时序动作定位:Rethinking the Faster R-CNN Architecture for Temporal Action Localization(TAL-Net)
这篇是2018CVPR的文章,论文下载链接: http://cn.arxiv.org/pdf/1804.07667.pdf
1 背景
1.1 Faster R-CNN vs TAL-Net
得益于Faster R-CNN 在目标检测领域的巨大成功,自然想讲Faster R-CNN 应用于视频时序动作检测。思路是直接把anchor、proposals、pooling全变成了对1-D时间维度的处理

1.2 R-C3D
《R-C3D: Region Convolutional 3D Network for Temporal Activity Detection》是 2017年ICCV的文章,论文下载链接:https://arxiv.org/pdf/1703.07814.pdf

Rethinking的作者认为R-C3D是对Faster R-CNN 的直接的、简单的应用,精度不高,主要存在以下三方面的问题并提出了优化方案:
1)如何解决动作时序片段变化大的问题?
时间段的变化比目标检测的区域变化范围更大,一个动作几秒到几分钟不等,Faster R-CNN评估不同尺度的proposals用的是共享特征,而时间段的范围和anchor的跨度不对齐,可能无法获得相关信息。
Rethinking提出多尺度的网络结构(mutilti-tower)和扩张(空洞)卷积(dilated temporal conv)来扩大感受野并对齐。
2)如何解决利用上下文信息问题?
时间上的动作开始之前和之后的这些上下文信息对时序定位任务的作用比空间上的上下文对目标检测的作用要大的多。Faster R-CNN没有利用到上下文。
Rethinking提出扩展在proposal生成和动作分类时的感受野。
3)如何最好的融合多流信息?
目前在动作分类任务效果好的都是混合了RGB和Flow特征,Faster R-CNN没有融合。
Rethinking提出分类结果上融合的晚融合(late fusion)方法,并且证明了晚方法比早融合方法效果好。
2 TAL-Net
主要是Receptive Field Alignment、Context Feature Extraction、 Late Feature Fusion三方面工作:
2.1 Receptive Field Alignment
thumos14数据集动作片段几秒到几分钟都有,为了保证high recall,需要 anchor segment 有范围更宽的尺度。但如果感受野太小,可能无法提取到足够的特征给长时间段的anchor;而如果感受野太大,提取的特征可能包含很多无关信息,对短时间anchor又不利。
解决这个问题关键的两步骤:
1)multi-tower ;
2)dilated temporal convolutions;
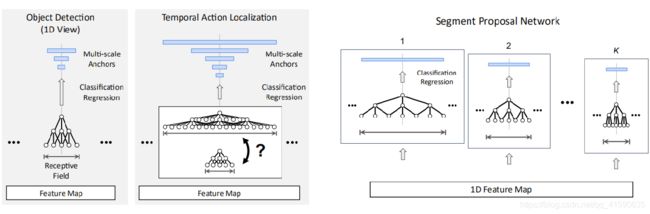
Segment proposal network是K个temporal convnets的集合,每个负责分类特定尺度的anchor segments,每个temporal convnet感受野尺寸和anchor尺寸一致。每个卷积网络最后用两个kernel size为1的卷积层对anchor分类和对边界回归。
下面就是 设计与感受野s对应的temporal convnet:
以往方法:
1)多叠加几层卷积,s=(kernel-1)layer+1,层数L将随着s线性增长,增加很多参数,也容易过拟合;
2)增加池化层,s=2*(layer+1) - 1 (kernel=2),这个方法会指数级降低输出特征图的分辨率;
为了避免增加模型参数并保持分辨率,提出用dilated temporal convolutions:
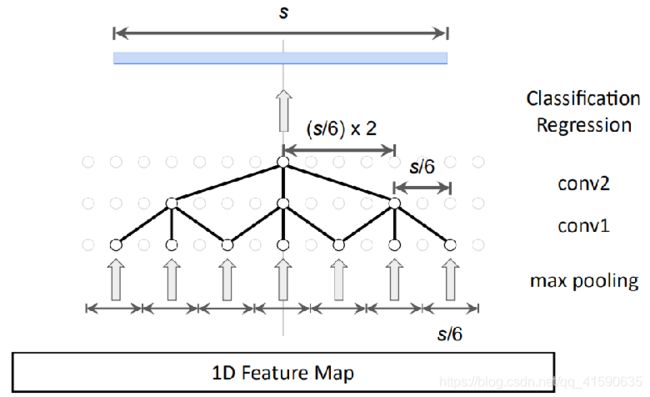
其中,每个temporal convnet只有两层dilated conv layers。目标感受野尺寸s,定义两层的dialation rate :d1=s/6 ,d2=s/6*2,为了平滑输入,在第一个conv层前加了一个kernel size = s/6的max pooling。
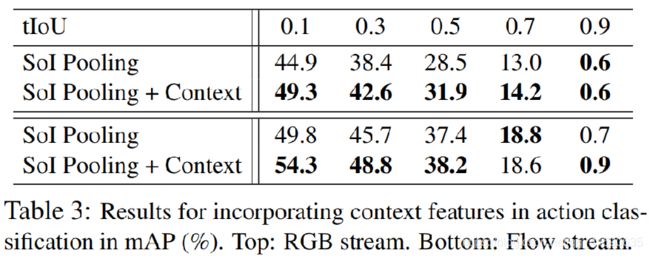
2.2 Context Feature Extraction
上面的proposal生成方法只计算了anchor内的,没有考虑上下文。为了对anchor分类和回归的时候加入上下文信息,在anchor前后各取s/2长度加入一起计算,这个操作可以通过dilated rate2来完成,d1=s/62, d2=s/622,最大池化的kernel size也要加倍为 s/6*2。

作者举了两个例子,如看到一个标枪在空中飞,则表明一个人刚完成“扔标枪”的动作(javelin throw),而不是“撑杆跳”(pole vault),因而上下文对于动作分类(Action recognition)很有用处。
而当看到一个人站在“diving board”远端上时,这便是“diving”动作开始的强烈信号,这对于动作检测很有用处。
2.3 Late Feature Fusion
Two-Stream Convolutional Networks for Action Recognition in Videos. K. Simonyan , A. Zisserman. 2014 NIPS

得益于双流在动作识别领域的巨大成功,作者认为action proposal 的生成也可以采用双流的思想。并且不同于直接在一开始就将RGB和flow融合的早融合(early fusion),而是采用先用两个网络分别提取1-D的RGB和FLOW特征,输入proposal生成网络(rpn)最后两个分数做均值产生proposals,再把proposals结合各自网络特征最分类(fast-rcnn部分)在把两个网络结果做均值。
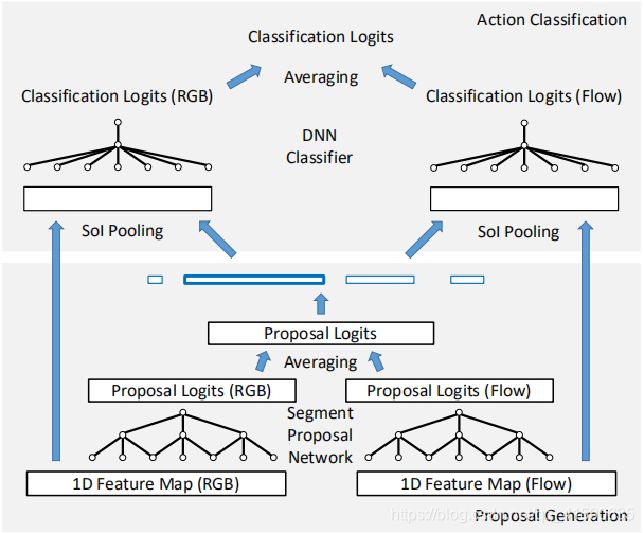
作者证明了这种方法比特征早融合,然后用这个特征一直计算到结果的方法效果好一些。
3 实验
为了验证作者做的三部分工作的效果,做了大量的消融实验:




thumos14数据集效果:
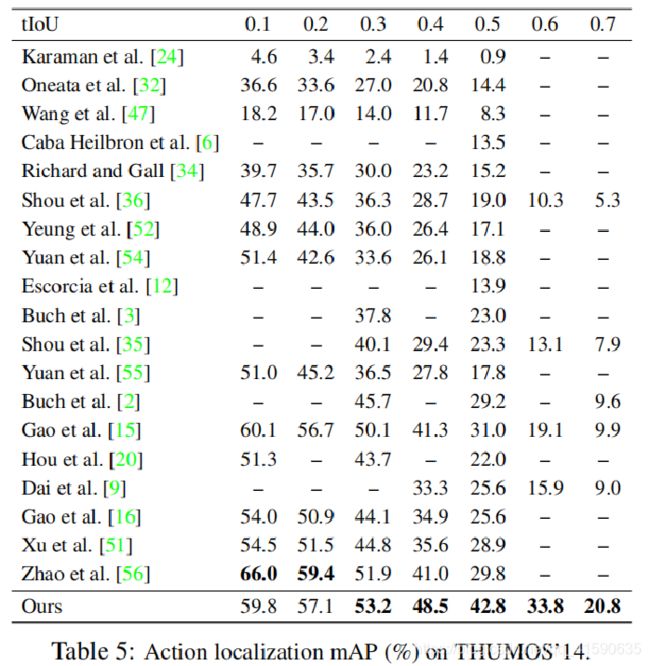
TAL-Net效果超过之前方法很多,IOU=0.5达到了42.8%,为当时最好效果,现在也是比较好的结果。(其中[51]为R-C3D)

作者列出了thumos14数据集的三个动作效果,其中扣篮开始和结束的预测都比较好;中间“CleanAndJerk”的例子虽然动作成功分类,但是动作的开始时间预测较差,是因为前面的准备工作和动作的开始很像,差别不大导致的。最后的扔铅球的例子被误分类为扔铁饼,是因为两者的上下文背景很相似。
ActivityNet数据集效果:
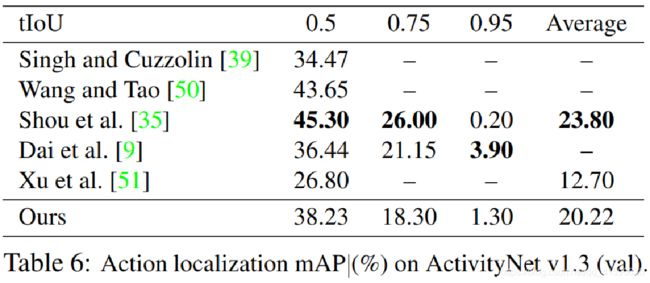
ActivityNet数据集的效果并不是很好,作者给出的解释是:
THUMOS14 is a better dataset for evaluating action localization than ActivityNet, as the former has more action instances per video and each video contains a larger portion of background activity: on average, the THUMOS14 training set has 15 instances per video and each video has 71% background, while the ActivityNet training set has only 1.5 instances per video and each video has only 36% background.
更多文章请搜索公众号“StrongerTang”,众多资料分享,一起学习!
相关阅读:
Representation Flow for Action Recognition论文解读
视频动作检测最新发展调研(Action Detection)
视频动作识别调研(Action Recognition)