dwz....
描述:在DWZ版中lookup的处理机制与经典的完全不同,对于lookup有两种展现形式,一种是通过点击lookup图标弹出对话框后带回选中的值,另一种是通过在文本框中输入相应信息从而实现联机式的查找带回效果。从实现目的来看,无非是让lookup的实体的主键值带回到hidden的一个元素中,而其它值只是作为显示参考之用,与底层的数据库结构与数据库表无关。一个完整的lookup由如下html元素构成:1)一个hidden用于保存带回实体主键的ID值;如果要实现缺省的lookup过滤或排序可以相应的pageInfo的hidden元素,具体实现方式的用例参见《HowTo手册》;2)n个text用于显示带回的多个数据带回项(注意:因为带回的数据项与数据访问层也就是数据库表无关,因此每个text的name都有一个hi_作为前缀);3)一个lookup有且只有一个主带回项,只有主带回项的文本框是可编辑的并且只有主带回项会有lookup图标也就是html的中的a元素。
| 扩展属性名 |
描 述 |
|
| lookupGroup |
lookup组可以理解为当前实体的名字,如果当前lookup组件是主实体中,则lookupGroup就是实体名,如果当前lookup组件在从实体(也就是明细表的lookup)中,则lookupGroup就是明细的集合属性名 |
|
| lookupName |
lookup名可以理解为当前lookup实体的属性名。从整体的DWZ框架来分析,实际上所有的tab都在一个IE窗口,也就是说JS文件在打开浏览器只会加载一次。这就产生了必须要保证每一个html元素的唯一性,即使是在不同的tab下也是如此。对于lookup来说,是通过lookupGroup+lookupName来确定元素的唯一性的。 |
|
| suggestClass |
主带回项才会有该属性,实现联想查找带回 |
待lookup实体的POJO类的全限定名 |
| searchFields |
查询过滤的属性名列表,以逗号分隔。例如带回HiUser,该属性的值为”fullName,userNum”,在文本框中001则平台会查询姓名或者是编号为001的所有用户 |
|
| callback |
回调方法名,在查找带回值后系统会回调该属性的值的方法,以实现您对带回后的特殊处理。例如callback=fun,那么在带回值后系统会自动调用fun方法,并会自动传入两个参数fun(json,index),其中json:是带回的完整json对象,index:是索引值,主要用于明细的带回时要提供是第几条明细记录 |
|
场景描述:一个会员编辑页面要指定该会员所在的省份、城市、地区,要求在选择省份后会自动过滤该省份的城市,地区以此类推。
以下所有步骤只是修改OrganizationEdit.jsp文件,即可
步骤一、为省份的主带回项加callback回调方法,并在实现该js方法
<input type="text" class="textInput" name="organization.hi_province.name" value="${organization.province.name}" callback="processProvince"
function processProvince(json){
document.getElementById("pageInfo.province.f_id").value = json.id;
} //该方法的目的是在选择某个省份后将该省份的ID值放到指定的hidden元素中
步骤二、为城市加一个用于过滤的hidden元素,注意:processProvince()方法中的赋值语句就是该hidden元素;用于过滤的name必须与PageInfo的具体类相对应;必须要指定lookupGroup与lookupName
<input type="hidden" lookupGroup="organization" lookupName="city" name="pageInfo.province.f_id" id="pageInfo.province.f_id" value=""/>
步骤三、为城市的主带回项加callback回调方法,并在实现该js方法
<input type="text" class="textInput" name="organization.hi_city.name" value="${organization.city.name}" callback="processCity"
function processCity(json){
document.getElementById("pageInfo.city.f_id").value = json.id;
}
步骤四、为地区加一个用于过滤的hidden元素
<input type="hidden" name="pageInfo.city.f_id" id="pageInfo.city.f_id" lookupGroup="organization" lookupName="region" value=""/>
总结:级联下拉实际上是lookup的一个变种形式,主要的思想是为你要级联的下拉的lookup加入过滤项,例如在城市加一个省份的过滤项,在选择省份时后,会通过回调方法将这个过滤项的值存到该过滤项中。这样逐级过滤就实现了级联下拉的效果.
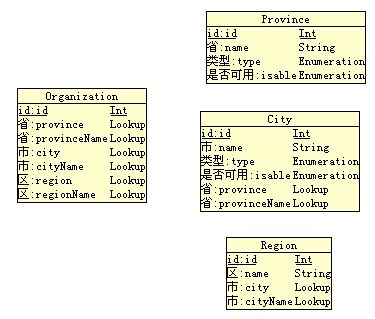
大家可以简单将J-Hi建模工具理解为数据库的E-R图,每个实体就对应一个数据库的表,而实体中每个属性就对应数据库表的一个字段。那么实体与实体之间的关系或表与表的关系又是如何描述的呢?
对于数据库表的关系大体可分为,如下几种形式
many-to-one:相当于一个数据库表的字段(外键)对应另一张数据库表的主键,对于J-Hi来说,就是一个lookup(查找带回)。即一个实体中的某个属性是lookup类型,这个属性会lookup另一个实体。对lookup定义的操作步骤请参见“应用开发视频”。页面中的展示形式,例如你有一个报销单,要lookup用户,那么平台就会自动将用户的名称带回来,并在数据库中将用户的ID值保存到报销单表的相应字段中。
one-to-many:相当于一个数据库表下面会有一个或多个明细表,例如一个报销单是主表而报销单明细是明细表。在数据库端的实现形式为,在明细表中有一个主表的外键ID字段。在J-Hi中我们称之为引用,具体操作见联机帮助
one-to-one:所谓一对一的关系在数据库上的理解为,B表每加一条记录A表也会随着增加一条记录,在J-Hi中的表现形式为实体继承
对于实体的继承,不只是简单的表one-to-one关系,实体的继承还包括所有的java类的继承关系,JSP页面的整合等等
many-to-many:多对多是一种复杂的表关系,J-Hi是通过中间过渡表来实现这种多对多的关系,例如一个项目可以有多个成员,而一个成员又有可能在多个项目中,建模的图为

1.前台页面:
//自定义一个回调函数ajaxDone
本文主要讲解J-hi中树的过滤。以员工部门树为例。
要求在点击某个员工时,能够查看到该员工所在的部门。
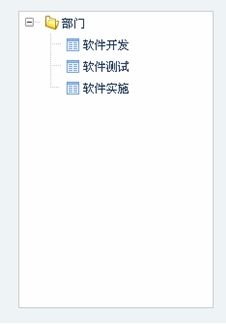
图1-部门树
下图2是所有员工列表:

图-2
当点击王五时,显示王五所在的部门结构树如图3。

图-3
主要代码部分:
1、Jsp超链接代码:
<a
href="tree.action?menuName=orgList&orgId=${item.org.id}" target="dialog">${item.org.orgName}
注意:orgId是动态传入的参数,这里指该员工所在的部门编号。
2、在himenu-config.xml中配置部门树的后面加上这么一段
<void property="filter">
<string>org.cis.filter.orgCollectionProcessorstring>
void>
注意:string标签内的是写过滤数据的类。对树的数据进行过滤,提供两种接口方式对数据进行过滤 MenuFilterProcessor 在获取数据之前填加过滤器;MenuCollectionProcessor 在获取数据之后再对数据做整理.具体方法查看java-doc的API。
而例子的orgCollectionProcessor类代码:
public class orgCollectionProcessor implements MenuCollectionProcessor {
public Collection getCollection(Collection coll, Map
// TODO Auto-generated method stub
//coll - 当前节点下一级节点的数据集合
//map 动态的传入数据,以map的形式
//传入一个员工的所在的部门Id,返回该员工所在的部门结构树
int orgId=Integer.parseInt(map.get("orgId").toString());
for (Iterator iterator = coll.iterator(); iterator.hasNext();) {
Object obj = (Object) iterator.next();
if(obj instanceof HiOrg){
HiOrg hiorg = (HiOrg)obj;
if(hiorg.getId()!=orgId) {
iterator.remove();
coll.remove(obj);
}
}
}
return coll;
}
}
注:该文档由J-Hi爱好者"无可"提供,他的QQ号为924372739,欢迎大家与他在技术上多多交流
树形菜单能很好的呈现菜单项之前的从属关系,结构清晰明了。J-hi平台提供了自定义树形菜单的功能,通过简单的配置即可实现。
本文主要介绍通过树形菜单选择带回节点值的实现方法。以选择带回行政区划位置为例。
数据库表设计:

默认带回页选择界面:

通过jhi自动生成代码的功能,对于lookup xzqhwz的字段默认是如上带回页面,显然并不能表现行政区划位置之间的主从关系。
树形带回页面:
而如果实现如下页面的展示,将会清晰方便许多。

双击即可带回节点,也可通过配置带回节点的各级父节点。
下面是配置的方法:
配置方法:
修改xml
修改C:"Program"hi-studio"eclipse"workspace"earch5"web"WEB-INF"config"himenu-config.xml
在代码末尾:
object>
java>
之前插入:(注意修改其中参数)
<void method="put">
<string>zdtreestring>
<object class="org.hi.base.menu.strutsmenu.WebDynamicMenuDefine">
<void property="keymap">
<object class="java.util.HashMap">
<void method="put">
<string>idstring>
<string>parentxzqhwzstring>
void>
object>
void>
<void property="parent">
<string>idstring>
void>
<void property="child">
<string>parentxzqhwzstring>
void>
<void property="childValue">
<int>0int>
新版本jhi应为:
>
void>
<void property="menuName">
<string>zdtreestring>
void>
<void property="beanName">
<string>org.hi.zdtree.model.Xzqhwzstring>
void>
<void property="submenuName">
<string>zdtreestring>
void>
<void property="title">
<string>行政区划位置string>
void>
<void property="titleField">
<string>xzqhwzstring>
void>
<void property="needShow">
<boolean>trueboolean>
void>
<void property="javascript">
<string>
function backAgent(id,orgName){
if(opener.document.getElementById('yzjbxx.xzqhwz')!=null){
opener.document.getElementById('yzjbxx.xzqhwz').value=orgName;
}
>
else{ opener.document.getElementById('xzqhwz.pxzqhwz').value=orgName;
opener.document.getElementById('xzqhwz.parentxzqhwz.id').value=id;
window.close();
}
}
string>
void>
<void property="action">
<string>{js}backAgent([#id],"'[#xzqhwz]"');string>
<string>{js}backAgent([#id],"'[#parentxzqhwz.parentxzqhwz.parentxzqhwz.xzqhwz][#parentxzqhwz.parentxzqhwz.xzqhwz][#parentxzqhwz.xzqhwz][#xzqhwz]"');string>
>
void>
object>
void>
修改XzqhwzEdit.jsp页面
将C:"Program"hi-studio"eclipse"workspace"earch5"web"zdtree"XzqhwzEdit.jsp中
οnclick="xzqhwz_lookupPOP('parentxzqhwz')"
改为:
οnclick="window.open('/tree.action?menuName=zdtree','部门','width=300,height=500,left=10,top=20,location=no,status=no')"
这样,到Xzqhwz的页面,点击父节点的带回按钮即可看到效果,同样lookup到xzqhwz字段的地方也修改Edit.jsp页面的onclick动作就行啦。
该文档是对J-Hi树形的入门级介绍,J-Hi的树功能还有:节点的过滤,lazy加载,一个节点可以多个图标、复选框效果,多个实体组合形成一棵树,我们将在以后继续讲解
注:该文档由J-Hi爱好者"冯思豪"提供,他的QQ号为382600911,欢迎大家与他在技术上多多交流
信息内容
1)菜单中“权限”、“权限资源”将不在显示,因为一旦将做好的项目发布后,这些信息是不能让客户维护的。
2)菜单中“触发器”、“消息管理”将不可见,因为一旦定时服务设定好,一般来说客户很少会调整,即使是调整也应该是由开发人员来调整触发的周期与频率。对于消息管理也是一样。
3) 整个“国际化”菜单项全部不显示,这其中包括“多语言参数”、“语言编码”、“时区”,原因这些内部均应该在开发过程中将信息内容一并编辑完成。比如有一个语言编码就要有一套多语言参数与之对应,因些一旦系统上线,所有国际化部分的维护功能也应该同时完成。
4)“应用配置”列表中,“删除”图标将不再显示,因为如果系统上线,系统中的一些基础配置项是不能删除,而只能更改的
对于这个功能的控制,是在main.jsp中,加入一个变量,代码如下
< ws:set name ="published" value ="@org.hi.framework.HiConfigHolder@getPublished()" />
安全
如果采用了发布模式后,页面提交的URL将会被加密,而开发模式URL则是以明文显示,开关则试前后URL的效果如下:
http: // localhost:8080/hiUserEdit.action?cf4a9619dd97fc2689fb63048237404f
效率
1)如果是发布模式,DWZ版的所有js文件将采用压缩的文件,而非一个一个的离散文件,这样系统的传输的内容会更少,具体的方式参见styles.jsp文件
2)如果是发布模式,系统在启动时一次性加载 枚举实体、 枚举值、 多语言参数、 应用配置这些常量性的信息进入缓存,在取这些信息时系统会自动从缓冲中取而并非每都要查询数据库。举例来说,性别是一个下拉的枚举,如果是发布模式只直接从缓冲区中取数据,而如果是开发模式它就会去数据库中取数据,如果是一个人员列表,那么有几个要显示枚举的地方就要去数据库取几次。因此开发模式的运行效率要远远低于发布模式,但开发模式更有实效性,只要数据有任何变化都可以实体的反应出来,即使是在同一个事务中,而发布模式只能在一个事务完成之后再能做数据同步处理(即内存与数据库之间的数据同步)
J-Hi与DWZ两个国内优秀的开源项目强强联合,携手推出J-Hi4DWZ版。


登录页面

首页面

J-Hi生成器生成的编辑页面:使你不用写任何一行代码就能实现富文本编辑、页面校验、上传附件、自动带回、主从表编辑等功能

角色分派页面:可以看到平台提供左侧树型结构(无需任何编码,简单配置即可)
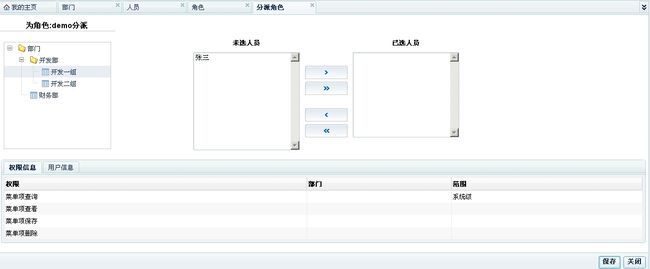
当然树还可以做成是弹出带回值效果

更新日志:
1、融合DWZ富客户端做前端页面展示
2、支持跨浏览器包括IE6\7\8\9 FireFox等
3、实现webwork与struts2无配置文件解决方案
4、插件增加悬浮联机帮助
5、支持实体复制
1、解决登录用户的信息与数据库信息不一致的问题
2、解决多语言标签缓存问题
3、生成时如果有从表不在菜单显示
4、解决在struts下角色、权限、人员会有垃圾数据问题
5、增加二个对菜单树的过滤的接口,及回调实现
6、修改了对菜单树非整数型的配置方法
7、解决加删除标识符的实体未做过滤的问题
8、优化了webwork和struts的基类BaseAction
开发人员列表:
| 人员 |
主要工作 |
| 张慧华 |
与dwz集成,富客户端开发 |
| 杨新峰 |
Eclipse插件开发 |
| 张昊 |
生成器及底层开发 |
| 肖金华、尹福泉 |
修改平台功能页面,修改bug |
测试人员列表:
罗天文、伏占才、宋艺、肖金华、张昊
下载地址:http://code.google.com/p/j-hi/downloads/list
J-Hi:http://code.google.com/p/j-hi/
DWZ:http://code.google.com/p/dwz/
线上交流:133176937(满),133177634(满),133178083,134232577
相关文章:写在J-Hi for DWZ版发布的前夜
J-Hi快速开发平台到底快速在哪里?
“J-Hi”Java开源平台的生力军
下一步计划:
1) 融合SpringJDBC
2) 支持实体从数据库反向导入并生成代码
3) 支持树形组件的可视化配置
1、快速上手,降低学习曲线
对于刚刚接触J-Hi的人来说,它上手很容易,我们为每一个功能点都提供了悬浮帮助功能,即使没有任何资料(当然我们已提供了视频与开发文档),您也可以通过向导与帮助在十分钟之内就可以创建出您自己的项目原型。

其次J-Hi平台采用的大都是大家耳熟能详的主流框架与技术,如果您对主流的框架有所了解,那么对J-Hi的学习就没有任何阻力了。
2、快速搭建开发环境
也许您因为项目或自身开发团队的不同会采用不同的框架技术,例如您团队中对struts2熟悉的人远远要比掌握webwork的工程师要多,或者在您的项目中统计分析的功能很多,您要考虑ORM的效率问题,而不得不放弃hibernate而采用ibatis或springJDBC,也许您还要考虑数据库问题等等。在搭建开发环境您一定会考虑很多因素,尽管搭建开发环境并不复杂,但还是不够自动化,还要手动的配置,费时费力。J-Hi为快速搭建开发环境提供合理的解决方案,您可以按需求动态的搭建开发环境。

在此您可以选择不同的ORM框架

在此您可以选择不同的表现层框架

在此您可以选择不同的页面框架,并且我们提供了“预览”让您在搭建开发环境之前就可以看到搭建后的页面显示效果

在此您可以选择不同的数据库。
3、快速生成所有代码
通过建立或导入模式,您可以快速的生成所有代码与文件,并且在生成时会根据您选择的框架技术与数据库的不同而自动适配。
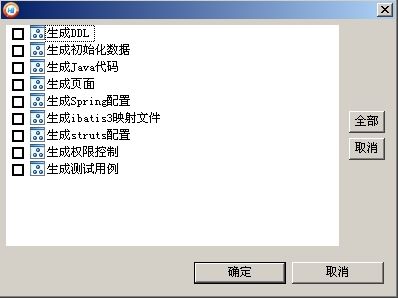
当然您还可以有选择的生成部分代码文件,例如只生成JSP页面,或只生成java代码。生成的java代码结构如下(因为我选择的框架是ibatis3+struts2,所以平台会自动匹配只生成与这两个框架相关的类文件,而不会生成无用的其它框架的东西):

4、快速解决在业务需求中的技术难点
一般我们在做项目开发时,总是要等到项目开发的中、后期才能去解决业务核心问题,因此很造成无法合理估计项目的技术风险。原因是复杂的业务总是要等到基础模块建好后才能进入到开发阶段,从而使解决核心的技术问题置后。我们以一个报销为例来做个简单说明,比如报销在审核后的业务逻辑很复杂并且有可能还要涉及到与其它的系统对接。一般来说我们总是要等到这个报销单建好,起码要有最基本的增删查改功能(即使没有页面也要有后台的代码)后才能进入到核心业务的开发,这就加大的技术风险,因为我们会很早的发现问题,但解决这些问题却远远的落后于发现这个问题,甚至到了开发的中、后期因为技术问题在底层上还要一改再改。而使用J-Hi可以很快的进入到业务核心的技术上,因为只要生成,基础功能就已经提供,甚至平台还为您提供了单元测试用例类,从而使您可以直指业务核心,将项目风险控制在最低。
5、通过提供通用的组件
平台提供了很多通用业务组件,例如组织机构、角色权限、报表、定时任务、菜单管理、日志管理、系统配置、附件上传等等,除此之外平台还提供了一些纯技术组件,例如树型结构、java脚本工具、编码生成器、可选择性的返回JSON对象等等。这些通用的业务组件与技术组件可以为您在开发过程节省很多时间,随需使用,从而大大降低开发速度。
6、通过服务的复用性提高开发速度
在介绍平台的服务复用性之前,让我们来举个例子。比如您做了一个OA项目其中有一个模块是报销管理这个模块很成熟,您已经在OA系统中应用了很久。现在又有一个ERP系统,您想把这个成熟的报销管理复制到ERP系统中,这样这个功能就不用在ERP系统中再做开发了。对于平台来说这就是服务的复用性,我们提供了一整套对服务复用性的解决方案,并且有自己的可视化工具。
我们叫它J-Hi整合工具,是用C#做的。它的作用:
1)可视化导入/导出数据库,并同时实现跨数据库,例如您可以在mysql上开发(导出),开发完将所有的数据迁移到oracle上(导入)。
2)发布器,可视化将您开发的模块或系统自动发布成一个发布包(包括数据库、jar、文件[jsp、js、图片、配置文件等]还包括文件的片段[例如修改web.xml文件中的一部分内容])
3)部署器,将发布包部署到开发的工程中,部署的内容见发布器的描述
4)实施器,对应的生产系统,我们通过FTP,将相应的文件与数据库自动部署到生产系统中
7、快速的部署与迁移
也许您正在为客户要求从SQLServer数据库改为Oracle而感到苦恼,因为这要做大量的数据迁移工作,或许您反复的将修改后的bug部署到生产环境中而郁闷,我想J-Hi通过它的整合工具为您提供了便捷的方式。具体的实现方式请参见上一节的介绍
8、开发人员可以快速的接手别人的工作
因为使用J-Hi开发,生成的代码与文件的风格都是相同的,在哪里写业务逻辑应该怎么写?在哪里要改页面应该怎么做?想要到哪张数据库表或表与类的对应关系?包括生成的类、JSP文件、配置文件的命名规则都是统一的。因此一个新人加入团队会很容易的上手并进入工作状态,即使是修改别人写过的代码,也会很快速的定位到相应要修改的位置。
9、快速解决需求变更
对于项目开发来说,项目的需求变更是很正常的事情,对于有经验的项目经理来说,如果一个项目从未发生过需求变更过反而是不正常了:)一但需求变更大多都要改数据库表,如果是已运行很稳定的系统,这种变更真是要命。J-Hi为此也提供了自己的解决方案,对于简单表变更,平台只要对单个实体生成就可以了。如果是复杂的变更,我们还提供继承实体的解决方案,也就是说原来的所有代码与表结构都不变,通过实体继承J-Hi会从数据库表到java类再到JSP页面形成一整套继承关系,从而保证以前功能的稳定性。这个说来好象很玄妙,让我们举例说明。比如你有一个部门表,N多信息都与它有联系,而且做了很多的业务处理,现在客户要求在部门表中加另一些信息。对你来说可能会为部门表中加字段,由此而带来所有类的变化与页面的变化,而这套系统已经很稳定已经用了一、两年了,开发人员都已经离开了公司,这样接手的人要读懂全部代码才有可能改,这样就造成开发速度的大大降低。平台提供了另一种解决方案:不动以前的任何东西,相关于在原有的基础上打上一块补丁。再做一张表,让这张表与部门表形成one to one的关系,而类无论是POJO、DAO、Service都继承自部门相应类作为父类,同时在JSP页面上也会继承所有部门的所有元素,这样就形成了实体继承关系,这就好比设计模式中最基本的“开闭原则”,对于所有的新生功能是开放的,而对于已有的老功能是关闭的,可以完全把老的功能视为一个黑箱。这样即能保证已有功能的稳定性,又能加入新的功能做为补充。
1、在struts.xml或xwork.xml加如下配置信息

< result name ="auto" > /${proxy.config.packageName}/${proxy.method}.jsp result >
global-results >
2、在BaseAction类中加入proxy的方法实现
public ActionProxy getProxy(){
if(proxy == null)
proxy = ActionContext.getContext().getActionInvocation().getProxy();
return proxy;
}
3、做一个JSP文件,文件名一定要与action的方法名相同,列如:a.jap那么action的方法的写法
return AUTO;
}
4、在某个Jsp页面中调于这个无配置actoin的写法
actionName!a.action
分析
ActionProxy类是struts2或webwork提供的一个action代理类,它的作用是它的作用是记录当前这个action的对象 、action的名称 、配置信息及该action所属的包名等信息。该接口的声明如下
/**
* @return the Action instance for this Proxy
*/
Object getAction();
/**
* @return the alias name this ActionProxy is mapped to
*/
String getActionName();
/**
* @return the ActionConfig this ActionProxy is built from
*/
ActionConfig getConfig();
/**
* Sets whether this ActionProxy should also execute the Result after executing the Action
*
* @param executeResult
*/
void setExecuteResult( boolean executeResult);
/**
* @return the status of whether the ActionProxy is set to execute the Result after the Action is executed
*/
boolean getExecuteResult();
/**
* @return the ActionInvocation associated with this ActionProxy
*/
ActionInvocation getInvocation();
/**
* @return the namespace the ActionConfig for this ActionProxy is mapped to
*/
String getNamespace();
/**
* Execute this ActionProxy. This will set the ActionContext from the ActionInvocation into the ActionContext
* ThreadLocal before invoking the ActionInvocation, then set the old ActionContext back into the ThreadLocal.
*
* @return the result code returned from executing the ActionInvocation
* @throws Exception
* @see ActionInvocation
*/
String execute() throws Exception;
/**
* Sets the method to execute for the action invocation. If no method is specified, the method provided by
* in the action's configuration will be used.
*
* @param method the string name of the method to invoke
*/
void setMethod(String method);
/**
* Returns the method to execute, or null if no method has been specified (meaning "execute" will be invoked)
*/
String getMethod();
}
J-Hi借用了这个代理类,在action的基类也就是BaseAction中添加了对该类实例的引用,从而实体全局配置
< result name ="auto" > /${proxy.config.packageName}/${proxy.method}.jsp result >
其中 ${proxy.config.packageName}用来指定当前action所属的包名,例如,"testjs"就是配置文件的包名
< package name ="testjs" extends ="hi" >
< action name ="materialList"
class ="org.hi.testjs.action.webwork.MaterialListAction" >
< result name ="success" > /testjs/MaterialList.jsp result >
< interceptor-ref name ="modelParamsStack" />
action >
.xwork >
name="auto" 是我们特意为这样无配置的actoin起了一个特定的名字,也就是说
return "auto";
或
return AUTO;
}
我们特意将这段result的配置放在了 < global-results > 中原因是省去写配置文件,只要是return "auto";就会调用这个结果。那么它的结果是什么呢?对,是一个JSP,也就是说你通过actionName! method.action后, 系统会自动执行这个方法,并自动调用这个aciton所属包名下的与方法名相同的jsp文件。例如配置文件的包名为"testjs",actionName为"materialList",对应的class为" org.hi.testjs.action.webwork.MaterialListAction",你在这个action类中增加了一个a(),想通过调用该方法实现无配置调用jsp,那么你就应该将这个jsp文件放到web/testjs(与包名相同)目录下,并且该jsp的文件名为a.jsp(与方法名相同)。调用这个action方法的写法如下: materialList!a.action。OK,大工告成!!
技巧
为了适应不同人对action的开发习惯,J-Hi对struts2与webwork的生成方式是不同的。struts2是所有的操作都放在一个Action类中通过方法调用,而webwork是每个一操作一个Action类。两种方式均有优势也优有不足之处,大家在使用时全凭自己的习惯就好。我们之所以实现无配置,主要是考虑到J-Hi它不只是一个开发管理系统的平台,也应该可以做网站或电子商务前端的开发。我们知道对于后台管理系统主要考虑的是系统安全性(页面的布局与样式风格要统一),而网站或电子商务前端恰好相反,它追求的是安全不是问题因为它欢迎更多的浏览者不需要对每个操作都做权限控制(页面的风格也五花八门,炫、酷不规则是这类系统的特点)。因此提供了无配置文件的方式,以满足这类需求(当然纯页面还是要由美工来完成,无规则平台的生成器是无法胜任该工作的)。由此而带来的另一个问题是,平台已经生成了很多aciton的功能,如何让前台与后台共用这些已生成的action类呢?下面我们以struts2为例
在BaseAction中有一个 protected String returnCommand()方法,该方法是确定返回的结果的名字
String viewMode = HiConfigHolder.getViewMode();
if (viewMode.equals( " dwz " )){
if ((ajax == null || ! ajax.trim().equals( " 1 " )) && message == null )
return SUCCESS;
if (message == null )
return ajaxForwardSuccess(I18NUtil.getString( " 操作成功 " )); //如果是dwz版就返回一个json对象的字符串
else
return ajaxForwardError(message);
}
return SUCCESS; //如果是经典版就返回success字符串
}
if ( this .getRequest().getRequestURI().indexOf( " ! " ) > 0 ) //如果在URL中包含!就说明是无配置的,它就会返回auto
return " auto " ;
return super .returnCommand(); //否则就走BaseAction也就是父类的retunCommand()方法
}
例如struts的action配置文件如下
< package name = " testjs " extends = " hi " >
< action name = " materia l"
class = " org.hi.testjs.action.struts.MaterialAction " >
< interceptor - ref name = " modelParamsStack " />
action >
.
struts >
安装插件后的eclipse启动不能创建hi项目 或者点完成时 很快就回到当前页面。
在eclipse ![]() 创建 eclipse.exe 的快捷方式
创建 eclipse.exe 的快捷方式
在快捷方式右键查看属性 在目标后面加上 -clean

双击快捷方式启动eclipse
就ok啦
启动tomcat时报错
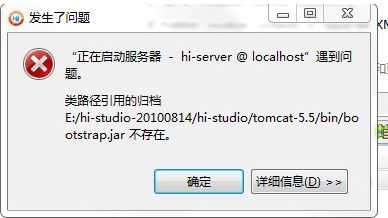
把默认的删除
新建服务器

点完成 就ok
注:该文档由J-Hi爱好者"罗天文"提供,他的QQ号为610817750,欢迎大家与他在技术上多多交流
知道许多代码技巧、JS炫彩技巧的人大有人在。你知道多少个.net函数,这一点都没有意义。你知道多少个新鲜IT名词,多少技术介绍,这也没有意义。做,真正做一个原型,做一个项目,解决你手头棘手的问题,这才有意义。
1、快速准确的理解别人说的-〉
2、快速的开发,还准确的反映了别人的需求-〉
3、稳定,最少出BUG-〉
4、高性能,10万条记录你能顶住,1000万条记录你能顶住吗?这就是技术功底的考验
5、这还不够,你的代码是否能让别人快速的理解了
6、你的代码是否能比较容易的接受不同客户的需求差异
这都是处处要你的分析功底、架构功底、编码功底。
二、怎么炼成高手?
1、阅读优秀的开源源代码。先找代码量不大的。要彻底的阅读,剖析清楚有多少个类,这些类的关系。为什么要设计这样的类架构,为什么要这样设计接口。这些思考相当有深度。
2、根据你的需求,把开源源代码进行修改。因为开源源代码是浑然一体,你加的功能是否很好和现有代码融合。这相当考验功底。
3、 读书,谁发明的这个东西就读谁的书。如想学 SQLSERVER,就一定要读SQLSERVER开发经理或技术小组写的书。别人写的书都会有歧义。要读透,反复阅读它的设计原理。不要只学会使用。比 如说SQLSERVER,写SQL和SP就是懂SQLSERVER?我们一定要明白到SQLSERVER的数据页面是如何组织的,为什么要这样组织,它是 怎样被载入内存中,它又是怎样回写到物理设备上。我们要到这个深度。否则,你只能是知道个皮毛,平时看是高手,一到真正难关立马歇菜。
如果你学的技术还不能帮助你解决你目前手头的问题,说明你还学的不到位。
4、 找到你的师傅。一个人的成长,很难是自己一个人苦苦学习摸索修炼。这样提升很慢。你如果想快速发展,你必须找到你在这家公司中的引路人。他可能是你的入职 指引人,也可能是别人。你一定要好好观察,看中了就一定要积极联系上他紧紧的跟随着他,平时多请教多观察他的思考方式做事方式。
5、给 自己树立一个信念:我要在X年中成为公司所有人公认的技术高手。我要在X年终成为中国软件业一流的程序员。必须设立目标,而且时时刻刻为这个目标奋斗,坚 持每天阅读、思考、开发、修改代码达到13-16个小时以上。有一个故事讲的就是每件事要想做专业必须要经过1万个小时的反复练习才能成功。对,我说的就 是这个意思。不疯魔不成活。
一个成功的产品的诞生是多么的曲折与艰难,中间会经历多少商业竞争机缘巧合,也会浮现多少独当一面的代码英雄。
一个人有没有可能成为软件高手,他是有一种说不清的气质的,你知道那就是程序员精神,他是与众不同的,你能明显感觉的到。
作为我个人,在技术上我是一直关注数据架构层、Java架构层、前端架构、和大型Web应用与研发。在业务上,我一直关注电子商务、互联网生活服务/互联网营销/互联网客户关系社区、Web前端技术。 最后一句话:
美到极致是疯狂。希望大家在平时工作中开发每一个产品时,都能暗下决心:It's My Baby!
对,它就是你创造的孩子,你要用心去雕琢它呵护它。
全文转至张慧华的博文URL: 美到极致是疯狂
J-Hi在没集成DWZ之前页面端一直是它的软肋,之所以没有对富客户端的支持原因有三
1)我自身的原因,始终认为过多的引入ajax会降低开发速度,增大了使用者的学习曲线,增大了开发工作量
2)团队内部原因,J-Hi核心团队成员对js与页面美工技术能力还很簿弱
3)我一直没有找到中国人自已做的设计优秀,而又不影响开发人员针对JSP的开发习惯的开源架构做集成
有一天一个朋友(张国勇)给我推荐了DWZ,简单的分析了一下它的运行原理,我一下子就喜欢上了它,原因如下:
1)它是国产的,尽管内核仍采用的是JQuery,但在使用时基本上可以脱离JQuery,也就是说你可以基本的认为JQuery是一个黑箱
2)它足够轻量,内核很小加上JQuery压缩后只有160K左右
3) 它尊重开发人员的开发习惯,js部分的处理全部交给DWZ,只要在html中指定相应的class就可以。也就是说除非业务必须否则开发人员根本不用写js代码
4)页面与局布是通过JSP渲染,而不象ext等其它的富客户端框架纯js实现,这样更方便开发人员对页面的控制
后来通过网络我认识了DWZ开发团队核心成员张慧华,给我的第一印象他是待人谦和,不善言谈的人。我到现在还清楚的记得我们第一次见面的情景,我在我们约好的公交车站等他,他抱着他的女儿来接我,心情平静而又谈吐随意。本来这一切都很平常,然而通过后面的聊天,却让我对他,对他的心态与人格肃然起敬。
我寒喧的问他“这是你女儿?”
他说“是,这是我大女儿”
我开玩笑的说“你真行,难不成来有一个小女儿?”
他说“对”
我说“你的小女儿在那里,我怎么没看到呀?”
他说“住院了”
我对“孩子怎么了?得了什么病?”当时我就在想每个为人父母的,孩子病了都会很难过
他说“小女儿得了白血病”
我听到这里,一下惊呆了,不自禁的看了他一眼,他还是那样心态平和。如此的大事在我和他聊天过程,他始终没有情绪上的变化,反而是我心情跟着他的谈话起伏不定。当时我在想,如果这事放在我的身上,我早就象热锅上的蚂蚁,焦躁不安了。这是怎样一个人,怎样的一个心态啊?如此淡定,达观的人生态度,我还第一次见到,对他充满敬意。
随着后来我们接触的越来越多,我看到他正像他说的一样“我尽我最大的能力去做我该做的事情,无论结果如何起码问心无愧,不会后悔”--每周都往返于医院、家里和公司之间,有时还要在医院通宵的护理他的小女儿(因为要化疗)--我看他真是辛苦,看着他这样我都觉得疲惫,我想这种疲惫不只是肉体的也许心理的更大吧!然后我却从来没有听到他的一句怨言,甚至是述苦的话。我也从未安慰过他,我想如此坚强的人我的安慰是多余的。
后来他答应帮助我做J-Hi对DWZ的融合工作,在工作过程中我更是对他超强的精力与娴熟的技术佩服不已,因为我负闲在家,所以每天都在凌晨两点多睡觉九点多起床,因为我们总是在QQ上实时联络,而他每天都是凌晨一点才会休息,他的公司与家离的很远,每天六点半就要起床,如此精力充沛的人我还真是头一次见到。他是一个工作狂,对技术有狂热的兴趣。我自认为自己对技术是一个近乎偏执的狂人,而与他相比,看来我把自己高估了。
明天J-Hi for DWZ bate版就要发布了,我对曾经帮助过我的人充满感激,特别是张慧华这里面不只是感激更多是敬意。我很庆幸有一个团队,有大家的帮助,更有象张慧华这样的朋友!
Svn简介
Subversion简称svn是一个自由/开源的版本控制系统。也就是说,在Subversion管理下,文件和目录可以超越时空。也就是Subversion允许你数据恢复到早期版本,或者是检查数据修改的历史。正因为如此,许多人将版本控制系统当作一种神奇的“时间机器”。
Subversion的版本库可以通过网络访问,从而使用户可以在不同的电脑上进行操作。从某种程度上来说,允许用户在各自的空间里修改和管理同一组数据可以促进团队协作。因为修改不再是单线进行,开发速度会更快。此外,由于所有的工作都已版本化,也就不必担心由于错误的更改而影响软件质量—如果出现不正确的更改,只要撤销那一次更改操作即可。
某些版本控制系统本身也是软件配置管理(SCM)系统,这种系统经过精巧的设计,专门用来管理源代码树,并且具备许多与软件开发有关的特性—比如,对编程语言的支持,或者提供程序构建工具。不过Subversion并不是这样的系统。它是一个通用系统,可以管理任何类型的文件集。对你来说,这些文件这可能是源程序—而对别人,则可能是一个货物清单或者是数字电影。
一个典型的客户/服务器系统:

Subversion版本库的特别之处在于,它会记录每一次改变:每个文件的改变,甚至是目录树本身的改变,例如文件和目录的添加、删除和重新组织。
一般情况下,客户端从版本库中获取的数据是文件系统树中的最新数据。但是客户端也具备查看文件系统树以前任何一个状态的能力。举个例子,客户端有时会对一些历史性问题感兴趣,比如“上星期三时的目录结构是什么样的?”或者“谁最后一个修改了这个文件,都修改了什么?”这些都是版本控制系统的核心问题:设计用来记录和跟踪数据变化的系统。
服务器端软件安装
这里选择用VisualSVN-Server-2.1.7.msi搭建svn版本库服务器。
下载地址:http://www.visualsvn.com/server/download/
一直默认进行安装:
(选择:VisualSVN Server and management Console)

(Location:指的是软件安装的位置。Repositories:是需要svn控制的源码存放的位置。端口保持默认:443)
(Anthentication:身份验证模式,这里注意,如果选用第二个User Windows authentication,可能需要域环境。我选用的第一个。)
服务器配置运行
新建用户
右击左侧的Users,选择新建---User ,新建用户

新建repository(版本库)
选中 Repositories,在右侧的空白区域,选择新建---Repository,输入名字e-test,这样就创建了一个项目
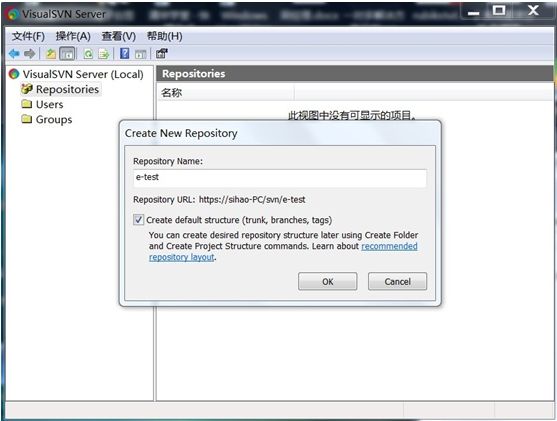
url是:https://sihao-PC/svn/e-test
sihao-PC是我的电脑名,e-test是我的项目名。中间的svn是默认就有的,注意由于我没有加入域,所以在客户端获取的时候要把电脑名换成它的ip地址
赋予用户权限
右击e-test,所有任务--Manage Security 或者properties
把新建的用户添加进去并赋值权限,如下图:

这样就完成了服务器所有内容。
(参考文档:http://hi.baidu.com/sygwin/blog/item/7f2f1217168f0d144a90a793.html)
客户端软件介绍
客户端可以选择TortoiseSVN-1.6.15.21042-win32-svn-1.6.16.msi
下载地址:http://tortoisesvn.net/downloads.html
也可以用eclipse的svn插件:Subclipse
下载地址:http://subclipse.tigris.org/
本文主要介绍用eclipse插件的配置与使用
客户端软件Subclipse的安装
J-hi标准完全版本已经配置好了svn插件,如果没有的话可以用以下方法安装:
Eclipse的使用者可以通过Eclipse的插件自动下载和更新功能来安装这个插件,在Eclipse的菜单中选择Help->Software Updates->Find and Install-> Search for new features to install ->New Remote Site。URL中就输入http://subclipse.tigris.org/update,Eclipse就会自已安装上了。
安装完成后,在Eclipse的plugins中就会多了5个包,命名为org.tigris.subversion.*的都应该是了。打开Eclipse,window->show view窗口中多了一个SVN文件夹,到此就证明svn插件成功的安装上了。具体的使用方法,在Eclipse的Help中有详细的帮助Subclipse - Subversion Eclipse Plugin,教你一步一步的使用SVN的客户端了。如果你对subversion想进行深入的了解,那么看看help中的Version Control with Subversion一定有所收获。据观察,这份文档和sbuversion安装文件中提供的官方文档一样,这里看起来就更舒服些了。
客户端配置
打开svn视图
安装完毕后即可打开svn视图

或者显示视图:
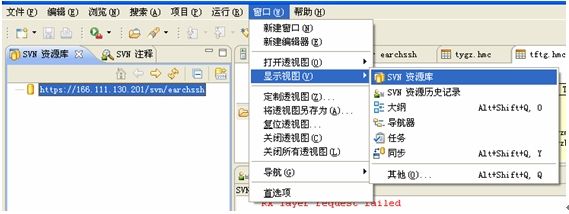
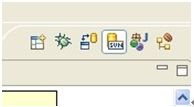
更快捷的方式是在右上角,点击svn视图图标:
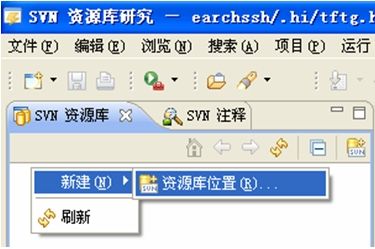
新建资源库
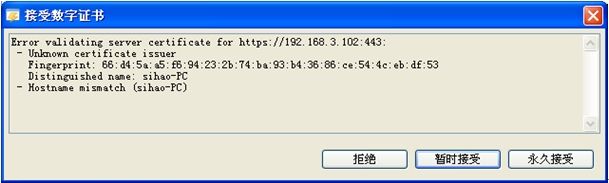
输入url的地址,需要将计算机名转换成ip地址:

选择永久接受:
输入用户名和密码:

如果一切正常即创建了一个资源库:
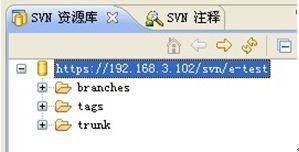
可以看到了服务器上的目录结构。
SVN服务的使用
共享项目
首先需要将现有的项目共享到服务器上:

选择svn,下一步:

选择建好的资源库,也可以在这里建资源库:

设置文件夹名称:

点击完成,及完成了项目的共享与版本库连接。
接下来即可写入项目第一个版本。

运行到98%的时候可能会停滞很长时间,耐心等候即可。

数据提交
这是可以看到小组菜单里的item已经有变化了。
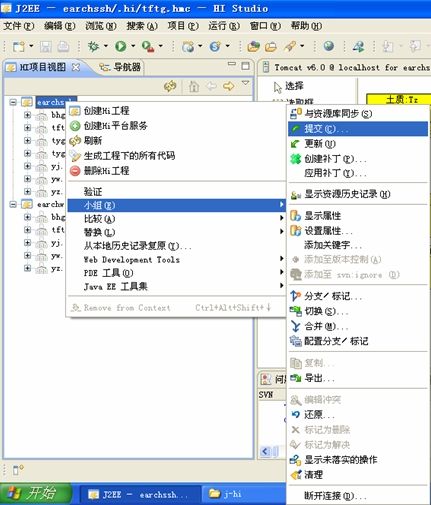
修改程序后,即可提交:

可以看到对程序的改动已经被记录并提示,是否更新到版本库。
点击确定即可将本地数据提交到服务器版本库。
数据下载更新
在小组中点击更新即可将服务器版本库中的版本下载到本地。
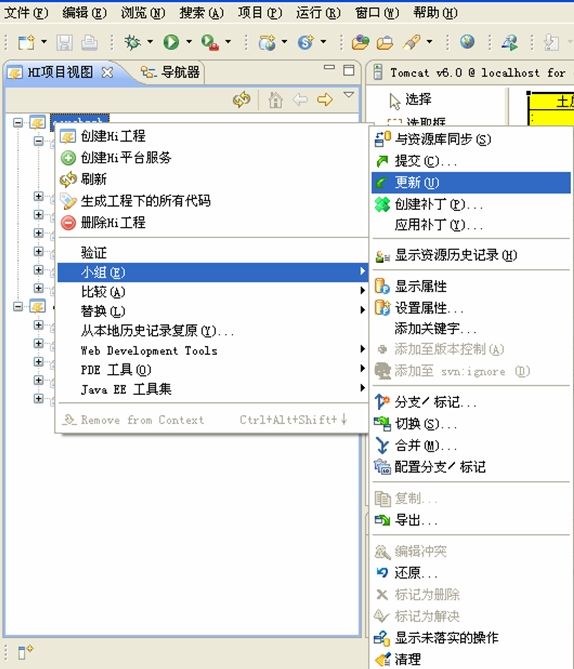
每次开始工作之前从版本库中下载更新,阶段工作完成并测试无误之后提交。会让团队的合作开发变得方便可控。
参考资源:http://www.uml.org.cn/pzgl/200904106.asp
删除或更改项目的资源库位置
若要删除svn服务的资源库,需要先从项目中删除svn信息,可在小组中删除版本共享链接先:
删除版本共享链接
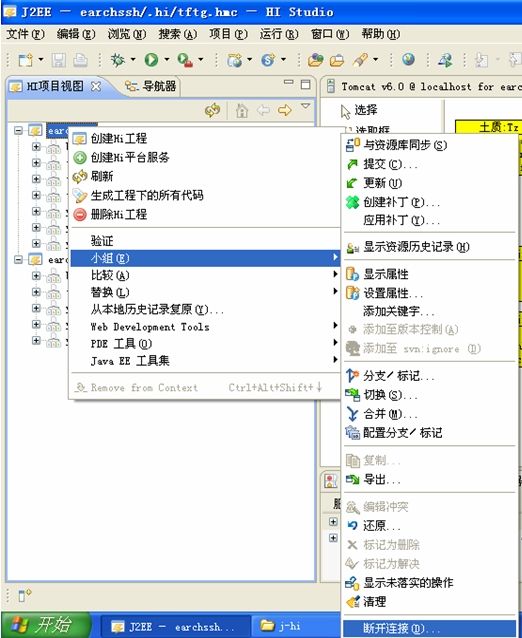
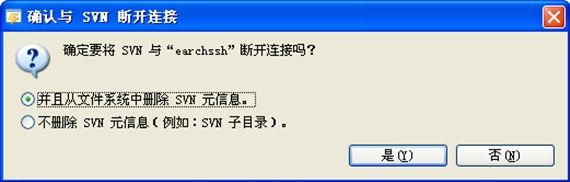
删除资源库位置
回到svn视图中,废弃位置:

这样就使开发的源程序断开了与版本共享库的链接,即退出了svn服务。
更改资源库位置只用新建资源库并配置即可。
Subclipse的卸载
卸载的方法也很简单,也是点击 Help => Software Updates => Manage Configuration
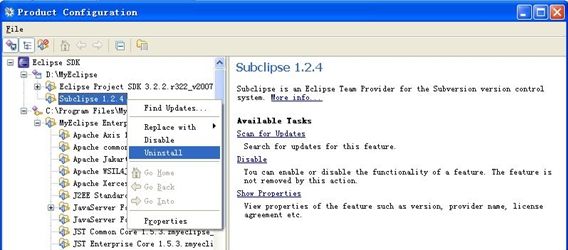
按上图操作就可以卸载了。
注:该文档由J-Hi爱好者"寻找本拉登"提供,他的QQ号为382600911,欢迎大家与他在技术上多多交流
1、主键自增的解决方案
this .getJdbcTemplate().update( new PreparedStatementCreator(){
public PreparedStatement createPreparedStatement(Connection con)
throws SQLException {
PreparedStatement ps = con.prepareStatement(sql,Statement.RETURN_GENERATED_KEYS);
return ps;
}
}, keyHolder);
return keyHolder.getKey().intValue();
当keyHolder获得主键值后,您可以在任何时候通过访问keyHolder对象得到这个主键值,也就是说只要它的生命期存在,这个主键的值就一直不会丢失。
总结:1)、在执行 PreparedStatement之前创建自增主键的持有者对象keyHolder
2)、在创建 PreparedStatement对象时一定要声明返回主键值,列如 con.prepareStatement(sql,Statement.RETURN_GENERATED_KEYS)
3)、只要keyHolder的生命期存在,那么主键的值在任何时候与位置你都可以取得到
2、检索数据库序列生成的主键的解决方案
return incr.nextIntValue();
J-Hi的问题与解决方法
因为J-Hi要实现跨数据库跨多个ORM框架因此对于SpringJDBC这两种方案必须要融合到一起,并且在总体设计上还要与其它的ORM框架(目前J-Hi已融合的ORM框架有hibernate、ibatis2、ibatis3)的接口声明相兼容,因此在对SpringJDBC集成的总体设计上我借鉴了hibernate的方言思想,通过方言将SpringJDBC两种方案融合在J-Hi之中以实现对不同类型数据库主键管理的差异性。
this .getJdbcTemplate().update( new PreparedStatementCreator(){
public PreparedStatement createPreparedStatement(Connection con)
throws SQLException {
ISpringJDBCHiDialect dialect = sessionFactory.getDialect();
PreparedStatement ps = con.prepareStatement(sql,Statement.RETURN_GENERATED_KEYS);
if (stepFlage == primaryKeyIndex && valueClass.getPropertyName().equals(primaryKeyName)){
Number _id = dialect.getSelectKey(entity.getEntityName(), getJdbcTemplate().getDataSource());
return ps;
}
}, keyHolder);
if (obj.getPrimarykey() == null )
BeanUtil.setPropertyValue(obj, " id " , keyHolder.getKey().intValue());
从原生的SQL语句上讲Oracle在insert时要插入主键值,而SQLServer恰好相反必须不能插入主键的值,我在设计上就是抓住这一特性,再结合方言,实现了跨数据库的SpringJDBC, dialect.getSelectKey()方法,对应不同的数据库方言,如果是oracle就会生成主键的值,而如果是SQLServer这个方法不会返回任何值,代码如下
Oracle的方言方法:
OracleSequenceMaxValueIncrementer incr = new OracleSequenceMaxValueIncrementer(dataSource, " HIBERNATE_SEQUENCE " );
return incr.nextIntValue();
}
// 自增主键不用实现该方法
return null ;
}
最后通过
if (obj.getPrimarykey() == null )
BeanUtil.setPropertyValue(obj, " id " , keyHolder.getKey().intValue());
Pojo对象是否主键值(如果没有就说明是自增型的如SQLServer,如果有就说明是序列生成的如Oracle),来将其赋值到POJO的属性中.
在以前我还真没对各数据库的翻页处理做深入的分析,只是肤浅的知道SQLServer用top,Oracle用rownum,MySQL用limit通过sql语句做分页处理,我一直认为通过对应数据库的这些关键字就可以获取指定的数据条数,而这些数据是在数据库端就可以一次完成的。例如只取满足条件的第11-20这10条记录,这样ResultSet就会只有10条结果,而事实并非如此,主要就纠结在SQLServer上。
通过做J-Hi对SpringJDBC融合的开发,我才知道实际上SQLServer2000并不能满足我们这样现实的需求,而只有到了SQLServer2005这个局面才有了改观,下面让我们对SQLServer的分页处理做如下分析:
SQLServer2000,由于它只提供了top关键字,而top的作用只是满足条件的前多少条记录,因此在处理翻页时,它是将满足条件的前多少条记录一并取出,如每页10条,翻到第二页时的sql语句为
搞笑的时,用了这么久的SQLServer却昏然不知,等到SQLServer2005微软才算时对此做了补充与修改,下面是SQLServer2005的SQL语句
通过上面的一个小功能的分析,我真是对微软及SQLServer产品有些失望,如此的功能要事隔5年才完善它,而且完善的并无新意,更何况象这样的功能就连mysql这种免费开源的产品都早已实现,而SQLServer还是商业运作,真不知微软的SQLServer在某些方面上都不如开源的产品它是做何感想?
场景分析
如果项目大量使用了ajax或者项目使用了类似extjs这种富客户端框架的朋友们可能会经常碰到一个问题:我们如何为客户端提供正确有效的数据?例如以下简单需求:
有一个界面,用于显示用户名、用户所在公司名称、用户拥有的权限名称,使用ajax去服务端获取数据。
我们有以下三个类:
User:用户类

Company:公司类

Role:角色类

用户类1:M角色,用户类1:1公司。
这里有一段测试代码,调用了j-hi的JSONObject API进行序列化:
我们测试结果如下:
{"user":{"mobile":null,"primarykey":null,"parentEntity":null,"class":class test.User,"dataSymbol":null,"username":"zhangsan","cascadeDirty":false,"roles":[{"rolename":"角色1","primarykey":null,"parentEntity":null,"class":class test.Role,"dataSymbol":null,"cascadeDirty":false,"dirty":false,"deletedFlag":false,"version":1},{"rolename":"角色2","primarykey":null,"parentEntity":null,"class":class test.Role,"dataSymbol":null,"cascadeDirty":false,"dirty":false,"deletedFlag":false,"version":1}],"dirty":false,"deletedFlag":false,"version":null,"company":null},"id":1}
我们发现,将整个对象序列化了。尤其是company对象,客户端只需要公司名,但结果是所有属性都被序列化了。
我们不需要序列化所有属性,在新版本的J-Hi中,提供了新的方法,输出我们需要的属性,看如下例子:

输出结果如下:
{"user":{"username":"zhangsan","roles":[{"rolename":"角色1"},{"rolename":"角色2"}],"company":{"companyName":"新浪"}},"id":1}
完美达到我们的要求。
在某些需求中,我们甚至可以从客户端发起获取数据的请求,动态的获取我们需要的数据,比如我们发起一个请求:
{
'entity': 'xxxxx.user.User' ,
'returnType':'JSON',
'properties': 'username, company.companyName, roles.rolename'
},
请求获取User类对象的以下属性username,company.companyName,roles.rolename
服务器端返回User类型对象,并序列化成JSON返回,返回以下几个属性username,company.companName.
通过j-hi的新JSONObject API,我们可以很方便实现这样的功能,为客户端提供任意数据。甚至能实现万能的服务器查询API。
代码分析:
JSONObject类一个将多个java对象封装成一个JSON字符串的工具类,每一个java(POJO)对象都是对象JSON字符串的一个属性,可以通过addJSONObject(),为要转换的JSON不断加入新的java对象。
缺省在创建JSONObject对象时,构建函数参数已经加了一个java对象,如果JSON可能会有多个java对象拼接而成,就可以通过addJSONObject()累加的方式实现。
/**
*添加一个待转换的java对象,使其作为JSON字符串的一部分
*@paramjsonPropertyName给定JSON的属性名
*@paramobj待转换的java对象,这个java对象可以是基础类型比如日期、字符串,也可以是POJO对象,或者是Collection集合类对象
*@paramobjectProperties返回JSON字符串对应POJO的属性名列表,属性名与属性名之间用逗号分隔,如果该java对象的某个元素是集合也可以支持即集合属性名.集合元素对象属性名
*,例如HiUser的POJO"id,org.orgName,org.id",注意:如果该参数为空
*则只转换一级属性,即它不会级联的返回属性的属性值
*/
publicvoid addJSONObject(String jsonPropertyName, Object obj, String objectProperties)
/**
*获得封装后的JSON对象
*@return返回一个JSON对象的字符串
*/
public String toString()
目的与意义:
1、 在一次客户端的请求过程中,尽量的压缩传输数据的传输量,从而降低带宽,提高传输效率
2、 提高浏览器的对JSON对象的解析速度,对于IE浏览器来说9以下的版本对JSON的解析速度都很差,这也是适应目前客户现场情况解决实际问题的方法
3、 一个清爽没有数据冗余的JSON对象,更方便你在客户端做数据控制,例如根据返回的JSON动态的显示列表的列数
注:该文档由J-Hi爱好者"叶青"提供,他的QQ号为405986916,欢迎大家与他在技术上多多交流

因此我们正在为下一步的工作与下一步的平台升级做准备工作,在平台目前的版本中支持Struts2、Webwork、hibernate、ibatis2、ibatis3,我们计划在下一升级版中融入SpringMVC与SpringJDBC框架,如果兴趣参与我们的设计与开发的人员欢迎加入到我们的项目中来。
要求:1、对SpringMVC或SpringJDBC的底层非常熟悉
2、对J-Hi的底层运行原理有一定了解
3、要有带领一个小团队的组织能力
4、对中国的开源有兴趣与激情,并能始终坚持下来
工作内容:
1、编写相应框架与J-Hi集成的详细设计文档
2、编写开发计划的Project
3、组织开发人员按计划开发
4、组织测试工作
联系方式:
邮箱:[email protected]
QQ群:133178083
参考:
http://code.google.com/p/j-hi/
2 #macro(digui)
3 #set ($s_parent = $s_owner.parent)
4 #set( $count = $s_parent.components.size() - 1)
5 #if($s_parent.components.get($count) == $s_owner)
6 ul > li >
7 # set ($s_owner = $s_owner.parent)
8 #digui()
9 #end
10 #end
11
12 #macro( menuItem $menu $level )
13 ## set title
14 #set ($title = $displayer.getMessage($menu.title))
15 #if ($level == 0)
16 < li > < a href = " javascript:void(0) " > ${title} a >
17 < ul >
18 # else
19 < li >
20 # if ($menu.components.size() > 0)
21 #set ($numItems = $menu.components.size())
22 < a # if($menu.action)href="$!menu.action"#end #if($menu.jsFunctionName)οnclick="$!menu.jsFunctionName" href="javascript:void(0)"#end target="#if($menu.target)$!menu.target#end">${title}
23 < ul >
24 # else
25 < a # if($menu.define.checkbox) tname="hi_checkbox_common" tvalue="$!menu.checkbox"#end" #if($menu.action)href="$!menu.action"#end #if($menu.jsFunctionName)οnclick="$!menu.jsFunctionName" href="javascript:void(0)"#end target="#if($menu.target)$!menu.target#end">${title}
26 #end
27 #if($menu.components.size() == 0)
28 li >
29 # end
30 #if ($level != 0 && $velocityCount == $menu.parent.components.size() && $menu.components.size() == 0)
31 #set ($s_owner = $menu)
32 #digui()
33 #end
34 #end
35 #end
36
37 < script type = " text/javascript " >
38 ${menu . define . javascript}
39 # if($menu.define.checkbox)
40 function selectedcb(button){
41 var checkeds = jQuery(button) . parent() . find( " .tree :checkbox " ) . filter( " :checked " ) . filter( " [name] " );
42 var ids = new Array();
43 var texts = new Array();
44 checkeds . each (function(i){
45 var input = jQuery(this);
46 ids[i] = input . val();
47 texts[i] = input . attr( " text " );
48 });
49 var result = new Array();
50 if (ids . length == 0 )
51 return result;
52 result[ 0 ] = ids;result[ 1 ] = texts;
53 return result;
54 }
55 # end
56 script >
57
58 < div style = " float:left; display:block; margin:10px; overflow:auto; width:200px; height:300px; border:solid 1px #CCC; line-height:21px; background:#FFF; " >
59 < ul class = " tree treeFolder collapse#if($menu.define.checkbox) treeCheck#end " >
60 # displayMenu($menu 0)
61 ul >
62 # if($menu.define.checkbox)
63 < input type = ' button ' name = ' button1 ' value = ' 带回 ' onclick = ' bringBackCheckBox(selectedcb(this)) ' / >
64 # end
65 div >
66
67
68
2011年9月16日 #
http://developer.51cto.com/developer/51cto-salon-13/