Windows下用pip安装TensorFlow-GPU
1. 前言
检测结果显示,TensorFlow的代码确实正在利用GPU时,我激动地鼓起了掌。
记录一下本次安装TensorFlow-GPU的历程。不过其中问题不多,就不再记录了。
最终配置:Win10 x64 + NVIDIA GeForce GTX850M + VS2017 + Python 3.6 + CUDA 9.0 + cuDNN 7.3.1 + tensorflow-gpu 1.11.0
2. 准备工作
- 一台Win7以上64位电脑
- 英伟达显卡,我的是NVIDIA GeForce GTX850M(看型号就知道是老笔记本)
- 电脑上已经安装了Python 3.4/3.5/3.6,我的是3.6
- 耐心,这次准备了同学给的一盒百奇
- 提前下载好一些文件:
- 从官网上搞一个VS2017社区版
- 更新好NVIDIA显卡驱动
- 下载CUDA9.0或9.2(我的是9.0,离线包都有一个多G大小),不要下载10.0,TensorFlow貌似还不支持10.0
- 下载cuDNN对应系统对应版本,需要在官网上注册账户填写一些调查信息
- tensorflow-gpu等whl文件,可以从文末的扩展下载网站上下载,避免在安装时出现网络问题
- 可以搞一个Python IDE,我用的是pycharm
- 应该还需要从微软官网上下载一个vc++ redistributable 2015
3. 方案
3.1. 安装 VS2017
为了安装CUDA,我们需要看一下CUDA的安装指南看它支持哪些系统哪些版本的VS,不过其实安装9.0以后的版本的话VS2017都是可以用的。

安装时要勾选上WIN10 SDK至少一个版本,缺了这个可能CUDA无法编译成功。仅供参考,我也还是不知其所以然,只是按文章照做,但个人感觉如果不需要在VS中使用CUDA的话应该是不需要安装这个的。
管他呢,安了再说。安装的时候注意C盘空间。
安装VS这个航母可是个耗时间的活计,可以先做别的事情去。
3.2. 安装 CUDA9.0 与cuDNN
下载好安装包之后,感觉不需要像看的文章里写的那样自定义安装,直接精简安装即可。至少在我的电脑上这样做是可以的。
- 安装完毕之后,可能需要进行一个修改版本号的操作:打开路径 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.0\include\crt 中的 host_config.h头文件,将其中 _MSC_VER > 1911 中的 1911 改为 1920或者其他比当前你电脑上的VS版本高的一个数字即可。
安装完毕之后,打开cmd,输入:nvcc -V可以查看CUDA的版本,若出现正确的版本信息,即安装成功。
安装成功后,打开环境变量窗口,可以发现系统变量中多了 CUDA 相关的几个路径。然后还需要添加几个变量:
- 在用户变量Path下添加:
- C:\ProgramData\NVIDIA GPU Computing Toolkit\v9.0
- 在系统变量中添加:
- CUDA_SDK_PATH = C:\ProgramData\NVIDIA Corporation\CUDA Samples\v9.0
- CUDA_LIB_PATH = %CUDA_PATH%\lib\x64
- CUDA_BIN_PATH = %CUDA_PATH%\bin
- CUDA_SDK_BIN_PATH = %CUDA_SDK_PATH%\bin\win64
- CUDA_SDK_LIB_PATH = %CUDA_SDK_PATH%\common\lib\x64
设置完成后,在cmd中输入:set cuda可以查看设置路径。
然后解压下载好的cuDNN压缩包,将其中的文件直接拷贝到cuda的对应目录去。cuda安装目录应该是在:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.0 。
3.3. 安装 TensorFlow-GPU
采用的安装包就是官方文档安装页最下面的whl文件。具体流程依然是按照官方文档来用pip直接安装,可以参考我的上一篇文章:
https://blog.csdn.net/haibinwan1024/article/details/83188058
中的第三部分。(当然,有了这一堆whl文件,梯子什么的滚一边去吧)
- 注意: 最好不用把cpu和gpu版本同时安装。若同时安装了,最好先用
pip uninstall tensorflow-gpu将gpu版卸载掉,再用pip uninstall tensorflow把cpu版卸载掉,再重新pip install tensorflow-gpu才行。
3.4. 验证代码是否使用GPU
安装成功的话,至少是可以通过简单的代码显示tensorflow的版本号的。
从文章中找到了一些代码,来进行激动人心的验证。若侵删。
- 代码一:查看电脑CPU和GPU
import os
from tensorflow.python.client import device_lib
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "99"
if __name__ == "__main__":
print(device_lib.list_local_devices())
我的输出为:
[name: "/device:CPU:0"
device_type: "CPU"
memory_limit: 268435456
locality {
}
incarnation: 15210516810682985301
, name: "/device:GPU:0"
device_type: "GPU"
memory_limit: 1469861068
locality {
bus_id: 1
links {
}
}
incarnation: 17712230884952356649
physical_device_desc: "device: 0, name: GeForce GTX 850M, pci bus id: 0000:01:00.0, compute capability: 5.0"
]
可以查看则说明tensorflow可以识别计算机上的cpu和NVIDIA GPU,后续代码基本都可以实现了。
- 代码二:验证CUDA和GPU是否可用
import tensorflow as tf
a = tf.test.is_built_with_cuda() # 判断CUDA是否可以用
b = tf.test.is_gpu_available(cuda_only=False,min_cuda_compute_capability=None) # 判断GPU是否可以用
print(a)
print(b)
输出为:
True
True
代表CUDA和GPU可用。
- 代码三:官网测试代码
import tensorflow as tf
mnist = tf.keras.datasets.mnist
(x_train, y_train),(x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation=tf.nn.relu),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5)
model.evaluate(x_test, y_test)
print(y_test)
输出为(取最后几行):
4448/10000 [============>.................] - ETA: 0s
5184/10000 [==============>...............] - ETA: 0s
5984/10000 [================>.............] - ETA: 0s
6688/10000 [===================>..........] - ETA: 0s
7360/10000 [=====================>........] - ETA: 0s
8128/10000 [=======================>......] - ETA: 0s
8896/10000 [=========================>....] - ETA: 0s
9632/10000 [===========================>..] - ETA: 0s
10000/10000 [==============================] - 1s 83us/step
[7 2 1 ... 4 5 6]
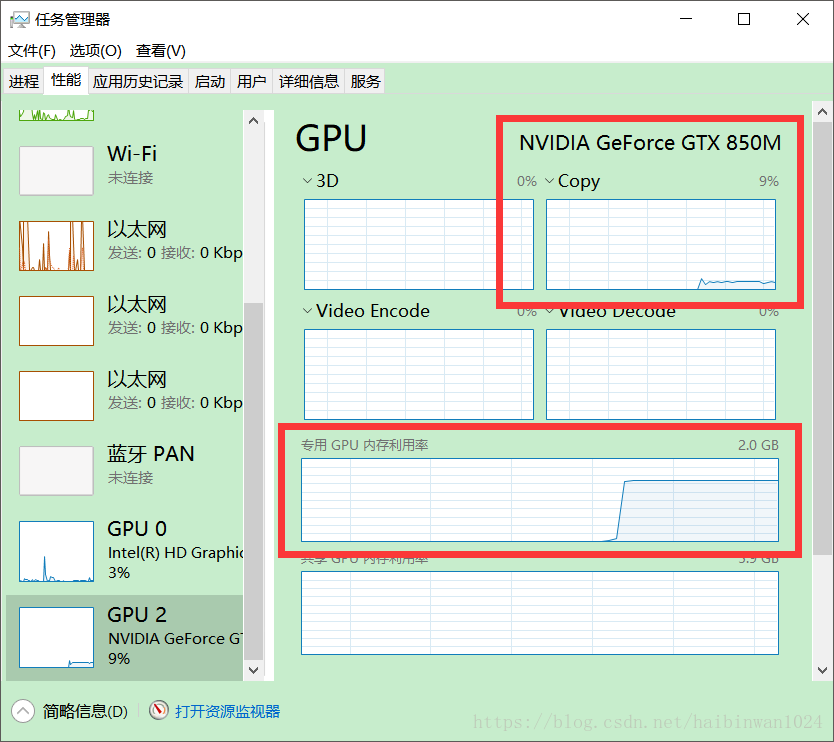
如图,GPU利用率已经开始变化。在上一篇文章中我用CPU跑过这个代码,这一次用GPU跑能很明显地感觉到速度快了三倍左右。
- 代码四:通过终端输入控制使用cpu与gpu
import sys
import numpy as np
import tensorflow as tf
from datetime import datetime
device_name = sys.argv[1] # Choose device from cmd line. Options: gpu or cpu
shape = (int(sys.argv[2]), int(sys.argv[2]))
if device_name == "gpu":
device_name = "/gpu:0"
else:
device_name = "/cpu:0"
with tf.device(device_name):
random_matrix = tf.random_uniform(shape=shape, minval=0, maxval=1)
dot_operation = tf.matmul(random_matrix, tf.transpose(random_matrix))
sum_operation = tf.reduce_sum(dot_operation)
startTime = datetime.now()
with tf.Session(config=tf.ConfigProto(log_device_placement=True)) as session:
result = session.run(sum_operation)
print(result)
# It can be hard to see the results on the terminal with lots of output -- add some newlines to improve readability.
print("\n" * 5)
print("Shape:", shape, "Device:", device_name)
print("Time taken:", datetime.now() - startTime)
print("\n" * 5)
终端输入:python 文件名.py cpu 10000时的输出:
Shape: (10000, 10000) Device: /cpu:0
Time taken: 0:00:35.058028
终端输入:python 文件名.py gpu 10000时的输出:
Shape: (10000, 10000) Device: /gpu:0
Time taken: 0:00:04.862100
可以发现,在这个案例中gpu竟然比cpu运算速度快了九倍!!!
- 至此,大功告成,可以愉快地玩耍了~
4. 总结
- 在上次安装完CPU版的基础上,花了六七个小时把GPU版本安装好,比较尽人意。想想在工作之外茶余饭后的时间里,把玩游戏看小说的时间拿来装装软件学学新知识,也是相当不错的。
- 开始安装的时候没有细看tensorflow的支持环境,直接下载了一个CUDA10.0安装上,结果发现tensorflow一直识别不出gpu。后来细看之下才发现(现在又不那么肯定了)需要下载9.0或9.2的版本。花了好多时间卸载掉重新安装起来,结果还不错,至少成功了。版本问题可以是这次安装的主要问题,找对版本即可解决。
- 那个时候真是要崩溃似的,都想把电脑上的vs2017、Python、pycharm、anaconda什么的有关的东西全部卸载掉重新安装。真是太傻了,还好及时放弃关了电脑,第二天一口气安装成功。年轻人还是太冲动了!
- 文中文字和内容如有不妥之处,敬请留言纠正!
5. 参考链接
- https://blog.csdn.net/haibinwan1024/article/details/83188058 我的上一篇文章及其中所有链接
- https://www.lfd.uci.edu/~gohlke/pythonlibs/ Python Extention Packages for Windows网站,里面有无数whl文件
- https://blog.csdn.net/weixin_42359147/article/details/80622306 从挖坑到跳坑到出坑,主要参考的这篇文章以及其中的评论。文中VS2017编译CUDA Sample的部分我尚未实现
- https://blog.csdn.net/wwtor/article/details/80603296?utm_source=blogxgwz0 Anaconda环境中安装成功的一篇文章
- https://blog.csdn.net/sinat_29957455/article/details/80636683 tensorflow查看电脑的CPU和GPU