论文阅读:Temporal Action Localization by Structured Maximal Sums
Temporal Action Localization by Structured Maximal Sums
- 概述
- 作者贡献
- 结构化预测定位
- 结构化最大和
- 训练
- 网络结构
- 结构化损失
- 实验
- 实验结果
概述
将行为定位作为对任意长度时间窗口的结构化预测,其中每个窗口被评分为逐帧分类分数的总和。模型将每个行为的开始,中间和结束分类为单独的组件,允许模拟每个动作的时间演变,并利用此结构中存在的信息时间依赖关系。 在这个框架中,通过搜索结构化最大和来定位动作。使用来自深度卷积神经网络(CNN)的特征来计算逐帧分类分数,所述特征来自端对端的训练,以直接针对新颖的结构化目标进行优化。
作者贡献
- 提出了一种直接模拟动作时间演化的方法,并且开发了一个可行的高效算法来执行本框架中的定位。
- 提出了一种新颖的动态规划算法,可以找到任意长度视频的top-k结构最大和。
- 使用一种新颖的结构化损失函数对整个系统进行端到端的训练。

结构化预测定位
- 对于给定的视频 v = v= v={ x 1 , x 2 , . . . , x n x_1,x_2,...,x_n x1,x2,...,xn} ∈ V ∈V ∈V,其中 x t x_t xt表示时间t的帧,n为视频的总帧数。
- 时序窗口: y = y= y={ x s , x s + 1 , . . . , x e x_s,x_{s+1},...,x_e xs,xs+1,...,xe} ∈ Y ∈Y ∈Y,s和e分别表示帧的开始和结束,1≤s≤e≤n。
- 每一帧有一个帧向分数: f ( x t ) ∈ R f(x_t)∈R f(xt)∈R(正负数均可),表明某一帧属于特定行为类别的置信度。
- 为了方便, f ( x t ) f(x_t) f(xt)只用于表达单一帧 x t x_t xt,且在实践中依赖从完整视频中提取的特征。
- 置信分数: F : V × Y → R F:V×Y→R F:V×Y→R作为帧向分数的总和,即 F ( v , y ) = ∑ t = s e f ( x t ) F(v,y)=\sum^{e}_{t=s}f(x_t) F(v,y)=∑t=sef(xt)。
- 预测的时序窗口是最大的置信分数,即 y ^ = a r g m a x y ∈ Y F ( v , y ) \hat{y}=argmax_{y∈Y}F(v,y) y^=argmaxy∈YF(v,y)。
简而言之,通过搜索所有可能的起始和终点对,这种最大化需要在帧的数量上以二次方的空间进行搜索。 对于长视频来说,这是不切实际的。 然而,因为 F F F可以分解成帧的分数,所以可以把它作为经典的最大和问题,对此存在一个 O ( n ) O(n) O(n)时间解。 在实际设置中,可能在一个视频中有多个动作实例。 寻找 k k k个最佳窗口同样可以作为一个 k k k最大和问题,对此存在一个 O ( n + k ) O(n+k) O(n+k)时间解。
时间评估模型
为了鼓励精确定位,将每个行为明确地建模为单个开始帧,然后是任意长度的一系列中间帧,最后是单个结束帧。
- 分别为开始,中间和结束分量定义帧向置信度分数, f s ( x ) , f m ( x ) , f e ( x ) f^s(x),f^m(x),f^e(x) fs(x),fm(x),fe(x)
- 使用以下公式重写置信分数 F ( v , y ) F(v,y) F(v,y):

其中 λ s , λ m , λ e λ_s,λ_m,λ_e λs,λm,λe是每个行为部分相对重要的参数,在实验中,均设为1。
优点:这种生成方式带来了一些优于没有时间演进的单分类置信值的优势。
- 首先,会受到因为检测不到而无法找到匹配开始帧和结束帧的严重处罚。这强化了时间上的一致性,因为最好的检测将是按照正确顺序成功匹配三个组件中的每一个。
- 这种对不合逻辑匹配的抵抗使我们对帧级分数的变化具有鲁棒性。这使我们不太可能将动作的连续或部分实例合并为单个检测,并鼓励检测器将每个检测延伸到动作实例的全部范围,从而防止过分和不足分割。
- 开始和结束标签可以从现有的时间行为注释中随时获得,这意味着我们不需要额外的训练数据。最后,由于每个行动都有一个开始,中间和结束,所以这个表述对复杂行为的结构没有任何限制性的假设。
结构化最大和
给定帧分数 f s , f m 和 f e f_s,f_m和f_e fs,fm和fe以及视频v,目标是检测特定行为的所有实例。 将这些检测结果表示为top-k时间窗口,按照它们在公式1中的置信度分数排序。现在需要计算top-k结构化的最大总和(图2)。

为了解决上述问题,引入了结构化最大和(SMS)算法(算法1),它有效地找到了top-k结构的最大和。
- 在视频中进行单次遍历,保持到目前为止在 k m a x [ : ] kmax[:] kmax[:]列表中找到的K个最佳窗口的值,该列表保持排序顺序。
- 跟踪 r m a x [ : ] rmax[:] rmax[:]中在第 i i i帧结束的 K − b e s t K-best K−best不完整时间窗口的值,即在第 i i i帧结束但不包括端点 f e [ i ] f^e[i] fe[i]的窗口。
- 为了清楚起见,首先引入以下符号。
1)假设所有帧分类器分数是预计算的,并且包含在有序列表 f s [ 1... n ] f^s [1 ... n] fs[1...n], f m [ 1... n ] f^m [1 ... n] fm[1...n]和 f e [ 1 ⋅ ⋅ ⋅ n ] f^e [1 ···n] fe[1⋅⋅⋅n],简写 [ : ] [:] [:]同时引用列表中的所有元素。
2)为列表中的每个成员添加一个值表示为 f [ : ] + n f [:]+n f[:]+n。
3)将条目s插入已排序列表 k m a x kmax kmax中表示为 m e r g e ( s , k m a x ) merge(s,kmax) merge(s,kmax)的操作。
4)将离散空间 X X X上的函数 g g g的第 k k k个最大值表示为 k − m a x x ∈ X g ( x ) k-max_x∈Xg(x) k−maxx∈Xg(x)。

详细:
- r m a x = f s [ 1 ] rmax=f^s[1] rmax=fs[1]
- 当 i = 2 , k = 1 i=2,k=1 i=2,k=1时, s = f s [ 1 ] + f e [ 2 ] , r m a x [ 1 ] = f s [ 1 ] + f m [ 2 ] , k m a x s=f^s[1]+f^e[2],rmax[1]=f^s[1]+f^m[2],kmax s=fs[1]+fe[2],rmax[1]=fs[1]+fm[2],kmax加入 s s s。
遍历结果如图:

最后 r m a x rmax rmax有两个不是 − ∞ -∞ −∞的值( f s [ 1 ] + f m [ 2 ] , f s [ 2 ] f^s[1]+f^m[2],f^s[2] fs[1]+fm[2],fs[2]),假定( f s [ 1 ] + f m [ 2 ] > f s [ 2 ] f^s[1]+f^m[2]>f^s[2] fs[1]+fm[2]>fs[2]) - 当 i = 3 , k = 1 i=3,k=1 i=3,k=1时, s = f s [ 1 ] + f m [ 2 ] + f e [ 3 ] , r m a x [ 1 ] = f s [ 1 ] + f m [ 2 ] + f m [ 3 ] , k m a x s=f^s[1]+f^m[2]+f^e[3],rmax[1]=f^s[1]+f^m[2]+f^m[3],kmax s=fs[1]+fm[2]+fe[3],rmax[1]=fs[1]+fm[2]+fm[3],kmax加入 s s s
- 当 i = 3 , k = 2 i=3,k=2 i=3,k=2时, s = f s [ 2 ] + f e [ 3 ] , r m a x [ 1 ] = f s [ 2 ] + f m [ 3 ] , k m a x s=f^s[2]+f^e[3],rmax[1]=f^s[2]+f^m[3],kmax s=fs[2]+fe[3],rmax[1]=fs[2]+fm[3],kmax加入 s s s
遍历结果如图:

最后 r m a x rmax rmax有三个个不是 − ∞ -∞ −∞的值( f s [ 1 ] + f m [ 2 ] + f m [ 3 ] , f s [ 2 ] + f m [ 3 ] , f s [ 3 ] f^s[1]+f^m[2]+f^m[3],f^s[2]+f^m[3],f^s[3] fs[1]+fm[2]+fm[3],fs[2]+fm[3],fs[3]) - 当 i = 3 i=3 i=3时,遍历结果如图:
引理1
令 r m a x i [ : ] rmax_i [:] rmaxi[:]表示在时间步 i i i结束的 K K K个最佳不完整时间窗口列表,不包括终点 f e [ i ] f^e [i] fe[i]。 也就是说:
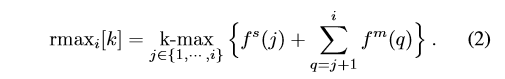
然后 m e r g e ( f s [ i + 1 ] , r m a x i [ i ] + f m [ i + 1 ] ) merge(f^s[i+1],rmax_i[i]+f^m[i+1]) merge(fs[i+1],rmaxi[i]+fm[i+1])给出时间步 i + 1 i+1 i+1结束的K个最佳不完整时间窗口的列表。
证明。 在第 i + 1 i + 1 i+1帧结束的第k个最佳不完整窗口或者是从 i + 1 i + 1 i+1开始的窗口,或者是在第 i i i帧结束的K个最佳窗口之一的延续。 r m a x i [ : ] + f m [ i + 1 ] rmaxi [:] + f^m [i + 1] rmaxi[:]+fm[i+1]给出以前K个最佳不完整窗口的所有延续列表。 在这个列表中插入 f s [ i + 1 ] f^s [i + 1] fs[i+1],并且如果 f s [ i + 1 ] f^s [i + 1] fs[i+1]大于它,则丢弃至多K个连续中的一个。 剩余的K最好的不完整的时间窗口在第 i + 1 i + 1 i+1帧结束。
引理2
令 k m a x i [ : ] kmaxi [:] kmaxi[:]表示在第 i i i帧或之前结束的K个最佳时间窗口的列表。 然后 m e r g e ( r m a x i [ : ] + f e [ i + 1 ] , k m a x i [ : ] ) merge(rmaxi [:] + f^e [i + 1],kmax_i [:]) merge(rmaxi[:]+fe[i+1],kmaxi[:])给出在时间步 i + 1 i + 1 i+1结束的K-最佳时间窗的列表。
证明。 从引理1知道 r m a x i [ : ] rmax_i [:] rmaxi[:]给出了在第一帧结束的K个最佳不完整时间窗口。 在第 i + 1 i + 1 i+1帧结束的第 k k k个最佳时间窗口是这些不完整窗口之一,通过添加 f e [ i + 1 ] f^e [i + 1] fe[i+1]完成,或者它是已经包含在 k m a x i kmax_i kmaxi中的顶部完整窗口之一。 通过合并这两个列表,选择整个top-K窗口,保留top-K完整时间窗口。
每个 r m a x i 和 k m a x i rmax_i和kmax_i rmaxi和kmaxi(包括调用合并)都可以在 O ( K ) O(K) O(K)时间中构造。 计算所有的 i ∈ 1 , . . . , k m a x i , . . . , n i∈{1,...,kmax_i,...,n} i∈1,...,kmaxi,...,n,所以总的时间复杂度是 O ( n K ) O(nK) O(nK)。 这个结果以及上述引理的结果使我们得到了我们的主要理论贡献:
定理4.1 SMS算法计算 O ( n K ) O(nK) O(nK)时间内长度为 n n n的视频中的 K K K最佳时间窗口。
注意到,尽管这个算法只能计算top-K时间窗口的分数,但我们的实现能够自行恢复窗口。 这是通过简单的簿记来完成的,它可以保持时间窗口的开始点和结束点,因为它们被添加到 r m a x rmax rmax和 k m a x kmax kmax列表中。
训练
网络结构
- 采用的双流网络体系结构为每个视频帧提取深时空特征。
- 采用较大的VGG 15层网络作为两个流中每一个的主干架构。 对于每个流,生成(C×3)维输出,其中C是动作类别的总数。最后,对来自两个流的帧向分数进行平均,并将各个帧之间的结果连接起来。 这种架构如图3所示。

结构化损失
模型将视频级结构损失函数最小化,而不是用于训练典型的双流动作识别结构的帧向损失函数。 通过直接优化时间行为定位,使帧级分数考虑到动作的时间演变。 这实现了一个微调的水平,这是通过针对框架目标进行优化而无法实现的。
首先单独对每个流进行预训练并通过微调进行融合:
- 有m个训练视频的数据集 V = V = V= { v 1 , v 2 , . . . , v m v_1,v_2,...,v_m v1,v2,...,vm}, 和m个对应标签 Y = Y= Y= { y 1 , y 2 , . . . , y m y_1,y_2,...,y_m y1,y2,...,ym}
- 每个视频 v i = v_i= vi={ x 1 ( i ) , . . . , x n i ( i ) x^{(i)}_1,...,x^{(i)}_{n_i} x1(i),...,xni(i)} ∈ V ∈V ∈V可以是任意长度,其长度表示为 n i n_i ni。为简单起见,假设每个训练视频只包含一个行为实例。
- 每个标签 y i = ( s ( i ) , e ( i ) , l ( i ) ) y_i=(s^{(i)},e^{(i)},l^{(i)}) yi=(s(i),e(i),l(i))包含一个起始索引 s s s,一个结束索引 e e e,和一个类别标签 l l l
- 目标:学习一个置信度函数 F : V × Y → R F:V×Y →R F:V×Y→R,它测量视频中出现特定动作实例的可能性。
- 要求 F F F采用如方程1中的逐帧求和形式。将 F F F的可学习参数,即CNN的参数表示为 w w w。 用符号 F ( v , y ; w ) F(v,y; w) F(v,y;w)来表示视频 v v v和窗口 y y y的参数 w w w产生的置信度分数。
- 对于训练视频 v i v_i vi,将定位损失 L l o c L_{loc} Lloc定义为最高得分时间窗与行为 l i l^i li的真值标签之间的差距:

其中, [ ⋅ ] + = m a x ( 0 , ⋅ ) [·]_+=max(0,·) [⋅]+=max(0,⋅); ∆ ( y , y ‾ ) = ∣ y ∪ y ‾ ∣ − ∣ y ∩ y ‾ ∣ ∆(y,\overline{y})=|y∪\overline{y}|-|y∩\overline{y}| ∆(y,y)=∣y∪y∣−∣y∩y∣(用于降低对与真实标签高度重叠的窗口的惩罚) - 为了进一步提高网络的分类能力,引入了一个分类损失 L c l s L_{cls} Lcls,该 L c l s L_{cls} Lcls强制其他行为的估计窗口的分数要低于真实标签动作类的估计窗口的分数。定义:

其中 M M M是一个固定的参数,如果距离已经小于 M M M,则不进行惩罚检测。在实验中,将 M M M设为视频 v i v_i vi的真实标签窗口长度 ∣ y i ∣ |y_i| ∣yi∣。 - 全结构目标 L L L是训练集中所有视频的两个损失之和,定义如下:

其中, λ = 0.5 λ=0.5 λ=0.5。 - 两种损失函数都是典型的结构支持向量机损失,因此可以以类似的端到端方式学习参数 w w w。 由于定位和分类损失都是可微分的,因此可以通过反向传播学习两个CNN流的参数。 具体而言,对于一个层 l l l,一个视频 L ( ⋅ ) ( v i ) L_{(·)}(v_i) L(⋅)(vi)相对于该层的参数 w ( l ) w^{(l)} w(l)的损失的梯度可以计算为

- 相对于网络参数 f f f的梯度可以通过反向传播计算出来,因此,它需要计算两个梯度:1)分类器 f f f置信函数 F w . r . t . F_{w.r.t.} Fw.r.t.的梯度。2)目标函数 L ( ⋅ ) w . r . t . F L(·)_{w.r.t}.F L(⋅)w.r.t.F的梯度:

- 为了计算次梯度,我们需要找到最好的窗口 y i ∗ y^*_i yi∗。 使用SMS算法(算法1)在 L c l s L_{cls} Lcls中查找 y i ∗ y^*_i yi∗。 但是,由于∆在 L l o c L_{loc} Lloc中的最大化中,为了计算 y i ∗ y^*_i yi∗,我们需要执行损失增强置信度的最大化。 在算法2中,修改SMS算法以包含这个术语,实现相同的线性时间复杂度,保证在训练期间可以有效地计算这个。 另外,只计算top检测。

实验
数据集:THUMOS’14
实现:基于Caffe
双流神经网络:
- Spatial-CNN的输入是裁剪为224×224的RGB视频帧,并减去平均RGB值。
- Motion-CNN的输入是由TVL1光流算法计算的密集光流通道。将每个光流图像缩放到[1,255]之间,并在两个方向上叠加10帧的流,以形成224×224×20的3D体积。
- Spatial-CNN在ImageNet上进行了对象识别的预先训练
- 针对UCF101上的动作分类预先训练了Motion-CNN。
- 分别训练Spatial-CNN和Motion-CNN,然后共同调整它们最后的两个完全连接的层。
- 对这两个流采用多尺度随机裁剪。对于每个样本,首先从预定义列表中随机选择一个比例尺,然后选择一个尺寸为 ( 224 × 224 ) × s c a l e (224×224)×scale (224×224)×scale的随机裁剪。在输入到网络之前,裁剪区域被调整为224×224。对于空间CNN,有三个尺度[1, 0.875, 0.75];对于Motion-CNN,使用两个尺度[1, 0.875]。
后期处理:
- 将每个测试视频分成重叠的20秒片段,并在相邻片段之间重叠18秒,并针对每个片段独立执行定位。
- 将这些片段中的预测合并在一起。将动作实例的数量设置为K = 100,因为实验性K≥100不会提高我们验证集的召回率。
- 等式1中的时间动作窗口分数倾向于给较长的窗口更高的分数,所以我们另外通过其窗口长度来标准化每个窗口的置信度。
- 将置信度得分乘以行动时间先验,以鼓励行动窗口具有合理的长度。
- 在生成所有候选者后,使用非最大抑制来过滤具有大重叠的那些候选者。
平衡训练: 中间帧比开始和结束帧更普遍,因此为了防止网络偏向中间帧,在训练期间将每个中间帧的分数除以总窗口长度。 另外,由于动作开始和结束的手动注释相对较嘈杂,因此从前10%帧开始随机采样开始帧,从后10%随机采样结束帧, 中间帧从中间抽样80%。
评估指标: mAP(如果预测正确的行为标签,并且IoU>重叠阈值σ,则检测计为正确)
实验结果
在训练过程中,裁剪每个验证视频以缩短包含单个动作实例的800帧剪辑。我们通过将来自训练和验证片段的动作实例与背景视频和验证视频拼接起来,增加了训练数据集,其中20个类别的任何实例都不出现。总共,生成了42000个用于训练的动作片段。根据验证视频的版本子集中的结果选择超参数。分别训练Spatial-CNN和Motion-CNN,分别进行16K和20K次迭代。然后,对双流网络进行微调,进行2K次迭代。
在测试时间,将所有视频下采样为5fps,并筛选出不太可能包含20个动作类别中任何一个的视频。通过平均他们在行为识别模型上得到的框架级分数平均来实现这一点,在THUMOS’14上进行了细化。在图4中,展示了THUMOS’14测试集的示例检测。


