大数据架构基本逻辑梳理
大数据架构基本逻辑梳理
流处理、批处理、交互式查询之间区别在文末
大数据的特点:
- Value(价值) Velocity(速度) Variety(多样性) Volume(体量)
大数据处理主要解决两个问题。
数据保存,数据操作
。以及处理结果的展现。其特点是:
数据单向增加。
删除和修改很少。Write-once-read-many
数据形态多样。
数据价值随时间递减。
实时数据价值最大,历史数据虽然有价值但会降低
数据在一个或多个数据中心的集群的大量机器中保存。
读写太多,导致硬件发生故障率升高。
数据保存涉涉及到两个问题:
数据的表达和数据的存储
。
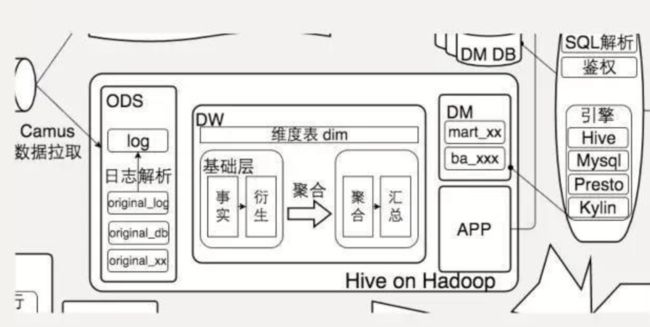
鉴于大数据形态的多样性,很难用一种统一的结构化方法对数据建模。现在采用的基本策略都是用一个
统一的大表(Bigtable)来保存。在大表中,所有的数据(包括键值)都以字符串的形式保存
,将字符串的内部格式的控制权交给该数据的用户。该方案在简化数据模型的同时,也增加了数据用户的负担。
在Hadoop中也有它的对应的解决技术:
HBase。
数据的表达和数据的存储是紧密相关的。为了
存储
Bigtable的数据,谷歌提出了一个分布式文件系统GFS(Google File System)。相应地在Hadoop中也有一个对应的实现:
HDFS
(Hadoop DistributedFile System)。
- 大量数据的保存。唯一的选择只有分布式保存。当然在分布式保存的前提下,需要解决数据组织、访问接口和数据检索的问题。
- 数据的可靠性。在使用普通商用硬件的前提下,硬件故障的发生是不可避免的,因此提高可靠性的唯一选择就是数据的冗余备份。与此相关,主要需要解决故障检测、冗余备份的时机、数据一致性等问题。次要地,也涉及到冗余备份的安排,既保证可靠性尽量高,也要保证并发访问的速度尽量快。
- 数据的快速访问,也即数据访问的吞吐率。提高吞吐率的方法不外乎分布式保存和平行读取。为了消除瓶颈,需要保证对主控节点的访问尽量地少。
数据处理
由于一个数据集的数据分散在成百上千、甚至上万的计算机上,因此大规模平行处理框架就成为一个必然的选择。
- 尽可能避免大量数据在计算/存储节点间的移动。
- 将数据处理程序推到数据存储节点上。
- 处理应仅可能在不同的节点上平行进行。
在Hadoop中,提供了
两种处理框架
:
HadoopMapReduce和Spark
。
前者比较适合对整个数据集的批处理操作,后者比较适合对整个数据集、或其中一部分进行反复的变换、查询等操作。



我们将大数据处理按处理时间的跨度要求分为以下几类
基于
实时数据流的处理
,通常的时间跨度在
数百毫秒到数秒
之间
基于
历史数据的交互式查询
,通常时间跨度在
数十秒到数分钟
之间
复杂的批量数据处理
,通常的时间跨度在
几分钟到数小时
之间
1.流处理
流是一种数据传送技术,它把客户端数据变成一个稳定的流。正是由于数据传送呈现连续不停的形态,所以流引擎需要连续不断处理数据
流处理的主要应用场景:金融领域和电信领域
1.1 Stom
Storm是一个免费开源、分布式、高容错的实时计算系统。
Storm主要分为两种组件Nimbus和Supervisor。这两种组件都是快速失败的,没有状态。任务状态和心跳信息等都保存在Zookeeper上的,提交的代码资源都在本地机器的硬盘上。
1)Nimbus负责在集群里面发送代码,分配工作给机器,并且监控状态。全局只有一个。
2)Supervisor会监听分配给它那台机器的工作,根据需要启动/关闭工作进程Worker。每一个要运行Storm的机器上都要部署一个,并且,按照机器的配置设定上面分配的槽位数。
3)Zookeeper是Storm重点依赖的外部资源。Nimbus和Supervisor甚至实际运行的Worker都是把心跳保存在Zookeeper上的。Nimbus也是根据Zookeerper上的心跳和任务运行状况,进行调度和任务分配的。
4)Storm提交运行的程序称为Topology。
5)Topology处理的最小的消息单位是一个Tuple,也就是一个任意对象的数组。
Topology由Spout和Bolt构成。Spout是发出Tuple的结点。Bolt可以随意订阅某个Spout或者Bolt发出的Tuple。Spout和Bolt都统称为component。
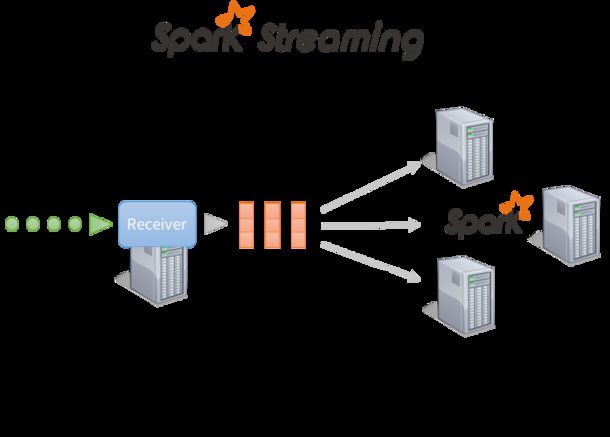
1.2 Spark Streaming
Spark Streaming是一种构建在Spark上的实时计算框架,它扩展了Spark处理大规模流式数据的能力。
Spark Streaming的基本原理是将输入数据流以时间片(秒级)为单位进行拆分,然后以类似批处理的方式处理每个时间片数据。
2.交互式查询(Adhoc Query)
在商业智能领域少量更新和大量扫描分析场景,目前是
Impala+Kudu/Hive/Spark SQL/Greenplum Mpp
数据库在混战。
3.批处理技术
3.1 MapReduce(Hadoop)
MapReduce模式的主要思想是自动将一个大的计算拆解成Map和Reduce

3.2 Spark
Spark的中间数据放到内存中,对于迭代运算效率更高。
Spark更适合于迭代运算比较多的ML和DM运算。因为在Spark里面,有RDD的抽象概念。
Spark比Hadoop更通用
Spark提供的数据集操作类型有很多种,不像Hadoop只提供了Map和Reduce两种操作。比如map, filter, flatMap, sample, groupByKey, reduceByKey, union, join, cogroup, mapValues, sort,partionBy等多种操作类型,Spark把这些操作称为Transformations。同时还提供Count, collect, reduce, lookup, save等多种actions操作。