址: https://ai-studio-static-online.bj.bcebos.com/preset_dataset/housing.txt
鸢尾花数据集
类型: csv
体积: 4KB
简介: 约150条数据,每条样本4个属性,共3个类别
下载地址: https://ai-studio-static-online.bj.bcebos.com/preset_dataset/Iris_DataSet.csv
MNIST数据集
类型: zip
体积: 30MB
简介: 共包含70000张灰度图
下载地址: https://ai-studio-static-online.bj.bcebos.com/preset_dataset/mnist.zip
(MD5: d569e1965b8e90e066681e1dbe864487)
猫狗数据集
类型: zip
体积: 550MB
简介: 包含25000张RGB图片,其中cat12500张,dog12500张
下载地址: https://ai-studio-static-online.bj.bcebos.com/preset_dataset/catVsdog.zip
(MD5: 384bbb42dfc5faf63beaa0cade3d8cff)
Ox-Flowers17
类型: zip
体积: 58MB
简介: 包含17种不同类型的花,每类包含80张RGB图
下载地址: https://ai-studio-static-online.bj.bcebos.com/preset_dataset/flowers17.zip
(MD5: bd2a8acfe07529b89649e7ca5a866242)
CIFAR10数据集
类型: zip
体积: 51.31MB
简介: http://www.paddlepaddle.org/documentation/docs/zh/0.14.0/new_docs/beginners_guide/basics/image_classification/README.cn.html
下载地址: https://ai-studio-static-online.bj.bcebos.com/preset_dataset/cifar10.zip (MD5: 2cf4e2caa2b7759572eef14f47cccf61))
vegetables
类型: zip
体积: 9.5MB
简介: 包含3类蔬菜(黄瓜、生菜、莲藕),每类包含100张RGB图片
下载地址: https://ai-studio-static-online.bj.bcebos.com/preset_dataset/vegetables.zip (MD5: 90835e76aa00b6c6bf1ed3b8cba96df5)
pascalvoc
类型: zip
体积: 2.6GB
简介: 包含20类,共约21503张RGB图像及标注信息
下载地址: https://ai-studio-static-online.bj.bcebos.com/preset_dataset/pascalvoc.zip (MD5: 3aaa5ad581114438ab6ba4dbf0720504)
6. 在线部署及预测
6.1 功能说明
在线部署与预测为开发者提供训练模型向应用化API转换的功能. 开发者在AI Studio平台通过NoteBook项目完成模型训练后, 在Notebook详情页通过创建一个在线服务, 应用模型生成在线API, 使用该API可以直接检验模型效果或实际应用到开发者的私有项目中。目前, 该功能暂时仅对Notebook项目开放。
6.2 通过训练任务生成模型文件
- 在训练任务过程中, 通过调用paddle.fluid.io.save_inference_model实现模型的保存,保存后的目录需要可以被在线服务使用. 我们以房价预测的线性回归任务为例, 具体代码如下
import paddle
import paddle.fluid as fluid
import numpy
import math
import sys
from __future__ import print_function
BATCH_SIZE = 20
train_reader = paddle.batch(
paddle.reader.shuffle(
paddle.dataset.uci_housing.train(), buf_size=500),
batch_size=BATCH_SIZE)
test_reader = paddle.batch(
paddle.reader.shuffle(
paddle.dataset.uci_housing.test(), buf_size=500),
batch_size=BATCH_SIZE)
params_dirname = "model2"
x = fluid.layers.data(name='x', shape=[13], dtype='float32')
y = fluid.layers.data(name='y', shape=[1], dtype='float32')
y_predict = fluid.layers.fc(input=x, size=1, act=None)
main_program = fluid.default_main_program()
startup_program = fluid.default_startup_program()
cost = fluid.layers.square_error_cost(input=y_predict, label=y)
avg_loss = fluid.layers.mean(cost)
sgd_optimizer = fluid.optimizer.SGD(learning_rate=0.001)
sgd_optimizer.minimize(avg_loss)
#clone a test_program
test_program = main_program.clone(for_test=True)
use_cuda = False
place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
exe = fluid.Executor(place)
num_epochs = 100
# For training test cost
def train_test(executor, program, reader, feeder, fetch_list):
accumulated = 1 * [0]
count = 0
for data_test in reader():
outs = executor.run(program=program,
feed=feeder.feed(data_test),
fetch_list=fetch_list)
accumulated = [x_c[0] + x_c[1][0] for x_c in zip(accumulated, outs)]
count += 1
return [x_d / count for x_d in accumulated]
params_dirname = "fit_a_line.inference.model"
feeder = fluid.DataFeeder(place=place, feed_list=[x, y])
naive_exe = fluid.Executor(place)
naive_exe.run(startup_program)
step = 0
exe_test = fluid.Executor(place)
# main train loop.
for pass_id in range(num_epochs):
for data_train in train_reader():
avg_loss_value, = exe.run(main_program,
feed=feeder.feed(data_train),
fetch_list=[avg_loss])
if step % 10 == 0: # record a train cost every 10 batches
print (step, avg_loss_value[0])
if step % 100 == 0: # record a test cost every 100 batches
test_metics = train_test(executor=exe_test,
program=test_program,
reader=test_reader,
fetch_list=[avg_loss.name],
feeder=feeder)
print (step, test_metics[0])
# If the accuracy is good enough, we can stop the training.
if test_metics[0] < 10.0:
break
step += 1
if math.isnan(float(avg_loss_value[0])):
sys.exit("got NaN loss, training failed.")
if params_dirname is not None:
# We can save the trained parameters for the inferences later
fluid.io.save_inference_model(params_dirname, ['x'],
[y_predict], exe)
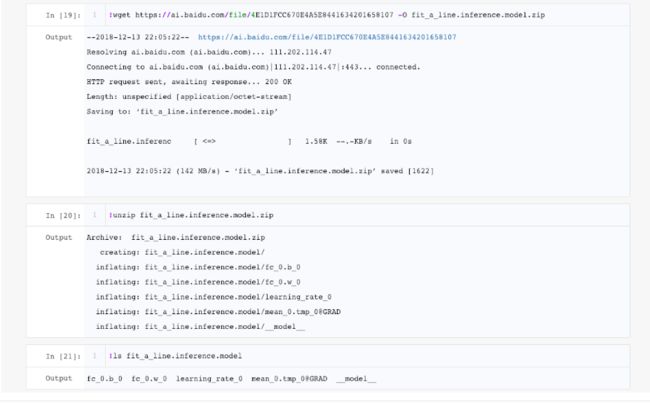
- 使用已有模型, 可以通过
!wget在Notebook中传输模型文件到环境目录。以房价预测的线性回归模型为例, 通过!wget https://ai.baidu.com/file/4E1D1FCC670E4A5E8441634201658107 -O fit_a_line.inference.model传输文件, 解压后直接被在线服务使用.
6.3 创建一个在线服务
完成模型训练后, 在Notebook项目页面点击【创建预测服务】
6.3.1 第一步 选择模型文件
- 勾选模型文件
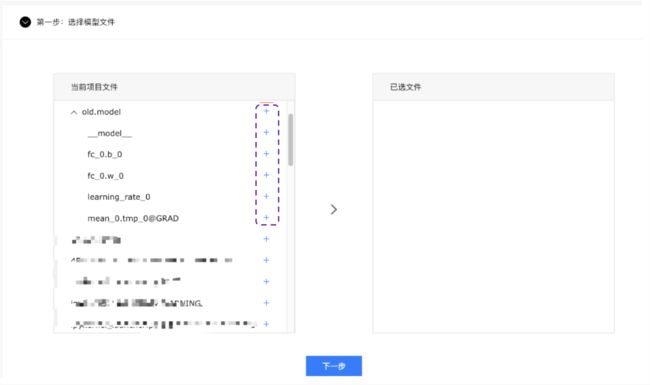
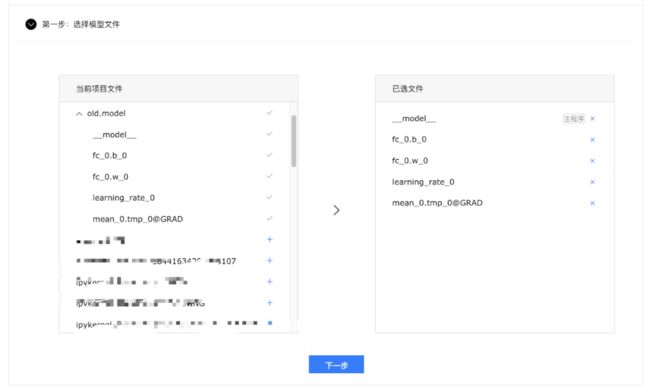
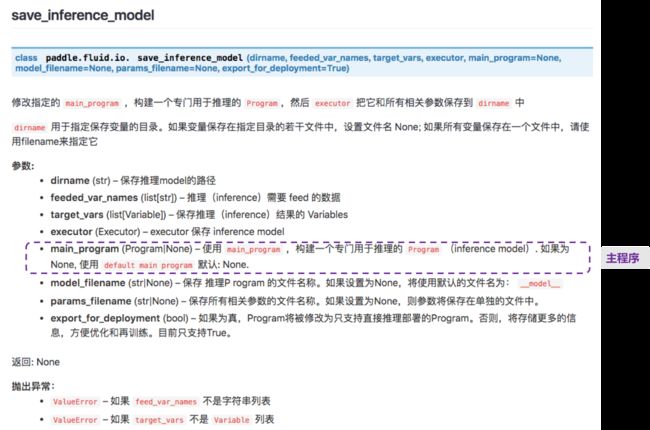
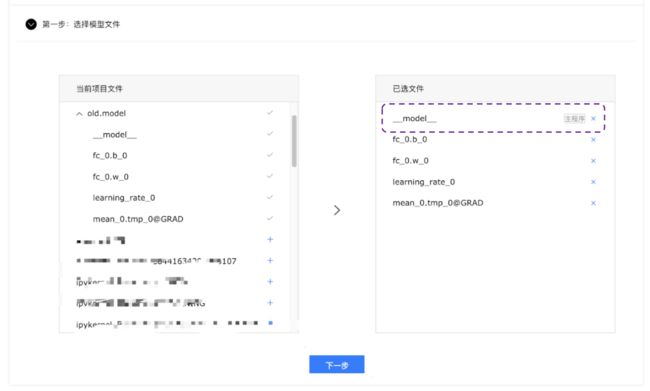
- 设置主程序, 主程序为
paddle.fluid.io.save_inference_model中参数main_program配置的程序, 在房价预测的示例中,我们使用默认参数调用save_inference_model, 因此将__model__文件设置为主程序.
6.3.2 第二步 确认输入输出
填写模型的输入输出参数. 以房价预测的线性回归模型为例(参数参考), 添加参数如下图所示.


6.3.3 第三步 制作参数转换器
参数转换器帮助用户转化合法输入并完成数据预处理.
- 方式一: 自定义转换器(
Python2.7)(推荐).
输入参数转换器方法
def reader_infer(data_args):
"""
reader_infer 输入参数转换器方法
:param data_args: 接口传入的数据,以k-v形式
:return [[]], feeder
"""
#构造内容
pass
输出参数转换器方法
def output(results, data_args):
"""
output 输出参数转换器方法
:param results 模型预测结果
:param data_args: 接口传入的数据,以k-v形式
:return array 需要能被json_encode的数据格式
"""
#构造内容
pass

转换器代码示例, 以房价预测为例.
输入参数转换器:
import os
import sys
sys.path.append("..")
from PIL import Image
import numpy as np
import paddle.fluid as fluid
from home.utility import base64_to_image
def reader_infer(data_args):
"""
reader_infer 输入参数转换器方法
:param data_args: 接口传入的数据,以k-v形式
:return [[]], feeder
"""
def reader():
"""
reader
:return:
"""
x = fluid.layers.data(name='x', shape=[13], dtype='float32')
# y = fluid.layers.data(name='y', shape=[1], dtype='float32')
feeder = fluid.DataFeeder(place=fluid.CPUPlace(), feed_list=[x])
CRIM = float(data_args["CRIM"])
ZN = float(data_args["ZN"])
INDUS = float(data_args["INDUS"])
CHAS = float(data_args["CHAS"])
NOX = float(data_args["NOX"])
RM = float(data_args["RM"])
AGE = float(data_args["AGE"])
DIS = float(data_args["DIS"])
RAD = float(data_args["RAD"])
TAX = float(data_args["TAX"])
PTRATIO = float(data_args["PTRATIO"])
B = float(data_args["B"])
LSTAT = float(data_args["LSTAT"])
return [[[CRIM, ZN, INDUS, CHAS, NOX, RM, AGE, DIS, RAD, TAX, PTRATIO, B, LSTAT]]], feeder
return reader
输出参数转换器:
def output(results, data_args):
"""
output 输出参数转换器方法
:param results 模型预测结果
:param data_args: 接口传入的数据,以k-v形式
:return array 需要能被json_encode的数据格式
"""
lines = []
for dt in results:
y = dt.tolist()
lines.append({"predict": y})
return lines
-
方式二: 默认参数, 不设置转换器.
用户的
API参数直接传递给模型.

6.3.4 第四步 沙盒部署
用户可以同时部署至多五个沙盒服务, 用来对比模型优化结果.
录入名称点击【生成沙盒】或者点击【暂存】将沙盒保存到草稿箱.
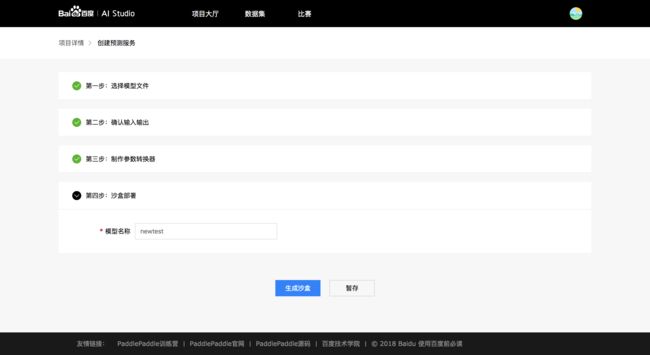
6.4 测试沙盒服务
对沙盒列表中的沙盒服务进行测试,验证是否配置正确。
6.4.1 第一步 点击【测试】打开测试页面

6.4.2 第二步 填写json格式请求参数
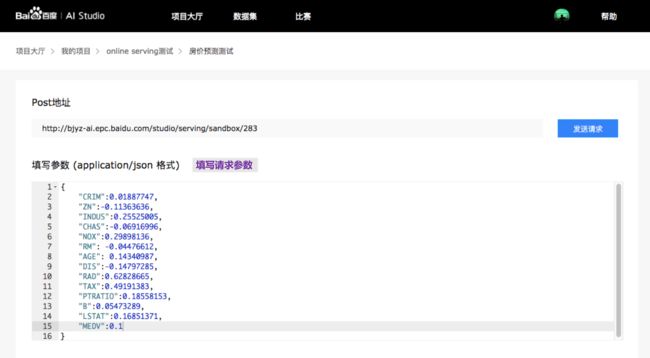
6.4.3 第三步 点击【发送】检验返回结果

6.5 部署在线服务
点击【正式部署】部署线上API.
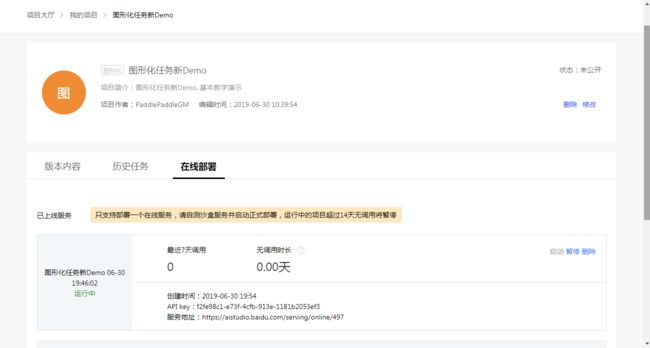
- 一个项目可以创建至多五个沙盒服务, 并选择其中一个沙盒服务部署为线上服务.
- 沙盒服务如果连续超过24小时无调用将自动调整为暂停状态.
- 线上服务如果连续超过14天无调用将自动调整为暂停状态.
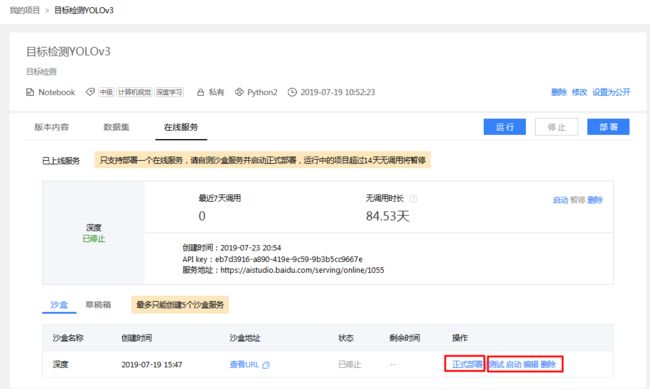
6.6 调用在线服务
依据API key、服务地址和用户自定义参数, 实现对服务的调用.
6.6.1 请求方式
HTTP请求URL: [服务地址] [?] [apiKey=xxx]HTTP请求方法:POSTHTTP Body: 用户自定义参数

6.6.2 调用示例
以房价预测项目为例.
CURL
curl -H "Content-Type: application/json" -X POST -d '{"CRIM":0.01887747, "ZN":-0.11363636, "INDUS":0.25525005, "CHAS":-0.06916996, "NOX":0.29898136, "RM": -0.04476612, "AGE": 0.14340987, "DIS":-0.14797285, "RAD":0.62828665, "TAX":0.49191383, "PTRATIO":0.18558153, "B":0.05473289, "LSTAT":0.16851371}' "https://aistudio.baidu.com/serving/online/xxx?apiKey=xxxxxxxxxx"

Python
import json
import traceback
import urllib
import urllib2
formdata = {
"CRIM":0.01887747,
"ZN":-0.11363636,
"INDUS":0.25525005,
"CHAS":-0.06916996,
"NOX":0.29898136,
"RM": -0.04476612,
"AGE": 0.14340987,
"DIS":-0.14797285,
"RAD":0.62828665,
"TAX":0.49191383,
"PTRATIO":0.18558153,
"B":0.05473289,
"LSTAT":0.16851371
}
header = {"Content-Type": "application/json; charset=utf-8"}
url = "https://aistudio.baidu.com/serving/online/xxx?apiKey=a280cf48-6d0c-4baf-bd39xxxxxxcxxxxx"
data = json.dumps(formdata)
try:
request = urllib2.Request(url, data, header)
response = urllib2.urlopen(request)
response_str = response.read()
response.close()
print(response_str)
except urllib2.HTTPError as e:
print("The server couldn't fulfill the request")
print(e.code)
print(e.read())
except urllib2.URLError as e:
print("Failed to reach the server")
print(e.reason)
except:
traceback.print_exc()

参考:
https://ai.baidu.com/ai-doc/AISTUDIO/Dk3e2vxg9