【BasicNet系列:五】DenseNet 论文笔记解读+pytorch代码分析
2017 CVPR Best / Oral
Densely Connected Convolutional Networks
Introduce
结构和网络图
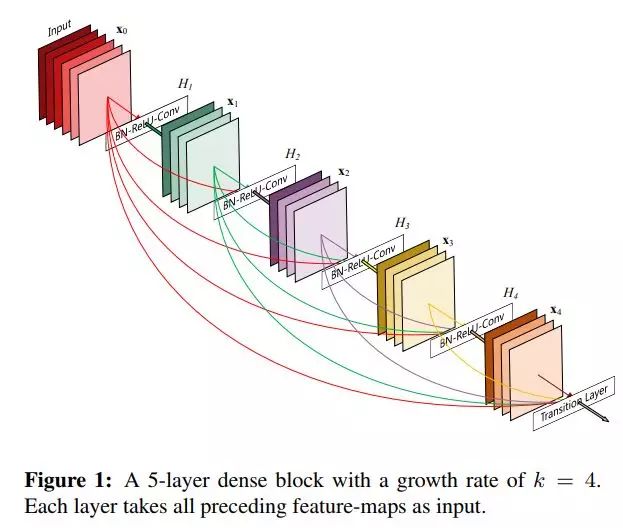
由来
- 梯度消失问题解决方案:
(1)Highway Network,Residual Network通过前后两层的残差链接使信息尽量不丢失
(2)Stochastic depth通过随机drop掉Resnet的一些层来缩短模型
(3)FractalNets通过重复组合一些平行的层序列来保证深度的同时减轻这个问题。
共性:都是在前一层和后一层中都建立一个短连接。
ResNet,Highway Networks,Stochastic depth,FractalNets等
核心都在于:create short paths from early layers to later layers
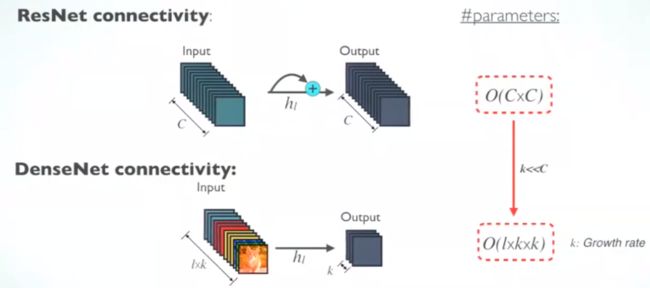
DenseNet:直接concat(resnet用的是sum)来自不同层的特征图
(DenseNet脱离了加深网络层数(ResNet)和加宽网络结构(Inception)来提升网络性能的定式思维,从特征的角度考虑,通过特征重用和旁路(Bypass)设置,既大幅度减少了网络的参数量,又在一定程度上缓解了gradient vanishing问题的产生.结合信息流和特征复用的假设)

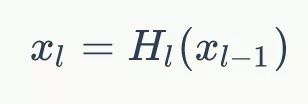
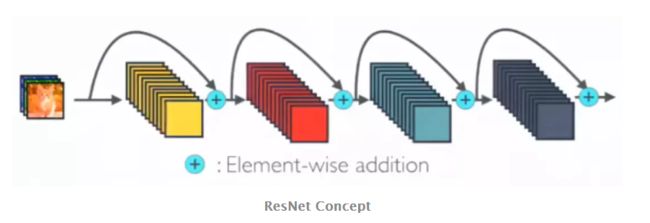
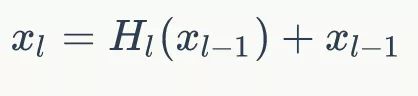
(ResNet,增加了来自上一层输入的identity函数)
ResNet中,提出了恒等映射(identity mapping)来促进梯度传播,同时使用使用 element 级的加法。它可以看作是将状态从一个ResNet 模块传递到另一个ResNet 模块的算法。
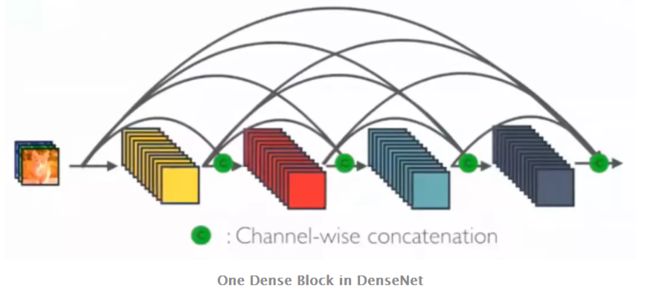
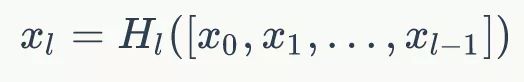
(DenseNet中,会连接前面所有层作为输入)
H l ( . ) H_l(.) Hl(.) 代表是 非线性转化函数(non-liear transformation),它是一个组合操作,其可能包括一系列的BN(Batch Normalization),ReLU,Pooling及Conv操作
在 DenseNet 中,每个层从前面的所有层获得额外的输入,并将自己的特征映射传递到后续的所有层,使用级联方式,每一层都在接受来自前几层的“集体知识(collective knowledge)”。

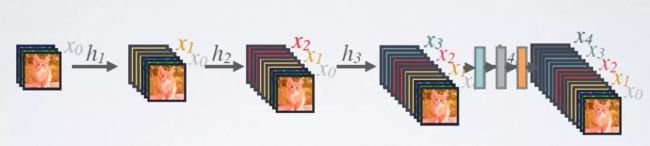
DenseNet 结构
1.Dense layer
一个Dense Block中是由L层dense laryer组成,layer之间是dense connectivity。
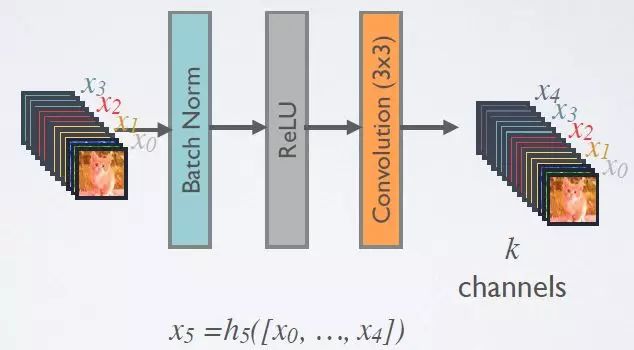
对于每个组成层使用 Pre-Activation Batch Norm (BN) 和 ReLU,然后用k通道的输出特征映射进行 3×3 卷积,例如,将x0、x1、x2、x3转换为x4。这是 Pre-Activation ResNet 的想法。
在DenseNet中,所有的3x3卷积均采用padding=1的方式以保证特征图大小维持不变。
Growth rate
每层dense layer输出为K(growth rate)个feature map, 那么第i层网络的输入便为K0+(i-1)×K
每个网络层输出的特征图数量K又称为Growth rate

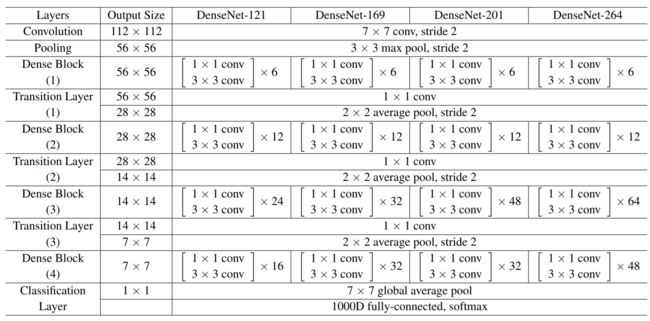
网络表中的k=32,k=48中的k是growth rate,表示每个dense block中每层输出的feature map个数。为了避免网络变得很宽,作者都是采用较小的k,比如32这样,作者的实验也表明小的k可以有更好的效果。
def conv_block(in_channel, out_channel):
layer = nn.Sequential(
nn.BatchNorm2d(in_channel),
nn.ReLU(True),
nn.Conv2d(in_channel, out_channel, 3, padding=1, bias=False)
)
return layer
class dense_block(nn.Module):
def __init__(self, in_channel, growth_rate, num_layers):
super(dense_block, self).__init__()
block = []
channel = in_channel
for i in range(num_layers):
block.append(conv_block(channel, growth_rate)) # conv_block(in_channel, out_channel)
channel += growth_rate
self.net = nn.Sequential(*block)
def forward(self, x):
for layer in self.net:
out = layer(x)
x = torch.cat((out, x), dim=1)
return x
# 每一层输出channel数为growth_rate,输入为in_channel+growth_rate * num_layers
2.DenseNet-B (Bottleneck layer)
由于后面层的输入会非常大,DenseBlock内部可以采用bottleneck层来减少计算量,主要是原有的结构中增加1x1 Conv.
使用1×1 Conv(Bottleneck)作为特征降维的方法来降低channel数量
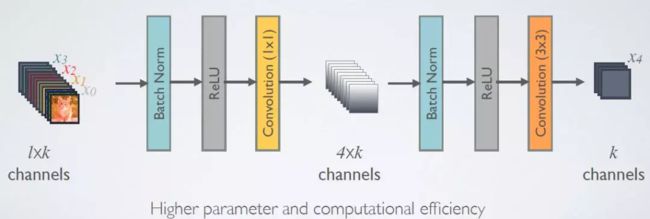
为了降低模型的复杂度和规模,在BN-ReLU-3×3 conv之前进行了BN-ReLU-1×1 conv.
3. Dense Block
Dense Block有L层dense layer组成
layer 0:输入( 56 ∗ 56 ∗ 64 56*56*64 56∗56∗64)->输出( 56 ∗ 56 ∗ 32 56*56*32 56∗56∗32)
layer 1:输入( 56 ∗ 56 ∗ ( 32 ∗ 1 56*56*(32*1 56∗56∗(32∗1))->输出( 56 ∗ 56 ∗ 32 56*56*32 56∗56∗32)
layer 2:输入( 56 ∗ 56 ∗ ( 32 ∗ 2 ) 56*56*(32*2) 56∗56∗(32∗2))->输出( 56 ∗ 56 ∗ 32 56*56*32 56∗56∗32)
…
layer L:输入( 56 ∗ 56 ∗ ( 32 ∗ L ) 56*56*(32*L) 56∗56∗(32∗L))->输出( 56 ∗ 56 ∗ 32 56*56*32 56∗56∗32)
- L层dense layer的输出 不变
- 每层的输入channel数是增加的,每层的输入是前面所有层的concat。
4. transition layer
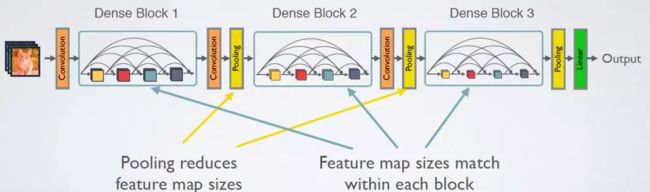
在DenseBlock中,各个层的特征图大小一致,可以在channel维度上连接。
Transition layer 采用1×1 Conv和2×2平均池化作为相邻 dense block 之间的转换层。
特征映射大小在 dense block 中是相同的,因此它们可以很容易地连接在一起。
在最后一个 dense block 的末尾,执行一个全局平均池化,然后附加一个Softmax分类器。
def transition(in_channel, out_channel):
trans_layer = nn.Sequential(
nn.BatchNorm2d(in_channel),
nn.ReLU(True),
nn.Conv2d(in_channel, out_channel, 1),
nn.AvgPool2d(2, 2)
)
return trans_layer
- Pooling Layers
DenseNet中需要对不同层的feature map进行cat操作,所以需要不同层的feature map保持相同的feature size,这就限制了网络中Down sampling的实现.为了使用Down sampling,作者将DenseNet分为多个Denseblock
将DenseNet分成多个dense block,原因是希望各个dense block内的feature map的size统一,这样在做concatenation就不会有size的问题。
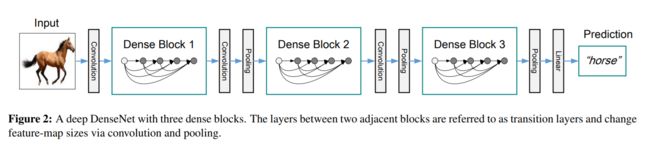
同一个Denseblock中要求feature size保持相同大小。
不同Denseblock之间设置transition layers实现Down sampling。
transition layer由BN + Conv(1×1) +2×2 average-pooling组成.
5. DenseNet-BC (Compression)
为了进一步优化模型的简洁性,我们同样可以在transition layer中降低feature map的数量.
若一个Denseblock中包含m个feature maps,那么我们使其输出连接的transition layer层生成⌊θm⌋个输出feature map.其中θ为Compression(压缩) factor
当θ=1时,跨转换层的特征映射数保持不变。在实验中:
当同时使用 bottleneck 和 θ<1 时的转换层时,该模型称为 DenseNet-BC 模型。
6. Classification Block
将3维的数据拉平成一维,再接上全连接层,以准备做softmax。计算过程如下:
算法分析
1. Model Compactness (模型紧凑)
对输入进行cat操作,每一层学到的feature map都能被之后所有层直接使用,参数量少。
2. Implicit Deep Supervision (隐性深层监督)
网络中的每一层不仅接受了原始网络中来自loss的监督,同时由于存在多个bypass与shortcut,网络的监督是多样的.
Each layer has direct access to the gradients from the loss function and the original input signal, leading to an implicit deep supervision. (每层都可以直接访问损失函数和原始输入信号的梯度)
3. Feature Reuse
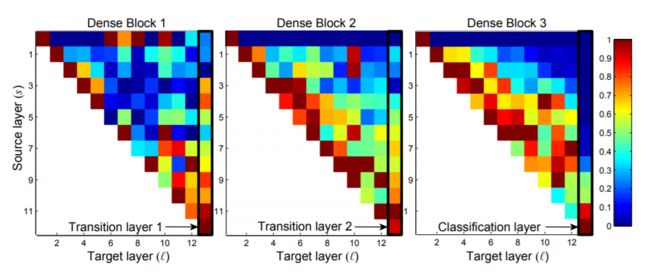
红色代表strong use
蓝色代表almost no use
横坐标为选定层
纵坐标为选定层的之前层
最右侧列以及第一行为transition layer
-
一些较早层提取出的特征仍可能被较深层直接使用
-
即使是Transition layer也会使用到之前Denseblock中所有层的特征
-
第2-3个Denseblock中的层对之前Transition layer利用率很低,说明transition layer输出大量冗余特征.这也为DenseNet-BC提供了证据支持,既Compression(压缩)的必要性.
-
最后的分类层虽然使用了之前Denseblock中的多层信息,但更偏向于使用最后几个feature map的特征,说明在网络的最后几层,某些high-level的特征可能被产生.
DenseNet 的优势
-
早期层中可以从最终的分类层直接获得监督
-
参数和计算效率 < Resnet
-
参数更小且计算更高效:由于DenseNet是通过concat特征来实现短路连接,实现了特征重用,并且采用较小的growth rate,每个层所独有的特征图是比较小的;
-
更加多样化的特征( DenseNet 中的每一层都接收前面的所有层作为输入,加强了feature的传递 )
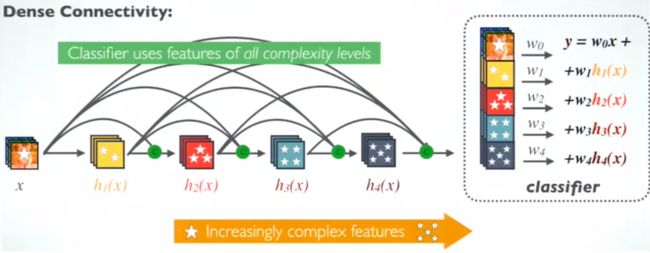
- 最后的分类器使用了低级特征
缺点:
-
DenseNet可能耗费很多GPU显存
(Pytorch框架可以自动实现这种优化) -
CIFAR 小规模数据集结果
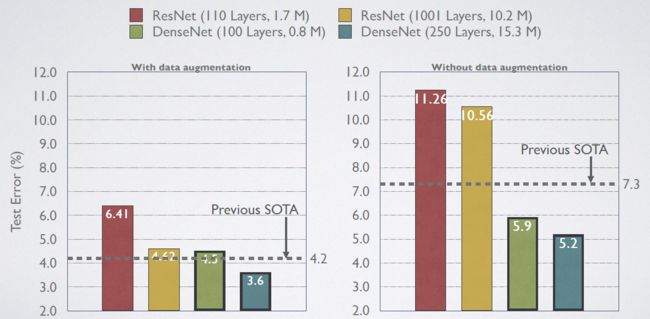
DenseNet-BC获得最佳效果。