29Python时间序列分析(美国消费者信心指数及维基百科点击量EDA,含实例数据)
唐宇迪《python数据分析与机器学习实战》学习笔记
29Python时间序列分析
一、pandas生成时间序列
常见的时间序列:时间戳(timestamp):具体时间点2020.4.6的20:58的15秒
固定周期(period)
时间间隔(interval)
创建时间序列,最简单函数:date_range H:小时、D:天、M:月
#时间的几种表达方式:2016 Jul 1 ,7/1/2016,2016-07-01,2016/07/01
rng = pd.date_range('2016/07/01',periods=10,freq='D')#频率默认按天加,3D就3天加
#这里也用(起始时间、终止时间、频率)的方式创建,
rng
DatetimeIndex([‘2016-07-01’, ‘2016-07-02’, ‘2016-07-03’, ‘2016-07-04’, ‘2016-07-05’, ‘2016-07-06’, ‘2016-07-07’, ‘2016-07-08’, ‘2016-07-09’, ‘2016-07-10’],dtype=‘datetime64[ns]’, freq=‘D’)
将时间作为索引,这样方便之后通过时间就拿出数据或者对数据进行切片
time = pd.Series(np.random.randn(10),
index = pd.date_range("2016-1-1",periods=10))
time
2016-01-01 -0.070435
2016-01-02 -0.916814
2016-01-03 0.370355
2016-01-04 0.215701
2016-01-05 -0.266909
2016-01-06 -0.476030
2016-01-07 -0.600339
2016-01-08 0.792472
2016-01-09 -0.074305
2016-01-10 1.772727
Freq: D, dtype: float64
truncate过滤
before这里2016-1-3之前的数据都不要了,也可以用after操作。
time.truncate(before='2016-1-5')
2016-01-05 -0.266909
2016-01-06 -0.476030
2016-01-07 -0.600339
2016-01-08 0.792472
2016-01-09 -0.074305
2016-01-10 1.772727
Freq: D, dtype: float64
时间戳的指定:
print(pd.Timestamp("2016-07-1"))
print(pd.Timestamp("2016-07-1 10"))
print(pd.Timestamp("2016-07-1 10:15:1"))
2016-07-01 00:00:00
2016-07-01 10:00:00
2016-07-01 10:15:01
时间区间的指定:
pd.Period("2016-07")
Period(‘2016-07’, ‘M’)
pd.Period("2016-07-1 10:5:1")
Period(‘2016- 07-01 10:05:01’, ‘S’)
时间加减:
pd.Timestamp('2016-01-01 10:10')+pd.Timedelta('1 day')
Timestamp(‘2016-01-02 10:10:00’)
时间戳和时间周期的转换及区别
ts = pd.Series(range(10),pd.date_range('07-10-16 8:00',periods=10,freq='H'))
ts_period = ts.to_period()
ts_period
2016-07-10 08:00 0
2016-07-10 09:00 1
2016-07-10 10:00 2
2016-07-10 11:00 3
2016-07-10 12:00 4
2016-07-10 13:00 5
2016-07-10 14:00 6
2016-07-10 15:00 7
2016-07-10 16:00 8
2016-07-10 17:00 9
Freq: H, dtype: int64
print(ts_period['2016-07-10 08:30':'2016-07-10 11:45'])
print('————————')
print(ts['2016-07-10 08:30':'2016-07-10 11:45'])
2016-07-10 08:00 0
2016-07-10 09:00 1
2016-07-10 10:00 2
2016-07-10 11:00 3
Freq: H, dtype: int64
————————
2016-07-10 09:00:00 1
2016-07-10 10:00:00 2
2016-07-10 11:00:00 3
Freq: H, dtype: int64
二、数据重采样 (多角度多维度分析数据)
时间数据由一个频率转换到另外一个频率。例如将天变换为月,为降采样。降月变为天,为升采样。
这里重采样直接使用resample操作
#升采样
rng = pd.date_range("1/1/2011",periods=90,freq='D')
ts = pd.Series(np.random.randn(len(rng)),index=rng)
print(ts.head())
print('——————————')
print(ts.resample('M').sum()) #可以按月展示和,也可mean展示均值
print('——————————')
print(ts.resample('3D').sum().head())
2011-01-01 -0.054447
2011-01-02 2.114083
2011-01-03 0.593211
2011-01-04 0.923929
2011-01-05 -0.480473
Freq: D, dtype: float64
——————————
2011-01-31 4.719470
2011-02-28 2.434292
2011-03-31 1.882250
Freq: M, dtype: float64
——————————
2011-01-01 2.652847
2011-01-04 2.060122
2011-01-07 -2.649867
2011-01-10 -2.167812
2011-01-13 0.268306
Freq: 3D, dtype: float64
升采样比如3天综合数据扩展为每天的数据,会造成空值,这时就需要指定升采样策略了,插值填充。
day3Ts = ts.resample('3D').mean()
print(day3Ts.resample('D').asfreq().head(6))
2011-01-01 0.884282
2011-01-02 NaN
2011-01-03 NaN
2011-01-04 0.686707
2011-01-05 NaN
2011-01-06 NaN
Freq: D, dtype: float64
升采样插值方法: ffill(空值取前面的值)、bfill(空值取后面的值)、interpolate(线性取值)
#前值填充,只对一个值填充
print(day3Ts.resample('D').ffill(1).head(6))
print("——————————————")
#前值填充,两个值都填充
print(day3Ts.resample('D').ffill(2).head(6))
print("——————————————")
#后值填充
print(day3Ts.resample('D').bfill(2).head(6))
print('——————————————')
#线性拟合填充,将原始点连线,然后线上取点插值
print(day3Ts.resample('D').interpolate('linear').head())
2011-01-01 0.884282
2011-01-02 0.884282
2011-01-03 NaN
2011-01-04 0.686707
2011-01-05 0.686707
2011-01-06 NaN
Freq: D, dtype: float64
——————————————
2011-01-01 0.884282
2011-01-02 0.884282
2011-01-03 0.884282
2011-01-04 0.686707
2011-01-05 0.686707
2011-01-06 0.686707
Freq: D, dtype: float64
———————————————
2011-01-01 0.884282
2011-01-02 0.686707
2011-01-03 0.686707
2011-01-04 0.686707
2011-01-05 -0.883289
2011-01-06 -0.883289
Freq: D, dtype: float64
——————————————
2011-01-01 0.884282
2011-01-02 0.818424
2011-01-03 0.752566
2011-01-04 0.686707
2011-01-05 0.163375
Freq: D, dtype: float64
三、滑动窗口
假设有一份数据(2016~2017年365天365个点),现在想了解2016/2/5情况,拿出这个点的数据可对其进行描述,但这样太绝对有误差,可以拿2.1-2.10的数据取平均值来描述。这样更加科学,尤其是在进行预测时。我们可以基于这样一个窗口取平均,使值更加平稳。**滑动窗口**:指定窗口尺寸,计算时根据待求值对窗口进行单位距离滑动。

#构造数据
df = pd.Series(np.random.randn(600),index= pd.date_range('7/1/2016',freq='D',periods = 600))
print(df.head())
print('————————')
#构造滑动窗口(指定窗口大小)
r = df.rolling(window = 10)
print(r)
print('————————')
#指定窗口计算方式
print(r.mean().head(15)) #在长度为10的窗口上计算均值
2016-07-01 -1.678791
2016-07-02 -0.423588
2016-07-03 -0.181786
2016-07-04 -1.788095
2016-07-05 -1.655618
Freq: D, dtype: float64
————————
Rolling [window=10,center=False,axis=0]
————————
2016-07-01 NaN
2016-07-02 NaN
2016-07-03 NaN
2016-07-04 NaN
2016-07-05 NaN
2016-07-06 NaN
2016-07-07 NaN
2016-07-08 NaN
2016-07-09 NaN
2016-07-10 -0.521953
2016-07-11 -0.393140
2016-07-12 -0.328614
2016-07-13 -0.286851
2016-07-14 -0.150791
2016-07-15 -0.057482
Freq: D, dtype: float64
可视化效果对比展示
%matplotlib inline
import matplotlib.pyplot as plt #导人模块
plt.figure(figsize=(15,5)) #指定绘图尺寸
df.plot(style='r--') #原始数据用红色虚线展示
df.rolling(window = 10).mean().plot(style='b') #窗口滑动计算数据,用蓝色实线展示

四、ARIMA模型
4.1 数据平稳性与差分法
ARIMA模型=AR+I+MA,应用:如现在拿到股票数据,根据其历史变化情况预测其未来变化。
拿到的数据可能千奇百怪,需要有迹可循才能预测,因此要求这些序列有惯性。


数据浮动太大,为了让数据变得稳定采用:差分法,二阶差分就是对一阶差分做差分。

4.2ARIMA模型的组成 (AR + I + MA)
i=几,就和前几天有关,一直延续到第t天。I就是指的这个差分项。


前面误差项的预测:让误差越均衡越好



4.3相关函数评估方法
如果两个变量变化情况相似则相关系数为+1,如果变化相反则为-1(负相关),为0则无关。
下面0-20代表阶数,虚线代表置信区间,一般95%
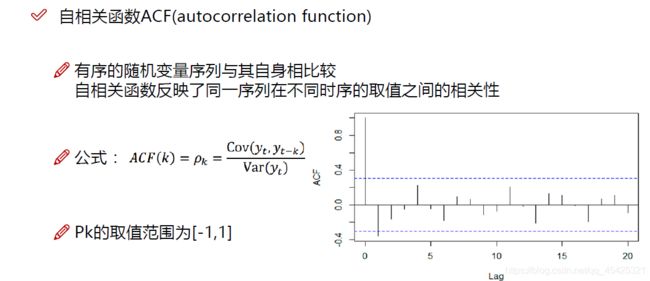
PACF做得更绝,严格两个变量间的相关性。

这里先提起安装一个模块: statsmodels,我这走镜像网络在cmd里面采用pip安装
python-ana -m pip install statsmodels -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
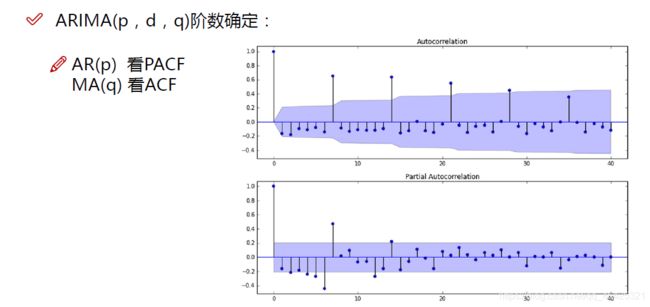
d通过肉眼观察就行,通过观察ACF、PACF结果看p\q取值,AR主要是PACF在多少阶后截尾取得P值。MA看ACF多少阶截尾取得q值,其他条件满足下表。

下图阴影代表置信区间,p看下半部分图取1就行,q看上半部分图取7.

通过观察法确定pq不完全靠谱,这里把你觉得可能的pq组合拿出来通过下面两个函数计算。
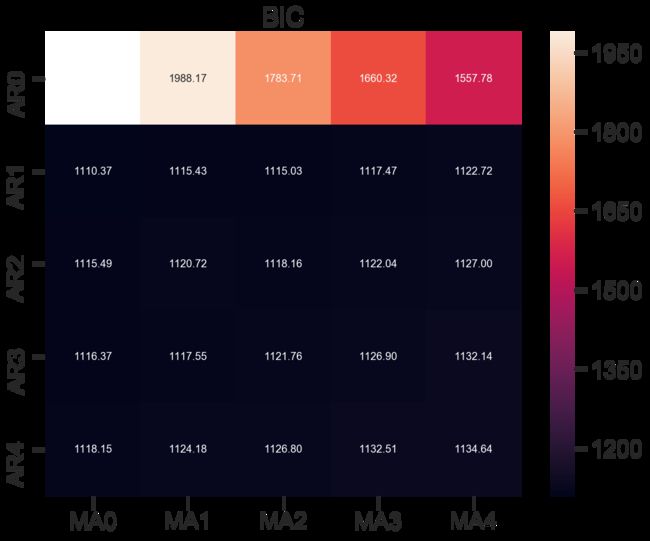
通常K越小L越大越好,画出热度图横坐标为q、纵坐标为p,选择值小的组合,AIC和BIC得出的组合可能不同还需其他评估。模型参数选择还有其他非常多的方法这里就讲了这两个。


五、实例
相关数据:链接,提取码:b95m
5.1美国消费者信心指数(sentiment.csv)
一个简单的小例子,对大致流程作部分展示
模块导入
from __future__ import absolute_import, division, print_function
import sys
import os
import pandas as pd
import numpy as np
# TSA from Statsmodels
import statsmodels.api as sm
import statsmodels.formula.api as smf
import statsmodels.tsa.api as smt
# 绘图
import matplotlib.pylab as plt
import seaborn as sns
#一些参数风格设置
pd.set_option('display.float_format', lambda x: '%.5f' % x) # pandas
np.set_printoptions(precision=5, suppress=True) # numpy
pd.set_option('display.max_columns', 100)
pd.set_option('display.max_rows', 100)
sns.set(style='ticks', context='poster')
%load_ext autoreload
%autoreload 2
%matplotlib inline
%config InlineBackend.figure_format='retina'
5.1.1数据读取及预处理
#数据读取
Sentiment = pd.read_csv('sentiment.csv',index_col=0, parse_dates=[0])
print(Sentiment.head())
#切分为测试数据和训练数据
n_sample = Sentiment.shape[0]
n_train = int(0.95 * n_sample)+1
n_forecast = n_sample - n_train
ts_train = Sentiment.iloc[:n_train]['UMCSENT']
ts_test = Sentiment.iloc[:n_forecast]['UMCSENT']
#截取10年数据并展示
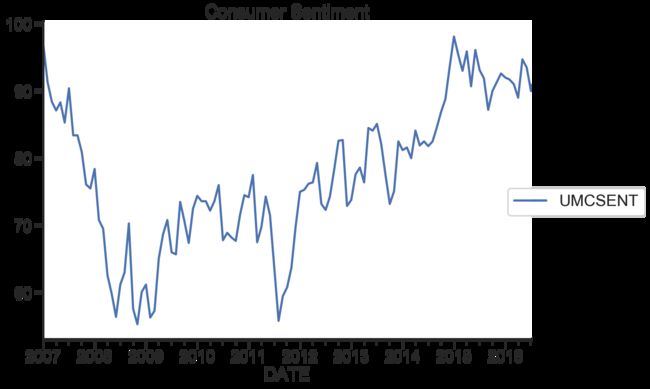
sentiment_short = Sentiment.loc['2007':'2017']
sentiment_short.plot(figsize = (12,8))
plt.title("Consumer Sentiment")
plt.legend(bbox_to_anchor = (1.25,0.5))
sns.despine()
plt.show()
DATE UMCSENT
2000-01-01 112.000000
2000-02-01 111.300000
2000-03-01 107.100000
2000-04-01 109.200000
2000-05-01 110.700000
5.1.2 d值确认
接着进行差分,绘画一阶差分及二阶差分图,观察图形得出
#一阶差分
sentiment_short['diff_1'] = sentiment_short['UMCSENT'].diff(1)
#二阶差分
sentiment_short['diff_2'] = sentiment_short['diff_1'].diff(1)
print(sentiment_short.head())
sentiment_short.plot(subplots=True, figsize=(18, 12))
DATE UMCSENT diff_1 diff_2
2007-01-01 96.90000 nan nan
2007-02-01 91.30000 -5.60000 nan
2007-03-01 88.40000 -2.90000 2.70000
2007-04-01 87.10000 -1.30000 1.60000
2007-05-01 88.30000 1.20000 2.50000

5.1.3 合适的p,q
ACF和PACF图像绘制
这里删除回原数据来展示,不然下一步会报错 ValueError: x is required to have ndim 1 but has ndim 2
del sentiment_short['diff_2']
del sentiment_short['diff_1']
print(sentiment_short.head())
print (type(sentiment_short))
DATE UMCSENT
2007-01-01 96.90000
2007-02-01 91.30000
2007-03-01 88.40000
2007-04-01 87.10000
2007-05-01 88.30000
fig = plt.figure(figsize=(12,8))
#画ACF
ax1 = fig.add_subplot(211)
fig = sm.graphics.tsa.plot_acf(sentiment_short, lags=20,ax=ax1)#lags表示滞后的阶数
ax1.xaxis.set_ticks_position('bottom')
fig.tight_layout();
#画PACF
ax2 = fig.add_subplot(212)
fig = sm.graphics.tsa.plot_pacf(sentiment_short, lags=20, ax=ax2)
ax2.xaxis.set_ticks_position('bottom')
fig.tight_layout();

四图直观展示改进:残差图、直方图、ACF图和PACF图
def tsplot(y, lags=None, title='', figsize=(14, 8)):
fig = plt.figure(figsize=figsize)
layout = (2, 2)
ts_ax = plt.subplot2grid(layout, (0, 0))
hist_ax = plt.subplot2grid(layout, (0, 1))
acf_ax = plt.subplot2grid(layout, (1, 0))
pacf_ax = plt.subplot2grid(layout, (1, 1))
y.plot(ax=ts_ax)
ts_ax.set_title(title)
y.plot(ax=hist_ax, kind='hist', bins=25)
hist_ax.set_title('Histogram')
smt.graphics.plot_acf(y, lags=lags, ax=acf_ax)
smt.graphics.plot_pacf(y, lags=lags, ax=pacf_ax)
[ax.set_xlim(0) for ax in [acf_ax, pacf_ax]]
sns.despine()
plt.tight_layout()
return ts_ax, acf_ax, pacf_ax
tsplot(ts_train, title='A Given Training Series', lags=20);

建立模型+参数选择(AIC、BIC):p范围[0 ,4],q范围[0, 4] d=0,遍历求最佳组合。
arima200 = sm.tsa.SARIMAX(ts_train, order=(2,0,0))
model_results = arima200.fit()
#遍历,寻找适宜的参数
import itertools
p_min = 0
d_min = 0
q_min = 0
p_max = 4
d_max = 0
q_max = 4
# Initialize a DataFrame to store the results,,以BIC准则
results_bic = pd.DataFrame(index=['AR{}'.format(i) for i in range(p_min,p_max+1)],
columns=['MA{}'.format(i) for i in range(q_min,q_max+1)])
for p,d,q in itertools.product(range(p_min,p_max+1),
range(d_min,d_max+1),
range(q_min,q_max+1)):
if p==0 and d==0 and q==0:
results_bic.loc['AR{}'.format(p), 'MA{}'.format(q)] = np.nan
continue
try:
model = sm.tsa.ARIMA(ts_train, order=(p, d, q),
#enforce_stationarity=False,
#enforce_invertibility=False,
)
results = model.fit()
results_bic.loc['AR{}'.format(p), 'MA{}'.format(q)] = results.bic
except:
continue
results_bic = results_bic[results_bic.columns].astype(float)
绘制BIC值热度图
fig, ax = plt.subplots(figsize=(10, 8))
ax = sns.heatmap(results_bic,
mask=results_bic.isnull(),
ax=ax,
annot=True,
fmt='.2f',
)
ax.set_title('BIC')
plt.show()
train_results = sm.tsa.arma_order_select_ic(ts_train, ic=['aic', 'bic'], trend='nc', max_ar=4, max_ma=4)
print('AIC', train_results.aic_min_order)
print('BIC', train_results.bic_min_order)
AIC (4, 3)
BIC (1, 0)
模型评估:残差分析 正态分布 QQ图线性
model_results.plot_diagnostics(figsize=(16, 12));

5.2维基百科词条探索性数据分析 EDA(train_1.csv)
我们通常拿到时间序列的数据后不会直接建模,而是会通过EDA观看数据内部结构。
数据内容为:维基百科词条点击量时间序列数据
5.2.1 导入模块、读取并查看数据
``cpp
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import re
%matplotlib inline
```cpp
train = pd.read_csv('train_1.csv').fillna(0)
train.head()
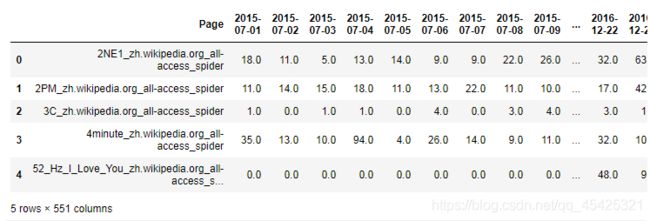
train.info() #数据相关信息查询
RangeIndex: 145063 entries, 0 to 145062
Columns: 551 entries, Page to 2016-12-31
dtypes: float64(550), object(1)
memory usage: 609.8+ MB
5.2.2Float 转 Int
这里数据比较大,观察数据发现有很有Float类型但实际都是整数,所以将其转换为Int类型节省空间:
for col in train.columns[1:]: #循环将每列转换
train[col] = pd.to_numeric(train[col],downcast='integer')
train.head()
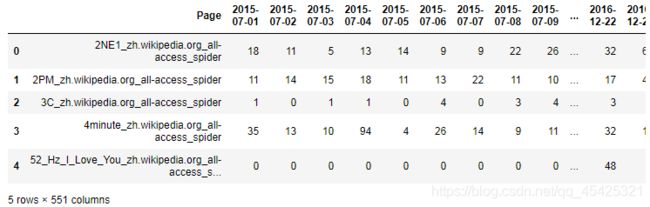
train.info()
RangeIndex: 145063 entries, 0 to 145062
Columns: 551 entries, Page to 2016-12-31
dtypes: int32(550), object(1)
memory usage: 305.5+ MB
5.2.3 分类统计展示(语种、词条)
该数据包含多种语言,用同一种模型预测不太科学,这里先统计语种出现频次:
#将page列的标志符号(例如zh)映射为国家
def get_language(page):
#通过下列公式搜索XX.wikipedia.org格式后返回xx
res = re.search('[a-z][a-z].wikipedia.org',page)
if res:
return res.group()[0:2]
return 'na'
train['lang']=train.Page.map(get_language)
#统计频次
from collections import Counter
print(Counter(train.lang))
Counter({‘en’: 24108, ‘ja’: 20431, ‘de’: 18547, ‘na’: 17855, ‘fr’: 17802, ‘zh’: 17229, ‘ru’: 15022, ‘es’: 14069})
基于语种划分词条:
lang_sets = {} #建立每个语种对应的词条库
lang_sets['en'] = train[train.lang=='en'].iloc[:,0:-1]
lang_sets['ja'] = train[train.lang=='ja'].iloc[:,0:-1]
lang_sets['de'] = train[train.lang=='de'].iloc[:,0:-1]
lang_sets['na'] = train[train.lang=='na'].iloc[:,0:-1]
lang_sets['fr'] = train[train.lang=='fr'].iloc[:,0:-1]
lang_sets['zh'] = train[train.lang=='zh'].iloc[:,0:-1]
lang_sets['ru'] = train[train.lang=='ru'].iloc[:,0:-1]
lang_sets['es'] = train[train.lang=='es'].iloc[:,0:-1]
sums = {} #统计每个语种的词条每天平均点击量
for key in lang_sets: #语种所有词条总点击量/词条数
sums[key] = lang_sets[key].iloc[:,1:].sum(axis=0) / lang_sets[key].shape[0]
将上面统计结果可视化:
days = [r for r in range(sums['en'].shape[0])]#提取总的天数550
fig = plt.figure(1,figsize=[15,10])
plt.ylabel('Views per Page')
plt.xlabel('Day')
plt.title('Pages in Different Languages')
labels={'en':'English','ja':'Japanese','de':'German',
'na':'Media','fr':'French','zh':'Chinese',
'ru':'Russian','es':'Spanish'
}
for key in sums:
plt.plot(days,sums[key],label = labels[key] )
plt.legend()
plt.show()

通过上图统计发现,英语明显高于其他语种,俄语和英语有一个突变可能发生了重大事情。因此通过不同语种进行建模是可行的,当然这里也可以通过不同词条建模,随机选择几个词条查看一下阅读量变化情况:
def plot_entry(key,idx):
data = lang_sets[key].iloc[idx,1:]
fig = plt.figure(1,figsize=(10,5))
plt.plot(days,data)
plt.xlabel('day')
plt.ylabel('views')
plt.title(train.iloc[lang_sets[key].index[idx],0])
plt.show()
idx = [1,100,500,5000]
for i in idx:
plot_entry('en',i)


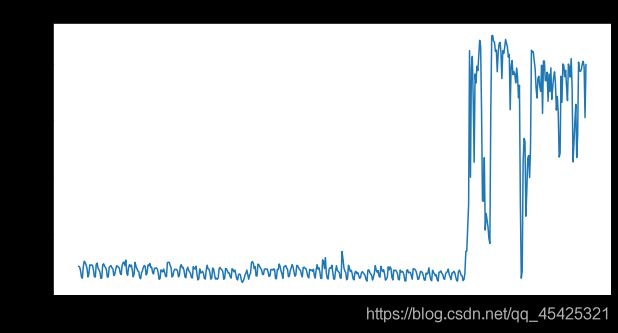

从上面的图可见明显的趋势变化,每个词条都有其时间热度,例如第一个图爆发明显,前面500天毫无波动,之后突然爆发。大部分词条都有类似趋势,我们可以筛选这类爆发图,统计分析后进而了解当时的“网红事件”。
通过对不同语种词条点击量的排序,我们也可以了解大众关注点,即热点:
npages = 5
top_pages = {}
for key in lang_sets:
print(key)
sum_set = pd.DataFrame(lang_sets[key][['Page']])
sum_set['total'] = lang_sets[key].sum(axis=1)
sum_set = sum_set.sort_values('total',ascending=False)
print(sum_set.head(10))
top_pages[key] = sum_set.index[0]
print('\n\n')
en Page total
38573 Main_Page_en.wikipedia.org_all-access_all-agents 12066181102
9774 Main_Page_en.wikipedia.org_desktop_all-agents 8774497458
74114 Main_Page_en.wikipedia.org_mobile-web_all-agents 3153984882
39180 Special:Search_en.wikipedia.org_all-access_all… 1304079353
10403 Special:Search_en.wikipedia.org_desktop_all-ag… 1011847748
74690 Special:Search_en.wikipedia.org_mobile-web_all… 292162839
39172 Special:Book_en.wikipedia.org_all-access_all-a… 133993144
10399 Special:Book_en.wikipedia.org_desktop_all-agents 133285908
33644 Main_Page_en.wikipedia.org_all-access_spider 129020407
34257 Special:Search_en.wikipedia.org_all-access_spider 124310206
ja Page total
120336 メインページ_ja.wikipedia.org_all-access_all-agents 210753795
86431 メインページ_ja.wikipedia.org_desktop_all-agents 134147415
123025 特別:検索_ja.wikipedia.org_all-access_all-agents 70316929
89202 特別:検索_ja.wikipedia.org_desktop_all-agents 69215206
57309 メインページ_ja.wikipedia.org_mobile-web_all-agents 66459122
119609 特別:最近の更新_ja.wikipedia.org_all-access_all-agents 17662791
88897 特別:最近の更新_ja.wikipedia.org_desktop_all-agents 17627621
119625 真田信繁_ja.wikipedia.org_all-access_all-agents 10793039
123292 特別:外部リンク検索_ja.wikipedia.org_all-access_all-agents 10331191
89463 特別:外部リンク検索_ja.wikipedia.org_desktop_all-agents 10327917
de Page total
139119 Wikipedia:Hauptseite_de.wikipedia.org_all-acce… 1603934248
116196 Wikipedia:Hauptseite_de.wikipedia.org_mobile-w… 1112689084
67049 Wikipedia:Hauptseite_de.wikipedia.org_desktop_… 426992426
140151 Spezial:Suche_de.wikipedia.org_all-access_all-… 223425944
66736 Spezial:Suche_de.wikipedia.org_desktop_all-agents 219636761
140147 Spezial:Anmelden_de.wikipedia.org_all-access_a… 40291806
138800 Special:Search_de.wikipedia.org_all-access_all… 39881543
68104 Spezial:Anmelden_de.wikipedia.org_desktop_all-… 35355226
68511 Special:MyPage/toolserverhelferleinconfig.js_d… 32584955
137765 Hauptseite_de.wikipedia.org_all-access_all-agents 31732458
na Page total
45071 Special:Search_commons.wikimedia.org_all-acces… 67150638
81665 Special:Search_commons.wikimedia.org_desktop_a… 63349756
45056 Special:CreateAccount_commons.wikimedia.org_al… 53795386
45028 Main_Page_commons.wikimedia.org_all-access_all… 52732292
81644 Special:CreateAccount_commons.wikimedia.org_de… 48061029
81610 Main_Page_commons.wikimedia.org_desktop_all-ag… 39160923
46078 Special:RecentChangesLinked_commons.wikimedia… 28306336
45078 Special:UploadWizard_commons.wikimedia.org_all… 23733805
81671 Special:UploadWizard_commons.wikimedia.org_des… 22008544
82680 Special:RecentChangesLinked_commons.wikimedia… 21915202
fr Page total
27330 Wikipédia:Accueil_principal_fr.wikipedia.org_a… 868480667
55104 Wikipédia:Accueil_principal_fr.wikipedia.org_m… 611302821
7344 Wikipédia:Accueil_principal_fr.wikipedia.org_d… 239589012
27825 Spécial:Recherche_fr.wikipedia.org_all-access_… 95666374
8221 Spécial:Recherche_fr.wikipedia.org_desktop_all… 88448938
26500 Sp?cial:Search_fr.wikipedia.org_all-access_all… 76194568
6978 Sp?cial:Search_fr.wikipedia.org_desktop_all-ag… 76185450
131296 Wikipédia:Accueil_principal_fr.wikipedia.org_a… 63860799
26993 Organisme_de_placement_collectif_en_valeurs_mo… 36647929
7213 Organisme_de_placement_collectif_en_valeurs_mo… 36624145
zh Page total
28727 Wikipedia:首页_zh.wikipedia.org_all-access_all-a… 123694312
61350 Wikipedia:首页_zh.wikipedia.org_desktop_all-agents 66435641
105844 Wikipedia:首页_zh.wikipedia.org_mobile-web_all-a… 50887429
28728 Special:搜索_zh.wikipedia.org_all-access_all-agents 48678124
61351 Special:搜索_zh.wikipedia.org_desktop_all-agents 48203843
28089 Running_Man_zh.wikipedia.org_all-access_all-ag… 11485845
30960 Special:链接搜索_zh.wikipedia.org_all-access_all-a… 10320403
63510 Special:链接搜索_zh.wikipedia.org_desktop_all-agents 10320336
60711 Running_Man_zh.wikipedia.org_desktop_all-agents 7968443
30446 瑯琊榜_(電視劇)zh.wikipedia.org_all-access_all-agents 5891589
ru Page total
99322 Заглавная_страница_ru.wikipedia.org_all-access… 1086019452
103123 Заглавная_страница_ru.wikipedia.org_desktop_al… 742880016
17670 Заглавная_страница_ru.wikipedia.org_mobile-web… 327930433
99537 Служебная:Поиск_ru.wikipedia.org_all-access_al… 103764279
103349 Служебная:Поиск_ru.wikipedia.org_desktop_all-a… 98664171
100414 Служебная:Ссылки_сюда_ru.wikipedia.org_all-acc… 25102004
104195 Служебная:Ссылки_сюда_ru.wikipedia.org_desktop… 25058155
97670 Special:Search_ru.wikipedia.org_all-access_all… 24374572
101457 Special:Search_ru.wikipedia.org_desktop_all-ag… 21958472
98301 Служебная:Вход_ru.wikipedia.org_all-access_all… 12162587
es Page total
92205 Wikipedia:Portada_es.wikipedia.org_all-access… 751492304
95855 Wikipedia:Portada_es.wikipedia.org_mobile-web_… 565077372
90810 Especial:Buscar_es.wikipedia.org_all-access_al… 194491245
71199 Wikipedia:Portada_es.wikipedia.org_desktop_all… 165439354
69939 Especial:Buscar_es.wikipedia.org_desktop_all-a… 160431271
94389 Especial:Buscar_es.wikipedia.org_mobile-web_al… 34059966
90813 Especial:Entrar_es.wikipedia.org_all-access_al… 33983359
143440 Wikipedia:Portada_es.wikipedia.org_all-access_… 31615409
93094 Lali_Espósito_es.wikipedia.org_all-access_all-… 26602688
69942 Especial:Entrar_es.wikipedia.org_desktop_all-a… 25747141
接着也可以统计热点随时间变化的情况:
for key in top_pages:
fig = plt.figure(1,figsize=(10,5))
cols = train.columns
cols = cols[1:-1]
data = train.loc[top_pages[key],cols]
plt.plot(days,data)
plt.xlabel('Days')
plt.ylabel('Views')
plt.title(train.loc[top_pages[key],'Page'])
plt.show()
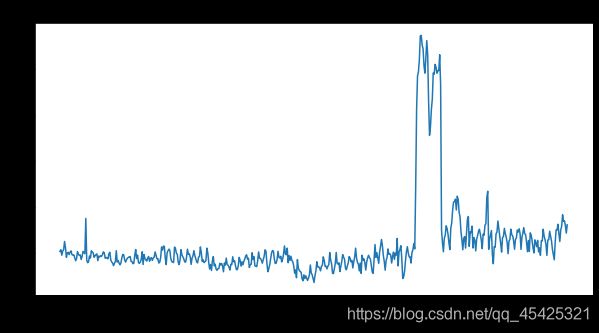
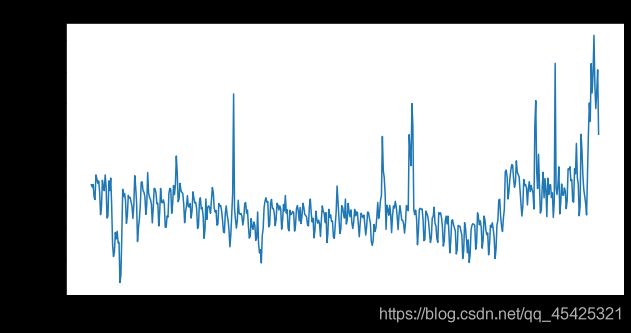






还可以通过文章类型之类的进行分类展示,越细越好。