


1
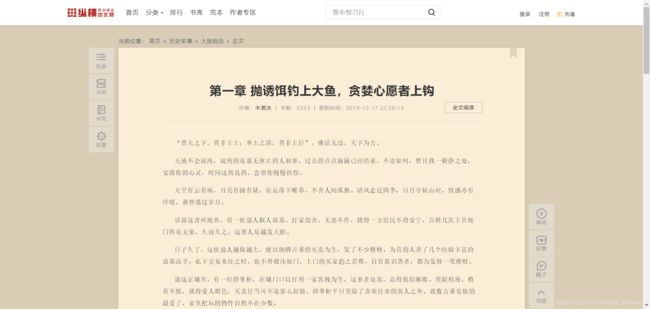
细心的朋友可能已经发现,除了div字样外,还有itemprop和class。itemprop和class就是div标签的属性,content和acticleBody是属性值,一个属性对应一个属性值。这东西有什么用?它是用来区分不同的div标签的,因为div标签可以有很多,我们怎么加以区分不同的div标签呢?就是通过不同的属性值。
仔细观察目标网站一番,我们会发现这样一个事实:itemprop属性为acticleBody的div标签,独一份!这个标签里面存放的内容,是我们关心的正文部分。
知道这个信息,我们就可以使用Beautiful Soup提取我们想要的内容了,编写代码如下:
# -*- coding:UTF-8 -*-
import requests
from bs4 import BeautifulSoup
if __name__ == "__main__":
target = 'http://book.zongheng.com/chapter/912802/59031605.html'
req = requests.get(url=target)
html = req.text
bf = BeautifulSoup(html)
texts = bf.find_all('div', itemprop="acticleBody")
print(texts)
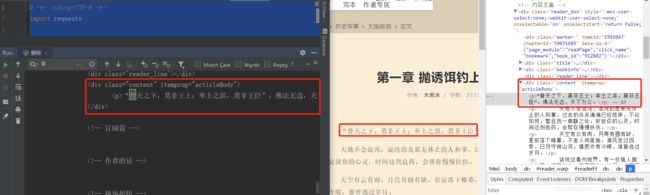
在解析html之前,我们需要创建一个Beautiful Soup对象。BeautifulSoup函数里的参数就是我们已经获得的html信息。然后我们使用find_all方法,获得html信息中所有itemprop属性为acticleBody的div标签。find_all方法的第一个参数是获取的标签名,第二个参数class_是标签的属性,为什么不是class,而带了一个下划线呢?因为python中class是关键字,为了防止冲突,这里使用class_表示标签的class属性,class_后面跟着的acticleBody就是属性值了。看下我们要匹配的标签格式:
这样对应的看一下,是不是就懂了?可能有人会问了,为什么不是find_all(‘div’,class="content", itemprop="acticleBody")?这样其实也是可以的,属性是作为查询时候的约束条件,添加一个 itemprop="acticleBody"条件,我们就已经能够准确匹配到我们想要的标签了,所以我们就不必再添加class这个属性了。运行代码查看我们匹配的结果:

我们可以看到,我们已经顺利匹配到我们关心的正文内容,但是还有一些我们不想要的东西。比如div标签名,p标签,以及各种空格。怎么去除这些东西呢?我们继续编写代码:
# -*- coding:UTF-8 -*-
import requests
from bs4 import BeautifulSoup
if __name__ == "__main__":
target = 'http://book.zongheng.com/chapter/912802/59031605.html'
req = requests.get(url=target)
html = req.text
bf = BeautifulSoup(html)
texts = bf.find_all('div', itemprop="acticleBody")
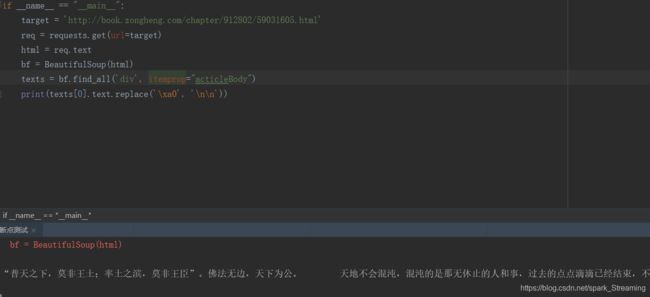
print(texts[0].text.replace('\xa0', '\n\n'))
find_all匹配的返回的结果是一个列表。提取匹配结果后,使用text属性,提取文本内容,滤除p标签。随后使用replace方法,剔除空格,替换为回车进行分段。 在html中是用来表示空格的。replace(’\xa0’,’\n\n’)就是去掉下图的空格符号,并用回车代替:
程序运行结果如下:
可以看到,我们很自然的匹配到了所有正文内容,并进行了分段。我们已经顺利获得了一个章节的内容,要想下载正本小说,我们就要获取每个章节的链接。我们先分析下小说目录:
URL:http://book.zongheng.com/showchapter/912802.html
通过审查元素,我们发现可以发现,这些章节都存放在了class属性为chapter-list clearfix的ul标签下,选取部分html代码如下:
在分析之前,让我们先介绍一个概念:父节点、子节点、孙节点。和限定了
标签的开始和结束的位置,他们是成对出现的,有开始位置,就有结束位置。我们可以看到,在
标签包含标签,那这个标签就是
标签的子节点,标签又包含标签,那么标签和标签就是
标签的孙节点。有点绕?那你记住这句话:谁包含谁,谁就是谁儿子!
**他们之间的关系都是相对的。**比如对于标签,它的子节点是标签,它的父节点是标签。这跟我们人是一样的,上有老下有小。
看到这里可能有人会问,这有好多标签和标签啊!不同的标签,它们是什么关系啊?显然,兄弟姐妹喽!我们称它们为兄弟结点。
好了,概念明确清楚,接下来,让我们分析一下问题。我们看到每个章节的名字存放在了标签里面。标签还有一个href属性。这里就不得不提一下标签的定义了,标签定义了一个超链接,用于从一张页面链接到另一张页面。标签最重要的属性是 href 属性,它指示链接的目标。
我们将之前获得的第一章节的URL和 标签对比看一下:
http://book.zongheng.com/chapter/912802/59031605.html
第一章 抛诱饵钓上大鱼,贪婪心愿者上钩
不难发现, 标签中href属性存放的属性值http://book.zongheng.com/chapter/912802/59031605.html就是章节URLhttp://book.zongheng.com/chapter/912802/59031605.html。其他章节也是如此!那这样,我们就可以根据 标签的href属性值获得每个章节的链接和名称了。
总结一下:小说每章的链接放在了class属性为chapter-list clearfix的 第一章 抛诱饵钓上大鱼,贪婪心愿者上钩 每个章节的链接、章节名、章节内容都有了。接下来就是整合代码,将获得内容写入文本文件存储就好了。编写代码如下: if __name__ == "__main__":
target = 'http://book.zongheng.com/showchapter/912802.html'
req = requests.get(url = target)
html = req.text
div_bf = BeautifulSoup(html)
div = div_bf.find_all('ul', class_ = 'chapter-list clearfix')
print(div[0])
还是使用find_all方法,运行结果如下:
很顺利,接下来再匹配每一个标签,并提取章节名和章节文章。如果我们使用Beautiful Soup匹配到了下面这个标签,如何提取它的href属性和标签里存放的章节名呢?
方法很简单,对Beautiful Soup返回的匹配结果a,使用a.get(‘href’)方法就能获取href的属性值,使用a.string就能获取章节名,编写代码如下:# -*- coding=UTF-8 -*-
import requests
from bs4 import BeautifulSoup
if __name__ == "__main__":
target = 'http://book.zongheng.com/showchapter/912802.html'
req = requests.get(url = target)
html = req.text
div_bf = BeautifulSoup(html)
div = div_bf.find_all('ul', class_ = 'chapter-list clearfix')
a_bf = BeautifulSoup(str(div[0]))
a = a_bf.find_all('a')
for each in a:
print(each.string, each.get('href'))
因为find_all返回的是一个列表,里边存放了很多的标签,所以使用for循环遍历每个标签并打印出来,运行结果如下。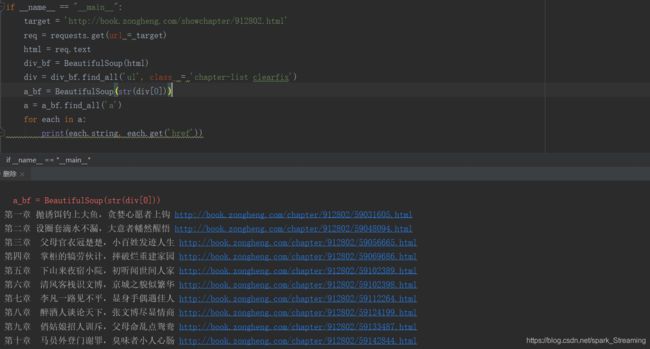
(4)整合代码
# -*- coding:UTF-8 -*-
'''
爬取小说内容思路步骤:
1.获取小说各个章节的下载链接
2.获取章节内容
3.将章节内容写入到磁盘文件中
'''
'''
from module_name import function_name as fn 从module_name模块中导入function_name函数并利用as指定函数的别名为fn
import module_name 导入module_name模块
BeautifulSoup 是一个可以从 HTML 或 XML 文件中提取数据的 Python 库
'''
from bs4 import BeautifulSoup
import requests, sys
"""
类说明:下载<纵横中华网>小说《大国良臣》
class class_name(): #class:来标识创建一个类
"""
class downloader():
def __init__(self):
'''
def: 定义一个函数(方法)
__init__: python中的特殊方法,当根据类创建一个实例时python会自动运行此方法(根据实例中传入的实参给类中的属性赋值)
self:类中的方法必须存在此形参,并且位于多个形参最前面,是一个指向实例本身的引用,让实例可以访问类中的属性和方法
'''
self.server = 'http://book.zongheng.com/'
self.target = 'http://book.zongheng.com/showchapter/912802.html'
self.names = [] #存放章节名
self.urls = [] #存放章节链接
self.nums = 0 #章节数
"""
函数说明:获取下载链接
"""
def get_download_url(self):
'''通过requests模块的get方法中的text方法可以获取链接的HTML代码'''
req = requests.get(url = self.target)
html = req.text
div_bf = BeautifulSoup(html)
'''通过变量div_bf的find_all可以找出所有标签为ul 属性为class="chapter-list clearfix"的所有内容'''
div = div_bf.find_all('ul', class_="chapter-list clearfix")
'''获取标签为ul 属性为class="chapter-list clearfix"的第一组'''
a_bf = BeautifulSoup(str(div[0]))
"""获取a_bf变量内容中标签为a的全部html标签内容存放于a列表中"""
a = a_bf.find_all('a')
"""获取a列表中的元素的数目即a标签的数目即章节的数目"""
self.nums = len(a)
for each in a:
"""
each中的每一个元素例如:六十章 假大人煽动贼人,小无赖举报立功
将a标签中的字符串追加到names属性中
将each中a标签的href属性中的信息获取追加到urls中
"""
self.names.append(each.string)
self.urls.append(each.get('href'))
"""
函数说明:获取章节内容
Parameters:
target - 下载连接(string)
"""
def get_contents(self, target):
req = requests.get(url = target)
html = req.text
bf = BeautifulSoup(html)
texts = bf.find_all('div', itemprop="acticleBody")
texts = texts[0].text.replace('\xa0','\n')
return texts
"""
函数说明:将爬取的文章内容写入文件
Parameters:
name - 章节名称(string)
path - 当前路径下,小说保存名称(string)
text - 章节内容(string)
"""
def writer(self, name, path, text):
write_flag = True
"""
with:不再需要打开文件时自动关闭文件
open:打开文件,若不存再则创建
path:文件目录,相对路径去当前.py的工作目录下面找,绝对路径去对应目录找文件
第二个参数:r/w/a/r+
r:只读取文件没有就新建
w:只写入文件没有就新建
a:在原有文件内容的基础上追加内容没有就新建
r+:可读取可写入没有就新建
encoding='utf-8':编码格式,大部分为UTF-8,也有GBK等
f 文件的别名
"""
with open(path, 'a', encoding='utf-8') as f:
f.write(name + '\n')
f.writelines(text)
f.write('\n\n')
"""
if __name__ == "__main__":只是一个虚拟标识,标识主函数入口位置(没有此标识代码依然可以执行不受影响)
__name__”是Python的内置变量,用于指代当前模块
"""
if __name__ == "__main__":
"""实例化downloader类为dl"""
dl = downloader()
dl.get_download_url()
print('《大国良臣》开始下载:')
print(dl.nums)
for i in range(dl.nums):
dl.writer(dl.names[i], 'E:\大国良臣.txt', dl.get_contents(dl.urls[i]))
sys.stdout.write(" 已下载:%.3f%%" % float(i/dl.nums) + '\r')
sys.stdout.flush()
# print(dl.names[i], '大国良臣.txt', dl.get_contents(dl.urls[i]))
print('《大国良臣》下载完成')