FPN特征金字塔 完整详解 【论文笔记】
Contents
- 1 Introduction
- 2 FPN网络
- 2.1 自底向上
- 2.2 自顶向下
- 2.3 横向连接
- 3 总结
- 4 FPN网络 pytorch代码
1 Introduction
论文地址:Feature Pyramid Networks for Object Detection
原来多数的目标检测算法仅仅根据最终的特征图输出做预测,而低层的特征语义信息比较少但目标位置准确;高层的特征语义信息丰富但目标位置粗略。识别不同尺寸的目标一直是目标检测的难点,尤其是小目标!
以VGG16为例,假如stride=16,表示若原图大小是1000×600,经过卷积层后的特征图大小为60×40,可理解为特征图上一个像素点映射原图中一个16×16的图像区域;那原图中有一个小于16×16大小的物体则会检测不到。
特征图金字塔网络FPN(Feature Pyramid Networks)是2017年提出的一种网络,它主要解决的是物体检测中的多尺度问题,在基本不增加原有模型计算量的情况下,通过简单的网络连接改变,大幅度提升了小物体的检测性能。
目前多尺度目标检测的图像/特征金字塔解决思路有下面几种:
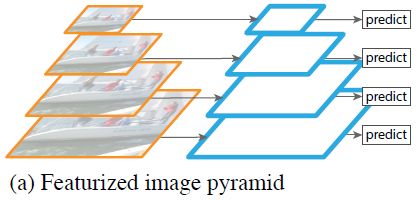
利用卷积神经网络在图片金字塔上进行特征提取,可以构建出特征金字塔。上图中左侧为图像金字塔(将图像resize成不同的大小),右侧为在图像金字塔上进行特征提取得到的特征金字塔。在得到特征金字塔后,下一步就是在特征金字塔上进行目标识别。这样的处理方式运算量巨大,不行不行。
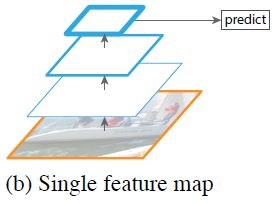
上图即为仅采用网络最后一层的特征,如Faster R-CNN一系列模型网络,包括最开头VGG16的举例。
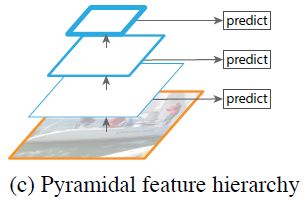 同时利用低层特征和高层特征,分别在不同的层同时进行预测。像SSD(Single Shot Detector)就是采用这种多尺度特征融合的方式,从网络不同层抽取不同尺度的特征做预测,这种方式不会增加额外的计算量(正向传播都已经计算出来了)。作者认为SSD算法中没有用到足够低层的特征(在SSD中,使用的最低层的特征是VGG网络的conv4_3),而在作者看来足够低层的特征对于检测小物体是很关键得。
同时利用低层特征和高层特征,分别在不同的层同时进行预测。像SSD(Single Shot Detector)就是采用这种多尺度特征融合的方式,从网络不同层抽取不同尺度的特征做预测,这种方式不会增加额外的计算量(正向传播都已经计算出来了)。作者认为SSD算法中没有用到足够低层的特征(在SSD中,使用的最低层的特征是VGG网络的conv4_3),而在作者看来足够低层的特征对于检测小物体是很关键得。
2 FPN网络
结合之前的工作,作者提出了FPN网络。做法很简单,把低分辨率、高语义信息的高层特征和高分辨率、低语义信息的低层特征进行自上而下的侧边连接,使得所有尺度下的特征都有丰富的语义信息。
网络大致结构如下:一个自底向上的线路、一个自顶向下的线路、横向连接(lateral connection,图中放大的区域是横向连接)

2.1 自底向上
自底向上的过程就是神经网络普通的前向传播过程。在前向过程中,feature map的大小在经过某些层后会改变,而在经过其他一些层的时候不会改变,作者将不改变feature map大小的层归为一个stage,因此每次抽取的特征都是每个stage的最后一个层输出,这样就能构成特征金字塔。
2.2 自顶向下
把高层特征图进行上采样(比如最近邻上采样),然后把该特征横向连接(lateral connections )至前一层特征,因此高层特征得到加强。
上采样几乎都是采用内插值方法,即在原有图像像素的基础上在像素点之间采用合适的插值算法插入新的元素,从而扩大原图像的大小。通过对特征图进行上采样,使得上采样后的特征图具有和下一层的特征图相同的大小,这样做主要是为了利用底层的位置细节信息。
2.3 横向连接
横向连接:前一层的特征图经过 1×1的卷积核卷积,目的为改变通道数,因为要和后一层上采样的特征图通道数相同。
连接方式:像素间的加法。
重复迭代该过程,直至生成最精细的特征图。得到精细的特征图之后,用 3×3的卷积核再去卷积已经融合的特征图,目的是消除上采样的混叠效应,以生成最后需要的特征图。
混叠效应:在统计、信号处理和相关领域中,混叠是指取样信号被还原成连续信号时产生彼此交叠而失真的现象。当混叠发生时,原始信号无法从取样信号还原。而混叠可能发生在时域上,称做时间混叠,或是发生在频域上,被称作空间混叠。在视觉影像的模拟数字转换或音乐信号领域,混叠都是相当重要的议题。因为在做模拟-数字转换时若取样频率选取不当将造成高频信号和低频信号混叠在一起,因此无法完美地重建出原始的信号。为了避免此情形发生,取样前必须先做滤波的操作。
所以论文中使用一个 3×3 的卷积核来卷积特征图来产生最后的参考特征图。
3 总结
因为池化会不断缩小特征图尺寸,卷积神经网络由浅到深,分辨率越来越粗糙,特征图越来越小,但是卷积层越高,特征图包含语义信息越丰富。
作者提出的FPN(Feature Pyramid Network)算法同时利用低层特征高分辨率和高层特征的高语义信息,通过融合这些不同层的特征达到预测的效果。并且预测是在每个融合后的特征层上单独进行的,这和常规的特征融合方式不同。
总结来说,FPN = top-down的融合 + 在金字塔各层进行prediction。
4 FPN网络 pytorch代码
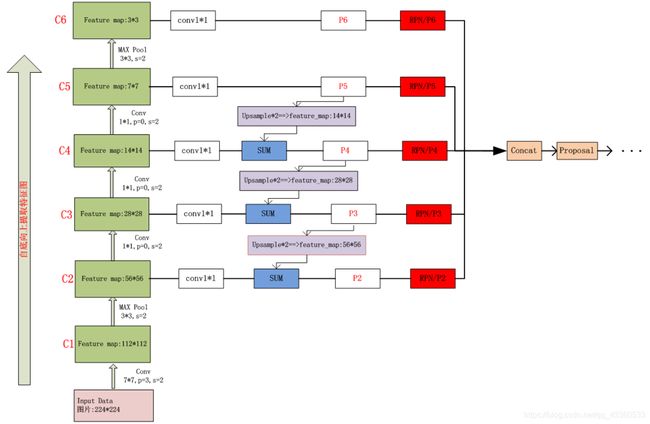
首先通过一张图(图片来源),对FPN的整体工作原理进行直观描述(基于ResNet50网络)
以下代码参考github
class FPN(nn.Module):
def __init__(self, num_blocks, num_classes, back_bone='resnet', pretrained=True):
super(FPN, self).__init__()
self.in_planes = 64
self.num_classes = num_classes
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
BatchNorm = nn.BatchNorm2d
self.back_bone = build_backbone(back_bone)
# Bottom-up layers
self.layer1 = self._make_layer(Bottleneck, 64, num_blocks[0], stride=1)
self.layer2 = self._make_layer(Bottleneck, 128, num_blocks[1], stride=2)
self.layer3 = self._make_layer(Bottleneck, 256, num_blocks[2], stride=2)
self.layer4 = self._make_layer(Bottleneck, 512, num_blocks[3], stride=2)
# Top layer
self.toplayer = nn.Conv2d(2048, 256, kernel_size=1, stride=1, padding=0) # Reduce channels
# Smooth layers
self.smooth1 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
self.smooth2 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
self.smooth3 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
# Lateral layers
self.latlayer1 = nn.Conv2d(1024, 256, kernel_size=1, stride=1, padding=0)
self.latlayer2 = nn.Conv2d( 512, 256, kernel_size=1, stride=1, padding=0)
self.latlayer3 = nn.Conv2d( 256, 256, kernel_size=1, stride=1, padding=0)
def _upsample(self, x, h, w): # upsample use 'bilinear' interpolate
return F.interpolate(x, size=(h, w), mode='bilinear', align_corners=True)
def _make_layer(self, Bottleneck, planes, num_blocks, stride):
strides = [stride] + [1]*(num_blocks-1)
layers = []
for stride in strides:
layers.append(Bottleneck(self.in_planes, planes, stride))
self.in_planes = planes * Bottleneck.expansion
return nn.Sequential(*layers)
def _upsample_add(self, x, y):
'''Upsample and add two feature maps.
Args:
x: (Variable) top feature map to be upsampled.
y: (Variable) lateral feature map.
Returns:
(Variable) added feature map.
Note in PyTorch, when input size is odd, the upsampled feature map
with `F.upsample(..., scale_factor=2, mode='nearest')`
maybe not equal to the lateral feature map size.
e.g.
original input size: [N,_,15,15] ->
conv2d feature map size: [N,_,8,8] ->
upsampled feature map size: [N,_,16,16]
So we choose bilinear upsample which supports arbitrary output sizes.
'''
_,_,H,W = y.size()
return F.interpolate(x, size=(H,W), mode='bilinear', align_corners=True) + y
def forward(self, x):
# Bottom-up
c1 = F.relu(self.bn1(self.conv1(x)))
c1 = F.max_pool2d(c1, kernel_size=3, stride=2, padding=1)
c2 = self.layer1(c1)
c3 = self.layer2(c2)
c4 = self.layer3(c3)
c5 = self.layer4(c4)
# Top-down
p5 = self.toplayer(c5)
p4 = self._upsample_add(p5, self.latlayer1(c4))
p3 = self._upsample_add(p4, self.latlayer2(c3))
p2 = self._upsample_add(p3, self.latlayer3(c2))
# Smooth
p4 = self.smooth1(p4)
p3 = self.smooth2(p3)
p2 = self.smooth3(p2)
return p2, p3, p4, p5
参考博客
欢迎关注【OAOA】
