有序表查找算法总结
有序表:按一定顺序排列的表。

1、折半查找:又称二分查找,直接上代码、
public int BinarySerch(int[] a,key){
int low=1,high=a.length,mid;
while( low <= high ){
mid = low + (high - low) / 2;
if( key < a[mid]){
high = mid - 1;
}else if( key > a[mid] ){
low = mid + 1;
}else{
return mid
}
}
return 0;
}2、 继续上面的想法,我们可以通过规律公式来确定key的大概范围,来减少查找次数。
插值查找 ,(key - a[low]) / (a[high] - a[low]).
见上述代码。将 mid 改成
mid = low + (high - low) * ( key - a[low]) /(a[high] - a[low])3、斐波那契查找:
学编程的就没有入不知道斐波那契,特别是它的循环自己调用自己,对是递归。
0.618被公认为最具有审美意义的比例数字,这个数值的作用不仅仅体现在诸如
绘画、雕塑、音乐、建筑等艺术领域,而且在管理、工程设计等方面也有着不可忽视
的作用。因此被称为黄金分割。
大家记不记得斐波那契数列:1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89…….(从第三个数
开始,后边每一个数都是前两个数的和)。然后我们会发现,随着斐波那契数列的递增,
前后两个数的比值会越来越接近0.618,利用这个特性,我们就可以将黄金比例运用到查
找技术中。
1)相等,mid位置的元素即为所求
2)>,low=mid+1;
3)<,high=mid-1。
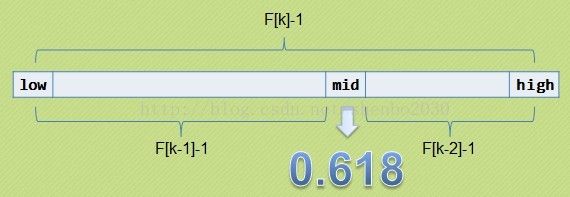
斐波那契查找与折半查找很相似,他是根据斐波那契序列的特点对有序表进行分割的。
要求开始表中记录的个数为某个斐波那契数小1,及n=F(k)-1; 开始将k值与第F(k-1)位置
的记录进行比较(及mid=low+F(k-1)-1),比较结果也分为三种
1)相等,mid位置的元素即为所求
2)>,low=mid+1,k-=2;
说明:low=mid+1说明待查找的元素在[mid+1,high]范围内,k-=2 说明范围
[mid+1,high]内的元素个数为n-(F(k-1))= Fk-1-F(k-1)=Fk-F(k-1)-1=F(k-2)-1个,所以
可以递归的应用斐波那契查找。
3)<,high=mid-1,k-=1。
说明:low=mid+1说明待查找的元素在[low,mid-1]范围内,k-=1 说明范围[low,mid-1]
内的元素个数为F(k-1)-1个,所以可以递归 的应用斐波那契查找。以下代码是C写的,
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
|
#include
#include
using namespace std;
const int MAX_SIZE = 20;
int a[] = { 1, 5, 15, 22, 25, 31, 39, 42, 47, 49, 59, 68, 88 };
void Fibonacci(int F[])
{
F[0] = 0;
F[1] = 1;
for (size_t i = 2; i < MAX_SIZE; i++)
F[i] = F[i - 1] + F[i - 2];
}
int FibonacciSearch(int value)
{
int F[MAX_SIZE];
Fibonacci(F);
int n = sizeof(a) / sizeof(int);
int k = 0;
while (n > F[k] - 1)
k++;
vector<int> temp;
temp.assign(a, a + n);
for (size_t i = n; i < F[k] - 1; i++)
temp.push_back(a[n - 1]);
int l = 0, r = n - 1;
while (l <= r)
{
int mid = l + F[k - 1] - 1;
if (temp[mid] < value){
l = mid + 1;
k = k - 2;
}
else if (temp[mid] > value){
r = mid - 1;
k = k - 1;
}
else{
if (mid < n)
return mid;
else
return n - 1;
}
}
return -1;
}
int main()
{
int index = FibonacciSearch(88);
cout << index << endl;
}
|