深入理解编译、链接和运行(obj文件组成格式分析,可执行文件组成格式分析)
一、简单的CS历史
现代大多数计算机都是基于冯.诺伊曼提出的存储程序原理采用冯.诺伊曼架构,即由运算器、控制器、存储器和输入输出设备组成。
为了屏蔽I/O设备的底层差异,产生虚拟文件系统virtual file system(VFS)。为了屏蔽内存和I/O的差异产生了虚拟存储器(虚拟内存),而为了屏蔽CPU、I/O和内存的差异进而产生进程的概念。
虚拟的概念是由大名鼎鼎的计算机公司IBM提出的,为了方便理解虚拟,IBM写出下面的几句话:
1、看得见 存在 物理
2、看得见 不存在 虚拟
3、看不见 存在 透明
二、程序是怎么执行的
我们或多或少都有疑问,这些看似平常的由字符组成的文章是通过怎样的过程可最终以在计算机上执行,高级语言如pascal、c、c++、java等,尽管语言不相同,持有各自的特性,但其最终生成的无非就是指令和数据,毫不夸张的讲程序其实就是指令和数据。所以计算机是在做运算,处理指令和数据。那么我们用高级语言编写的程序最终是怎么成为计算机可以识别的机器语言的。在linux系统上,当我们输入./a.out并进行回车时发生了什么。作为一名程序员,这是我们需要知道的。
下边的代码,用于分析编译、链接过程。
#include上边共定义的12个变量,其中哪些是指令,哪些是数据。都分布在内存的哪些区域是我们所需清楚的。
为探究上述问题,首先我们需要清楚的了解虚拟地址空间的内存布局。操作系统为每一个进程分配虚拟地址空间,而虚拟地址空间的大小,取决于CPU的位数,更具体的说是ALU(算术逻辑运算单元的宽度)即一次可以处理最长整数的宽度,同时也可以理解为数据总线的条数。在32bit的linux内核,也可以理解为地址总线的条数,因为地址总线的条数和数据总线的条数相同。总而言之,在32bit操作系统下,虚拟地址空间的大小为2^32即4G的大小的虚拟地址空间。
三、虚拟地址空间
由上边分析可知,在32bit的CPU架构下地址总线的条数为32条,所以其寻址能力为2^32个,按字节编址,所以虚拟地址空间的大小为4GB。下面以图示的方式说明这4GB的虚拟地址空间布局是什么样的。

用户空间的分析:
(1)保留区:很多情况下,正是由于我们对虚拟地址空间布局不熟悉所以编写出错误的程序。如果熟悉虚拟地址空间的内存布局,大可避免这些不必要的错误。如下边的小程序正是许多许多新手程序员经常犯的错误:
#include显然程序中并没有给指针变量p分配合理的内存,就对p进行了访问,此时p所指向的内存区域正是虚拟地址空间中128MB的保留区,所以会出现段错误。
(2).data、.bss和.text

图中绿色区域位于虚拟地址空间中的数据段(.bss和.data),而红色区域位于虚拟地址控制中的.text即代码段。
其中,经过加载.data段存放初始化不为0的全局变量而.bss段存放初始化为0的全局变量和未初始化的局部变量。注意,这里的局部变量和全局变量是指符号解析为local和global符号。bss(better save space)这里.bss节省的是文件的空间还是虚拟地址空间放在后边进行解释。实际上.bss段(better save space)节省的obj文件格式的大小。
(3)共享库 如果程序中用到了库函数,如printf、scanf、puts、gets等。则在共享库中包含了这些函数的定义。
(4)栈 函数运行用到的栈
内核空间的分析:
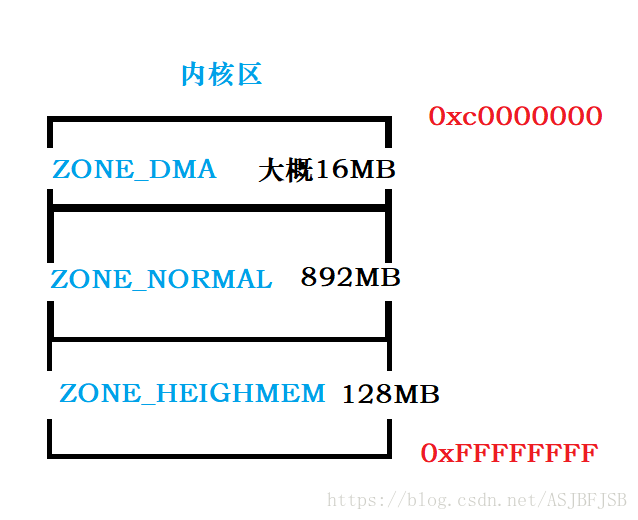
(1)ZONE_DMA:直接内存访问,正常情况下,磁盘中的数据到达主存需要进过存储器的层次结构,需要经过CPU。若这些数据不需要CPU处理,则浪费了大量的CPU时间。如果在主存和辅存之间之间开辟一条数据通路,则可提高CPU的使用率,同时可以加快主存和辅存之间交换数据的速度,进而提高整机的性能。DMA直接内存访问正是提供了这样的一种机制。
(2)ZONE_NORMAL
(3)ZONE_HEIGHMEM:主要用于在32bit的linux系统中在内核映射高于1GB的物理内存时会用到高端内存。
四、深入编译和链接过程。
下面详细分析由源文件是如何经过编译和链接过程最终生成可执行文件。
测试环境:ubuntu18.04 + gcc
测试工具:逆向和反汇编工具 objdump和readelf
测试代码:
int gdata1 = 10; //.data
int gdata2 = 0; //.bss
int gdata3; //.bss
static int gdata4 = 20; //.data
static int gdata5 = 0; //.bss
static int gdata6; //.bss
int main(){ //.text
int a = 30; //.text
int b = 0; //.text
int c; //.text
static int d = 40; //.data
static int e = 0; //.bss
static int f; //.bss
return 0; //.text
}
//.bss共占24个字节 .data共占12个字节编译生成可重定位的二进制文件:
编译
整个编译过程分为预编译、编译和汇编,最终生成可执行文件,其中在windows下生成 .obj文件,在linux下生成 .o文件,学名叫做二进制可重定位文件
(1)预编译:gcc -E *.c -o *.i
预编译要干的事情:如删除注释、替换宏、递归展开头文件、处理以#开头的预编译指令等,在预编译阶段不做任何 有效信息的类型检查。
(2)编译:gcc -S *.i -o *.s
词法分析、语法分析和语义分析、代码的优化、编译、汇总所有的所有的符号
(3)汇编:gcc -c *.s -o *.o
将汇编指令转换为特定平台下的机器语言、构建*.o文件组成格式。
链接
(1)合并所有obj文件的段,并调整段偏移和段长度,合并符号表,进行符号解析,分配内存地址(虚拟地址)。
(2)链接的核心:符号的重定位。
针对编译和链接过程,提出以下需要解决的问题:
(1)编译的过程是怎么样的?
(2)obj文件的组成格式是什么,它为什么不能执行?
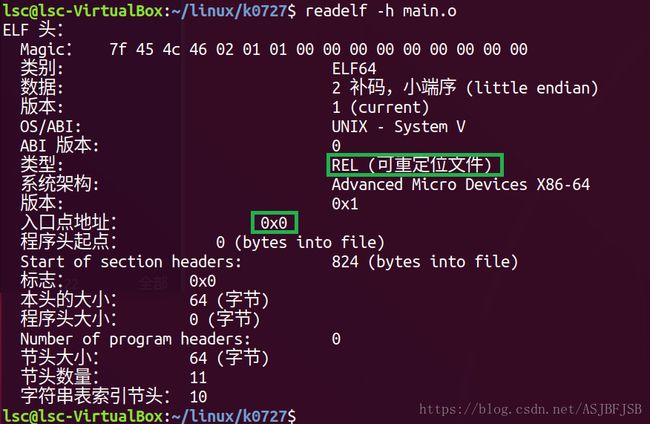
1.readelf -h main.o输出obj文件头部,可以查看到obj文件一些重要信息。
2.file main.o

在上边两个图中,可以得出这样的一个结论。.obj是一个二进制可重定位文件,不能执行,并不是一个executable的文件。
下面分析.obj文件的组成格式
3.objdump -s main.o


4.readelf -S main.o产看当前二进制可重定位文件中所有的段。

.obj文件组成格式的分析,着重看
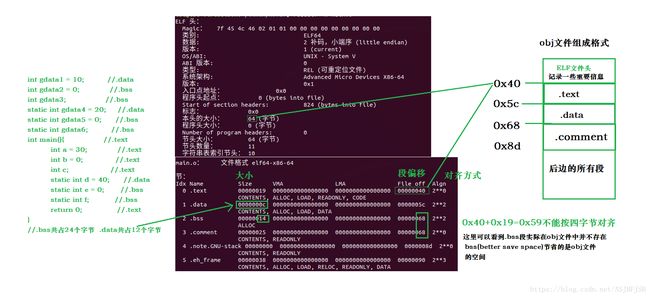
现在新的问题出现了:
(2.1)既然.obj文件中都没有存储.bss段的信息,那么在程序中那些初始化为0的全局变量和未初始化的局部变量它是怎么识别它们的?
答:由于.bss段中都是0,所以不需要记录。只需要记录其大小即可,所以通过段表即可找到。
(2.2)分析测试代码,得出由六个变量位于.bss段,但实际上在.bss中大小只有20个字节即只记录了5个变量,那么还有一个变量为什么不记录,它在哪里?
答:这里涉及到强弱符号,我会单独写出来。浅显的可以这样理解,由于全局变量gdata3是一个弱符号,而未经链接。并不知道是否有强符号的存在,所以在.bss段中并为记录。而gdata6虽然未经初始化,但由于其经static关键字修饰,本文件可见,所以不存在强弱符号之分。
(3)链接的第二步具体做了哪些事情,什么是符号重定位?
链接器只对所有.obj文件的global符号进行处理,对local的符号不做任何处理。如static生成的符号就是local的符号。
objdump -t main.o查看生成的符号表

可以看到弱符号在 *COM*中存放。
为方便探究链接的过程及其核心符号的重定位,用下边两个文件的代码进行验证:
//main.c
extern int gdata10;//不可对外部变量进行初始化
extern int sum(int,int);
int gdata1 = 10;
int gdata2 = 0;
int gdata3;
static int gdata4 = 20;
static int gdata5 = 0;
static int gdata6;
int main(){
int a = 30;
int b = 0;
int c;
static int d = 40;
static int e = 0;
static int f;
return 0;
}
//sum.c
int gdata10 = 20;
int sum(int a,int b){
return a+b;
}分别查看main.o和sum.o所生成的符号表:


符号解析:所有obj文件符号表中对符号引用的地方都要找到符号定义的地方,否则就会出现链接错误。由于源文件是单独编译的,所以对外部的符号处理为*UND*即undefine。
objdump -d main.o

可以看到编译过程并不给数据和函数入口分配内存地址,都是以0地址作为替代。
下面详细看链接过程:
简单的合并策略,将每个obj文件的段拿来即可,像下边这样:

实际上这样做并不好,通过上边的分析,在.obj文件中,每个段对齐方式是4字节对齐,但是可执行文件是按照页面对齐的,在32bit的CPU架构下,常用的页面大小是4KB,假设现在每个段现在都是一字节大小,如果按照这种简单的合并策略,将会有大量的空间会被浪费。
合理的分配策略:将所有属性相同的段合并,组织在一个页面上。合并所有.obj文件的段,调整段大小和段偏移,重点:合并符号表,进行符号解析,即符号的重定位,即在符号引用的地方找到符号定义的地方。
现在手动链接:ld -e main *.o -o run

objdump -h run

链接完成后,弱符号gdata3并为找到强符号,所用就用它自己,此时.bss大小为24个字节,即六个变量。
查看符号表objdump -t run
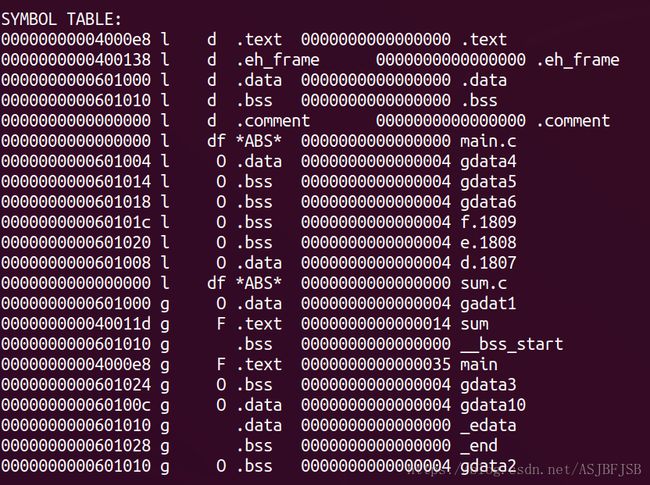
此时所有符号都有合理的虚拟地址空间的地址,即符号进行了重定位。将代码段中数据的地址替换为数据的地址,将函数入口的地址的偏移量替换到调用函数的call指令中。这整个过程称为符号的重定位。
(4)可执行文件的组成格式是什么?它为什么可以执行?它从哪开始执行? CPU怎么知道它从哪开始执行?
分析可执行文件run的组成格式
readelf -h run获取可执行文件的头部信息


可以看到入口地址已经不是0地址了,正是main函数的地址。
程序的运行,进程:
(1)./a.out 创建虚拟地址空间到物理内存的映射(创建内核地址映射结构体),创建页目录和页表。
(2)加载代码段和数据段。
(3)将可执行文件人入口地址写入CPU的PC寄存器中
可执行文件的组成格式

可见可执行文件组成较.obj文件组成多了program headers,前面提到了可执行文件是按照页面进行组织的,可是现在看来它的对齐方式还是按照四字节,需要搞清楚这个问题就需要搞清楚program headers中到底有什么?
readelf -l run输出program headers头部信息

会看到两个LOAD项,其对齐方式为0x200000即2MB对齐,由于我的机器是64bit操作系统,实际上在32bit系统下对齐为4KB,按照页面对齐的。
这里的两个LOAD页非常重要,第一个LOAD页.text,可读可执行,第二个LOAD页可读可写包含了.bss和.data。这两个LOAD页面指示了操作系统LOADER加载器要把当前程序的哪些内容加载到物理内存上。

为什么之前讲可执行文件的组织方式是页面,就是为了之后方便映射。包括虚拟地址空间和物理内存都是以页面进行组织的。而从磁盘到虚拟地址空间的映射是由mmap函数的映射,而虚拟地址空间到物理内存映射是多级页表的方式进行映射的,属于操作系统的内容。关于多级页表映射方式我会独立写出一篇相关的博客。
strace ./run跟踪一下可执行文件run成为进程后所涉及到系统调用等信息。

这里可以看到许多mmap系统调用函数。
为了方便观察进程执行后虚拟地址空间的布局,不能让程序直接跑完,需要添加一些输入,设置阻塞。
#includegcc -o run *.c
./run &放到后台执行

cat /proc/2508/maps查看run进程虚拟地址空间

相信自习看完本篇的内容,大家一定会对编译和链接过程有新的理解,这对我们写出高效的代码是非常有帮助的。