目录
- KNN算法
- 用鸢尾花数据做分类
- 通过交叉验证的方式筛选参数
- 用KNN进行癌症的预测
- 将字符串转换成数据值
KNN算法
用鸢尾花数据做分类
import numpy as np
import matplotlib.pylab as pyb
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
X,y =load_iris(True)
print(X.shape)
X=X[:,:2]
print(X.shape)
knn=KNeighborsClassifier(n_neighbors=5)
knn.fit(X,y)
x1=np.linspace(4,8,100)
y1=np.linspace(2,4.5,80)
X1,Y1=np.meshgrid(x1,y1)
print(X1.shape,Y1.shape)
X_test=np.c_[X1.ravel(),Y1.ravel()]
print(X_test.shape)
y_=knn.predict(X_test)
from matplotlib.colors import ListedColormap
lc=ListedColormap(['#FFAAAA','#AAFFAA','#AAAAFF'])
lc2=ListedColormap(['#FF0000','#00FF00','#0000FF'])
pyb.scatter(X_test[:,0],X_test[:,1],c=y_,cmap=lc)
pyb.scatter(X[:,0],X[:,1],c=y,cmap=lc2)
pyb.show()
(150, 4)
(150, 2)
(80, 100) (80, 100)
(8000, 2)
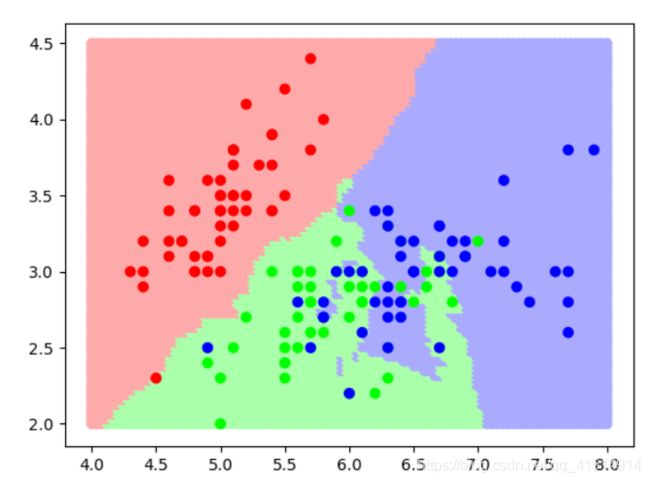
通过交叉验证的方式筛选参数
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import cross_val_score
X,y=load_iris(True)
knn=KNeighborsClassifier()
score=cross_val_score(knn,X,y,scoring='accuracy',cv=6)
erros=[]
for k in range(1,14):
knn=KNeighborsClassifier(n_neighbors=k)
score=cross_val_score(knn,X,y,scoring='accuracy',cv=6).mean()
erros.append(1-score)
import matplotlib.pyplot as plt
plt.plot(np.arange(1,14),erros)
plt.show()
weights=['uniform','distance']
for w in weights:
knn = KNeighborsClassifier(n_neighbors=11,weights=w)
score = cross_val_score(knn, X, y, scoring='accuracy', cv=6).mean()
print(w,score)
result={}
for k in range(1,14):
for w in weights:
knn=knn = KNeighborsClassifier(n_neighbors=k,weights=w)
sm=cross_val_score(knn, X, y, scoring='accuracy', cv=6).mean()
result[w+str(k)]=sm
max=np.array(list(result.values())).argmax()
print(max)
uniform 0.98070987654321
distance 0.9799382716049383
20
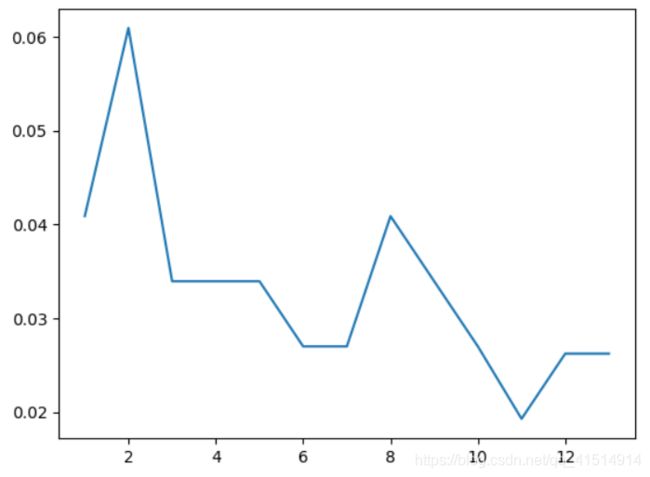
用KNN进行癌症的预测
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import accuracy_score
cancer=pd.read_csv('./cancer.csv',sep='\t')
cancer.drop('ID',axis=1,inplace=True)
X=cancer.iloc[:,1:]
y=cancer['Diagnosis']
X_train ,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2)
knn=KNeighborsClassifier()
params={'n_neighbors':[i for i in range(1,30)],
'weights':['uniform','distance'],
'p':[1,2]}
gcv=GridSearchCV(knn,params,scoring='accuracy',cv=6)
gcv.fit(X_train,y_train)
knn_best=gcv.best_estimator_
y_=knn_best.predict(X_test)
print(accuracy_score(y_test,y_))
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test,y_)
from sklearn.metrics import classification_report
print(classification_report(y_test,y_,target_names=['B','M']))
将字符串转换成数据值
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score,GridSearchCV
from sklearn.model_selection import KFold,StratifiedKFold
data=pd.read_csv('./salary.txt')
data.drop(labels=['final_weight','education','capital_gain','capital_loss'],axis=1,inplace=True)
X=data.iloc[:,0:-1]
y=data['salary']
u=X['workclass'].unique()
def convert(x):
return np.argwhere(u==x)[0,0]
X['workclass']=X['workclass'].map(convert)
cols=['marital_status','occupation','relationship','race','sex','native_country']
for col in cols:
u=X[col].unique()
def convert(x):
return np.argwhere(u==x)[0,0]
X[col] = X[col].map(convert)
knn=KNeighborsClassifier()
kFold=KFold(10)
accuracy=0
for train,test in kFold.split(X,y):
knn.fit(X.loc[train],y[train])
acc=knn.score(X.loc[test],y[test])
accuracy+=acc/10
print(accuracy)
0.7973345728987424
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
from sklearn.preprocessing import OrdinalEncoder,OneHotEncoder,LabelEncoder
from sklearn.neighbors import KNeighborsClassifier
salary=pd.read_csv('./salary.txt')
salary.drop(labels=['final_weight','education_num','capital_gain','capital_loss'],axis=1,inplace=True)
ordinalEncoder=OrdinalEncoder()
data=ordinalEncoder.fit_transform(salary)
salary_ordinal=DataFrame(data,columns=salary.columns)
salary_ordinal.head()
labelEncoder=LabelEncoder()
salary_label=labelEncoder.fit_transform(salary['salary'])
for col in salary.columns:
salary[col]=labelEncoder.fit_transform(salary[col])
salary.head()
edu=salary[['education']]
onehotEncoder=OneHotEncoder()
onehot=onehotEncoder.fit_transform(edu)
onehot.toarray()[:10]